memcached内存分配及回收初探
mc简介:
mc是由LiveJournal技术团队开发的一套分布式对象缓存系统,基于c语言,目前应用十分广泛,它可以应对任意多个连接,使用非阻塞的网络I/O。它的使用非常简单和方便,最常用的功能不超过5个方法(set,get,delete...)。目前pconline的网站群基本上都是使用mc做缓存服务
mc在很多时候都是作为数据库前端缓冲使用的。因为它比数据库少了SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的, 所以它可以提供比直接读取数据库更好的性能,在大型bbs系统中,访问同样的数据是很频繁的,mc可以大大降低数据库压力,使系统执行效率提升。 另外,mc也经常作为服务器之间数据共享的存储媒介,例如在SSO系统中保存系统单点登陆状态的数据就可以保存在mc中,被多个应用共享。
命题提出
前段时间登录系统出现了一个比较怪异的问题,刚刚登录的用户,还未到session过期时间就开始抛空异常,查看mc内存利用率不到60%,检查重启mc后问题得到缓解,后来小虎分析可能是mc中缓存的未过期数据被冲掉,于是有了下面的分析
mc内存分配机制简介
memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
先来解释一下与Slab Allocator存储有关的几个术语:
Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk:用于缓存记录的内存空间。
Slab Class:特定大小的chunk的组。
Growth Factor:增长因数,默认为1.25(较早的版本固定为2)
mc启动后,会根据这个factor,计算出从1M逐步递减的不同的slab,如factor=1.25时:
-
- slab class 2: chunk size 112 perslab 9362
- slab class 3: chunk size 144 perslab 7281
- slab class 4: chunk size 184 perslab 5698
- slab class 5: chunk size 232 perslab 4519
- slab class 6: chunk size 296 perslab 3542
- slab class 7: chunk size 376 perslab 2788
- slab class 8: chunk size 472 perslab 2221
- slab class 9: chunk size 592 perslab 1771
- slab class 10: chunk size 744 perslab 1409
- ...
第一列数据(slab class),为slab的编号;
第二列数据是chunk的大小,跟slab class是一一对应的关系,可以通俗的理解为slab就是存放一组相同大小chunk的集合,只不过这个集合是固定的(1M),
第三列数据,表示每种不同slab中的page可以存放的chunk个数,实际上等于1MB/ (chunk size),例如slab1中的chunk size是88B,那么这种slab中每个page中可以存放的chunk个数为 1MB / 88B ,约等于11915
很显然,slab的chunk size越大,其中的每个page包含的chunk数量就越少
如图所示:

新入对象时,会根据自身大小来匹配slab列表,比如100KB的对象,根据最小空间损失原则,会被放入到slab2(size:112B)对应的page下,如下图
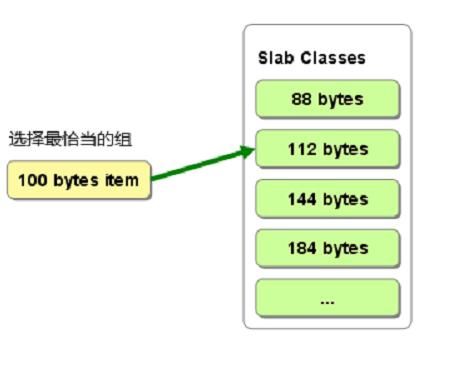
这时,如果slab2下的page中有尚可以使用的chunk(即空闲的chunk或者过期的chunk),slab2会优先使用这些chunk,在没有chunk可用的情况下,mc会去内存中再申请一个page,然后切分成chunk,然后使用;需要注意的是,根据 Slab Allocator算法, 该实例中的100KB对象,是永远没有机会存放到其他slab(如slab3,slab4等等),即便是其他slab中有大量的可用chunk,细心的朋友会发现,这种机制很有可能会导致内存浪费严重,mc命中率降低等问题,对,这种问题真的存在,这也正是这种机制的缺点,下面会进行详细的分析和探讨
mc数据删除机制简介:
首先我们知道,缓存在mc中的数据,不会主动从内存中消失,也就是说mc不会监视记录是否过期,而是在client端执行get方法时才去检查时间戳是否过期(这样做的目的就是避免在过期监视上耗费cpu资源,以提高mc的响应能力);每次有新对象加入时,mc会优先将对象置于已超时的同一规格chunk中,然而,即使如此,内存仍然会发生追加新记录时空间不足的情况,那么,当mc内存耗完后,又是怎样处理新入的数据呢?mc有两种处理策略,一种是默认的LRU(Least Recently Used),指删除近段时间最少使用同规格chunk,再将对象塞入),另一种策略是存满即不可再存,除非有过期的对象,否则会报错
再回头看问题:
想必各位已经发现我们的登录状态数据是怎么被冲走的了,对,没错,LRU!在内存还有将近一半的情况下,就发生了LRU,为什么呢?这一半空闲的内存,表面是空闲的,实际上已经被mc将其打包成page分配到了其他stat里,而这些stat即便空闲、数据过期,也不会被mc回收已供其他繁忙的slab调用的。产生这种情况的直接原因就是,mc启动后,较大chunk size的slab同时间大量涌入mc,假设slab为20,这时,mc不得为slab 20分配大量的page,而在一小段时间后,slab 20中的chunk纷纷过期,但是它们曾经占用的page就永远不会被mc主动回收了,除非再有与slab20同规格的对象进入时,这些page才会重新得到使用的机会,与此形成强烈对比的slab2(chunk size = 112B)却处于无可用chunk,无内存已供分配新page的境地,这个时候,LRU出场了,会按时间相关度清理掉一些尚未过期的slab2 chunk,如此造成缓存来去匆匆,实际上性能严重下降
LRU:
首先,在memcache分配的时候,初始化会去分配一系列的slab,例如初始的slab为88k,然后factor为1.25,那么你会发现开始的时候 就会有:88,112,44,....一直到1M大小的slab各一个,假如对象集中在其中某一个区间,那么很快那个slab就会分配满,此时如果内存还有,那么就会新建一个同样大小的slab作为链挂在第一个同等大小的slab上,如果说内存也满了,slab也满了,那么就开始LRU算法了。
但是Memcached的LRU算法是针对slab的,而非全局的,如果数据集中在一个slab上,那么初始化的时候其他几个slab肯定就浪费了,同时,如果slab的大小和对象的大小有比较大的差异,那么浪费的将会更加巨大。所以在评估使用 memcache初始大小和factor的时候需要注意这些,选择适合的初始化size和factor,减少slab分配的浪费。
解决思路
思路1.通用解决方法: 调整growth factor
逐步调整growth factor,并观察chunks的分布,尽量将数据对象的大小控制到一定区间内,启动时加入-f参数即可,在factor=1.25时有39组slab
- $memcached -m 5 -vv -l localhost -p 11211 -f 1.25s
- slab class 1: chunk size 88 perslab 11915
- slab class 2: chunk size 112 perslab 9362
- slab class 3: chunk size 144 perslab 7281
- slab class 4: chunk size 184 perslab 5698
- slab class 5: chunk size 232 perslab 4519
- slab class 6: chunk size 296 perslab 3542
- slab class 7: chunk size 376 perslab 2788
- slab class 8: chunk size 472 perslab 2221
- slab class 9: chunk size 592 perslab 1771
- slab class 10: chunk size 744 perslab 1409
- slab class 11: chunk size 936 perslab 1120
- slab class 12: chunk size 1176 perslab 891
- slab class 13: chunk size 1472 perslab 712
- slab class 14: chunk size 1840 perslab 569
- ...
- slab class 36: chunk size 250376 perslab 4
- slab class 37: chunk size 312976 perslab 3
- slab class 38: chunk size 391224 perslab 2
- slab class 39: chunk size 489032 perslab 2
当growth factor调大成2以后,slab class明显变少,只有13组了
- $memcached -m 5 -vv -l localhost -p 11211 -f 2
- slab class 1: chunk size 128 perslab 8192
- slab class 2: chunk size 256 perslab 4096
- slab class 3: chunk size 512 perslab 2048
- slab class 4: chunk size 1024 perslab 1024
- slab class 5: chunk size 2048 perslab 512
- slab class 6: chunk size 4096 perslab 256
- slab class 7: chunk size 8192 perslab 128
- slab class 8: chunk size 16384 perslab 64
- slab class 9: chunk size 32768 perslab 32
- slab class 10: chunk size 65536 perslab 16
- slab class 11: chunk size 131072 perslab 8
- slab class 12: chunk size 262144 perslab 4
- slab class 13: chunk size 524288 perslab 2
很显然,factor越小,chunk匹配得就越精准,但是slab组就会分得越多,而产生LRU的机会也会增加,factor越大,分组就越少,产生LRU的机会就越小,但是chunk匹配精准度会有所下降,如在数据大小为130B时,如果f=1.25,mc会将其放入class3(chunk size = 144B),浪费的空间为14B;如果f=2.0,mc会将其放入class2(class size = 256)中,浪费的空间为126B,相当惊人,所以factor的大小设置在一个比较平衡的值,一般以默认的1.25较为理想。
思路2.动态调整slab中page的数量
大体思路是使用java客户端监控程序,定时检查每个slab的使用情况,动态调整每个slab中的page,将某个比较空闲的slab中的page移动到另外的slab中去,不过mc的开发人员认为在mc中遍历slab和page移动会造成较大系统开销,所有没有提供直接的api已供调用,一直屏蔽调用,在1.28版本以前,还可以通过在memcached.h中添加宏#define ALL_SLABS_REASIGN并重新编译使slabs reassign命令生效,但在使用过程中,出现了大量的性能问题,mc稳定性下降,而且在数据移动过程中,会导致mc不可写的问题,针对这些弊端,mc的开发团队在其后续版本中已经彻底删除相关处理逻辑,我也尝试对1.28的源码进行修改和编译,基本可用,但是何时调用 reassign,以及reassign后对系统造成的影响仍然需要进一步的数据分析,继续跟进中。。。