自然语言处理从小白到大白系列(6)说说中文分词那些事
文章目录
- 一. 分词常用方法
- 1.1 基于词表的方法
- 最大匹配法
- 全切分路径选择法
- 1.2 基于统计模型的方法
- 1. n元语法模型
- 2. 隐马尔可夫模型(Hidden Markov Model ,HMM)
- 3. 条件随机场模型(Conditional Random Fields,CRF)
- 1.3 基于深度学习的方法
- 二. 分词常用工具
- 2.1 [jieba](https://github.com/fxsjy/jieba)
- 2.2 [hanLP](https://github.com/hankcs/pyhanlp)
- 2.3 [PKUseg](https://github.com/lancopku/pkuseg-python)
- 2.4 [thulac](https://github.com/thunlp/THULAC-Python)
- 2.5 [nlpir](https://github.com/NLPIR-team/NLPIR)
- 2.6 [snowNLP](https://github.com/isnowfy/snownlp)
自然语言处理的中文分词有三个难点:
- 分词标准
例如“花草”,有的人认为是一个词,有的人认为应该划分开为两个词“花/草”。某种意义上,中文分词可以说是一个没有明确定义的问题。- 切分歧义
不同的切分结果会有不同的含义,这个不用举例了,很常见。- 未登录词
也叫新词发现,或者生词,未被词典收录的词。
一. 分词常用方法
根据宗成庆老师的《统计自然语言处理》中,将分词的方法分为了基于词表的方法和基于统计的方法,而我们知道目前还有一种方法,无论是在NER(命名实体识别)还是POS(词性标注)中,都用得十分广泛,那就是Bi-LSTM +CRF的方法。本文我们就主要这三种主流的分词方法。
1.1 基于词表的方法
基于词表的方法典型的有:最大匹配法和全切分路径法。
最大匹配法
- 正向最大匹配法
顾名思义,就是一个句子从前往后一直匹配,只要能构成词语,就贪婪匹配,这种方法当然是简单粗暴,会导致切分歧义。 - 逆向最大匹配法
顾名思义+1,就是和正向相对应的,简单粗暴匹配,也会导致切分歧义。 - 双向扫描法
这就是结合了正向和逆向最大匹配法,然后两个当中选一个词数少的切分作为结果,当然也不尽如人意,也一定程度上会造成歧义。
全切分路径选择法
- n-最短路径方法
将所有的切分结果组成有向无环图,切词结果作为节点,词和词之间的边赋予权重,找到权重和最大的路径即为最终结果。比如可以通过词频作为权重,找到一条总词频最大的路径即可认为是最佳路径。
1.2 基于统计模型的方法
基于统计的分词算法,本质上是一个序列标注问题。我们将语句中的字,按照他们在词中的位置进行标注。标注主要有:B(词开始的一个字),E(词最后一个字),M(词中间的字,可能多个),S(一个字表示的词)。例如“网商银行是蚂蚁金服微贷事业部的最重要产品”,标注后结果为“BMMESBMMEBMMMESBMEBE”,对应的分词结果为“网商银行/是/蚂蚁金服/微贷事业部/的/最重要/产品”。
主要的统计模型有:
- N元文法模型(N-gram)
- 隐马尔可夫模型(Hidden Markov Model ,HMM)
- 最大熵模型(ME)
- 条件随机场模型(Conditional Random Fields,CRF)等。
1. n元语法模型
首先根据词典,对句子进行简单匹配,找出所有可能的词典词(和n-最短路径方法类似),然后,将他们和所有的单个字作为节点,构造一个n元切分词图。边上的n元概率表示代价,最后利用相关的搜索算法(如维特比算法)找到概率最大的路径,作为分词结果。
2. 隐马尔可夫模型(Hidden Markov Model ,HMM)
HMM,隐马尔科夫模型。隐马尔科夫模型在机器学习中应用十分广泛,它包含观测序列和隐藏序列两部分。对应到NLP中,我们的语句是观测序列,而序列标注结果是隐藏序列。任何一个HMM都可以由一个五元组来描述:观测序列,隐藏序列,隐藏态起始概率,隐藏态之间转换概率(转移概率),隐藏态表现为观测值的概率(发射概率)。其中起始概率,转移概率和发射概率可以通过大规模语料统计来得到。从隐藏态初始状态出发,计算下一个隐藏态的概率,并依次计算后面所有的隐藏态转移概率。我们的序列标注问题就转化为了求解概率最大的隐藏状态序列问题。jieba分词中使用HMM模型来处理未登录词问题,并利用viterbi算法来计算观测序列(语句)最可能的隐藏序列(BEMS标注序列)。
更详细的可以看另一篇详细的介绍:隐马尔可夫模型
3. 条件随机场模型(Conditional Random Fields,CRF)
既然是标注任务,肯定少不了条件随机场,条件随机场比较重要的是特征模板,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
更详细的可以移步我的另一篇博客:条件随机场
1.3 基于深度学习的方法
这里主要介绍双向LSTM+CRF的标注方法:
- 可以直接用crf吗?
