问题排查之频繁CMSGC
现象:
GC日志疯狂在刷,这是截取了其中一次CMSGC的全过程日志。
2019-03-28T10:10:46.489+0800: 1444.485: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1685579K(2097152K)] 1791138K(3984640K), 0.0873920 secs] [Times: user=0.09 sys=0.00, real=0.09 secs]
2019-03-28T10:10:46.577+0800: 1444.573: [CMS-concurrent-mark-start]
2019-03-28T10:10:47.997+0800: 1445.994: [GC (Allocation Failure)2019-03-28T10:10:47.998+0800: 1445.994: [ParNew: 1750551K->74756K(1887488K), 0.0569910 secs] 3436130K->1765656K(3984640K), 0.0578370 secs] [Times: user=0.21 sys=0.01, real=0.06 secs]
2019-03-28T10:10:49.588+0800: 1447.584: [CMS-concurrent-mark: 2.951/3.011 secs] [Times: user=9.37 sys=2.23, real=3.01 secs]
2019-03-28T10:10:49.588+0800: 1447.584: [CMS-concurrent-preclean-start]
2019-03-28T10:10:49.609+0800: 1447.605: [CMS-concurrent-preclean: 0.019/0.021 secs] [Times: user=0.05 sys=0.03, real=0.02 secs]
2019-03-28T10:10:49.609+0800: 1447.605: [CMS-concurrent-abortable-preclean-start]
2019-03-28T10:10:49.719+0800: 1447.715: [GC (Allocation Failure)2019-03-28T10:10:49.719+0800: 1447.715: [ParNew: 1752580K->78713K(1887488K), 0.0595130 secs] 3443480K->1778889K(3984640K), 0.0603000 secs] [Times: user=0.22 sys=0.01, real=0.06 secs]
2019-03-28T10:10:50.839+0800: 1448.836: [CMS-concurrent-abortable-preclean: 1.149/1.230 secs] [Times: user=3.71 sys=0.94, real=1.23 secs]
2019-03-28T10:10:50.841+0800: 1448.837: [GC (CMS Final Remark)[YG occupancy: 1142654 K (1887488 K)]2019-03-28T10:10:50.841+0800: 1448.837: [Rescan (parallel) , 0.4307530 secs]2019-03-28T10:10:51.272+0800: 1449.268: [weak refs processing, 0.0003880 secs]2019-03-28T10:10:51.272+0800: 1449.268: [class unloading, 0.0118590 secs]2019-03-28T10:10:51.284+0800: 1449.280: [scrub symbol table, 0.0161310 secs]2019-03-28T10:10:51.300+0800: 1449.296: [scrub string table, 0.0017690 secs] [1 CMS-remark: 1700176K(2097152K)] 2842830K(3984640K), 0.4645560 secs] [Times: user=1.77 sys=0.01, real=0.47 secs]
2019-03-28T10:10:51.306+0800: 1449.302: [CMS-concurrent-sweep-start]
2019-03-28T10:10:51.862+0800: 1449.859: [GC (Allocation Failure)2019-03-28T10:10:51.863+0800: 1449.859: [ParNew: 1756537K->64110K(1887488K), 0.0823590 secs] 3456693K->1773946K(3984640K), 0.0829730 secs] [Times: user=0.30 sys=0.00, real=0.09 secs]
2019-03-28T10:10:52.481+0800: 1450.477: [CMS-concurrent-sweep: 1.087/1.175 secs] [Times: user=3.85 sys=0.71, real=1.17 secs]
2019-03-28T10:10:52.481+0800: 1450.478: [CMS-concurrent-reset-start]
2019-03-28T10:10:52.491+0800: 1450.487: [CMS-concurrent-reset: 0.009/0.009 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
2019-03-28T10:10:53.341+0800: 1451.337: [GC (Allocation Failure)2019-03-28T10:10:53.341+0800: 1451.338: [ParNew: 1741934K->60753K(1887488K), 0.0540740 secs] 3451721K->1778397K(3984640K), 0.0546200 secs] [Times: user=0.18 sys=0.00, real=0.06 secs]
排查原因:
从一行CMS Initial Mark日志记录可以看到,这时的老年代容量为2097152K,在老年代内存使用达到1685579K时开始进行CMSGC。
用jstat看下CMSGC频率,jstat -gccause 28837 10000:
-gccause:显示各个分代内存使用率以及每一次进行GC的原因;
28837:jvm进程号(pid)
10000:刷新频率为10秒

因为每次CMSGC都会进行一次初始标记和最终标记阶段,这两个阶段都是暂停所有应用线程的,也就是我们常说的stop the world。而在jstat中会将这两个阶段都算成一次FGC。也就是说每执行一次CMSGC,jstat的FGC会加2。
从截图中可见,几乎每20秒都会执行一次CMSGC.
