深度学习模型转换
前言
当用户基于各种原因学习并使用了一种框架的时候,常常会发现应用或者再训练的场景改变了,比如用户用 Caffe 训练好了一个图像识别的模型,但是生产环境是使用 TensorFlow 做预测。再比如某机构主要以TensorFlow作为基础的深度学习开发框架,现在有一个深度算法项目,需要将其部署在移动设备上,并希望使用速度较优的ncnn前向框架,以观测变现等等。传统地我们可能需要用tf重写Caffe,或用Caffe2重写tf,然后再训练参数,试想这将是一个多么耗时耗力的过程。
因此,深度学习模型转换技术在AI工程化中将变得越来越重要。本人花了将近半个月的时间完成现有模型转换的技术调研,并将模型转换技术涉及到知识点以及实际转换时容易遇到的问题梳理成多个章节进行粗劣地讲解。具体分为深度学习模型简介、深度学习模型转换技术和模型转换之实战这三部分内容,并在文章的最后作了简单的总结。
深度学习模型简介
深度学习模型是指一种包含深度神经网络结构的机器学习模型。算法工程师使用某种深度学习框架构建好模型,经调参和训练优化后,将最终生成的网络参数和模型结构一并保存,得到的文件即为可用于前向推理的模型文件。不同深度学习框架训练得到的模型文件的格式不尽相同,但完整的模型文件一般都包含了张量数据、运算单元和计算图等信息。
1.1 张量(Tensor)
张量(Tensor)是深度学习系统的数据容器,它可以理解为矩阵向任意维度的扩展。仅包含一个数字的张量叫作标量(Scalar,也叫标量张量、零维张量、0D张量);数字组成的数组叫作向量(Vector)或一维张量(1D张量),而向量组成的数组叫作矩阵(Matrix)或二维张量(2D张量);将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体;将多个3D张量组合成一个数组,可以创建一个4D张量,以此类推。深度学习处理的一般是0D到4D 的张量,但处理视频数据时可能会遇到5D张量。
1.2 运算单元(Operation/Operator)
运算单元(Operation/Operator,常见的翻译还有计算单元、操作符、算子等)表示一种符号化的运算过程,是主流深度学习框架的基本单元,即图中的节点。它的输入和输出都是张量(Tensor)。所有计算机程序最终都可以简化为二进制输入上的一些二进制运算(AND、OR、NOR等),类似地,深度神经网络学到的所有变换也都可以简化为数值数据张量上的一些张量运算(Tensor operation),如图1的tf.add函数为TensorFlow一个简单的加法运算单元。

图1 TensorFlow的add运算单元
常见的运算单元有Add、BatchNormalization 、Conv、GRU、LRN、LSTM、MaxPool、Relu、RNN、Softmax等。
1.3 计算图(Graph)
1.3.1 基本概念
计算图(Graph,又称数据流图)被定义为有向无环图( directed acyclic graph),张量和运算单元都是图中的对象,运算单元是图的节点,张量是图的边上流动的数据。无环( acyclic)这个限定词很重要,即这些图不能有循环。张量 x 不能成为生成 x 的某一层的输入。唯一允许的处理循环(即循环连接)是循环层的内部循环。
深度学习框架使用计算图将计算表示为独立的指令之间的依赖关系,我们可以通俗地将计算图理解为表达和评估数学表达式的一种方式。例如,这里有个简单的数学公式:
g = ( x + y ) ∗ z
我们可以绘制上述方程的计算图如下:
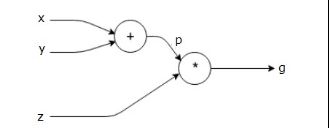
图2 简单的计算图示例
上述示例图虽然简单,但它包含了前向推理模型所需的基本要素。所谓前向传播,可简单理解为模型将张量(x、y、z)从左侧输入向前传递(即有序接受运算单元的处理)到右侧输出,最终得到推理值(g)。
常见的深度神经网络模型(Inception、ResNet等)包含了一些较为复杂的运算单元,比如残差卷积单元、池化、非线性激活、Bottleneck等节点(PS:通常这些节点也可能归属于网络的某一层layer,一个layer可能包含1个或多个基本运算单元)。此外,涉及训练的模型需包含损失函数、梯度计算等反向传播所必须的运算单元。所谓反向传播,指的是计算神经网络参数梯度的方法。总的来说,反向传播根据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。反向传播的数学原理较为复杂,有兴趣的同学可参考这篇博文: https://blog.csdn.net/u013527419/article/details/70184690
