【Oracle】sum(..) over(..)用法分析
今天再看sql优化详解的时候,提到了一个sum(..) over(..)
于是自己实验并在网上找了相关的一些文章来看
下面创建一张表:
create sequence xulie
increment by 1
start with 1
maxvalue 9999999999;
create table test(id number(20),name varchar2(20),sal number(38),bumen number(30))
insert into test values(xulie.nextval,'aaa','1','10');--执行20次,在执行下一条
insert into test values(xulie.nextval,'aaa','1','20'); --执行5边就行查看下:
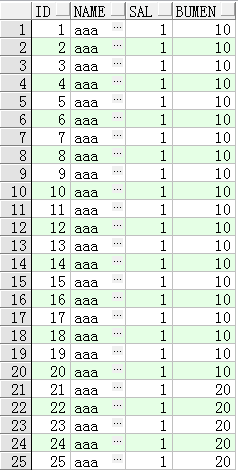
前20条部门为10,后5条部门为20
下面想将所有的员工sal加起来,但是要显示逐级加的
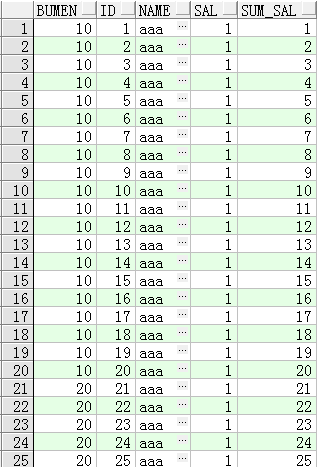
如上图所示,是1+1 -> 2+1->3+1...24+1
这样现实的是部分组,全部相加
sql:
select bumen,id,name,sal,sum(sal) over(order by id) as sum_sal from test 下面是部门之间相加:
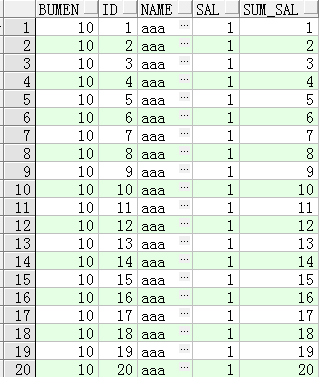
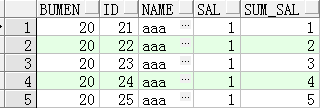
sql:
select bumen,id,name,sal,sum(sal) over(order by id) as sum_sal from test where bumen=10;
select bumen,id,name,sal,sum(sal) over(order by id) as sum_sal from test where bumen=20;可以通过一条sql达到两条sql的效果:
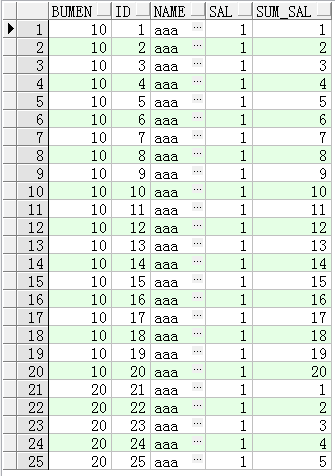
SQL:
select bumen,id,name,sal,sum(sal) over(partition by bumen order by id) as sum_sal from test 总结:
sum(…) over( ),对所有行求和
sum(…) over( order by … ), 连续求和
sum(…) over( partition by… ),同组内所行求和
sum(…) over( partition by… order by … ),同第1点中的排序求和原理,只是范围限制在组内
使用 sum(sal) over (order by id)… 查询员工的薪水“连续”求和,
注意over (order by id)如果没有order by 子句,求和就不是“连续”的.
sum(sal) over (partition by bumen order by id) 按部门“连续”求总和
sum(sal) over (partition by bumen) 按部门求总和
sum(sal) over (order by bumen,id) 不按部门“连续”求总和
sum(sal) over () 不按部门,求所有员工总和,效果等同于sum(sal)。
在”… from test;”后面不要加order by 子句,使用的分析函数的(partition by bumen order by sal)
里已经有排序的语句了,如果再在句尾添加排序子句,一致倒罢了,不一致,结果就令人费劲了
参考文章:
https://blog.csdn.net/yangshangwei/article/details/52985553