JAVA的并发编程(四): 线程的通信
目录
一、JAVA的线程通信
1. 线程通信的4种模式
模式 #1:利用共享变量来做控制,通过4种不同的方案来实现;
模式 #2:利用java提供的同步辅助类CyclicBarrier实现
引申:CountDownLatch与CyclicBarrier使用场景?
模式 #3:利用PipedInputStreamAPI实现;
模式 #4:利用BlockingQueue实现;
引申:用wait,notify和lock模拟LinkedBlockingQueue
2. ThreadLocal本地线程变量
(1)ThreadLocal的特性和应用场景
(2)ThreadLocal的原理简析
3. Semaphore计数信号量
一、JAVA的线程通信
线程是操作系统中独立的个体,但这些个体如果不经过特殊的处理就不能成为一个整体。线程间的通信就是成为整体的必用方案之一,可以说,使线程间进行通信后,系统之间的交互性会更强大,在大大提高CPU利用率的同时还会使程序员对各线程任务在处理的过程中进行有效地把控与监督。
1. 线程通信的4种模式
可能有人不太明白上面这段话,我们借用一个很有意思的面试题来进行说明:
“编写两个线程,一个线程打印1~52,另一个线程打印字母A~Z,打印顺序为12A34B56C……5152Z,要求使用线程间的通信。”
这是一道非常好的面试题,非常能彰显被面者关于多线程的功力。
通用代码:用来拼接和输出字符串等
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by Edison Xu on 2017/3/2.
*/
public enum Helper {
instance;
private static final ExecutorService tPool = Executors.newFixedThreadPool(2);
public static String[] buildNoArr(int max) {
String[] noArr = new String[max];
for(int i=0;i
模式 #1:利用共享变量来做控制,通过4种不同的方案来实现;
(a) 利用最基本的synchronized、notify、wait:
public class MethodOne {
private final ThreadToGo threadToGo = new ThreadToGo();
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
try {
for (int i = 0; i < arr.length; i=i+2) {
synchronized (threadToGo) {
while (threadToGo.value == 2)
threadToGo.wait();
Helper.print(arr[i], arr[i + 1]);
threadToGo.value = 2;
threadToGo.notify();
}
}
} catch (InterruptedException e) {
System.out.println("Oops...");
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
try {
for (int i = 0; i < arr.length; i++) {
synchronized (threadToGo) {
while (threadToGo.value == 1)
threadToGo.wait();
Helper.print(arr[i]);
threadToGo.value = 1;
threadToGo.notify();
}
}
} catch (InterruptedException e) {
System.out.println("Oops...");
}
}
};
}
class ThreadToGo {
int value = 1;
}
public static void main(String args[]) throws InterruptedException {
MethodOne one = new MethodOne();
Helper.instance.run(one.newThreadOne());
Helper.instance.run(one.newThreadTwo());
Helper.instance.shutdown();
}
}
(b)利用Lock和Condition:
public class MethodTwo {
private Lock lock = new ReentrantLock(true);
private Condition condition = lock.newCondition();
private final ThreadToGo threadToGo = new ThreadToGo();
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
try {
lock.lock();
while(threadToGo.value == 2)
condition.await();
Helper.print(arr[i], arr[i + 1]);
threadToGo.value = 2;
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
try {
lock.lock();
while(threadToGo.value == 1)
condition.await();
Helper.print(arr[i]);
threadToGo.value = 1;
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
};
}
class ThreadToGo {
int value = 1;
}
public static void main(String args[]) throws InterruptedException {
MethodTwo two = new MethodTwo();
Helper.instance.run(two.newThreadOne());
Helper.instance.run(two.newThreadTwo());
Helper.instance.shutdown();
}
}
(c)利用volatile:volatile修饰的变量值直接存在main memory里面,子线程对该变量的读写直接写入主内存,而不是像其它变量一样在线程工作区生成一份备份。volatile能保证所修饰的变量对于多个线程可见性,即只要被修改,其它线程读到的一定是最新的值。
这里用到了我上一篇博客中volatile的应用场景中的一种,标志变量。
public class MethodThree {
private volatile ThreadToGo threadToGo = new ThreadToGo();
class ThreadToGo {
int value = 1;
}
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
while(threadToGo.value==2){}