1.3.2 命名空间
一些深度学习框架的计算对象会定义一个命名空间(为其包含的 Operation 对象)。这里以TensorFlow为例,它会自动为您的图中的每个指令选择一个唯一名称,但您也可以指定描述性名称,使您的程序阅读和调试起来更轻松。TensorFlow API 提供两种方法来覆盖操作名称:
如果 API 函数会创建新的 tf.Operation 或返回新的 tf.Tensor,则会接受可选 name 参数。例如,tf.constant(42.0, name="answer") 会创建一个新的 tf.Operation(名为 "answer")并返回一个 tf.Tensor(名为 "answer:0")。如果默认图已包含名为 "answer" 的操作,则 TensorFlow 会在名称上附加 "_1"、"_2" 等字符,以便让名称具有唯一性。
借助 tf.name_scope 函数,您可以向在特定上下文中创建的所有操作添加名称作用域前缀。当前名称作用域前缀是一个用 "/" 分隔的名称列表,其中包含所有活跃 tf.name_scope 上下文管理器的名称。如果某个名称作用域已在当前上下文中被占用,TensorFlow 将在该作用域上附加 "_1"、"_2" 等字符。例如:
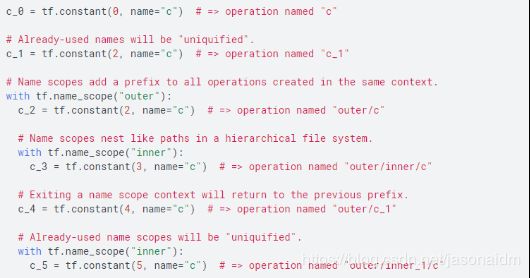
图3 使用TensorFlow框架构建运算单元示例
1.4 经典的深度神经网络模型
这里简单介绍一些经典的深度神经网络模型其中CV领域的模型之间的关系可参考图4。
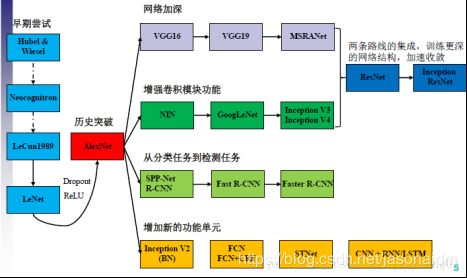
图4 常用的计算机视觉模型
1.4.1 AlexNet模型
2012年,Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军。AlexNet可以说是具有历史意义的一个网络结构,在此之前,深度学习已经沉寂了很长时间,自2012年AlexNet诞生之后,后面的ImageNet冠军都是用卷积神经网络(CNN)来做的,并且层次越来越深,使得CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。
1.4.2 VGG模型
VGG又分为VGG16和VGG19,分别在AlexNet的基础上将层数增加到16和19层,它除了在识别方面很优秀之外,对图像的目标检测也有很好的识别效果,是目标检测领域的较早期模型。
1.4.3 GoogLeNet模型
GoogLeNet除了层数加深到22层以外,主要的创新在于它的Inception,这是一种网中网(Network In Network) 的结构,即原来的节点也是一个网络。用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2到3倍的性能提升。
1.4.4 ResNet模型
ResNet直接将深度拉到了152层, 其主要的创新在于残差网络, 其实这个网络的提出本质上是要解决层次比较深时无法训练的问题。 这种借鉴了Highway Network思想的网络, 相当于旁边专门开个通道使得输入可以直达输出, 而优化的目标由原来的拟合输出H(x) 变成输出和输入的差H(x)-x, 其中H(x) 是某一层原始的期望映射输出, x是输入。
1.4.5 MobileNet模型
2017年,Google提出的适用于手机端的神经网络模型——MobileNet。MobileNet的精华在于卷积方式——Depthwise separable convolution;采用深度可分离卷积会涉及到两个超参数来减少参数量和计算量:
- 宽度乘数(width multiplier):[减少输入和输出的channels]
- 分辨率乘数(resolution multiplier):[减少输入和输出的feature map大小]
Mobilenet可以应用于多个领域:目标检测,分类,跟踪等诸多领域。用于移动和嵌入式视觉应用。
1.4.6 BERT模型
2018年年底,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步。BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进率5.6%)等。BERT模型是以Transformer编码器来表示的NLP词向量模型。相信2019年会有越来越多的NLP模型潜入BERT技术,并刷新各子领域的state-of-the-art!
