X86_64汇编与IA32比较
什么是X86-64?
所谓IA32就是“Intel32位体系结构”(Intel Architecture 32-bit),而我们常说的X86-64就是IA32的64为拓展。
数据格式
| C声明 |
Intel数据类型 |
汇编代码后缀 |
大小(字节) |
| char |
字节 |
b |
1 |
| short |
字 |
w |
2 |
| int |
双字 |
l |
4 |
| long int |
双字 |
l |
4 |
| long long int |
—— |
—— |
4 |
| char * |
双字 |
l |
4 |
| float |
单精度 |
s |
4 |
| double |
双精度 |
l |
8 |
| long double |
扩展精度 |
t |
10/12 |
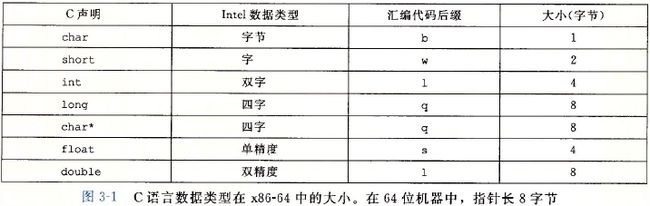
C语言数据类型在IA32中的大小
其实x86-64的汇编指令也是从8086来的,可以说是对8086的命令进行了一些扩展,例如数据传输命令:movb(传送字节)、movw(传送字)、movl(传送双字)和movq(传送四字)。后缀就是表示传送数据的大小。
访问信息
一个X86-64的CPU包含一组16个存储64位值的通用目的寄存器,对于IA32来说,是一组8个存储32位值的通用寄存器,下图红框中即为IA32的寄存器。而且相对于8086,IA32是在寄存器前面加了%e的前缀,X86-64是加了%r的前缀。
操作数指示符
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值以及放置结果的目的位置。操作数被分为三类。
第一种类型是立即数(immediate),用来表示常数值。立即数的书写格式是‘$’后面跟一个用标准C表示法表示的整数,比如$23或$0x1F。
第二种类型是寄存器(register),它表示某个寄存器的内容。如下图中,我们用符号ra来表示任意寄存器a,用引用R[ra]来表示它的值。
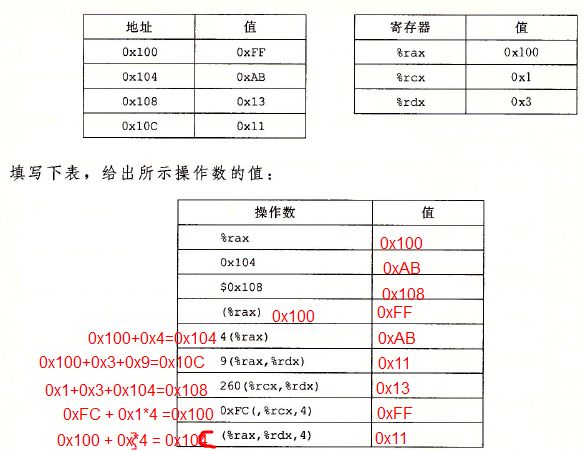
第三种操作数是内存引用,它会根据计算出来的地址(通常成为有效地址)访问某个内存位置。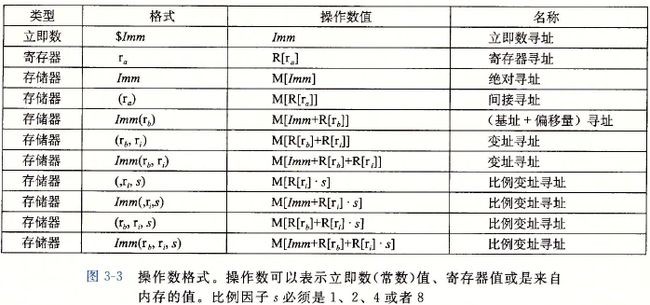
数据传送指令
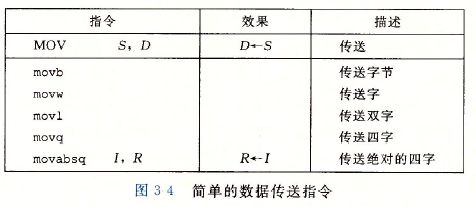

