SQL优化--索引问题
索引的存储分类
索引在Mysql的存储引擎中实现 不是在服务器层中实现。so 每个存储引擎的索引不一定完全相同 不是所有的存储引擎支持所有的索引类型
B-Tree索引:最常见 大部分引擎支持
HASH索引:只有Memory引擎支持
R-Tree索引(空间索引):是MyISAM的一个特殊索引类型 用于地理空间数据类型 较少
Full-text(全文索引):也是MyISAM的一个特殊索引类型 主要用于全文索引 InnoDB从MySQL5.6版本开始提供全文索引支持
目前不支持函数索引 但能对列的前面某一部分进行索引
-----MySQL使用索引的典型场景
1.匹配全值(Match the full value)对索引中所有列都指定具体值,对索引中的所有列都有等值匹配的条件。
例子:
alter table rental drop index rental_date;
alter table rental add index idx_rental_date(rental_date,inventory_id,customer_id);
explain select * from rental where rental_date='2005-05-25 17:22:10' and inventory_id=373 and customer_id=343\G;

2.匹配值得范围查询 对索引值能够进行范围查找。
explain select * from rental where customer_id >= 373 and customer_id < 400\G;

3.匹配最左前缀 仅仅使用索引中的最左边列查找 例如col1+col2+col3字段上的联合索引能够被包含coll (coll1+coll2)、(coll1+coll2+coll3)
如果查询条件中仅包含索引的第一列支付日期payment_date和索引的第三列更新时间last_update会使用index
alter table payment add index idx_payment_date(payment_date,amount,last_update);
explain select * from payment where payment_date = '2006-02-14 15:16:03'and last_update='2006-02-15 22:12:32'\G;

如果是第二列和第三列 就不会使用索引
explain select * from payment where amount=3.98 and last_update='2006-02-15 22:12:32'\G;

4.仅对索引进行查询 查询列都在索引的字段中,查询的效率更高
explain select * from payment where payment_date = '2006-02-14 15:16:03'and amount=3.98\G;

5.匹配列前缀 仅仅使用索引中的第一列 并且包含索引第一列的开头部分进行查找
create index idx_title_desc_part on film_text (title(10),description(20));
explain select title from film_text where title like 'AFRICAN%'\G;

6.能够实现索引匹配部分精确而其他部分进行范围匹配(部分精确 其他范围搜索)
explain select inventory_id from rental where rental_date='2006-02-14 15:16:03' and customer_id >= 300 and customer_id <= 400\G;
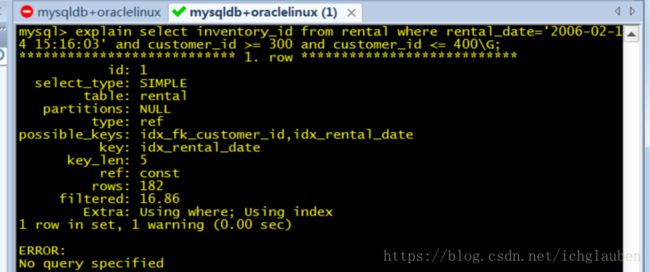
7.如果列名是索引 使用column_name is null就会使用索引(区别于oracle)
explain select * from payment where rental_id is null\G;

8.MySQL5.6引入Index Condition Pushdown的特性 进一步优化了查询
Pushdown表示操作下放 某些情况下的条件过滤操作下放到存储引擎
explain select * from rental where rental_date='2006-02-14 15:16:03' and customer_id >= 300 and customer_id <= 400\G;

------存在索引但不能使用索引的典型场景
1.以%开头的LIKE查询不能利用B-Tree索引 执行计划中key的值为NULL表示没有使用索引
2.数据类型出现隐式转换的时候也不会使用索引 特别是当列类型是字符串 在where条件中把字符常量值用引号引起来 否则即便有索引 MySQL也不会用到
explain select * from actor where last_name=1\G;
explain select * from actor where last_name='1'\G;

3.复合索引情况下,假如查询条件不包含索引列最左边部分 不满足最左原则leftmost 是不会使用复合索引的。
explain select * from payment where amount=3.98 and last_update='2006-02-15 22:12:32'\G;

4.mysql估计使用索引比全表扫描更慢 不使用索引
5.用or分割开的条件 如果or前的条件中的列有索引 后面的列中没有索引 那么涉及索引不会使用
explain select * from payment where customer_id= 203 or amount=3.96\G;

--查看索引使用情况
若索引在工作 Handler_read_key的值将很高 这个值代表了一个行被索引值读的次数,很低的值表名增加索引得到的性能改善不高,因为索引并不经常使用
show status like 'Handler_read%';

值较高 表名表索引不正确或写入的查询没有利用索引
--两个简单实用的优化方法
1.定期分析表和检查表
分析表语法
ANALYZE[LOCAL|NO_WRITE_TO_BINLOG] TABLE tbl_name [,tbl_name]....
analyze table payment;

CHECK TABLE tbl_name [,tbl_name]...[option]={QUICK|FAST|MEDIUM|EXTENDED|CHANGED}
check table payment_myisam;

example:
输入以下语句
建立视图
create view v_payment_myisam as select * from payment_myisam;
check table v_payment_myisam;
删除表
drop table payment_myisam;
check table v_payment_myisam;

2.定期优化表
OPTIMIZE [LOCAL|NO_WRITE_TO_BINLOG] TABLE tbl_name [,tbl_name]...
如果已经删除表的大部分 或者已经对含有可变长度行的表进行很多更改 使用OPTIMIZE TABLE命令来进行表优化。这个命令可以将表中的空间碎片进行合并,可以消除由于删除或者更新造成的空间浪费。该优化只对MyISAM
BDB 和InnoDB表起作用。
mysql> optimize table payment_myisam\G;

--常用SQL优化
--大批量插入数据
--优化INSERT数据
--优化ORDER BY语句
--优化GROUP BY语句
--优化嵌套查询
--MySQL如何优化OR语句
--优化分页查询
--使用SQL提示
--大批量插入数据
对于MyISAM存储引擎的表 可以通过以下方式快速导入大量的数据
ALTER TABLE tbl_name DISABLE KEYS;
...
ALTER TABLE tbl_name ENABLE KEYS;
以上用来打开或者关闭MyISAM表非唯一索引的更新 在导入大量的数据到一个非空的MyISAM表时 通过设置这两个命令 可以提高导入效率。
当导入大量数据->一个空的MyISAM表 默认就是先导入数据然后才创建索引
alter table film_test2 disable keys;
load data infile '/mysql/app/film_test.txt' into table film_test2;
alter table film_test2 enable keys;
以上对的是MyISAM表
对于InnoDB表 可以有以下几种方式提高InnoDB表的导入效率
1.因为InnoDB类型的表是按照主键的顺序保存的 所以将导入的数据按照主键的顺序排列 可以有效提高导入数据的效率
2.在导入数据前执行 SET UNIQUE_CHECKS=0 关闭唯一性校验 在导入结束后执行 SET UNIQUE_CHECKS=1 恢复唯一性校验 可以提高导入效率
--优化INSERT数据
考虑采用以下几种优化方式:
1.如果同时从同一客户插入很多行 应该尽量使用多个值表的INSERT语句 这种方式将大大缩减客户端与数据库之间的连接、关闭等消耗 使得效率比分开单个执行快 Insert into test values (1,2),(1,3),(1,4)......
2.如果从不同客户插入很多行 可以通过使用INSERT DELAYED语句得到更高速度 DELAYED含义是让INSERT马上执行 数据都被存放在内存队列中 并没有真正写入磁盘 LOW_PRIORITY相反 在所有其他用户对表的读写完成后才进行插入
3.将索引文件和数据文件分在不同的磁盘上存放
4.若进行批量插入 可以通过增加bulk_insert_buffer_size变量值得方法来提高速度(只对MyISAM适用)
5.当从一个文本文件装载一个表时 使用LOAD DATA INFILE。比使用很多INSERT语句快20倍
--优化ORDER BY语句
MySQL的两种排序方式
1.通过有序索引顺序扫描直接返回有序数据 这种方式在使用explain分析查询的时候显示为Using Index 不需要额外的排序 操作效率较高
explain select customer_id from customer order by store_id\G;