接下来用jmap看下各个分代的容量和实际使用量,使用jmap -heap pid(当前JVM进程号):
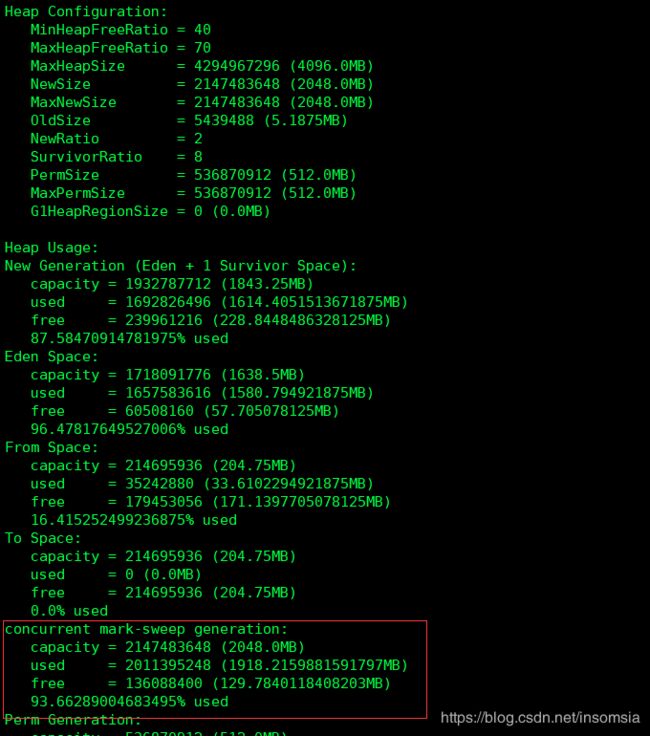
从图中可以看到整个堆(新生代+老年代)分配的内存为4096m,其中新生代和老年代各一半,都是2048m。而使用CMS作为垃圾收集器的老年代实际内存使用了1918mle,使用率已经高达百93.6%了。
CMSGC的条件,一般有下面几个条件判断,满足其一就进行CMSGC:
1、在设置了-XX:+UseCMSInitiatingOccupancyOnly参数的前提下,老年代当前使用率是否达到阈值CMSInitiatingOccupancyFraction;
2、判断当前新生代的对象是否能够全部顺利的晋升到老年代,如果不能,就提早触发一次老年代的收集;
3、是设置了-XX:+CMSClassUnloadingEnabled,而且_permGen永久代的内存使用率达到了阈值 CMSInitiatingPermOccupancyFraction,默认值是92
4、元空间扩容会触发CMSGC(元空间无论设定初始元空间大小为多少,实际最初只会提交21M)
5、配置了 ExplictGCInvokesConcurrent 且未配置 DisableExplicitGC 的情况下显示调用了 System.gc()
看老年代使用率这么高,感觉多半问题出在第一个判断上。用jcmd pid VM.flags查看JVM启动参数,得到参数如下:
-Xms4g
-Xmx4g
-Xmn2g
-XX:PermSize=256m
-XX:MaxPermSize=256m
-XX:+PrintGCCause
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:NativeMemoryTracking=summary
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=1
-XX:+CMSClassUnloadingEnabled
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
-XX:CMSInitiatingPermOccupancyFraction=90
而其中关键的两个配置在:
-XX:CMSInitiatingOccupancyFraction=70
-XX:+UseCMSInitiatingOccupancyOnly
这两个启动参数使JVM老年大使用率达到70时就开始做CMSGC了,而现在内存使用率高达93.6%,难怪一直在疯狂GC。
解决:
这里有三个办法:
1、调大整个堆分配的内存空间,调大老年代容量,使其使用率达不到 -XX:CMSInitiatingOccupancyFraction指定的值,自然就不会一直频繁执行CMSGC了。(但是这个受限于你服务器剩余物理内存)
2、调大 -XX:CMSInitiatingOccupancyFraction(不过现在使用率为93.6%,再往上调很容易就到达100%了,而且 -XX:CMSInitiatingOccupancyFraction过高的情况下很容易发生promotion failed和concurrent mode failure,不建议)
3、换个垃圾收集器,比如JDK1.7默认的并行垃圾收集器(Parallel GC),不会单独收集老年代内存空间,只有等到老年代满了之后才开始进行FGC来回收整个堆。
这里可能有人会说要看下是否有内存泄漏,emmm,之前确实将程序的内存快照dump下来分析过,但是没找到有内存泄漏的地方,当然也可能是自己功力有限看不出来~~