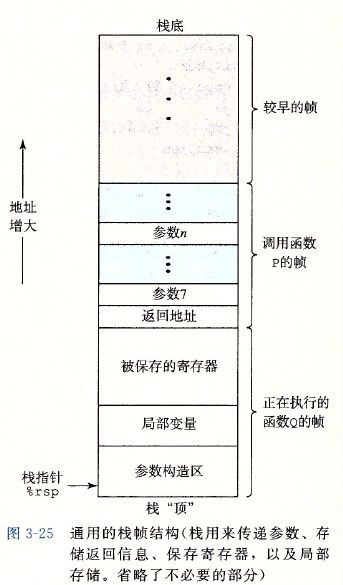
目的操作数指定一个位置,要么是一个寄存器,要么是一个存储器地址。不论是IA32还是x86-64,传送指令的两个操作数不能都指向内存位置。也就是说将一个值从一个内存位置复制到另一个内存位置需要两条指令:第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的位置。
注意,第一个是源操作数,第二个是目的操作数。
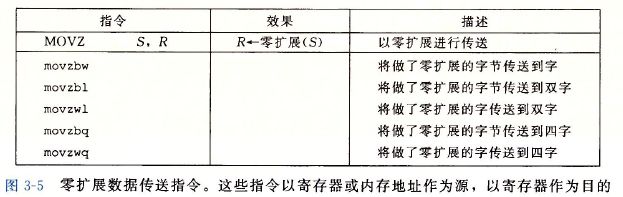
MOVZ和MOVS指令类都是将一个较小的源数据复制到一个较大的数据位置,高位用符号位扩展(MOVS)或者零扩展(MOVZ)进行扩充。用符号位扩展,目的位置的所有高位用源值的最高位数值进行填充。用零扩展,所有高位都用零填充。
压入和弹出数据栈

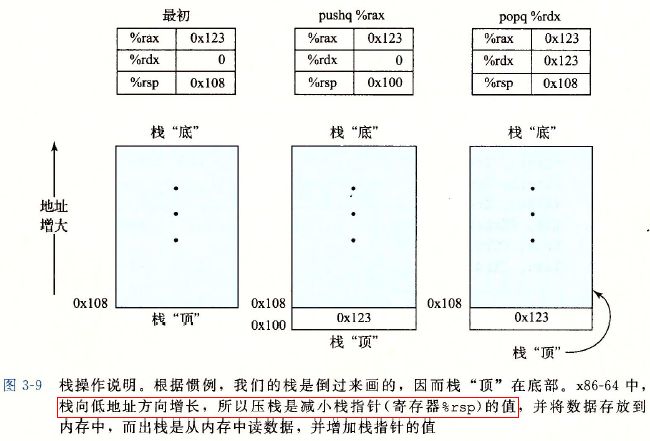
对于IA32来说,它的入栈和出栈的命令分别是pushl和popl,而且数据是32位的。由于栈的顶部定在地址减小的方向,那么在入栈的时候,需要将%rsp(%esp)的值减小8(4),然后压入数据,让在栈顶;对于出栈,操作则相反。
算术与逻辑操作
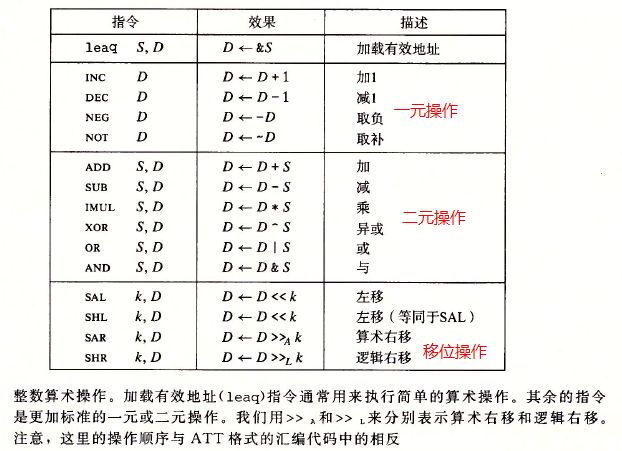
加载有效地址
加载有效地址(load effective address)指令leadq实际上是movq指令的变形。它的指令形式是从内存读数据到寄存器,但实际上它根本没有引用内存。它的第一个操作数看上去是一个内存引用,但该指令并不是从指令的位置读入数据,而是将有效地址写入到目的操作数。例如寄存器%rdx的值是x,那么指令leaq 7(%rdx,%rdx,4),%rax将设置寄存器%rax的值为5x+7。
一元和二元操作
对于一元操作,这个操作数既是源,又是目的。这个操作数可以是一个寄存器,也可以是一个寄存器位置。
对于二元操作,注意源操作数是第一个,目的操作数是第二个。
移位操作
对于移位操作来说,SHL和SAL效果是一样的,都是将右边填上0。最大的区别在右移的操作,对于SAR执行算术移位(填上符号位),而SHR执行逻辑移位(填上0)。移位操作的目的操作数可以是一耳光寄存器或是一个内存位置。
特殊的算术操作