Helper.print(arr[i], arr[i + 1]);
threadToGo.value=2;
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
while(threadToGo.value==1){}
Helper.print(arr[i]);
threadToGo.value=1;
}
}
};
}
public static void main(String args[]) throws InterruptedException {
MethodThree three = new MethodThree();
Helper.instance.run(three.newThreadOne());
Helper.instance.run(three.newThreadTwo());
Helper.instance.shutdown();
}
}
(d)利用AtomicInteger:
public class MethodFive {
private AtomicInteger threadToGo = new AtomicInteger(1);
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
while(threadToGo.get()==2){}
Helper.print(arr[i], arr[i + 1]);
threadToGo.set(2);
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
while(threadToGo.get()==1){}
Helper.print(arr[i]);
threadToGo.set(1);
}
}
};
}
public static void main(String args[]) throws InterruptedException {
MethodFive five = new MethodFive();
Helper.instance.run(five.newThreadOne());
Helper.instance.run(five.newThreadTwo());
Helper.instance.shutdown();
}
}
模式 #2:利用java提供的同步辅助类CyclicBarrier实现
CyclicBarrier是一个同步的辅助类,允许一组线程相互之间等待,达到一个共同点,再继续执行。
它可以实现让一组线程在全部到达Barrier时(执行await()),再一起同时执行,并且所有线程释放后,还能复用它,即为Cyclic。CyclicBarrier类提供两个构造器:
public CyclicBarrier(int parties, Runnable barrierAction) {
}
public CyclicBarrier(int parties) {
}
解决方案如下
public class MethodFour{
private final CyclicBarrier barrier;
private final List list;
public MethodFour() {
list = Collections.synchronizedList(new ArrayList());
barrier = new CyclicBarrier(2,newBarrierAction());
}
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0, j=0; i < arr.length; i=i+2,j++) {
try {
list.add(arr[i]);
list.add(arr[i+1]);
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
try {
list.add(arr[i]);
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
};
}
private Runnable newBarrierAction(){
return new Runnable() {
@Override
public void run() {
Collections.sort(list);
list.forEach(c->System.out.print(c));
list.clear();
}
};
}
public static void main(String args[]){
MethodFour four = new MethodFour();
Helper.instance.run(four.newThreadOne());
Helper.instance.run(four.newThreadTwo());
Helper.instance.shutdown();
}
}
这里多说一点,这个API其实还是利用lock和condition,无非是多个线程去争抢CyclicBarrier的instance的lock罢了,最终barrierAction执行时,是在抢到CyclicBarrierinstance的那个线程上执行的。所以,这里无法保证字母和数字的插入顺序,最后通过Collections.sort()方法对list进行列。但是Collections.sort()方法针对的是首字母进行排练,所以9和10的排练会出现颠倒,推荐大家自己写个list的排序方法,进行排序。
private Runnable newBarrierAction(){
return new Runnable() {
@Override
public void run() {
Collections.sort(list);
list.forEach(c->System.out.print(c));
list.clear();
}
};
}(这里无法使用CountDownLatch来进行通信,因为他是一次性的,与需求不符。)
引申:CountDownLatch与CyclicBarrier使用场景?
官方解释:

翻译:
CountDownLatch是一个同步的辅助类,允许一个或多个线程,等待其他一组线程完成操作,再继续执行。
CyclicBarrier是一个同步的辅助类,允许一组线程相互之间等待,达到一个共同点,再继续执行。
他们都是:Synchronization aid,都在concurrent.util包下,我把它翻译成同步辅助器
CountDownLatch:
个人理解:我把他理解成倒计时锁
场景还原:一年级期末考试要开始了,监考老师发下去试卷,然后坐在讲台旁边玩着手机等待着学生答题,有的学生提前交了试卷,并约起打球了,等到最后一个学生交卷了,老师开始整理试卷,贴封条,下班,陪老婆孩子去了。
补充场景:我们在玩LOL英雄联盟时会出现十个人不同加载状态,但是最后一个人由于各种原因始终加载不了100%,于是游戏系统自动等待所有玩家的状态都准备好,才展现游戏画面。
抽象图:

每位乘客(线程)上车后,可用座位减1,直到为0,老司机就开始发车了。
CyclicBarrier:
个人理解:CyclicBarrier:可看成是个障碍,所有的线程必须到齐后才能一起通过这个障碍
