Linux协议栈-netfilter(4)-期望连接
传统的conntrack和NAT处理只对IP层和传输层头部进行转换处理,但是一些应用层协议,在协议数据报文中包含了地址信息。为了使得这些应用也能透明地完成NAT转换,NAT使用一种称作ALG的技术,它能对这些应用程序在通信时所包含的地址信息也进行相应的NAT转换。
例如:对于FTP协议的PORT/PASV命令,在数据包载荷中需要包含地址信息,并且数据包如果需要做NAT,那应用层数据部分的地址也需要做NAT转换。实现这种转换,需要在普通的conntrack条目基础上增加一个expect conntrack(期望连接)来记录这个连接上的额外信息。
本文将以tftp和ftp协议举例期望连接。
1. 以tftp举例期望连接
tftp是基于UDP的应用层协议,用于简单的文件传输。
1.1 实验拓扑
测试拓扑如下,在路由器R1上通过tftp请求PC1上的文件“ethreg.sh”,R1和PC1之间有一个路由器R2让R1位于局域网中,PC1位于公网中。在R1上输入以下命令:
tftp –gr ethreg.sh 192.168.10.100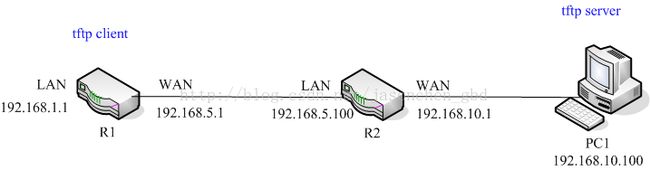
在PC1上抓包结果如下:

第一个数据包为read request请求,数据包方向为R1->PC1(192.168.1.1:50173-> 192.168.10.100:69),其中69中tftp端口号,数据包传输过程经过了SNAT转换。
数据部分共经过两次传输完成,发送数据方向为PC1->R1(192.168.10.100:3873-> 192.168.1.1:50173),数据包在传输过程经过了DNAT转换。
可见传输数据时,第一个包是从Server端即PC1发出的,而PC1处在NAT外面,而通常情况下,这样的数据包是无法通过NAT达到局域网的,因为路由器R2上并没有记录这个连接做NAT的连接条目,NAT的作用之一就是隐藏局域网中的主机。
下面来看一下tftp协议如何依靠期望连接实现数据包的NAT转换的。
1.2 tftp协议的期望连接实现
在编译内核时打开CONFIG_NF_CONNTRACK_TFTP宏,使其以模块形式编译到内核,来支持tftp建立期望连接。该模块的init函数为nf_conntrack_tftp_init(),它初始化了一个conntrack helper方法,并将其注册到helper extension的链表中去(conntrack extensions见前面的博文)。
static struct nf_conntrack_helper tftp[MAX_PORTS][2]__read_mostly;tftp conntrack模块的初始化函数:
static int __init nf_conntrack_tftp_init(void)
{
int i, j, ret;
char *tmpname;
if (ports_c == 0)
ports[ports_c++] = TFTP_PORT;
for (i = 0; i < ports_c; i++) {
memset(&tftp[i], 0, sizeof(tftp[i]));
tftp[i][0].tuple.src.l3num = AF_INET;
tftp[i][1].tuple.src.l3num = AF_INET6;
for (j = 0; j < 2; j++) {
tftp[i][j].tuple.dst.protonum = IPPROTO_UDP;
tftp[i][j].tuple.src.u.udp.port = htons(ports[i]);
tftp[i][j].expect_policy = &tftp_exp_policy;
tftp[i][j].me = THIS_MODULE;
tftp[i][j].help = tftp_help;
tmpname = &tftp_names[i][j][0];
if (ports[i] == TFTP_PORT)
sprintf(tmpname, "tftp");
else
sprintf(tmpname, "tftp-%u", i);
tftp[i][j].name = tmpname;
ret = nf_conntrack_helper_register(&tftp[i][j]);
if (ret) {
printk("nf_ct_tftp: failed to register helper "
"for pf: %u port: %u\n",
tftp[i][j].tuple.src.l3num, ports[i]);
nf_conntrack_tftp_fini();
return ret;
}
}
}
return 0;
}
tftp_exp_policy的定义如下:
static const struct nf_conntrack_expect_policy tftp_exp_policy = {
.max_expected = 1,
.timeout = 5 * 60,
};
在init函数中对nf_conntrack_helper结构体的tuple进行了部分初始化,由于tftp数据包的协议和port是固定的,所以可以预先赋值。同时注册了help函数为tftp_help(),函数定义如下,注意,参数skb是当前处理的数据包,ct是相应的conntrack,处理tftp read/write request的时候会进入这个函数。
static int tftp_help(struct sk_buff *skb,
unsigned int protoff,
struct nf_conn *ct,
enum ip_conntrack_info ctinfo)
{
const struct tftphdr *tfh;
struct tftphdr _tftph;
struct nf_conntrack_expect *exp;
struct nf_conntrack_tuple *tuple;
unsigned int ret = NF_ACCEPT;
typeof(nf_nat_tftp_hook) nf_nat_tftp;
/* 获得tftp首部 */
tfh = skb_header_pointer(skb, protoff + sizeof(struct udphdr),
sizeof(_tftph), &_tftph);
if (tfh == NULL)
return NF_ACCEPT;
/* 从tftp首部中获得操作码 */
switch (ntohs(tfh->opcode)) {
case TFTP_OPCODE_READ: /* read请求 */
case TFTP_OPCODE_WRITE: /* write请求 */
/* RRQ and WRQ works the same way */
/*
在nf_ct_expect_cachep上分配一个expect连接,同时赋两个值:
exp->master = ct,
exp->use = 1。
*/
exp = nf_ct_expect_alloc(ct);
if (exp == NULL)
return NF_DROP;
/* 根据ct初始化expect */
tuple = &ct->tuplehash[IP_CT_DIR_REPLY].tuple;
nf_ct_expect_init(exp, NF_CT_EXPECT_CLASS_DEFAULT,
nf_ct_l3num(ct),
&tuple->src.u3, &tuple->dst.u3,
IPPROTO_UDP, NULL, &tuple->dst.u.udp.port);
/* 指向help() -- nf_nat_tftp.c */
nf_nat_tftp = rcu_dereference(nf_nat_tftp_hook);
/* 数据包需要走NAT时,if成立,局域网传输则else成立。 */
if (nf_nat_tftp && ct->status & IPS_NAT_MASK)
ret = nf_nat_tftp(skb, ctinfo, exp);
else if (nf_ct_expect_related(exp) != 0)
ret = NF_DROP;
nf_ct_expect_put(exp);
break;
case TFTP_OPCODE_DATA: /* 数据 */
case TFTP_OPCODE_ACK: /* 数据的ACK */
pr_debug("Data/ACK opcode\n");
break;
case TFTP_OPCODE_ERROR:
pr_debug("Error opcode\n");
break;
default:
pr_debug("Unknown opcode\n");
}
return ret;
}
tftp_help()的工作有两部分:
1. 根据数据包的ct初始化一个expect连接,由于help函数是在ipv4_confirm()时调用的,所以ct是存在的。另外需要说明一点,tftp请求(读或写)只能从client到server,所以,如果要走NAT,tftp请求包的方向一定是从内网到外网的。
按照上面的例子,当前ct为:
ORGINAL tuple: 17 192.168.10.1:58747 -> 192.168.10.100:69
REPLY tuple: 17 192.168.10.100:69 -> 192.168.10.1:58747
生成的expect为:
ORGINAL tuple: 17 192.168.10.100:0 -> 192.168.10.1:58747
同时,exp->master = ct。注意,expect只有一个tuple,即只有一个方向,这里只看到ORIGNAL方向的tuple,只是因为tuple的dir没赋值,默认为0。
2. 如果ct做了NAT,就调用nf_nat_tftp指向的函数,这里它指向nf_nat_tftp.c中的help()函数。
static unsigned int help(struct sk_buff *skb,
enum ip_conntrack_info ctinfo,
struct nf_conntrack_expect *exp)
{
const struct nf_conn *ct = exp->master;
exp->saved_proto.udp.port
= ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple.src.u.udp.port;
exp->dir = IP_CT_DIR_REPLY;
exp->expectfn = nf_nat_follow_master;
if (nf_ct_expect_related(exp) != 0) /* 插入链表 */
return NF_DROP;
return NF_ACCEPT;
}
这个函数进一步初始化了expect,同时将这个expect插入struct nf_conn_help结构的链表以及全局的期望连接链表expect_hash中:
static void nf_ct_expect_insert(struct nf_conntrack_expect *exp)
{
/* 获得exp->master的help */
struct nf_conn_help *master_help = nfct_help(exp->master);
struct net *net = nf_ct_exp_net(exp);
const struct nf_conntrack_expect_policy *p;
unsigned int h = nf_ct_expect_dst_hash(&exp->tuple);
atomic_inc(&exp->use);
/* 插入到help->expectations链表 */
hlist_add_head(&exp->lnode, &master_help->expectations);
master_help->expecting[exp->class]++;
/* 插入到全局的expect_hash表 */
hlist_add_head_rcu(&exp->hnode, &net->ct.expect_hash[h]);
net->ct.expect_count++;
/* 设置并启动定时器 */
setup_timer(&exp->timeout, nf_ct_expectation_timed_out,
(unsigned long)exp);
p = &master_help->helper->expect_policy[exp->class];
exp->timeout.expires = jiffies + p->timeout * HZ;
add_timer(&exp->timeout);
atomic_inc(&exp->use);
NF_CT_STAT_INC(net, expect_create);
}
我们还注意到在help()函数中将exp-> expectfn赋值为nf_nat_follow_master(),这个函数的作用在后面会提到。
上面的内容是在客户端发送tftp请求后触发的动作,主要的效果就是生成了一个期望连接并可以被使用了。下面以请求读数据来看一下传输数据时的数据包变化。
当tftp请求包进入nf_conntrack_in的时候,由于没有ct条目,所以调用init_conntrack()尝试新建一个条目,在这个函数中,根据skb新建两个方向的tuple,之后有这样的代码: spin_lock_bh(&nf_conntrack_lock);
exp = nf_ct_find_expectation(net, tuple);
/* 如果在期望连接链表中 */
if (exp) {
__set_bit(IPS_EXPECTED_BIT, &ct->status);
ct->master = exp->master;
if (exp->helper) {
help = nf_ct_helper_ext_add(ct, GFP_ATOMIC);
if (help)
rcu_assign_pointer(help->helper, exp->helper);
}