其实直接用crf当然是可以的,但是我们知道,crf的关键还是在于它的特征模板,特征模板的好坏,影响了最后标标注的结果。现在我们想要自动提取词的特征,怎么做呢?方案就是Bi-LSTM。
- 可以直接用Bi-LSTM吗?
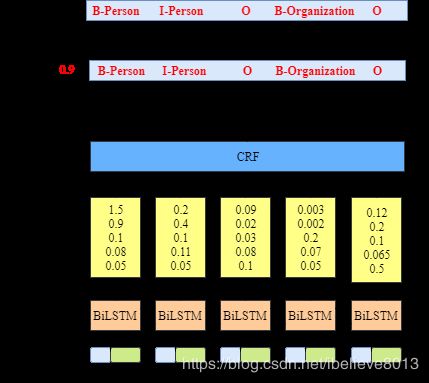
直接用Bi-LSTM当然也是可以的,每一个词向量输入了Bi-LSTM之后,都对应一个输出状态,直接用这个输出状态接softmax,输出每个标记的得分,当然也是可以的。但是这又有个问题,crf可以体现出的转移特征,这里的softmax没有体现,每个词的最大概率当然是输出来了,但是转移的概率没有被体现出来,这就可能会出现标记为’BB’(开头开头)这样的序列出现,而这样的序列却是不合理的。(图片是做NER的,照搬过来啦,意思是一样的)
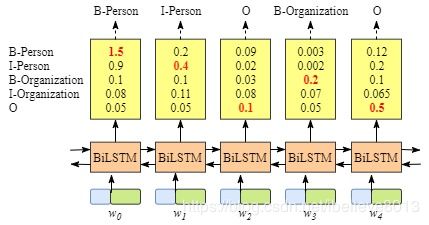
- 用Bi-LSTM+crf怎么做?