1.5 主流的深度学习框架
目前PC端主流的深度学习框架有TensorFlow、Keras、Pytorch、Caffe、CNTK等(如图5所示)。

图5 主流的深度学习框架
根据各框架在2018年度的热度排序(如图6所示),在这简单介绍流行度排前四的深度学习框架:
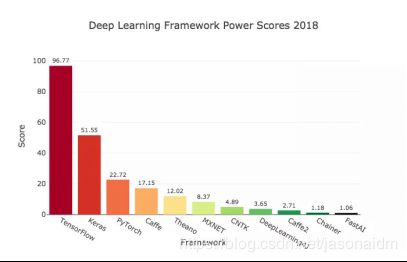
图6 各深度学习框架2018年热度比较
1.5.1 TensorFlow框架
TensorFlow 是一个开放源代码软件库,是很多主流框架的基础或者依赖。TensorFlow背后因站着Google,一经推出就获得了极大的关注,并迅速成为如今用户最多的深度学习框架。该框架几乎能满足所有机器学习开发的功能, 但是也有由于其功能代码过于底层,学习成本高,代码冗繁,编程逻辑与常规不同等缺点。
1.5.2 Keras框架
Keras是一个高层神经网络API,由纯Python编写而成并使用TensorFlow、Theano及CNTK作为后端。Keras为支持快速实验而生,能够把想法迅速转换为结果。Keras应该是深度学习框架之中最容易上手的一个,它提供了一致而简洁的API, 能够极大地减少一般应用下用户的工作量,避免用户重复造轮子。
1.5.3 Pytorch框架
2017年1月,Facebook人工智能研究院(FAIR)团队在GitHub上开源了Pytorch,并迅速占领GitHub热度榜榜首。Pytorch是由Lua Torch发展而来,但它不是简单地对封装Lua Torch提供Python接口,而是对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统。虽然相比tf要年轻很多,但其流行度的增速十分迅猛,目前已成为当下最流行的动态图框架。它支持TensorFlow尚不支持的一些机制。
Pytorch的设计追求最少的封装,尽量避免重复造轮子。不像TensorFlow中充斥着session、graph、operation、name_scope、variable、tensor、layer等全新的概念,Pytorch的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个抽象之间联系紧密,可以同时进行修改和操作。简洁的设计带来的另外一个好处就是代码易于理解。Pytorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得Pytorch的源码十分易于阅读。
1.5.4 Caffe框架
Caffe全称为Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架。Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络(通过写protobuf配置文件定义)。Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但对时间序列RNN、LSTM等支持得不是特别充分。Caffe的一大优势是拥有大量的训练好的经典模型(AlexNet、VGG、Inception)乃至其他state-of-the-art (ResNet等)的模型,收藏在它的Model Zoo(github.com/BVLC/Caffe/wiki/Model-Zoo)。
