CNN看清世界——浅谈四个经典网络的差异
本文介绍4种经典的卷积神经网络CNN,分别是AlexNet,VGGNet,Google Inception Net和ResNet,这4种网络依照出现的先后顺序排列,深度和复杂度也依次递进,并且在ILSVRC分类赛上表现突出。具体的网络结构的细节不作赘述,想必大家可以在搜索引擎上都可以找到满意的答案。本文就4种网络的微妙改之处进做一下个人的见解。仅供参考,如有错误,还望指出,互勉实现进步。
首先,隆重介绍之前,先花点时间说一下LeNet5,其是最早的深层卷积神经网络之一,大概的网络结构示意图如图1-1所示。由于图像具有很强的空间相关性,直接使用独立的像素作为输入则利用不到这些相关性,而训练参数的卷积层是一种可以用少量参数在图像的多个位置上提取相似特征的有效方式。LeNet5在当时的成功可以归纳为以下几点:
1.首次将卷积用到神经网络中,目的在于降低计算的参数量。
2.使用非线性激活函数(双曲正切Tanh和S型Sigmoid)。
3.降采样(Down-Sampling)降低输出参数量,提高了模型的泛化能力。

图 1-1 LeNet-5结构示意图
2012年ILSVRC冠军AlexNet
AlexNet的结构示意图如1-2所示,每层的参数信息如图1-3所示,相比之前的卷积网络有了显著的改进,概括为以下几点:
1.使用ReLU作为CNN的激活函数,成功解决了Sigmoid在网络较深时的梯度弥散问题。
补充:梯度弥散问题是指Sigmoid函数在反向传播中梯度值会逐渐减小,经过多层的传递后会呈指数级急剧减小,因此梯度值在传递到前面几层时就变得非常小了。这种情况下,根据训练数据的反馈来更新神经网络的参数将会非常缓慢,基本起不到训练的作用。具体的求导过程可参考文章【1】
2.训练时使用Dropout(失活)随机忽略一部分神经元,以避免模型过拟合。
补充:过拟合是机器学习中一个常见的问题,它是指模型预测准确率在训练集上升高,但是在测试集上反而下降了,通常意味着模型的泛化性不好。Dropout可以理解成随机把一张图片50%的点删除掉(即随机将50%的点变成黑点),此时还可以识别出这张图片的类别,这种做法实质上等同于创造出了很多新的随机样本,通过增大样本量、减少特征数量来防止过拟合。
3.提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元。
4.数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以水平翻转的镜像),相当于增加了(256-224)*(256-224)*2=2048倍的数据量。这样做的目的主要是防止陷入参数众多的CNN过拟合中,并提高泛化能力。
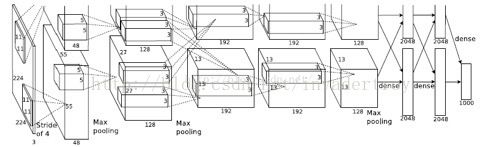
图1-2 AlexNet结构示意图

图1-3 AlexNet每层的超参数及参数数量
2014年ILSVRC亚军VGGNet
VGGNet构建了16~19层深的卷积神经网络,其拓展性很强,迁移到其他图片数据上的泛化性也非常好,VGGNet整个网络都使用了同样大小的卷积核尺寸(3*3)和最大池化尺寸(2*2),这也是该网络重要的特点之一。
1.通过两个3*3的卷积层串联相当于1个5*5的卷积层,如图1-4所示。前者使用的参数只有后者的(2*3*3)/(5*5)=0.72,参数明显减少。此外,两个3*3的卷几层拥有比1个5*5的卷几层更多的非线性变化(前者可以多使用一次ReLU激活函数),使得CNN对特征的学习能力更强。
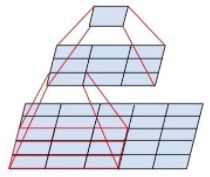
图 1-4 两个3*3的卷积层功能类似于一个5*5的卷积层
2.如图1-5所示,VGGNet基本上不再使用LRN,减少了内存的小消耗和计算时间。
补充:使用LRN效果不明显,并且会让前馈、反馈的速度大大下降(整体速度降到1/3)【2】

