前言
记录个人在2017年08月的学习和总结,不定期更新
2017-08-02
有序的Map
HashMap是无序的,有序的Map是TreeMap和LinkedHashMap,TreeMap里的元素排序要key实现Comparable接口或者传入一个Comparator比较器,LinkedHashMap里面元素的顺序和插入的顺序一致
效率比较:
TreeMap采用红黑树的数据结构实现,而LinkedHashMap采用链表的方式实现,查找效率上来说TreeMap会比LinkedHashMap高
TCP创建连接和断开连接的过程
TCP特点
- 三次握手
- 四次挥手
- 可靠连接
- 丢包重传
核心:tcp是可以可靠传输协议,它的所有特点都为这个可靠传输服务。
创建连接时的三次握手
来看一个java代码连接数据库的三次握手过程
- 第一步:client 发送 syn 到server 发起握手;
- 第二步:server 收到 syn后回复syn+ack给client;
- 第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的48287端口的连接已经是established)
握手的核心目的是告知对方seq(绿框是client的初始seq,蓝色框是server 的初始seq),对方回复ack(收到的seq+包的大小),这样发送端就知道有没有丢包了。
握手的次要目的是告知和协商一些信息,图中黄框。
MSS–最大传输包
SACK_PERM–是否支持Selective ack(用户优化重传效率)
WS–窗口计算指数(有点复杂的话先不用管)
这就是tcp为什么要握手建立连接,就是为了解决tcp的可靠传输。
断开连接时的四次挥手
再来看java连上mysql后,执行了一个SQL: select sleep(2); 然后就断开了连接
四个红框表示断开连接的四次挥手:
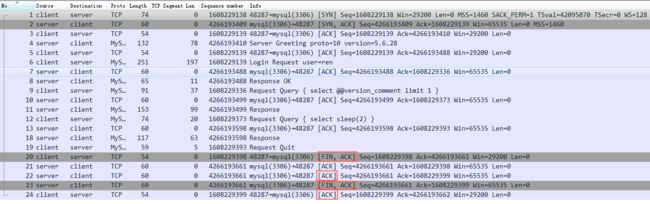
第一步: client主动发送fin包给server
第二步: server回复ack(对应第一步fin包的ack)给client,表示server知道client要断开了
第三步: server发送fin包给client,表示server也可以断开了
第四部: client回复ack给server,表示既然双发都发送fin包表示断开,那么就真的断开吧
为什么是握手是三次而挥手是四次
这是因为当client发送fin包给服务器的时候,server可能还需要有一些后续工作要做,比如OS通知应用层要关闭,这里应用层可能需要做些准备工作,或者说server还有一些数据需要发送给client,等准备工作做完或者是数据发送完毕,就可以发送fin包了
2017-08-03
JVM 参数初探
堆参数
-XX:+PrintGC 使用这个参数,虚拟机启动后,只要遇到GC就会打印日志
-XX:+UseSerialGC 配置串行回收器
-XX:+PrintGCDetails 可以查看详细信息,包括各个区的情况
-Xms 设置最小堆
-Xmx 设置最大堆
-Xmx20m -Xms5m -XX:+PrintCommandLineFlags 可以将隐式或者显示传递给虚拟机的参数输出,打印虚拟机配置
★技巧:JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最 大分配的内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70% 时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx相等以避免在每次GC 后调整堆的大小。
新生代配置
-Xmn 可以设置新生代的大小,设置一个比较大的新生代会减少老年代的大小,这个参数对系统性能以及GC行为有很大的影响,新生代GC频繁,老年代相对少,新生代大小一般会设置整合堆空间的1/3到1/4左右。
-XX:SurvivorRatio 用来设置新生代中eden区和from/to区的比例,默认8:1:1
含义:-XX:SurvivorRatio=eden/from=eden/to
★技巧:不同的堆分布情况,对系统执行会产生一定影响,在实际情况下,应该根据系统的特点做出合理的配置,基本策略:尽可能将对象预留在新生代,减少老年代的GC次数。
除了可以设置新生代的绝对大小-Xmn,还可以使用-XX:NewRatio来设置新生代和老年代的比例:-XX:NewRatio=新生代/老年代
堆溢出处理
堆溢出处理
在Java程序的运行过程中,如果堆空间不足,则会抛出内存溢出的错误Out of Memory(OOM),一旦这类问题发生在生产环境,就可能引起严重的业务中断,java虚拟机提供了-XX:HeapDumpOnOutOfMemoryError,使用该参数可以在内存溢出时导出整个堆信息,与之配合使用的还有参数。
-XX:HeapDumpPath,可以设置导出堆的存放路径
内存分析工具:Memory Analyzer
dump信息:-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/Test03.dump
栈参数
-Xss 指定线程最大栈空间,整合参数也直接决定了函数可调用的最大深度
方法区
JDK8以前,方法区和java堆一样,是一块所有线程共享的内存区域,它用于保存系统的类信息,方法区(永久区)可以保存多少信息可以对其进行配置,在默认情况下,-XX:MaxPermSize为64M,如果系统运行时产生大量的类,就需要设置一个相对合适的方法区,以免出现永久区0内存溢出的问题。
-XX:MaxPermSize=64M -XX:PermSize=64M
jdk1.7以后不分client或者server模式
JDK8以后,永久区被移除,使用本地内存来存储类元数据信息并称之为:元空间(Metaspace)
2017-08-04
Spring IOC和AOP
特点
- 降低了组件之间的耦合性 ,实现了软件各层之间的解耦
- 可以使用容易提供的众多服务,如事务管理,消息服务等
- 容器提供单例模式支持
- 容器提供了AOP技术,利用它很容易实现如权限拦截,运行期监控等功能
- 容器提供了众多的辅助类,能加快应用的开发
- spring对于主流的应用框架提供了集成支持,如hibernate,JPA,struts等
- spring属于低侵入式设计,代码的污染极低
- 独立于各种应用服务器
- spring的DI机制降低了业务对象替换的复杂性
- spring的高度开放性,并不强制应用完全依赖于Spring,开发者可以自由选择spring的部分或全部
根本目的
根本目的:简化Java开发。
为了降低Java开发的复杂性,Spring采取以下4种关键策略:
- 基于POJO的轻量级和最小侵入性编程
- 通过依赖注入和面向接口实现松耦合
- 基于切面和惯例进行声明式编程
- 通过切面和模版减少样板示代码
IOC
概念
Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好Ioc呢?理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对 象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
IoC能做什么
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
IoC和DI
DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
谁依赖于谁:当然是应用程序依赖于IoC容器;
为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
AOP
什么是AOP
AOP(Aspect-OrientedProgramming,面向方面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(cross-cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
而AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。正如Avanade公司的高级方案构架师Adam Magee所说,AOP的核心思想就是“将应用程序中的商业逻辑同对其提供支持的通用服务进行分离。”
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
使用场景
AOP用来封装横切关注点,具体可以在下面的场景中使用:
- Authentication 权限
- Caching 缓存
- Context passing 内容传递
- Error handling 错误处理
- Lazy loading 懒加载
- Debugging 调试
- logging, tracing, profiling and monitoring 记录跟踪 优化 校准
- Performance optimization 性能优化
- Persistence 持久化
- Resource pooling 资源池
- Synchronization 同步
- Transactions 事务
概念
首先让我们从一些重要的AOP概念和术语开始。这些术语不是Spring特有的。不过AOP术语并不是特别的直观,如果Spring使用自己的术语,将会变得更加令人困惑。
切面(Aspect):一个关注点的模块化,这个关注点可能会横切多个对象。事务管理是J2EE应用中一个关于横切关注点的很好的例子。在Spring AOP中,切面可以使用基于模式)或者基于@Aspect注解的方式来实现。
连接点(Joinpoint):在程序执行过程中某个特定的点,比如某方法调用的时候或者处理异常的时候。在Spring AOP中,一个连接点总是表示一个方法的执行。
通知(Advice):在切面的某个特定的连接点上执行的动作。其中包括了“around”、“before”和“after”等不同类型的通知(通知的类型将在后面部分进行讨论)。许多AOP框架(包括Spring)都是以拦截器做通知模型,并维护一个以连接点为中心的拦截器链。
切入点(Pointcut):匹配连接点的断言。通知和一个切入点表达式关联,并在满足这个切入点的连接点上运行(例如,当执行某个特定名称的方法时)。切入点表达式如何和连接点匹配是AOP的核心:Spring缺省使用AspectJ切入点语法。
引入(Introduction):用来给一个类型声明额外的方法或属性(也被称为连接类型声明(inter-type declaration))。Spring允许引入新的接口(以及一个对应的实现)到任何被代理的对象。例如,你可以使用引入来使一个bean实现IsModified接口,以便简化缓存机制。
目标对象(Target Object): 被一个或者多个切面所通知的对象。也被称做被通知(advised)对象。 既然Spring AOP是通过运行时代理实现的,这个对象永远是一个被代理(proxied)对象。
AOP代理(AOP Proxy):AOP框架创建的对象,用来实现切面契约(例如通知方法执行等等)。在Spring中,AOP代理可以是JDK动态代理或者CGLIB代理。
织入(Weaving):把切面连接到其它的应用程序类型或者对象上,并创建一个被通知的对象。这些可以在编译时(例如使用AspectJ编译器),类加载时和运行时完成。Spring和其他纯Java AOP框架一样,在运行时完成织入。
通知类型:
前置通知(Before advice):在某连接点之前执行的通知,但这个通知不能阻止连接点之前的执行流程(除非它抛出一个异常)。
后置通知(After returning advice):在某连接点正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回。
异常通知(After throwing advice):在方法抛出异常退出时执行的通知。
最终通知(After (finally) advice):当某连接点退出的时候执行的通知(不论是正常返回还是异常退出)。
环绕通知(Around Advice):包围一个连接点的通知,如方法调用。这是最强大的一种通知类型。环绕通知可以在方法调用前后完成自定义的行为。它也会选择是否继续执行连接点或直接返回它自己的返回值或抛出异常来结束执行。
环绕通知是最常用的通知类型。和AspectJ一样,Spring提供所有类型的通知,我们推荐你使用尽可能简单的通知类型来实现需要的功能。例如,如果你只是需要一个方法的返回值来更新缓存,最好使用后置通知而不是环绕通知,尽管环绕通知也能完成同样的事情。用最合适的通知类型可以使得编程模型变得简单,并且能够避免很多潜在的错误。比如,你不需要在JoinPoint上调用用于环绕通知的proceed()方法,就不会有调用的问题。
2017-08-06
线程和进程
什么是线程?
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。程序员可以通过它进行多处理器编程,你可以使用多线程对运算密集型任务提速。比如,如果一个线程完成一个任务要100毫秒,那么用十个线程完成改任务只需10毫秒。Java在语言层面对多线程提供了卓越的支持,它也是一个很好的卖点。
线程和进程有什么区别?
线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。不同的进程使用不同的内存空间,而所有的线程共享一片相同的内存空间。别把它和栈内存搞混,每个线程都拥有单独的栈内存用来存储本地数据。
2017-08-07
Java栈上分配对象
我们在学习使用Java的过程中,一般认为new出来的对象都是被分配在堆上,但是这个结论不是那么的绝对,通过对Java对象分配的过程分析,可以知道有两个地方会导致Java中new出来的对象并不一定分别在所认为的堆上。这两个点分别是Java中的逃逸分析和TLAB(Thread Local Allocation Buffer)
逃逸分析
定义
逃逸分析,是一种可以有效减少Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
在计算机语言编译器优化原理中,逃逸分析是指分析指针动态范围的方法,它同编译器优化原理的指针分析和外形分析相关联。当变量(或者对象)在方法中分配后,其指针有可能被返回或者被全局引用,这样就会被其他过程或者线程所引用,这种现象称作指针(或者引用)的逃逸(Escape)。
Java在java SE 6u23以及以后的版本中支持并默认开启了逃逸分析的选项。Java的 HotSpot JIT编译器,能够在方法重载或者动态加载代码的时候对代码进行逃逸分析,同时Java对象在堆上分配和内置线程的特点使得逃逸分析成Java的重要功能。
逃逸分析的方法
Java Hotspot编译器使用的是
Choi J D, Gupta M, Serrano M, et al. Escape analysis for Java[J]. Acm Sigplan Notices, 1999, 34(10): 1-19.
Jong-Deok Choi, Manish Gupta, Mauricio Seffano,Vugranam C. Sreedhar, Sam Midkiff等在论文《Escape Analysis for Java》中描述的算法进行逃逸分析的。该算法引入了连通图,用连通图来构建对象和对象引用之间的可达性关系,并在次基础上,提出一种组合数据流分析法。由于算法是上下文相关和流敏感的,并且模拟了对象任意层次的嵌套关系,所以分析精度较高,只是运行时间和内存消耗相对较大。
绝大多数逃逸分析的实现都基于一个所谓“封闭世界(closed world)”的前提:所有可能被执行的,方法在做逃逸分析前都已经得知,并且,程序的实际运行不会改变它们之间的调用关系 。但当真实的 Java 程序运行时,这样的假设并不成立。Java 程序拥有的许多特性,例如动态类加载、调用本地函数以及反射程序调用等等,都将打破所谓“封闭世界”的约定。
逃逸分析后的处理
经过逃逸分析之后,可以得到三种对象的逃逸状态。
- GlobalEscape(全局逃逸), 即一个对象的引用逃出了方法或者线程。例如,一个对象的引用是复制给了一个类变量,或者存储在在一个已经逃逸的对象当中,或者这个对象的引用作为方法的返回值返回给了调用方法。
- ArgEscape(参数级逃逸),即在方法调用过程当中传递对象的引用给一个方法。这种状态可以通过分析被调方法的二进制代码确定。
- NoEscape(没有逃逸),一个可以进行标量替换的对象。可以不将这种对象分配在传统的堆上。
编译器可以使用逃逸分析的结果,对程序进行一下优化。 - 堆分配对象变成栈分配对象。一个方法当中的对象,对象的引用没有发生逃逸,那么这个方法可能会被分配在栈内存上而非常见的堆内存上。
- 消除同步。线程同步的代价是相当高的,同步的后果是降低并发性和性能。逃逸分析可以判断出某个对象是否始终只被一个线程访问,如果只被一个线程访问,那么对该对象的同步操作就可以转化成没有同步保护的操作,这样就能大大提高并发程度和性能。
- 矢量替代。逃逸分析方法如果发现对象的内存存储结构不需要连续进行的话,就可以将对象的部分甚至全部都保存在CPU寄存器内,这样能大大提高访问速度。
下面,我们看一下逃逸分析的例子。
class Main {
public static void main(String[] args) {
example();
}
public static void example() {
Foo foo = new Foo(); //alloc
Bar bar = new Bar(); //alloc
bar.setFoo(foo);
}
}
class Foo {}
class Bar {
private Foo foo;
public void setFoo(Foo foo) {
this.foo = foo;
}
}
在这个例子当中,我们创建了两个对象,Foo对象和Bar对象,同时我们把Foo对象的应用赋值给了Bar对象的方法。此时,如果Bar对在堆上就会引起Foo对象的逃逸,但是,在本例当中,编译器通过逃逸分析,可以知道Bar对象没有逃出example()方法,因此这也意味着Foo也没有逃出example方法。因此,编译器可以将这两个对象分配到栈上。
编译器经过逃逸分析的效果
测试代码
class EscapeAnalysis {
private static class Foo {
private int x;
private static int counter;
public Foo() {
x = (++counter);
}
}
public static void main(String[] args) {
long start = System.nanoTime();
for (int i = 0; i < 1000 * 1000 * 10; ++i) {
Foo foo = new Foo();
}
long end = System.nanoTime();
System.out.println("Time cost is " + (end - start));
}
}
未开启逃逸分析设置为:
-server -verbose:gc
开启逃逸分析设置为:
-server -verbose:gc -XX:+DoEscapeAnalysis
在未开启逃逸分析的状况下运行情况如下:
[GC 5376K->427K(63872K), 0.0006051 secs]
[GC 5803K->427K(63872K), 0.0003928 secs]
[GC 5803K->427K(63872K), 0.0003639 secs]
[GC 5803K->427K(69248K), 0.0003770 secs]
[GC 11179K->427K(69248K), 0.0003987 secs]
[GC 11179K->427K(79552K), 0.0003817 secs]
[GC 21931K->399K(79552K), 0.0004342 secs]
[GC 21903K->399K(101120K), 0.0002175 secs]
[GC 43343K->399K(101184K), 0.0001421 secs]
Time cost is 58514571
开启逃逸分析的状况下,运行情况如下:
Time cost is 10031306
未开启逃逸分析时,运行上诉代码,JVM执行了GC操作,而在开启逃逸分析情况下,JVM并没有执行GC操作。同时,操作时间上,开启逃逸分析的程序运行时间是未开启逃逸分析时间的1/5。
TLAB
JVM在内存新生代Eden Space中开辟了一小块线程私有的区域,称作TLAB(Thread-local allocation buffer)。默认设定为占用Eden Space的1%。在Java程序中很多对象都是小对象且用过即丢,它们不存在线程共享也适合被快速GC,所以对于小对象通常JVM会优先分配在TLAB上,并且TLAB上的分配由于是线程私有所以没有锁开销。因此在实践中分配多个小对象的效率通常比分配一个大对象的效率要高。
也就是说,Java中每个线程都会有自己的缓冲区称作TLAB(Thread-local allocation buffer),每个TLAB都只有一个线程可以操作,TLAB结合bump-the-pointer技术可以实现快速的对象分配,而不需要任何的锁进行同步,也就是说,在对象分配的时候不用锁住整个堆,而只需要在自己的缓冲区分配即可。
关于对象分配的JDK源码可以参见JVM 之 Java对象创建[初始化]中对OpenJDK源码的分析。
Java对象分配的过程
编译器通过逃逸分析,确定对象是在栈上分配还是在堆上分配。如果是在堆上分配,则进入选项2.
如果tlab_top + size <= tlab_end,则在在TLAB上直接分配对象并增加tlab_top 的值,如果现有的TLAB不足以存放当前对象则3.
重新申请一个TLAB,并再次尝试存放当前对象。如果放不下,则4.
在Eden区加锁(这个区是多线程共享的),如果eden_top + size <= eden_end则将对象存放在Eden区,增加eden_top 的值,如果Eden区不足以存放,则5.