nf_conntrack_get(&ct->master->ct_general);
NF_CT_STAT_INC(net, expect_new);
} else {
__nf_ct_try_assign_helper(ct, GFP_ATOMIC);
NF_CT_STAT_INC(net, new);
}
hlist_nulls_add_head_rcu(&ct->tuplehash[IP_CT_DIR_ORIGINAL].hnnode,
&net->ct.unconfirmed);
spin_unlock_bh(&nf_conntrack_lock);
if (exp) {
if (exp->expectfn)
exp->expectfn(ct, exp);
nf_ct_expect_put(exp);
}
return &ct->tuplehash[IP_CT_DIR_ORIGINAL];
这里会在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。第一次过来的数据包肯定是没有的,于是走else分支,__nf_ct_try_assign_helper()函数去nf_ct_helper_hash哈希表中匹配当前tuple,由于我们在本节开头提到nf_conntrack_tftp_init()已经把tftp的helper extension添加进去了,所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper,而这个helper的help方法就是tftp_help()。
当tftp请求包走到ipv4_confirm的时候,会去执行这个help方法,即tftp_help(),也就是建立一个期望连接。
当后续tftp传输数据时,在nf_conntrack_in里面,新建tuple后,在expect_hash表中查可以匹配到新建tuple的期望连接(因为只根据源端口来匹配),因此上面代码的if成立,所以ct->master被赋值为exp->master,并且,还会执行exp->expectfn()函数,这个函数上面提到是指向nf_nat_follow_master()的,该函数根据ct的master来给ct做NAT,ct在经过这个函数处理前后的tuple分别为:
before expectfn:
ORGINAL : tuple 83b38338: 17 192.168.10.100:3873 ->192.168.10.1:50173
REPLY : tuple 83b38368: 17 192.168.10.1:50173 ->192.168.10.100:3873
after expectfn:
ORGINAL : tuple 83b38338: 17 192.168.10.100:3873 ->192.168.10.1:50173
REPLY : tuple 83b38368: 17192.168.5.1:50173 -> 192.168.10.100:3873
在ipv4_confirm中,由于ct没有期望连接,所以跳过helper有关的代码直接调用nf_conntrack_confirm()函数。
其他相关问题:
1. 数据传输时的服务器端的端口时谁指定的:
服务器端指定的。在从server->client传数据时,server收到tftp read request之后,就直接发送数据,数据从block1开始计数。而从client->server传数据时,server收到tftp write request之后,先回复一个tftp ack(标记为block0),包中携带server打开的端口号,client便知道使用的目的端口,然后client开始发送数据,数据从block1开始计数。
2. 期望连接的匹配原则:
添加到net->ct.expect_hash[]中的hash规则为nf_ct_expect_dst_hash(&exp->tuple),在查找的时候使用同样的hash规则。
__nf_ct_helper_find(tuple)函数用于在nf_ct_helper_hash[]表中查找匹配的structnf_conntrack_helper结构。过程中不匹配tuple->src.u3,即不匹配源IP地址,需要匹配的是源端口、L3协议号和L4协议号,dir和目的port也需要不匹配。当然,在对tuple进行hash的时候,也只用到了源端口、L3协议号和L4协议号。所以,对于下面的tuple,只比较红色部分:
REPLY : tuple 83a5d5b0: 17192.168.10.100:69 -> 192.168.5.1:40240