1.5.5 移动端框架
在这顺便简单介绍一下目前移动端流行的深度学习框架。目前的移动框架一般都是前向推理框架,即只含推理(inference)功能,使用的模型文件需要通过离线的方式训练得到。
Caffe2: Facebook新的开源深度学习框架。与之前的Pytorch不同,Caffe2专门用于将深度学习移植到移动应用程序。Caffe2官方教程以Python语言为主,是一个轻量化的深度学习算法框架,为移动端实时计算做了很多优化,方便机器学习算法和模型大规模部署在移动设备。
腾讯的FeatherCNN和ncnn:这两个框架都是腾讯出的,FeatherCNN来自腾讯AI平台部,ncnn来自腾讯优图。ncnn开源早点,文档、相关代码丰富一些,目前流行度很高。ncnn的官网宣称ncnn目前已支持Caffe2和Pytorch的模型转换。
小米的 MACE:它有几个特点:异构加速、汇编级优化、支持各种框架的模型转换,该框架还支持GPU运算,且不限于高通,这点很通用,很好,比如瑞芯微的RK3299就可以同时发挥出cpu和GPU的好处。
TFLite:无缝支持通过TensorFlow训练好的神经网络模型。只需要几个简单的步骤就可以完成桌面模型到移动端模型的转换。但通常情况下TFLite框架的运行效率要比上述的一些框架低。
深度学习模型转换技术
目前的转换技术在设计思路上主要存在两种差异,一种是直接将模型从现有框架转换为适合目标框架使用的格式,我们在这称此技术为直接转换技术;另外一种是针对深度学习设计一种开放式的文件规范,而主流深度学习框架最终都能实现对这种规范标准的支持,这种技术的代表是开放式神经网络切换框架——ONNX技术。
2.1 直接转换技术
转换器实现模型文件转换的基本原理涉及一下几步:
- 读取载入A框架生成的模型文件,读取并识别模型网络中的张量数据的类型/格式、运算单元的类型和参数、计算图的结构和命名规范,以及它们之间的其他关联信息。
- 将第一步识别得到的模型结构和模型参数信息翻译成B框架支持的代码格式,比如B框架指Pytorch时,relu激活层(运算单元)这一信息可翻译为torch.nn.ReLu()。当然,运算单元较为复杂时(特别是带较多参数的情况),可在转换器中封装一个对应的运算单元转换函数来实现B框架的运算单元骨架。
- 在B框架下保存模型,即可得到B框架支持的模型文件。
转换器如能将现有模型文件直接转换为生产环境支持的格式,这在操作上会给使用者带来很大的便利。但因市面上存在的深度学习框架众多(超过10种),目前还没有一种转换器能够实现所有模型文件之间的转换。我在这列出部分可实现不同框架迁移的模型转换器,如图7所示。更完整的列表请参考:https://github.com/jasonaidm/deep-learning-model-convertor
可以看出,目前既有机构,也有个人开发一些特定场景的模型转换器。其中最有名的模型转换器当属微软于2018年开源的MMdnn框架。下面我将多花点篇幅来介绍这个框架。
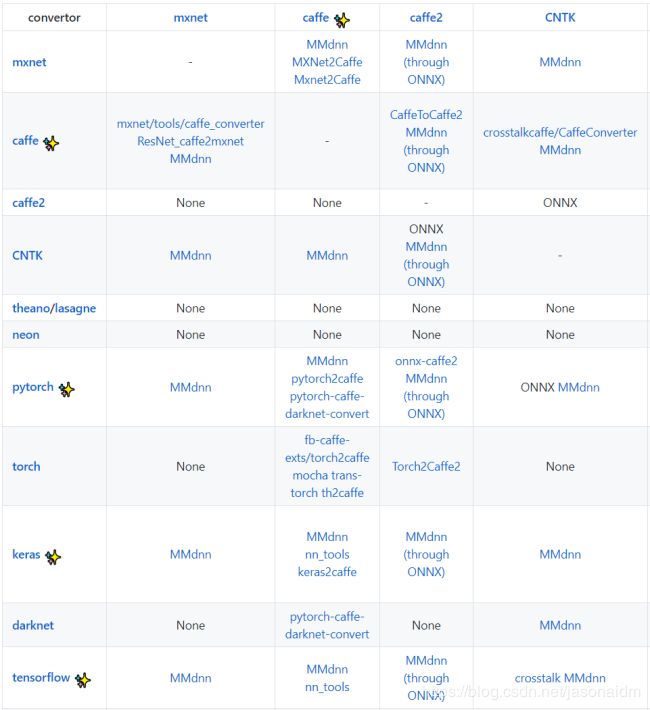
图7 不同模型文件的转换器