如图所示,这里的BiLSTM输出的是每个标注的得分,然后将这个输入到CRF中,输出最高概率的序列。
具体一点,对于每个输入 X = ( x 1 , x 2 , . . . , x n ) X=(x_1, x_2, ..., x_n) X=(x1,x2,...,xn),得到一个预测序列 y = ( y 1 , y 2 , . . . , y n ) y=(y_1, y_2,..., y_n) y=(y1,y2,...,yn),定义这个预测的得分 s ( X , y ) = Σ i = 0 n A y i , y i + 1 + Σ i = 1 n P i , y i s(X,y)=\Sigma_{i=0}^nA_{y_i,y_i+1}+\Sigma_{i=1}^nP_{i,y_i} s(X,y)=Σi=0nAyi,yi+1+Σi=1nPi,yi
其中 P i , y i P_{i,y_i} Pi,yi为第i个位置softmax输出为 y i y_i yi的概率, A y i , y i + 1 A_{y_i,y_i+1} Ayi,yi+1为从 y i y_i yi到 y i + 1 y_{i+1} yi+1的转移概率,当tag(B-person,B-location。。。。)个数为n的时候,转移概率矩阵为(n+2)*(n+2),因为额外增加了一个开始位置和结束位置。
这个得分函数S就很好地弥补了传统BiLSTM的不足,因为我们当一个预测序列得分很高时,并不是各个位置都是softmax输出最大概率值对应的label,还要考虑前面转移概率相加最大,即还要符合输出规则(B后面不能再跟B),比如假设BiLSTM输出的最有可能序列为BBIBIOOO,那么因为我们的转移概率矩阵中B->B的概率很小甚至为负,那么根据s得分,这种序列不会得到最高的分数,即就不是我们想要的序列。
————————————————
引用自:https://blog.csdn.net/bobobe/article/details/80489303
二. 分词常用工具
2.1 jieba
jieba分词是国内使用人数最多的中文分词工具
jieba分词支持三种模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba分词过程中主要涉及如下几种算法:
(1)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
(2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3)对于未登录词,采用了基于汉字成词能力的 HMM 模型,采用Viterbi 算法进行计算;
(4)基于Viterbi算法做词性标注;
(5)基于tf-idf和textrank模型抽取关键词;
对jieba的解析,更输入地可以看这篇,这位同僚讲得很好:对Python中文分词模块结巴分词算法过程的理解和分析。
2.2 hanLP
pyhanlp: Python interfaces for HanLP
自然语言处理工具包HanLP的Python接口, 支持自动下载与升级HanLP,兼容py2、py3。
安装
pip install pyhanlp
注意pyhanlp安装之后使用的时候还会自动下载相关的数据文件,zip压缩文件600多M,速度有点慢,时间有点长
2.3 PKUseg
pkuseg具有如下几个特点:
- 多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 我们目前支持了新闻领域,网络领域,医药领域,旅游领域,以及混合领域的分词预训练模型。在使用中,如果用户明确待分词的领域,可加载对应的模型进行分词。如果用户无法确定具体领域,推荐使用在混合领域上训练的通用模型。各领域分词样例可参考 example.txt。
- 更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
- 支持用户自训练模型。支持用户使用全新的标注数据进行训练。
支持词性标注。
编译和安装
目前仅支持python3
为了获得好的效果和速度,强烈建议大家通过pip install更新到目前的最新版本
通过PyPI安装(自带模型文件):
pip3 install pkuseg
之后通过import pkuseg来引用
建议更新到最新版本以获得更好的开箱体验:
pip3 install -U pkuseg
2.4 thulac
清华推出的自然语言工具包,具有中文分词和词性标注功能
(1)能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
(2)准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
(3)速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
2.5 nlpir
是由北京理工大学张华平博士研发的中文分词系统,经过十余年的不断完善,拥有丰富的功能和强大的性能。NLPIR是一整套对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。主要功能包括:中文分词,词性标注,命名实体识别,用户词典、新词发现与关键词提取等功能。
2.6 snowNLP
(1)中文分词(Character-Based Generative Model);
(2)词性标注(3-gram HMM);
(3)情感分析(简单分析,如评价信息);
(4)文本分类(Naive Bayes)
(5)转换成拼音(Trie树实现的最大匹配)
(6)繁简转换(Trie树实现的最大匹配)
(7)文本关键词和文本摘要提取(TextRank算法)
(8)计算文档词频(TF,Term Frequency)和逆向文档频率(IDF,Inverse Document Frequency)
(9)Tokenization(分割成句子)
(10)文本相似度计算(BM25)
SnowNLP的最大特点是特别容易上手,用其处理中文文本时能够得到不少有意思的结果,但不少功能比较简单,还有待进一步完善。
参考资料:
自然语言处理1 – 分词;
BiLSTM+crf的一些理解;
自然语言处理入门(4)——中文分词原理及分词工具介绍
对Python中文分词模块结巴分词算法过程的理解和分析
码农场