执行一次Young GC(minor collection)。
经过Young GC之后,如果Eden区任然不足以存放当前对象,则直接分配到老年代。
对象不在堆上分配主要的原因还是堆是共享的,在堆上分配有锁的开销。无论是TLAB还是栈都是线程私有的,私有即避免了竞争(当然也可能产生额外的问题例如可见性问题),这是典型的用空间换效率的做法。
2017-08-08
UnSafe类
JDK源码中,在研究AQS框架时,会发现很多地方都使用了CAS操作,在并发实现中CAS操作必须具备原子性,而且是硬件级别的原子性,Java被隔离在硬件之上,明显力不从心,这时为了能直接操作操作系统层面,肯定要通过用C++编写的native本地方法来扩展实现。JDK提供了一个类来满足CAS的要求,sun.misc.Unsafe,从名字上可以大概知道它用于执行低级别、不安全的操作,AQS就是使用此类完成硬件级别的原子操作。
Unsafe是一个很强大的类,它可以分配内存、释放内存、可以定位对象某字段的位置、可以修改对象的字段值、可以使线程挂起、使线程恢复、可进行硬件级别原子的CAS操作等等,但平时我们没有这么特殊的需求去使用它,而且必须在受信任代码(一般由JVM指定)中调用此类,例如直接Unsafe unsafe = Unsafe.getUnsafe();获取一个Unsafe实例是不会成功的,因为这个类的安全性很重要,设计者对其进行了如下判断,它会检测调用它的类是否由启动类加载器Bootstrap ClassLoader(它的类加载器为null)加载,由此保证此类只能由JVM指定的类使用。
public static Unsafe getUnsafe() {
Class cc = sun.reflect.Reflection.getCallerClass(2);
if (cc.getClassLoader() != null)
throw new SecurityException("Unsafe");
return theUnsafe;
}
当然可以通过反射绕过上面的限制,用下面的getUnsafeInstance方法可以获取Unsafe实例,这段代码演示了如何获取java对象的相对地址偏移量及使用Unsafe完成CAS操作,最终输出的是flag字段的内存偏移量及CAS操作后的值。分别为12和101。另外如果使用开发工具如Eclipse,可能会编译通不过,只要把编译错误提示关掉即可。
package com.example.demo;
import sun.misc.Unsafe;
import java.lang.reflect.Field;
/**
* @author zhangguoji
* @date 2017/8/8 11:46
*/
public class UnsafeTest {
private int flag = 100;
private static long offset;
private static Unsafe unsafe = null;
static {
try {
unsafe = getUnsafeInstance();
offset = unsafe.objectFieldOffset(UnsafeTest.class
.getDeclaredField("flag"));
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
int expect = 100;
int update = 101;
UnsafeTest unsafeTest = new UnsafeTest();
System.out.println("unsafeTest对象的flag字段的地址偏移量为:" + offset);
unsafeTest.doSwap(offset, expect, update);
System.out.println("CAS操作后的flag值为:" + unsafeTest.getFlag());
}
private boolean doSwap(long offset, int expect, int update) {
return unsafe.compareAndSwapInt(this, offset, expect, update);
}
public int getFlag() {
return flag;
}
private static Unsafe getUnsafeInstance() throws SecurityException,
NoSuchFieldException, IllegalArgumentException,
IllegalAccessException {
Field theUnsafeInstance = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeInstance.setAccessible(true);
return (Unsafe) theUnsafeInstance.get(Unsafe.class);
}
}
结果
unsafeTest对象的flag字段的地址偏移量为:12
CAS操作后的flag值为:101
Unsafe类让我们明白了java是如何实现对操作系统操作的,一般我们使用java是不需要在内存中处理java对象及内存地址位置的,但有的时候我们确实需要知道java对象相关的地址,于是我们使用Unsafe类,尽管java对其提供了足够的安全管理。
Java语言的设计者们极力隐藏涉及底层操作系统的相关操作,但此节我们本着对AQS框架实现的目的,不得不剖析了Unsafe类,因为AQS里面即是使用Unsafe获取对象字段的地址偏移量、相关原子操作来实现CAS操作的。
MySQL value和vlues的区别
两者功能一样,可以混合使用,但是value插入多条数据时性能较好,values插入单条数据时性能较好,跟我们的逻辑相反的,很奇怪
单是SQL Sever只能使用values
ConcurrentHashMap跨版本问题
背景知识
javac
javac有两个指令:-source和-target,比如下述指令:
/usr/lib/java/jdk1.8.0_131/bin/javac -source 1.7 -target 1.7 HelloWorld.java
-source:表示我的代码将采用哪个java版本来编译。该值影响的是编译器对语法规则的校验。比如HelloWorld.java中含有jdk8的语法,但是你的-source为1.7,那么编译器就会报错。
-target:表示生成的字节码将会在哪个版本(及以上)的jvm上运行。比如HelloWorld.java指定了-target为1.8,那么HelloWorld.class只能在1.8即以上的jvm中运行,如果在1.7的jvm上运行,就会报错。
rt.jar
jdk的rt.jar里面包含了jdk的核心类,比如String,集合等。JVM在加载类时,对于rt.jar包里面的所有的类持有最高的信任而不做任何校验。
ConcurrentHashMap
ConcurrentHashMap类有一个方法叫做keySet,用来返回当前map中的key集合。虽然返回的是key的集合,但是在1.7和1.8中用来表示该集合的类却完全不同。在1.7中,返回的是Set:
public Set More ...keySet() {
Set ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet());
}
然而在1.8中返回的是KeySetView:
public KeySetView keySet() {
KeySetView ks;
return (ks = keySet) != null ? ks : (keySet = new KeySetView(this, null));
}
其中KeySetView其实是Set接口的一个实现类。我们再来看下述代码:
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
public class HelloWorld {
public static void main(String[] args) {
ConcurrentHashMap test = new ConcurrentHashMap<>();
Set keySet = test.keySet();
}
}
然后我们用jdk8的javac来进行编译:
$ /usr/lib/java8/bin/javac -source 1.7 -target 1.7 HelloWorld.java
warning: [options] bootstrap class path not set in conjunction with -source 1.7
1 warning
或者中文版的报错信息如下:
警告: [options] 未与 -source 1.7 一起设置引导类路径
1 个警告
但是上述代码是可以通过编译的,因为KeySetView是Set的实现类,所以1.7的语法没有任何问题。但是编译生成的class文件无法在1.7版本的jvm上运行。我们看一下字节码的实际内容:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentHashMap.KeySetView;
public class HelloWorld
{
public static void main(String[] paramArrayOfString)
{
ConcurrentHashMap localConcurrentHashMap = new ConcurrentHashMap();
ConcurrentHashMap.KeySetView localKeySetView = localConcurrentHashMap.keySet();
}
}
我们可以看到,在字节码中,实际上keySet返回的是1.8中指定的KeySetView类,但是这个类在jdk1.7中是不存在的,所以当用1.7的jvm运行时,会抛出NoSuchMethodError的异常。
解决方法
为了解决这个问题,还是要看编译时的警告信息(不能忽视任何一个警告)。从warning的信息中我们可以得知,当指定了-source时,我们还需要一起指定引导类即bootstrap类,否则可能会出现某些兼容性的问题,比如刚才我们遇到的ConcurrentHashMap的问题。所以我们在编译的时候需要再加上引导类:
$ /usr/lib/java8/bin/javac -source 1.7 -target 1.7 HelloWorld.java -bootclasspath /usr/lib/java7/jre/lib/rt.jar
我们先来反编译生成的class文件
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
public class HelloWorld
{
public static void main(String[] paramArrayOfString)
{
ConcurrentHashMap localConcurrentHashMap = new ConcurrentHashMap();
Set localSet = localConcurrentHashMap.keySet();
}
}
我们可以看到现在class文件中返回的类变为了Set,然后我们在用1.7的jvm来运行,发现一切正常,问题被解决了!