nf_ct_find_expectation(net, tuple)函数用于在net->ct.expect_hash[]查找是否有和tuple匹配的连接跟踪,匹配函数为nf_ct_tuple_mask_cmp(tuple,&exp->tuple, &exp->mask),要求tuple中所有条件都符合,而由于expect连接的源端口是0。不过没关系,源端口的mask被设置为0,所以相当于不匹配该项(可参考创建expecttuple的函数nf_ct_expect_init是如何根据源端口设置mask的)。
待匹配tuple:ORGINAL : tuple 801efc1c: 17 192.168.10.100:4593-> 192.168.10.1:40240
expect tuple:ORGINAL : tuple 839dd908: 17 192.168.10.100:0 ->192.168.10.1:40240
我们现在可以来整理一下连接上的tuple和expect tuple之间的关系,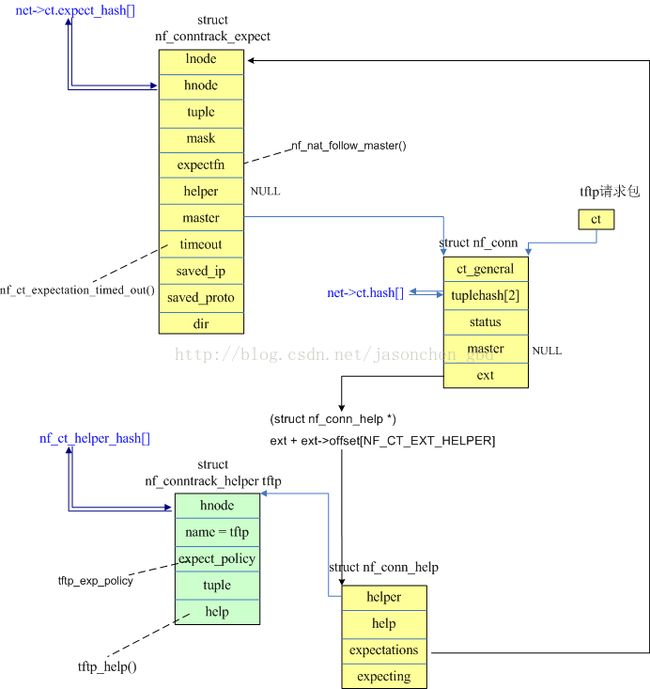
上图浅绿色内容是模块初始化时注册的,黄色内容是处理tftp请求包时初始化的,蓝色的数组是全局hash表。tftp数据包就根据上面的内容进行NAT转换。
注意,在nf_ct_find_expectation()查找期望连接时,如果找到了,就把该期望连接从struct nf_conn_help结构的链表以及全局的期望连接链表expect_hash中删除。在expect_hash中的连接通过设置的超时时间来超时。
2. 以ftp协议举例期望连接
有些应用层协议字段需要携带IP和PORT信息,例如ftp协议,它是基于TCP的文件传输协议,FTP 使用TCP 生成一个虚拟连接用于控制信息,然后再生成一个单独的TCP 连接用于数据传输。而简单的NAT转换并不关注TCP的数据部分,所以需要额外的helper和expect连接来让外网的服务器看到的源IP确实是WAN口的IP并且使用于传输数据的TCP连接上的数据包可以进行NAT转换。
测试拓扑如下图:
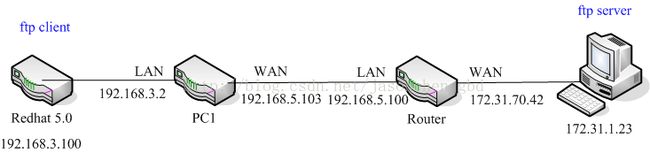
在PC1上抓包,在Router上查看连接信息。
在ftp客户端获取服务器上的do_exit-tty.log.rar文件:
[root@zhenfg build]# ftp 172.31.1.23
ftp> passive
ftp> get do_exit-tty.log.rar
ftp> disconnect
ftp> quit
[root@zhenfg build]#
下图是ftp在PORT(主动)模式下get服务器上的文件的抓包,其中黄色框部分是用于交互控制信息的TCP连接建立连接和断开连接的过程,绿色框部分是用于传输数据而建立的TCP连接。从红色框的数据包可以看到在ftp头部中包含了请求方的IP地址,而这个地址已经被转换成PC1的WAN口地址。
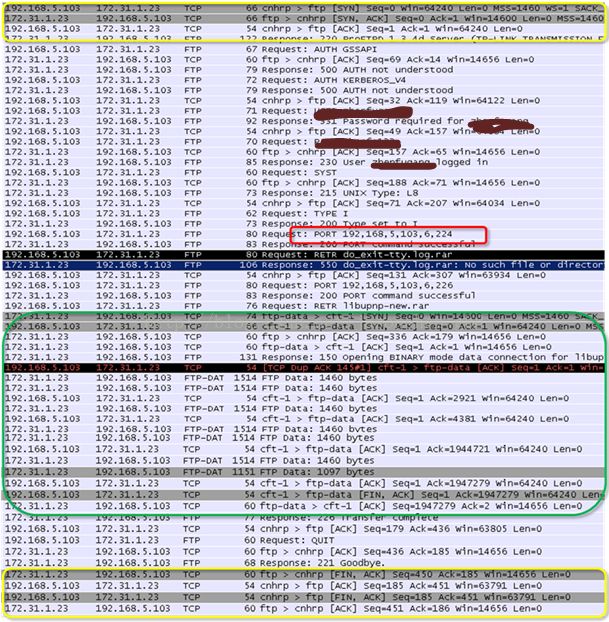
从上图可以看到,传输数据的TCP连接是从服务器端发起的,所以如果没有期望连接,路由器就不知道如何进行DNAT转换。
用于ftp控制信息的TCP连接的conntrack信息为:
ORGINAL : tuple 83b13580: 6 192.168.5.103:1757 ->172.31.1.23:21
REPLY : tuple 83b135b0: 6 172.31.1.23:21 ->172.31.70.42:1757
数据传输的TCP连接便是使用控制信息的TCP连接来生成期望连接的,并且将其作为期望连接的master。生成的期望连接为:
ORGINAL : tuple 83b1c9b8: 6 172.31.1.23:0 ->172.31.70.42:1762
实际机型NAT转换的函数依然是exp->expectfn(),并且仍然指向nf_nat_follow_master()函数,该函数根据ct的master来给ct做NAT,ct在经过这个函数处理前后的tuple分别为:
before expectfn:
ORGINAL : tuple 83b22ee8: 6 172.31.1.23:20 ->172.31.70.42:1762
REPLY : tuple 83b22f18: 6 172.31.70.42:1762 ->172.31.1.23:20
after expectfn:
ORGINAL : tuple 83b22ee8: 6 172.31.1.23:20 ->172.31.70.42:1762
REPLY : tuple 83b22f18: 6 192.168.5.103:1762 ->172.31.1.23:20
系统中的期望连接条目记录在proc文件/proc/net/nf_conntrack_expect中,显示文件内容的函数为exp_seq_show()。