2.通过对返回数据进行排序 Filesort排序 所有不是通过索引直接返回排序结果的排序都叫Filesort排序 Filesort并不代表通过磁盘文件进行排序 只是说明进行一个排序操作 操作是否使用磁盘文件或临时表 取决于MySQL服务器对排序参数的设置和需要排序数据的大小
mysql> explain select * from customer order by store_id\G;

ALTER TABLE customer add index idx_storeid_email (store_id,email);
explain select store_id,email,customer_id from customer order by email\G;
虽然只用访问idx就够了 但在索引上发生了一次排序 执行计划中仍有Using Filesort

Filesort:通过相应的排序算法 将取得的数据在sort_buffer_size系统变量设置的内存排序区中进行排序 如果内存装载不下 就会将磁盘上的数据分块 在对个数据块进行排序 然后将各个数据块合并成有序结果集 sort_buffer_size设置的排序区是每个线程独占的 所以同一时刻有多个sort buffer排序区
优化目标:尽量减少额外的排序 通过索引直接返回有序数据 WHERE和ORDER BY使用相同的索引 并且ORDER BY顺序和索引顺序相同 并且ORDER BY字段都是升序或降序 否则需要额外排序 Using Filesort
explain select store_id,email,customer_id from customer where store_id =1 order by email desc \G;

总结:下列SQL可以使用索引
SELECT * FROM tabname ORDER BY key_part1,key_part2,...;
SELECT * FROM tabname WHERE key_part1=1 ORDER BY key_part1 DESC ,key_part2 DESC;
SELECT * FROM tabname ORDER BY key_part1 DESC ,key_part2 DESC;
下列SQL可以不能使用索引
SELECT * FROM tabname ORDER BY key_part1 DESC,key_part2 ASC;
--order by 的字段混合ASC和DESC
SELECT * FROM tabname WHERE key2=constant ORDER BY key1;
--用于查询行的关键字与ORDER BY中使用的不相同
SELECT * FROM tabname ORDER BY key1,key2;
--对不同的关键字使用ORDER BY
Filesort优化:MySQL两种排序算法
两次扫描算法:首先根据条件取出排序字段和行指针的信息 之后在sort buufer中排序 如果排序区buffer不够 在临时表中存储排序结果 完成后根据行指针回表读取记录 需要两次访问数据 第一次获取排序字段和指针信息 第二次根据行指针获取记录
一次扫描算法:一次性取出满足条件行的所有字段
适当加大max_length_for_sort_data值
适当加大sort_buffer_size排序区
尽量使用必要字段 不是select *
--优化GROUP BY语句
默认情况下 MySQL对所有GROUP BY col1,col2字段进行排序 与ORDER BY col1,col2...类似
如果查询包括GROUP BY但用户想要避免排序结果的消耗 指定ORDER BY NULL禁止排序
EXPLAIN SELECT payment_date,sum(amount) from payment group by payment_date\G;
explain select payment_date,sum(amount) from payment group by payment_date order by null\G;

--优化嵌套查询
使用子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 同时也可以避免失误或者表锁死 写起来很容易 有些情况 可以被更有效率的JOIN代替(因为MySQL不需要在内存中创建临时表来完成这个逻辑上需要两个步骤的查询工作)
explain select * from customer where customer_id not in(select customer_id from payment)\G;
explain select * from customer a left join payment b on a.customer_id=b.customer_id where b.customer_id is null\G;