总结
以后在指定-source时,还需要同时指定-bootclasspath,否则就会默认使用当前javac所用到的jdk版本的核心jar包(比如rt.jar)。
2017-08-11
Iterator和Enumeration
Enumeration是一个接口,它的源码如下:
代码
package java.util;
public interface Enumeration {
boolean hasMoreElements();
E nextElement();
}
Iterator也是一个接口,它的源码如下:
package java.util;
public interface Iterator {
boolean hasNext();
E next();
void remove();
}
区别
函数接口不同
Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。Iterator支持fail-fast机制,而Enumeration不支持。
Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。
而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
遍历速度比较
下面,我们编写一个Hashtable,然后分别通过 Iterator 和 Enumeration 去遍历它,比较它们的效率。代码如下:
import java.util.Enumeration;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Random;
public class IteratorEnumeration {
public static void main(String[] args) {
int val;
Random r = new Random();
Hashtable table = new Hashtable();
for (int i=0; i<10000000; i++) {
// 随机获取一个[0,100)之间的数字
val = r.nextInt(100);
table.put(String.valueOf(i), val);
}
// 通过Iterator遍历Hashtable
iterateHashtable(table) ;
// 通过Enumeration遍历Hashtable
enumHashtable(table);
}
/*
* 通过Iterator遍历Hashtable
*/
private static void iterateHashtable(Hashtable table) {
long startTime = System.currentTimeMillis();
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
//System.out.println("iter:"+iter.next());
iter.next();
}
long endTime = System.currentTimeMillis();
countTime(startTime, endTime);
}
/*
* 通过Enumeration遍历Hashtable
*/
private static void enumHashtable(Hashtable table) {
long startTime = System.currentTimeMillis();
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
//System.out.println("enu:"+enu.nextElement());
enu.nextElement();
}
long endTime = System.currentTimeMillis();
countTime(startTime, endTime);
}
private static void countTime(long start, long end) {
System.out.println("time: "+(end-start)+"ms");
}
}
运行结果如下:
time: 9ms
time: 5ms
从中,我们可以看出。Enumeration 比 Iterator 的遍历速度更快。为什么呢?
这是因为,Hashtable中Iterator是通过Enumeration去实现的,而且Iterator添加了对fail-fast机制的支持;所以,执行的操作自然要多一些。
2017-08-15
Runnable、Callable、Future、FutureTask的区别
Runnable
其中Runnable应该是我们最熟悉的接口,它只有一个run()函数,用于将耗时操作写在其中,该函数没有返回值。然后使用某个线程去执行该runnable即可实现多线程,Thread类在调用start()函数后就是执行的是Runnable的run()函数。Runnable的声明如下
public interface Runnable {
/**
* When an object implementing interface Runnable is used
* to create a thread, starting the thread causes the object's
* run method to be called in that separately executing
* thread.
*
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
Callable
Callable与Runnable的功能大致相似,Callable中有一个call()函数,但是call()函数有返回值,而Runnable的run()函数不能将结果返回给客户程序。Callable的声明如下 :
public interface Callable {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
Future
Executor就是Runnable和Callable的调度容器,Future就是对于具体的Runnable或者Callable任务的执行结果进行
取消、查询是否完成、获取结果、设置结果操作。get方法会阻塞,直到任务返回结果(Future简介)。Future声明如下
/**
* @see FutureTask
* @see Executor
* @since 1.5
* @author Doug Lea
* @param The result type returned by this Future's get method
*/
public interface Future {
/**
* Attempts to cancel execution of this task. This attempt will
* fail if the task has already completed, has already been cancelled,
* or could not be cancelled for some other reason. If successful,
* and this task has not started when cancel is called,
* this task should never run. If the task has already started,
* then the mayInterruptIfRunning parameter determines
* whether the thread executing this task should be interrupted in
* an attempt to stop the task. *
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* Returns true if this task was cancelled before it completed
* normally.
*/
boolean isCancelled();
/**
* Returns true if this task completed.
*
*/
boolean isDone();
/**
* Waits if necessary for the computation to complete, and then
* retrieves its result.
*
* @return the computed result
*/
V get() throws InterruptedException, ExecutionException;
/**
* Waits if necessary for at most the given time for the computation
* to complete, and then retrieves its result, if available.
*
* @param timeout the maximum time to wait
* @param unit the time unit of the timeout argument
* @return the computed result
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
FutureTask
FutureTask则是一个RunnableFuture
public class FutureTask implements RunnableFuture
### RunnableFuture
```java
public interface RunnableFuture extends Runnable, Future {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
另外它还可以包装Runnable和Callable
public FutureTask(Callable callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
可以看到,Runnable注入会被Executors.callable()函数转换为Callable类型,即FutureTask最终都是执行Callable类型的任务。该适配函数的实现如下 :
public static Callable callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter(task, result);
}
RunnableAdapter适配器
/**
* A callable that runs given task and returns given result
*/
static final class RunnableAdapter implements Callable {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
由于FutureTask实现了Runnable,因此它既可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行。
并且还可以直接通过get()函数获取执行结果,该函数会阻塞,直到结果返回。因此FutureTask既是Future、
Runnable,又是包装了(Callable如果是Runnable最终也会被转换为Callable ), 它是这两者的合体。
代码演示
```java
import java.util.concurrent.*;
public class RunnableFutureTask {
/**
* ExecutorService
*/
static ExecutorService mExecutor = Executors.newSingleThreadExecutor();
/**
*
* @param args
*/
public static void main(String[] args) {
runnableDemo();
futureDemo();
}
/**
* runnable, 无返回值
*/
static void runnableDemo() {
new Thread(() -> System.out.println(fibc(20))).start();
}
/**
* 其中Runnable实现的是void run()方法,无返回值;Callable实现的是 V
* call()方法,并且可以返回执行结果。其中Runnable可以提交给Thread来包装下
* ,直接启动一个线程来执行,而Callable则一般都是提交给ExecuteService来执行。
*/
static void futureDemo() {
try {
/**
* 提交runnable则没有返回值, future没有数据
*/
Future result = mExecutor.submit(() -> fibc(20));
System.out.println("future result from runnable : " + result.get());
/**
* 提交Callable, 有返回值, future中能够获取返回值
*/
Future result2 = mExecutor.submit(() -> fibc(20));
System.out
.println("future result from callable : " + result2.get());
/**
* FutureTask则是一个RunnableFuture,即实现了Runnbale又实现了Futrue这两个接口,
* 另外它还可以包装Runnable(实际上会转换为Callable)和Callable
* ,所以一般来讲是一个符合体了,它可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行
* ,并且还可以通过v get()返回执行结果,在线程体没有执行完成的时候,主线程一直阻塞等待,执行完则直接返回结果。
*/
FutureTask futureTask = new FutureTask<>(() -> fibc(20));
// 提交futureTask
mExecutor.submit(futureTask) ;
System.out.println("future result from futureTask : "
+ futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
/**
* 效率底下的斐波那契数列, 耗时的操作
*
* @param num
* @return
*/
static int fibc(int num) {
if (num == 0) {
return 0;
}
if (num == 1) {
return 1;
}
return fibc(num - 1) + fibc(num - 2);
}
``
2017-08-16
linux根目录下的文件详解
linux哲学思想:
- 一切皆文件;
- 体积小,目的单一的小程序组成;组合小程序,完成复杂的任务;
- 尽量避免捕获用户接口;
- 通过配置文件保存程序的配置信息,而配置文件通常是纯文本文件;
根目录下的文件:
/boot该目录默认下存放的是Linux的启动文件和内核。/initrd它的英文含义是boot loader initialized RAM disk,就是由boot loader初始化的内存盘。在linux
内核启动前,boot loader会将存储介质(一般是硬盘)中的initrd文件加载到内存,内核启动时会在访问真正的根文件系统前先访问该内存中的initrd文件系统。/bin该目录中存放Linux的常用命令。/sbin该目录用来存放系统管理员使用的管理程序。/var该目录存放那些经常被修改的文件,包括各种日志、数据文件。/etc该目录存放系统管理时要用到的各种配置文件和子目录,例如网络配置文件、文件系统、X系统配置文件、设备配置信息、设置用户信息等。/dev该目录包含了Linux系统中使用的所有外部设备,它实际上是访问这些外部设备的端口,访问这些外部设备与访问一个文件或一个目录没有区别。/mnt临时将别的文件系统挂在该目录下。/root如果你是以超级用户的身份登录的,这个就是超级用户的主目录。/home如果建立一个名为“xx”的用户,那么在/home目录下就有一个对应的“/home/xx”路径,用来存放该用户的主目录。/usr用户的应用程序和文件几乎都存放在该目录下。/lib该目录用来存放系统动态链接共享库,几乎所有的应用程序都会用到该目录下的共享库。/opt第三方软件在安装时默认会找这个目录,所以你没有安装此类软件时它是空的,但如果你一旦把它删除了,以后在安装此类软件时就有可能碰到麻烦。/tmp用来存放不同程序执行时产生的临时文件,该目录会被系统自动清理干净。/proc可以在该目录下获取系统信息,这些信息是在内存中由系统自己产生的,该目录的内容不在硬盘上而在内存里。/misc可以让多用户堆积和临时转移自己的文件。/lost+found该目录在大多数情况下都是空的。但当突然停电、或者非正常关机后,有些文件就临时存放在这里。
2017-08-18
线程池ThreadPoolExecutor解析
JDK1.5中引入了强大的concurrent包,其中最常用的莫过了线程池的实现ThreadPoolExecutor,它给我们带来了极大的方便,但同时,对于该线程池不恰当的设置也可能使其效率并不能达到预期的效果,甚至仅相当于或低于单线程的效率。
线程池的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor类可设置的参数主要有:
- corePoolSize 核心线程数
- 核心线程会一直存活,即使没有任务需要处理。
- 当线程数小于核心线程数时,即使现有的线程空闲,线程池也会优先创建新线程来处理任务,而不是直接交给现有的线程处理。
- 核心线程在allowCoreThreadTimeout被设置为true时会超时退出,默认情况下不会退出。
- maxPoolSize 最大线程数
- 当线程数大于或等于核心线程,且任务队列已满时,线程池会创建新的线程,直到线程数量达到maxPoolSize。
- 如果线程数已等于maxPoolSize,且任务队列已满,则已超出线程池的处理能力,线程池会拒绝处理任务而抛出异常。
- keepAliveTime 线程空闲时间
- 当线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize。
- 如果allowCoreThreadTimeout设置为true,则所有线程均会退出直到线程数量为0。
- allowCoreThreadTimeout 允许核心线程超时
- 是否允许核心线程空闲退出,默认值为false
- queueCapacity 任务队列容量
- 当核心线程数达到最大时,新任务会放在队列中排队等待执行
- rejectedExecutionHandler:任务拒绝处理器
-
两种情况会拒绝处理任务:
- 当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务
- 当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
-
ThreadPoolExecutor类有几个内部实现类来处理这类情况:
- AbortPolicy 丢弃任务,抛运行时异常
- CallerRunsPolicy 执行任务
- DiscardPolicy 忽视,什么都不会发生
- DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务,如果使用的任务队列是优先队列PriorityBlockingQueue,那么抛弃权重最高的任务
实现RejectedExecutionHandler接口,可自定义处理器
如何执行任务
线程池按以下行为执行任务:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满
- 若线程数小于最大线程数,创建线程
- 若线程数等于最大线程数,抛出异常,拒绝任务
如何设置参数
默认值:
corePoolSize=1
queueCapacity=Integer.MAX_VALUE
maxPoolSize=Integer.MAX_VALUE
keepAliveTime=60s
allowCoreThreadTimeout=false
rejectedExecutionHandler=AbortPolicy()
需要根据几个值来决定
- tasks :每秒的任务数,假设为500~1000
- taskcost:每个任务花费时间,假设为0.1s
- responsetime:系统允许容忍的最大响应时间,假设为1s
做几个计算 - corePoolSize = 每秒需要多少个线程处理?
