python实现vip视频解析爬取
https://blog.csdn.net/u013589137/article/details/80683905?utm_source=blogxgwz0
转载请注明作者和出处:http://blog.csdn.net/c406495762
运行平台: Windows
Python版本: Python3.x
IDE: Sublime text3
一、前言
没有会员,想在线观看或下载爱奇艺、PPTV、优酷、网易公开课、腾讯视频、搜狐视频、乐视、土豆、A站、B站等主流视频网站的VIP视频?又不想充会员怎么办?博主本次写的VIP视频破解助手也许可以帮你解决烦恼。
PS:本软件只用来交流学习,请勿用于商业用途。如涉及版权侵权等问题,请联系我,我会删除文章。我可是守法的好公民….
二、软件使用说明
1、软件下载
软件运行平台:Windows
注意:该软件已经打包成exe可执行文件,无需Python环境即可运行。将软件压缩包解压,即可使用。
百度云盘下载地址:链接:http://pan.baidu.com/s/1bp8aMPD 密码:otw8
exe可执行文件,即助手软件保存在dist文件夹下:

运行软件,如果误报木马。将此应用程序添加到信任区,或者关闭杀毒软件,即可。PS:软件无毒,可放心使用。
2、在线播放视频(以爱奇艺为例讲解)
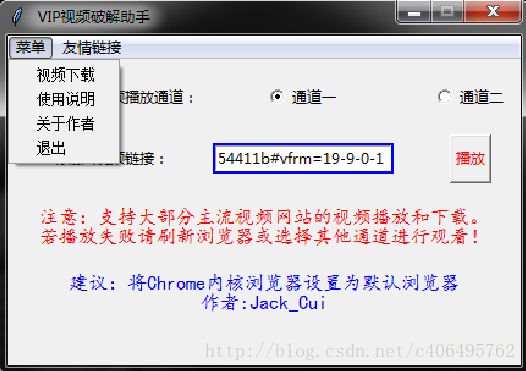
在主界面我们可以选择视频的播放通道(默认通道一)。在视频连接文本框中输入视频连接,点击播放按钮,该助手软件将启动默认浏览器,视频即可在线观看。
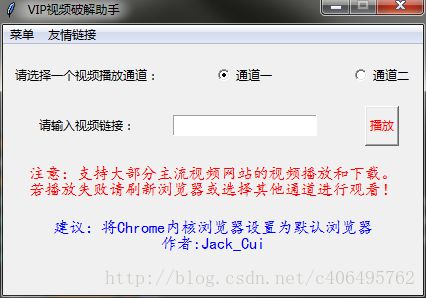
视频连接如何获取呢?
在菜单栏的友情链接的下拉列表中,我们可以选择打开一个我们喜欢的视频网站,比如点击爱奇艺,默认浏览器将自动打开爱奇艺首页。

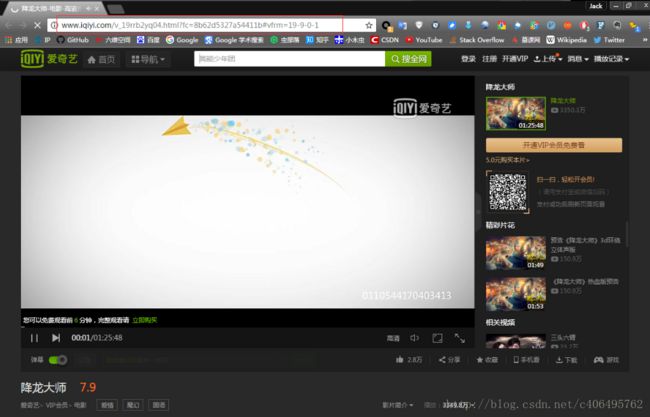
选择一部自己喜欢的电影,浏览器地址栏的内容即为视频连接。
降龙大师:URL:http://www.iqiyi.com/v_19rrb2yq04.html?fc=8b62d5327a54411b#vfrm=19-9-0-1
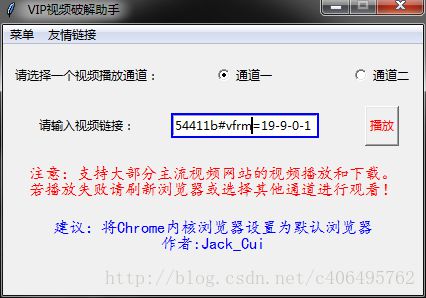
在助手软件文本输入框中输入地址,点击播放即可在线观看视频:
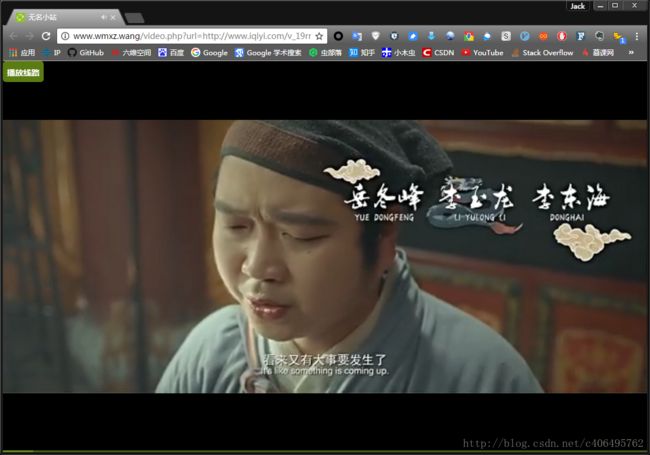
3、视频下载(以爱奇艺为例讲解 )
注意:暂只支持爱奇艺和优酷的视频下载,视频在线观看不受影响。
点击菜单,出现下拉菜单,在下拉菜单选择视频下载(注意:请先添加视频连接)
此时,默认浏览器会打开网页,等待几秒钟,待加载完成,点击下图按钮,即可通过浏览器下载视频。