--MySQL如何优化OR语句
善于利用索引 要用索引 需要OR之间的每个条件列都必须用到索引 如果没有索引 应该考虑增加索引
--优化分页查询
在一般分页查询时 通过创建覆盖索引能够比较好的提高性能 困扰场景 limit 1000,20 此时MySQL排序出前1020条记录 仅仅需要1001 -1020条记录 前1000条记录被抛弃 代价高
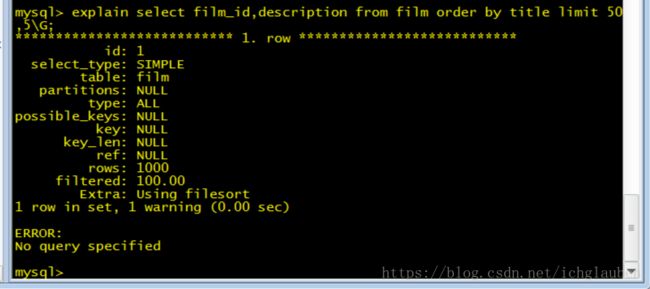
1.在索引上完成排序分页操作 最后根据主键关联回原表查询所需的其他列内容
explain select film_id,description from film order by title limit 50,5\G;
explain select a.film_id,a.description from film a inner join (select film_id from film order by title limit 50,5) b on a.film_id = b.film_id\G;
2.把limit查询转换成某个位置的查询
explain select * from payment order by rental_id desc limit 410,10\G;
select * from payment order by rental_id desc limit 400,10;
explain select * from payment where rental_id < 15640 order by rental_id desc limit 10\G;


--使用SQL提示
select SQL_BUFFER_RESULTS * from
1.USE INDEX
2.IGNORE INDEX
3.FORCE INDEX
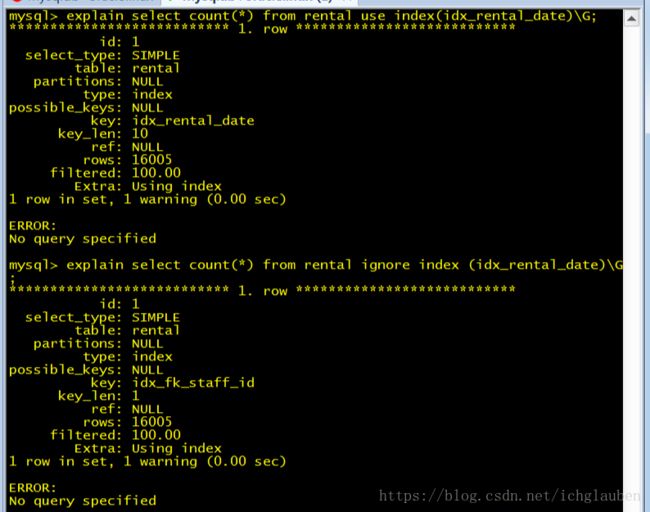
explain select count(*) from rental use index(idx_rental_date)\G;
explain select count(*) from rental ignore index (idx_rental_date)\G;
explain select * from rental where inventory_id > 1\G;
explain select * from rental use index(idx_fk_inventory_id) where inventory_id >1\G;
explain select * from rental force index (idx_fk_inventory_id) where inventory_id >1\G;

--常用SQL技巧
--1.正则表达式的使用
^ 在字符串开始匹配
$ 在字符串结尾匹配
. 匹配任意单个字符
[...] 匹配出括号内的任意字符
[^...] 普票不出括号内的任意字符
a* 匹配0个或多个a
a+ 匹配1个或多个a
a? 匹配1个或0个a
a1|a2 或
a(m) m个a
a(m,) m个或更多个a
a(m,n) 匹配m-n个a
a(,n) 匹配0-n个a
--rand()
--使用group by的with rollup子句
可以检索出更多的分组聚合信息 不仅仅能像一般的GROUP BY语句检索出各组的聚合信息 还能检索出本组类的整体聚合信息
with rollup是反应的一种OLAP思想 GROUP BY 语句执行完后可以满足用户想要得到的任何一个分组以及分组组合的聚合信息。
select date_format(payment_date,'%Y-%m') ,staff_id,sum(amount) from payment group by date_format(payment_date,'%Y-%m'),staff_id;
select date_format(payment_date,'%Y-%m') ,staff_id,sum(amount) from payment group by date_format(payment_date,'%Y-%m'),staff_id with rollup;

ROLLUP和ORDER BY排斥 LIMIT用在ROLLUP后面
--BIT GROUP FUNCTION做统计
BIT_AND()(统计每个顾客每次来的商品) BIT_OR()(作为二进制来计数买了什么东西 类型