- threadcount = tasks / (1 / taskcost) = tasks
- taskcout = (500~1000) * 0.1 = 50~100 个线程。corePoolSize设置应该大于50
- 根据8020原则,如果80%的每秒任务数小于800,那么corePoolSize设置为80即可
- queueCapacity = (coreSizePool/taskcost) * responsetime
- 计算可得 queueCapacity = 80 / 0.1 * 1 = 80。意思是队列里的线程可以等待1s,超过了的需要新开线程来执行
- 切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,不能新开线程来执行,响应时间会随之陡增。
- maxPoolSize = (max(tasks)- queueCapacity) / (1 / taskcost)
- 计算可得 maxPoolSize = (1000 - 80) / 10 = 92 * (最大任务数-队列容量)/ 每个线程每秒处理能力 = 最大线程数
- rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理
- keepAliveTime和allowCoreThreadTimeout采用默认通常能满足
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务的优先级:高,中和低。
任务的执行时间:长,中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能小的线程,如配置Ncpu+1个线程的线程池。IO密集型任务则由于线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
建议使用有界队列,有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。有一次我们组使用的后台任务线程池的队列和线程池全满了,不断的抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞住,任务积压在线程池里。如果当时我们设置成无界队列,线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。当然我们的系统所有的任务是用的单独的服务器部署的,而我们使用不同规模的线程池跑不同类型的任务,但是出现这样问题时也会影响到其他任务。
线程池的监控
通过线程池提供的参数进行监控。线程池里有一些属性在监控线程池的时候可以使用
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量。小于或等于taskCount。
- largestPoolSize:线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过。如等于线程池的最大大小,则表示线程池曾经满了。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,池里的线程不会自动销毁,所以这个大小只增不+ getActiveCount:获取活动的线程数。
通过扩展线程池进行监控。通过继承线程池并重写线程池的beforeExecute,afterExecute和terminated方法,我们可以在任务执行前,执行后和线程池关闭前干一些事情。如监控任务的平均执行时间,最大执行时间和最小执行时间等。这几个方法在线程池里是空方法。如:
protected void beforeExecute(Thread t, Runnable r) { }
2017-08-19
Linux后台运行jar文件
方式一
java -jar XXX.jar
特点:当前ssh窗口被锁定,可按CTRL + C打断程序运行,或直接关闭窗口,程序退出
那如何让窗口不锁定?
方式二
java -jar XXX.jar &
&代表在后台运行。
特定:当前ssh窗口不被锁定,但是当窗口关闭时,程序中止运行。
继续改进,如何让窗口关闭时,程序仍然运行?
方式三
nohup java -jar XXX.jar &
nohup 意思是不挂断运行命令,当账户退出或终端关闭时,程序仍然运行
当用 nohup 命令执行作业时,缺省情况下该作业的所有输出被重定向到nohup.out的文件中,除非另外指定了输出文件。
方式四
nohup java -jar XXX.jar >result.log 2>error.log &
command >out.file
command >out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中
这里我们将结果输出重定向到result.log中
2 > out.file是指将错误的输出重定向到文件,我们将错误的输出重定向到error.log
查看命令
可通过jobs命令查看后台运行任务
jobs
那么就会列出所有后台执行的作业,并且每个作业前面都有个编号。
如果想将某个作业调回前台控制,只需要 fg + 编号即可。
fg 23
2017-08-23
内部类为什么可以访问外部类的属性
内部类定义
内部类就是定义在一个类内部的类。定义在类内部的类有两种情况:一种是被static关键字修饰的, 叫做静态内部类, 另一种是不被static关键字修饰的, 就是普通内部类。 在下文中所提到的内部类都是指这种不被static关键字修饰的普通内部类。 静态内部类虽然也定义在外部类的里面, 但是它只是在形式上(写法上)和外部类有关系, 其实在逻辑上和外部类并没有直接的关系。而一般的内部类,不仅在形式上和外部类有关系(写在外部类的里面), 在逻辑上也和外部类有联系。 这种逻辑上的关系可以总结为以下两点:
- 内部类对象的创建依赖于外部类对象;
- 内部类对象持有指向外部类对象的引用。
上边的第二条可以解释为什么在内部类中可以访问外部类的成员。就是因为内部类对象持有外部类对象的引用。但是我们不禁要问, 为什么会持有这个引用?
在源代码层面, 我们无法看到原因,因为Java为了语法的简介, 省略了很多该写的东西, 也就是说很多东西本来应该在源代码中写出, 但是为了简介起见, 不必在源码中写出,编译器在编译时会加上一些代码。 现在我们就看看Java的编译器为我们加上了什么?