图1-5 VGGNet各级别网络结构图
3. 使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224*224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。基于这点,跟AlexNet只是策略不同,目的一致。
2014年ILSVRC冠军Google Inception Net
Google Inception Net在与VGGNet的比赛中,以较大的优势获得胜利。那届比赛的模型通常被称为Inception V1,它获胜的关键点在于控制了计算量和参数量。Inception V1有22层深,比VGGNet的19层还要深,但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12。目前,GoogleNets包括的模型有V1、V2、V3和带有ResNet特性的V4和Inception-ResNet-V2。
Inception V1:
Inception V1相比较之前的网络结构,有以下两方面的改进。
1.去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。
补充:全连接层几乎占据了AlexNet或AGGNet中90%的餐数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。
2.Inception V1精心设计的Inception Module提高了参数的利用效率,结构如图1-6所示。
补充,Inception module可以使网络的深度和宽度高效率地扩充,提升准确率且不至于过拟合。

图 1-6 Inception Module结构图
Inception V2:
Inception V2学习了VGGNet,主要有两个方面的改进。
1.用两个3*3的卷积代替5*5的大卷积,如何做到降低参数量在前文中提到过。
2.提出了著名的Batch Normalization(BN)方法,BN是一个非常有效的正则化方法,可以让大型卷及网络的训练速度加快很多倍,同时提高分类准确率。
补充:BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化处理,使输出规范化到N(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们可以有效的解决这个问题,不仅可以提高学习速率,也可以提高准确率。
Inception V3:
Inception V3网络也存在两方面的改造。
1.引入Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7*7卷积拆成1*7卷积和7*1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力。
2.优化了Inception Module的结构,V3版本的Inception Module有35*35、17*17和8*8三种结构。
Inception V4和Inception-ResNet-V2主要是结合了微软的ResNet,而ResNet会在下文中着重介绍,这里就不多做赘述。
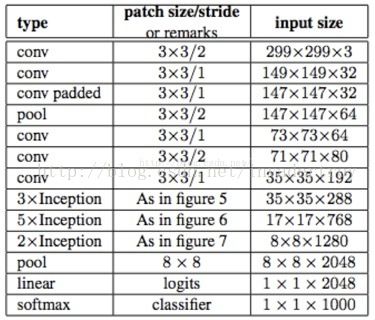
图1-7 Inception V3网络结构
2015年ILSVRC冠军ResNet
如上文所述,Inception V4和Inception-ResNet-V2都结合了ResNet网络的特性,足可见ResNet是一个推广性非常好的网络结构。ResNet一个最重要的特点是加深了神经网络的深度,但是网络越深其训练难度越大。ResNet最初的灵感出自这个问题:在不断加神经网络的深度时,会出现一个Degradation的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。
假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个y=x的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的全等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。
假定某段神经网络的输入是x,期望输出是H(x),如果直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x)=H(x)-x。如图1-8所示。
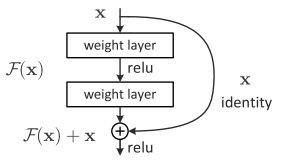
图1-8 ResNet的残差学习模块
传统的卷几层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
个人认为残差模块解决了网络在深度上的问题,使网络的层数不断加深;同Dropout有异曲同工之处,其实解决网络在广度上的问题,使网络存在更多的随机性。
至此为止,对四种网络的差异和区别做了详细的阐释,如果想要对四种网络了解的更深,可以参考文献【2】和文献【3】。路漫漫其修远兮,吾将上下而求索。
【1】http://blog.csdn.net/leo_xu06/article/details/53708647
【2】TensorFlow实战(P101)——黄文坚 唐源著
【3】https://www.leiphone.com/news/201702/dgpHuriVJHTPqqtT.html?ulu-rcmd=0_5021df_hot_1_baa6353dc902479b8a04a08b5ffa89c8