MMdnn实质上是一套用于转换、可视化深度神经网络模型的综合性解决方案。MMdnn中的「MM」代表模型管理,「dnn」的意思是深度神经网络,它能够通过中间表征格式让训练模型在Caffe、Keras、MXNet、TensorFlow、CNTK、Pytorch和CoreML等深度学习框架之间转换(如图8所示),帮助开发者实现模型在不同框架之间的交互。MMdnn主要有以下特征:
- 模型文件转换器,不同的框架间转换DNN模型
- 模型代码片段生成器,生成适合不同框架的代码
- 模型可视化,DNN网络结构和框架参数可视化
- 模型兼容性测试(正在进行中)
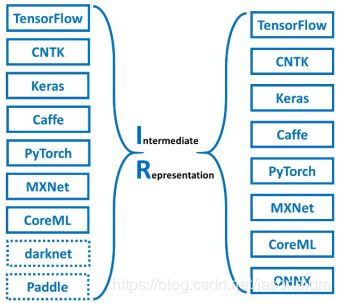
图8 MMdnn系统目前支持的深度学习框架
需要强调的是,强如背靠微软的MMdnn转换器,也仅支持部分模型的转换,具体原因我们在3.3节有作较为详细阐述。MMdnn在一些ImageNet模型上有做测试(如图9所示),但官方没有提及NLP项目上的测试情况。阅读一些模型转换器文档列出的运算单元支持表发现, MMdnn尚不支持一些较新的运算单元,比如PReLu、Bottleneck、BatchNormalization等,而诸如BiLSTM、Mask等自然语言常用的operators更是缺乏,可以推断,仅仅依靠MMdnn的原始骨架,只能完成小部分的模型转换。
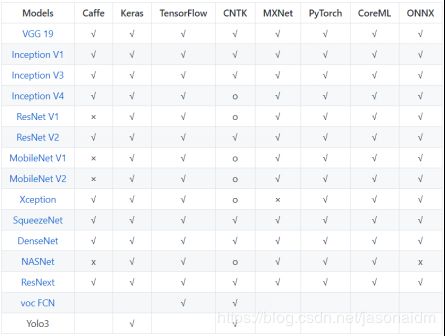
图9 MMdnn在一些ImageNet模型上测试的结果
2.2 ONNX技术
2.2.1简介
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,形成强大的深度学习开源联盟,并将源代码托管在Github上(地址: https://github.com/ONNX),谷歌一直在围绕TensorFlow和谷歌云的深度学习开发自己的独立生态,所以暂时不太会加入到这个联盟中来。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, Pytorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK, TensorFlow 也有非官方的支持ONNX,目前处于实验阶段。
ONNX 定义了一种可扩展的计算图模型、一系列内置的运算单元(OP)和标准数据类型。每一个计算流图都定义为由节点组成的列表,并构建有向无环图。其中每一个节点都有一个或多个输入与输出,每一个节点称之为一个 OP。这相当于一种通用的计算图,不同深度学习框架构建的计算图都能转化为它。事实上,上节介绍的一些模型文件转换器其内部实现机制也借用了ONNX技术。目前ONNX支持的框架和基于ONNX的转换器如下图10所示。具体可参考此链接:http://ONNX.ai/supported-tools

图10 ONNX支持的框架和转换器
2.2.2 ONNX结构规范
(此部分内容大部分直译官方文档:https://github.com/onnx/onnx/blob/master/docs/IR.md)