首先建一个工程TestInnerClass用于测试。 在该工程中为了简单起见, 没有创建包, 所以源代码直接在默认包中。在该工程中, 只有下面一个简单的文件。
public class Outer {
int outerField = 0;
class Inner{
void InnerMethod(){
int i = outerField;
}
}
}
编译后产生两个class文件,分别是Outer$Inner.class和Outer.class,这里我们看起来内部类除了前面有个外部类的名字之外,和其他类并没有区别,别的类和外部类也是两个不同的class文件,为什么内部类就可以访问呢?我们这样想,java总归还是java,再怎么变也不会超过这个语言的特性,能访问这个类说明,肯定是内部类持有一个引用,指向了外部类,编译器应该是帮我们做了这些事,我们不知道而已。
反编译
这里我们的目的是探究内部类的行为, 所以只反编译内部类的class文件Outer$Inner.class 。 在命令行中, 切换到工程的bin目录, 输入以下命令反编译这个类文件:
javap -classpath . -v Outer$Inner
-classpath . 说明在当前目录下寻找要反编译的class文件 -v 加上这个参数输出的信息比较全面。包括常量池和方法内的局部变量表, 行号, 访问标志等等。
注意, 如果有包名的话, 要写class文件的全限定名, 如:
javap -classpath . -v com.baidu.Outer$Inner
反编译的输出结果很多, 为了篇幅考虑, 在这里我们省略了常量池。 下面给出除了常量池之外的输出信息
{
final Outer this$0;
flags: ACC_FINAL, ACC_SYNTHETIC
Outer$Inner(Outer);
flags:
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #10 // Field this$0:LOuter;
5: aload_0
6: invokespecial #12 // Method java/lang/Object."":()V
9: return
LineNumberTable:
line 5: 0
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LOuter$Inner;
void InnerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: getfield #10 // Field this$0:LOuter;
4: getfield #20 // Field Outer.outerField:I
7: istore_1
8: return
LineNumberTable:
line 7: 0
line 8: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 this LOuter$Inner;
8 1 1 i I
}
首先我们会看到, 第一行的信息如下:
final Outer this$0;
这句话的意思是, 在内部类Outer$Inner中, 存在一个名字为this$0 , 类型为Outer的成员变量, 并且这个变量是final的。 其实这个就是所谓的“在内部类对象中存在的指向外部类对象的引用”。但是我们在定义这个内部类的时候, 并没有声明它, 所以这个成员变量是编译器加上的。
虽然编译器在创建内部类时为它加上了一个指向外部类的引用, 但是这个引用是怎样赋值的呢?毕竟必须先给他赋值, 它才能指向外部类对象。 下面我们把注意力转移到构造函数上。 下面这段输出是关于构造函数的信息。
Outer$Inner(Outer);
flags:
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #10 // Field this$0:LOuter;
5: aload_0
6: invokespecial #12 // Method java/lang/Object."":()V
9: return
LineNumberTable:
line 5: 0
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LOuter$Inner;
我们知道, 如果在一个类中, 不声明构造方法的话, 编译器会默认添加一个无参数的构造方法。 但是这句话在这里就行不通了, 因为我们明明看到, 这个构造函数有一个构造方法, 并且类型为Outer。 所以说,编译器会为内部类的构造方法添加一个参数, 参数的类型就是外部类的类型。
下面我们看看在构造参数中如何使用这个默认添加的参数。 我们来分析一下构造方法的字节码。 下面是每行字节码的意义:
aload_0 :
将局部变量表中的第一个引用变量加载到操作数栈。 这里有几点需要说明。 局部变量表中的变量在方法执行前就已经初始化完成;局部变量表中的变量包括方法的参数;成员方法的局部变量表中的第一个变量永远是this;操作数栈就是执行当前代码的栈。所以这句话的意思是: 将this引用从局部变量表加载到操作数栈。
aload_1:
将局部变量表中的第二个引用变量加载到操作数栈。 这里加载的变量就是构造方法中的Outer类型的参数。
putfield #10 // Field this$0:LOuter;
使用操作数栈顶端的引用变量为指定的成员变量赋值。 这里的意思是将外面传入的Outer类型的参数赋给成员变量this$0 。
这一句putfield字节码就揭示了, 指向外部类对象的这个引用变量是如何赋值的。
下面几句字节码和本文讨论的话题无关, 只做简单的介绍。 下面几句字节码的含义是: 使用this引用调用父类(Object)的构造方法然后返回。
用我们比较熟悉的形式翻译过来, 这个内部类和它的构造函数有点像这样: (注意, 这里不符合Java的语法, 只是为了说明问题)
class Outer$Inner{
final Outer this$0;
public Outer$Inner(Outer outer){
this.this$0 = outer;
super();
}
}
关于在内部类中如何使用指向外部类的引用访问外部类成员, 就不用多做解释了, 其实和普通的通过引用访问成员的方式是相同的。 在内部类的InnerMethod方法中, 访问了外部类的成员变量outerField, 下面的字节码揭示了访问是如何进行的:
void InnerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: getfield #10 // Field this$0:LOuter;
4: getfield #20 // Field Outer.outerField:I
7: istore_1
8: return
getfield #10 // Field this$0:LOuter;
将成员变量this$0加载到操作数栈上来
getfield #20 // Field Outer.outerField:I
使用上面加载的this$0引用, 将外部类的成员变量outerField加载到操作数栈
istore_1
将操作数栈顶端的int类型的值保存到局部变量表中的第二个变量上(注意, 第一个局部变量被this占用, 第二个局部变量是i)。操作数栈顶端的int型变量就是上一步加载的outerField变量。 所以, 这句字节码的含义就是: 使用outerField为i赋值。
上面三步就是内部类中是如何通过指向外部类对象的引用, 来访问外部类成员的。
总结
通过反编译内部类的字节码, 说明了内部类是如何访问外部类对象的成员的,除此之外, 我们也对编译器的行为有了一些了解, 编译器在编译时会自动加上一些逻辑, 这正是我们感觉困惑的原因。
关于内部类如何访问外部类的成员, 分析之后其实也很简单, 主要是通过以下几步做到的:
- 编译器自动为内部类添加一个成员变量, 这个成员变量的类型和外部类的类型相同, 这个成员变量就是指向外部类对象的引用;
- 编译器自动为内部类的构造方法添加一个参数, 参数的类型是外部类的类型, 在构造方法内部使用这个参数为1中添加的成员变量赋值;
- 在调用内部类的构造函数初始化内部类对象时, 会默认传入外部类的引用。
其实内部类可以访问类这个细节我们都知道,可是为什么呢?这就需要我们有思考问题的能力,深入探究细节,知其然和知其所以然,思维方式需要转变,深入的去考虑问题,不要只停留在表面,这也是自己需要提升的地方。
2017-08-29
字节数组转16进制字符串
对每一个字节,先和0xFF做与运算,然后使用Integer.toHexString()函数,如果结果只有1位,需要在前面加0。
/*
* 字节数组转16进制字符串
*/
public static String bytes2HexString(byte[] b) {
String r = "";
for (int i = 0; i < b.length; i++) {
String hex = Integer.toHexString(b[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
r += hex.toUpperCase();
}
return r;
}