三、代码编写
介绍完该助手软件,进入本次爬虫教程的正题:视频抓包
1、软件原理:
a)视频播放
在讲解视频抓包之前,先介绍下两个视频解析网站:
- VIP视频解析:http://www.vipjiexi.com/
- 无名小站:http://www.wmxz.wang/
这两个网站为我们提供了免费的视频解析,他们的通用解析方式是:
VIP视频解析: http://www.vipjiexi.com/tong.php?url=[播放地址或视频id]
无名小站:http://www.wmxz.wang/video.php?url=[播放地址或视频id]
笔者正式调用了这两个网站,实现视频在线播放的。至于,视频下载界面如何调出,即是本文的重点。
b)视频下载
这两个网站均没有提供下载功能,当然如果你使用chrome视频抓包插件,也可以实现视频的下载,例如使用chrome插件:Flash Video Downloader。不过为了学习,我们使用python程序进行抓包。因此,笔者使用无名小站进行视频下载,对无名小站视频进行抓包分析。
看过笔者之前的Python3网络爬虫的读者,一定知道如何进行抓包分析,在这里不再啰嗦,直接进入正题:我们可以看到这里有一个POST请求,Form Data中有两个参数,一个是up,另一个是url。因此,我们向服务器发送这个数据请求,对返回的数据进行json解析,即可得到视频的真实地址,打开这个视频的真实地址,就会出现之前介绍的现在视频的浏览器界面。仅仅这样就可以了吗?其实不然,因为如果你单纯使用这种方法,我们只能下载我们抓包分析时的视频。因为,这个url是随着我们解析视频的不同而改变的,因此如何获取这个改变的url,成为我们下一步的重点。

继续分析我们会发现在发送POST请求之前,有一个GET请求,如果我们向这个Request URL的地址发送GET请求,你会惊奇的发现,返回的信息里包含我们需要的url信息。

它是这个样子的:

瞧,url我们就这样得到了,通过相应的解析,提取出url信息,并将这个url信息作为之前提到的POST请求的Form Data,这样我们就可以得到真实的视频地址,通过该地址即可进行视频下载,代码如下:
#-*-coding:utf-8-*-
import re
import json
from bs4 import BeautifulSoup
from urllib import request, parse
if __name__ == '__main__':
ip = 'http://www.iqiyi.com/v_19rrb2yq04.html?fc=8b62d5327a54411b#vfrm=19-9-0-1'
get_url = 'http://www.sfsft.com/index.php?url=%s' % ip
get_movie_url = 'http://www.sfsft.com/api.php'
head = {
'User-Agent':'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19',
'Referer':'http://www.sfsft.com/index.php?url=%s' % ip
}
get_url_req = request.Request(url = get_url, headers = head)
get_url_response = request.urlopen(get_url_req)
get_url_html = get_url_response.read().decode('utf-8')
bf = BeautifulSoup(get_url_html, 'lxml')
a = str(bf.find_all('script'))
pattern = re.compile("url : '(.+)',", re.IGNORECASE)
url = pattern.findall(a)[0]
get_movie_data = {
'up':'0',
'url':'%s' % url,
}
get_movie_req = request.Request(url = get_movie_url, headers = head)
get_movie_data = parse.urlencode(get_movie_data).encode('utf-8')
get_movie_response = request.urlopen(get_movie_req, get_movie_data)
get_movie_html = get_movie_response.read().decode('utf-8')
print(get_movie_data['url'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
运行结果如下图所示:
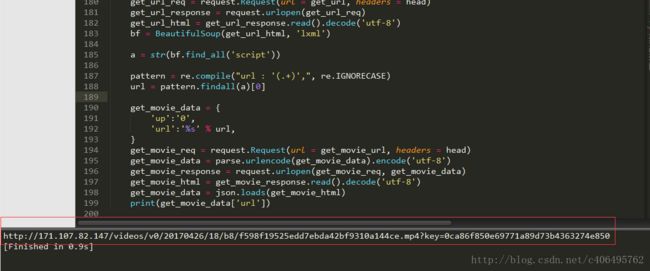
在浏览器中打开这个地址,即可出现上面提到的视频下载界面。同时,更改代码中的ip,即视频连接地址,即可解析不同的视频的真实视频地址,并对其进行下载。
2、Tkinter
该助手软件的界面是使用Python的Tkinter设计的,由于本部分内容不是Python网络爬虫的重点,因此不在此进行讲解。
仅用于学习交流,思路如上