场景还原:以前公司组织户外拓展活动,帮助团队建设,其中最重要一个项目就是全体员工(包括女同事,BOSS)在完成其他项目时,到达一个高达四米的高墙没有任何抓点,要求所有人,一个不能少的越过高墙,才能继续进行其他项目。
抽象图:
解放军叔叔完美配合,一个都不能少,继续完成任务。
模式 #3:利用PipedInputStreamAPI实现;
这里用流在两个线程间通信,但是Java中的Stream是单向的,所以在两个线程中分别建了一个input和output。这显然是一种很搓的方式,不过也算是一种通信方式吧……-_-T,执行的时候那种速度简直。。。。
public class MethodSix {
private final PipedInputStream inputStream1;
private final PipedOutputStream outputStream1;
private final PipedInputStream inputStream2;
private final PipedOutputStream outputStream2;
private final byte[] MSG;
public MethodSix() {
inputStream1 = new PipedInputStream();
outputStream1 = new PipedOutputStream();
inputStream2 = new PipedInputStream();
outputStream2 = new PipedOutputStream();
MSG = "Go".getBytes();
try {
inputStream1.connect(outputStream2);
inputStream2.connect(outputStream1);
} catch (IOException e) {
e.printStackTrace();
}
}
public void shutdown() throws IOException {
inputStream1.close();
inputStream2.close();
outputStream1.close();
outputStream2.close();
}
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
private PipedInputStream in = inputStream1;
private PipedOutputStream out = outputStream1;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
Helper.print(arr[i], arr[i + 1]);
try {
out.write(MSG);
byte[] inArr = new byte[2];
in.read(inArr);
while(true){
if("Go".equals(new String(inArr)))
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
private PipedInputStream in = inputStream2;
private PipedOutputStream out = outputStream2;
public void run() {
for (int i = 0; i < arr.length; i++) {
try {
byte[] inArr = new byte[2];
in.read(inArr);
while(true){
if("Go".equals(new String(inArr)))
break;
}
Helper.print(arr[i]);
out.write(MSG);
} catch (IOException e) {
e.printStackTrace();
}
}
}
};
}
public static void main(String args[]) throws IOException {
MethodSix six = new MethodSix();
Helper.instance.run(six.newThreadOne());
Helper.instance.run(six.newThreadTwo());
Helper.instance.shutdown();
six.shutdown();
}
模式 #4:利用BlockingQueue实现;
顺便总结下BlockingQueue的一些内容。
BlockingQueue定义的常用方法如下:
add(Object):把Object加到BlockingQueue里,如果BlockingQueue可以容纳,则返回true,否则抛出异常。offer(Object):表示如果可能的话,将Object加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false。put(Object):把Object加到BlockingQueue里,如果BlockingQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里有空间再继续。poll(time):获取并删除BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null。当不传入time值时,立刻返回。peek():立刻获取BlockingQueue里排在首位的对象,但不从队列里删除,如果队列为空,则返回null。take():获取并删除BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的对象被加入为止。
BlockingQueue有四个具体的实现类:
ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小。其所含的对象是以FIFO(先入先出)顺序排序的。LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定。其所含的对象是以FIFO顺序排序的。PriorityBlockingQueue:类似于LinkedBlockingQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数所带的Comparator决定的顺序。SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的。
这里我用了两种玩法:
- 一种是共享一个queue,根据
peek和poll的不同来实现; - 第二种是两个queue,利用
take()会自动阻塞来实现。
public class MethodSeven {
private final LinkedBlockingQueue queue = new LinkedBlockingQueue<>();
public Runnable newThreadOne() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
Helper.print(arr[i], arr[i + 1]);
queue.offer("TwoToGo");
while(!"OneToGo".equals(queue.peek())){}
queue.poll();
}
}
};
}
public Runnable newThreadTwo() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
while(!"TwoToGo".equals(queue.peek())){}
queue.poll();
Helper.print(arr[i]);
queue.offer("OneToGo");
}
}
};
}
private final LinkedBlockingQueue queue1 = new LinkedBlockingQueue<>();
private final LinkedBlockingQueue queue2 = new LinkedBlockingQueue<>();
public Runnable newThreadThree() {
final String[] inputArr = Helper.buildNoArr(52);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i=i+2) {
Helper.print(arr[i], arr[i + 1]);
try {
queue2.put("TwoToGo");
queue1.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
}
public Runnable newThreadFour() {
final String[] inputArr = Helper.buildCharArr(26);
return new Runnable() {
private String[] arr = inputArr;
public void run() {
for (int i = 0; i < arr.length; i++) {
try {
queue2.take();
Helper.print(arr[i]);
queue1.put("OneToGo");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
}
public static void main(String args[]) throws InterruptedException {
MethodSeven seven = new MethodSeven();
Helper.instance.run(seven.newThreadOne());
Helper.instance.run(seven.newThreadTwo());
Thread.sleep(2000);
System.out.println("");
Helper.instance.run(seven.newThreadThree());
Helper.instance.run(seven.newThreadFour());
Helper.instance.shutdown();
}
引申:用wait,notify和lock模拟LinkedBlockingQueue
利用线程通信的方式,模拟阻塞队列
当队列不为空时,取出队列中的数据,否则阻塞。
当队列装满时,阻塞数据的插入。
public class MyQueue {
//1 需要一个承装元素的集合
private LinkedList2. ThreadLocal本地线程变量
(1)ThreadLocal的特性和应用场景
ThreadLocal,很多地方叫做本地线程变量,也有些地方叫做本地线程存储,其实意思差不多。可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
public class ConnThreadLocal {
public static ThreadLocal th = new ThreadLocal();
public void setTh(String value){
th.set(value);
}
public void getTh(){
System.out.println(Thread.currentThread().getName() + ":" + this.th.get());
}
public static void main(String[] args) throws InterruptedException {
final ConnThreadLocal ct = new ConnThreadLocal();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
ct.setTh("张三");
ct.getTh();
}
}, "t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
ct.getTh();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t2");
t1.start();
t2.start();
}
} 执行结果为,显然线程t2并没有拿到t1放置在ThreadLocal中的值,他在线程之间是独立的。
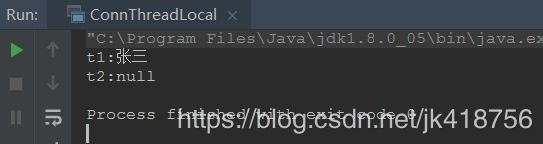
上面这个例子我们可以得知ThreadLocal的特性,但是如何使用还是一头雾水。
我们再来看一个例子:
class ConnectionManager {
private static Connection connect = null;
public static Connection openConnection() {
if(connect == null){
connect = DriverManager.getConnection();
}
return connect;
}
public static void closeConnection() {
if(connect!=null)
connect.close();
}
}假设有这样一个数据库链接管理类,这段代码在单线程中使用是没有任何问题的,但是如果在多线程中使用呢?很显然,在多线程中使用会存在线程安全问题:第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
所以出于线程安全的考虑,必须将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理。
这样将会大大影响程序执行效率,因为一个线程在使用connect进行数据库操作的时候,其他线程只有等待。
那么大家来仔细分析一下这个问题,这地方到底需不需要将connect变量进行共享?事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。
到这里,可能会有朋友想到,既然不需要在线程之间共享这个变量,可以直接这样处理,在每个需要使用数据库连接的方法中具体使用时才创建数据库链接,然后在方法调用完毕再释放这个连接。这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。由于在方法中需要频繁地开启和关闭数据库连接,这样不尽严重影响程序执行效率,还可能导致服务器压力巨大。
那么在这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。
但是要注意,虽然ThreadLocal能够解决上面说的问题,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。Threadlocal在处理一些需要在线程内共享的变量时,有着显著作用
(2)ThreadLocal的原理简析
在上面谈到了对ThreadLocal的一些理解,那我们下面来看一下具体ThreadLocal是如何实现的。
先了解一下ThreadLocal类提供的几个方法:
public T get() { }
public void set(T value) { }
public void remove() { }
protected T initialValue() { }get()方法是用来获取ThreadLocal在当前线程中保存的变量副本,set()用来设置当前线程中变量的副本,remove()用来移除当前线程中变量的副本,initialValue()是一个protected方法,一般是用来在使用时进行重写的,它是一个延迟加载方法。
下面详细说明set方法,我们来看一下ThreadLocal类是如何为每个线程创建一个变量的副本的。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}我们可以看到他干了这么一些事情
获取当前线程,调用getmap()方法尝试获取map
如果map!= null 则以当前线程为key,存入的值为value存入map
如果map = null 则创建map,存入key-value
在观察他调用的方法getmap()
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
得知,他尝试获取的map其实就是Thread类下的一个内部成员threadLocals
类型为ThreadLocal下的一个内部类ThreadLocalMap
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;至此,可能大部分朋友已经明白了ThreadLocal是如何为每个线程创建变量的副本的:
首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。
然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。其他方法大家有空可以去看下ThreadLocal的源码,还是挺清晰的。
3. Semaphore计数信号量
Semaphore管理一系列许可证。每个acquire方法阻塞,直到有一个许可证可以获得然后拿走一个许可证;每个release方法增加一个许可证,这可能会释放一个阻塞的acquire方法。然而,其实并没有实际的许可证这个对象,Semaphore只是维持了一个可获得许可证的数量。
Semaphore经常用于限制获取某种资源的线程数量。下面举个例子,比如说操场上有5个跑道,一个跑道一次只能有一个学生在上面跑步,一旦所有跑道在使用,那么后面的学生就需要等待,直到有一个学生不跑了,下面是这个例子:
public class UseSemaphore {
public static void main(String[] args) {
// 线程池
ExecutorService exec = Executors.newCachedThreadPool();
// 只能5个线程同时访问
final Semaphore semp = new Semaphore(5);
// 模拟20个客户端访问
for (int index = 0; index < 20; index++) {
final int NO = index;
Runnable run = new Runnable() {
public void run() {
try {
// 获取许可
semp.acquire();
System.out.println("Accessing: " + NO);
//模拟实际业务逻辑
Thread.sleep((long) (Math.random() * 10000));
// 访问完后,释放
semp.release();
} catch (InterruptedException e) {
}
}
};
exec.execute(run);
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(semp.getQueueLength());//等待限线程数
exec.shutdown(); // 退出线程池
}
} 执行结果为:
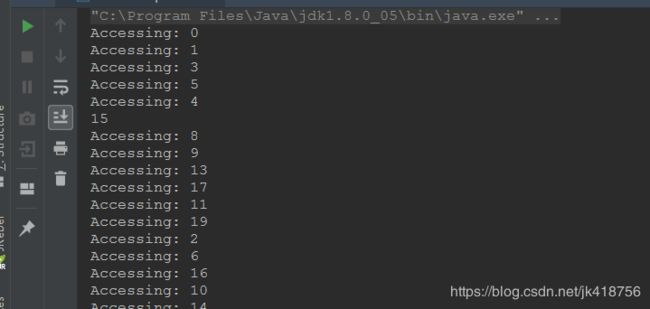
5个人进入了跑道,然后有15个人在等待,每有一个人结束跑步归还许可证,后面的人才能进入跑道跑步
在开发中,Semaphore信号量非常适合高并发访问。在新系统上线前,要对系统的访问量进行评估,当然这个值不是随随便便拍拍脑袋就能想出来的,是经过以往的经验、数据、历年的访问量,已经脱光力度进行一个合理的评估,当然评估标准不能太大也不能太小,太大的话投入的资源打不到实际效果,纯粹浪费资源,太小的话,某个时间点一个高峰值的访问量上来直接可以压垮系统。
PV(page view)网站的总访问量,页面浏览量或点击量,用户每刷新一次就会被记录一次
UV(unique Visitor)访问网站的一台年闹为一个访客,一般来讲,时间上以00:00-24:00之间相同的ip的客户端只记录一次。
QPS(query per second)既每秒查询数,qps很大程度上代表了系统业务上的繁忙程度,每次请求的背后,可能对应着多次的磁盘I/0,对此网络请求,多个cpu时间片等。我们通过qps可以非常直观的了解当前系统的业务情况。一但当前qps超过所设定的预警阀值,可以考虑增加机器对集群扩容,以免压力过大导致宕机。可以根据前期的压力测试得到估值,再结合后期综合运维情况,估算出阀值。
RT(response tome)既请求的响应时间,这个指标直接说明了前端用户的体验,因此任何系统设计师都想降低RT时间
当然还涉及cpu、内存、网络、磁盘等情况,细节的问题更多,如select、update、delete/ps等数据层面的设计。
容量评估:一般般来说,通过开发、运维、测试、以及业务等相关人员,综合出系统的一系列阀值,然后我们根据阀值如qps、rt等,对系统进行有效的变。
一般来说,我们进行多伦压力测试以后,可以对系统进行峰值评估,采用所谓的80/20原则,既80%的访问请求将在20%的时间内达到,这样我们可以根据系统对应的PV计算出峰值qps。
峰值qps =(总PV * 20%)/(60*60*24*20%)
然后再将总的峰值qps除以单台机器所能承受的最高qps值,就是所需要的机器数量。
机器数量 = 总的峰值qps/压测得出的单机极限qps
当然不排除系统在上线前进行大型促销活动,或者双十一、双十二热点事件、遭受DDos攻击和被爬库等情况,系统的开发和运维人员需要了解当前系统的运行状态和负载情况,通常有专用的后台系统来维护。
PS:博文仅作为个人学习笔记,如有错误欢迎指正,转载请注明出处~
详见:笔记分类导航目录
参考文档:
1. JAVA线程间通信的几种方式
2. 你真的理解CountDownLatch与CyclicBarrier使用场景吗?
3. Java并发编程:深入剖析ThreadLocal