模型结构的主要目的是将元数据(meta data)与图形(graph)相关联,图形包含所有可执行元素。首先,读取模型文件时需使用元数据,实现提供所需的信息,以确定它是否能够执行模型、生成日志消息、错误报告等功能。此外元数据对工具很有用,例如IDE和模型库,它需要它来告知用户给定模型的目的和特征。
每个model具有以下组件:

2.2.2.1 ONNX运算单元集
每个模型必须明确命名运算单元,命名方式依赖于运算单元的功能。运算单元集定义可用的操作符、版本和状态。所有模型都隐式导入默认的ONNX运算单元集。
运算单元集的属性:
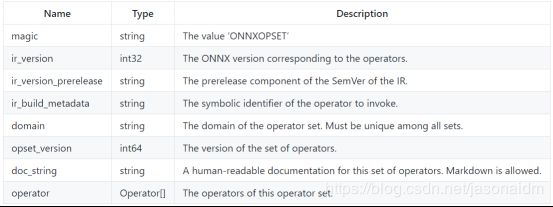
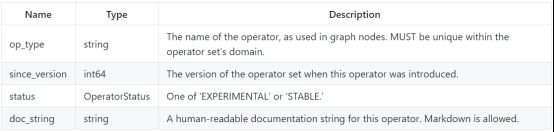
2.2.2.2 ONNX运算单元
运算单元定义的属性:
2.2.2.3 ONNX序列化图(Graph)
序列化图由一组元数据字段(metadata),模型参数列表(a list of model parameters,)和计算节点列表组成(a list of computation nodes)。每个计算数据流图被构造为拓扑排序的节点列表,这些节点形成图形,其必须是无循环的。 每个节点代表对运算单元的调用。 每个节点具有零个或多个输入以及一个或多个输出。
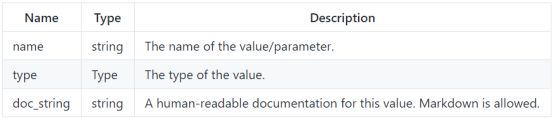
图表具有以下属性:

每个图形必须定义其输入和输出的名称和类型,它们被指定为“值信息”结构,具有以下属性:
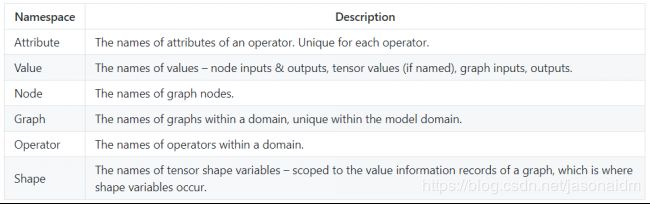
2.2.2.4 图的命名规范
所有名称必须遵守C标识符语法规则。节点,输入,输出,初始化器和属性的名称被组织到多个命名空间中。在命名空间内,每个给定图形的每个名称必须是唯一的。
2.2.2.5 标准化数据类型
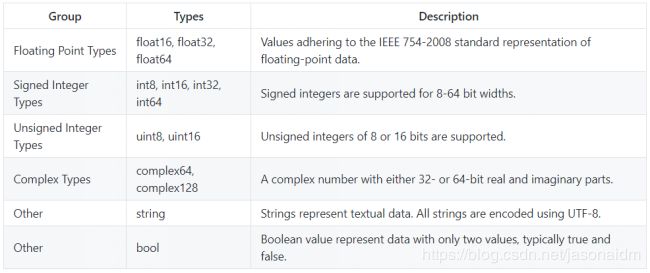
数据类型存在两种官方的ONNX变体,两者在支持的数据类型和支持的运算单元中存在区别。对于支持的数据类型,ONNX定义只识别张量作为输入和输出类型。而经典的机器学习扩展——ONNX-ML,还可识别序列和maps。对于计算图graph和节点node的输入和输出、计算图的初始化,ONNX支持 原始数字、字符串和布尔类型,但必须用作张量的元素。
张量元素类型:
其他规范如Input / Output Data Types、Attribute Types等都在官网上有申明,这里就不再罗列了。
2.2.3 ONNX支持的运算单元(Operator)
ONNX拥有非常明确的、严格的神经网络框架标准,并且拥有非常详细的官方文档。此外,它还支持非常多的运算单元,而且还在高频地增加新的operators。目前官网列出的operators已达134种,具体名单请参考:https://github.com/onnx/onnx/blob/master/docs/Operators.md
2.2.4 新增operator
ONNX支持用户新增operator,以解决特殊场景特殊模型的转换,并给出新增operator的规范步骤:https://github.com/onnx/onnx/blob/master/docs/AddNewOp.md
模型转换之实践
后续更新...