控制
条件码
除了整数寄存器,CPU中还维护着一组单个位的条件码(conditioncode)寄存器,它们描述了最近算术或逻辑操作的属性。

CMP指令根据它们的两个操作数之差来设置条件码。除了只设置条件码而不更新目标寄存器外,CMP指令和SUB指令的行为是一样的。
TEST指令的行为与AND指令一样,除了它们只设置条件码而不改变目的寄存器的值。
访问条件码
条件码通常不会直接读取,常用的使用方法有三种:
<1>可以根据条件码的某种组合,将一个字节设置为0或者1;
<2>可以条件跳转到程序的某个其他的部分;
<3>可以有条件地传送数据。

一条SET指令的目的操作数是低位单字节寄存器元素之一,或者一个字节的内存位置,指令会将这个字节设置成0或者1。为了得到一个32位或64位结果,我们必须对高位清零。
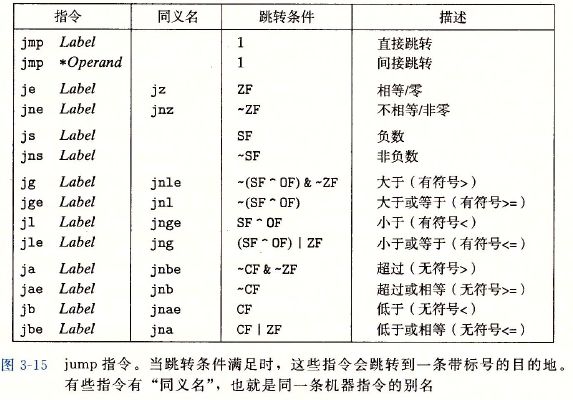
跳转指令及其编码
jmp指令是无条件跳转,它可以使直接跳转,即跳转目标是作为指令的一部分编码的;也可以是间接跳转,即跳转目标是从寄存器或寄存器位置中读出的。间接跳转的写法是“*”后面跟一个操作数指示符。

过程(这个词怎么看怎么别扭)
运行时栈
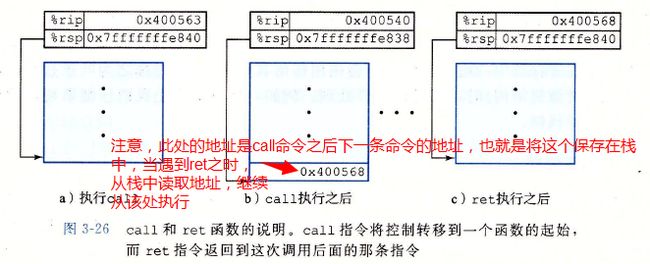
转移控制

Call指令有一个目标,即指明被调用过程起始的指令地址。同跳转一样,调用可以是直接的,也可以是间接的。在汇编底码中,直接调用的目标是一个标号,而间接调用的目标是*后面跟一个操作数指示符。
数组的分配与访问
C语言中的数组是一种将标量数据聚集成更大数据类型的方式。C语言的一个不同寻常的特点是可以产生指向数组中元素的指针,并对这些指针进行运算。在机器代码中,这些指针会被翻译成地址计算。
基本原则
对于数据类型T和整型常熟N,声明如下:
T A[N];
起始位置表示为xA。这个声明有两个效果。首先,它在内存中分配一个L*N字节的连续区域,这里L是数据类型T的大小(单位为字节)。其次,它引入了标识符A,可以用A来作为指向数组开头的指针,这个指针的值就是xA。可以用0~N-1的整数索引来访问该数组元素。数组元素i会被存放在地址为xA+L*i的地方。
指针的运算


嵌套的数组

要访问多维数组的元素,编译器会以数组起始为基地址,偏移量为索引,产生计算期望的元素的偏移量,然后使用某种MOV指令。通常来说,对于一个声明如下的数组:
TD[R][C]
它的数组元素D[i][j]的内存地址为
&D[i][j]=xD+L(C*i+j)
这里,L是数据类型T以字节为单位的大小。
关于结构与联合
结构(structure),用关键字struct来声明,将多个对象集合到一个单位中;联合(union),用关键字union来声明,允许用几种不同的类型来引用一个对象。
分别声明结构体和联合如下:
struct S3{
char c;
int i[2];
double v;
};
union S3{
char c;
int i[2];
double v;
};

也就是说对于结构体,它的大小是所有数据总的大小,这其中还涉及到数据对齐;而联合的大小由它其中最大的那个数据决定,例如上面就是由double来决定的。
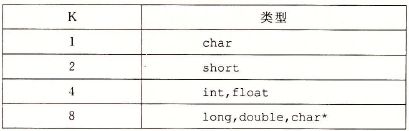
数据对齐
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某些对象的地址必须是某个K(通常是2、4或8)的倍数。这种对齐限制简化了形成处理器和内存系统之间接口的硬件设计。无论数据是否对齐,x86-64硬件都能正确工作。不过,对齐数据可以提高内存系统的性能。对齐原则是任何K字节的基本对象的地址必须是K的倍数。对于这条原则会得到如下对齐: