hadoop的安装配置入门
hadoop
开源软件,可靠的、分布式、可伸缩的。
大数据
去IOE
IBM //ibm小型机.
Oracle //oracle数据库服务器 RAC
EMC //EMC共享存储设备。
Cluster
集群。
1T = 1024G 1P = 1024T 1E = 1024P 1Z = 1024E 1Y = 1024Z 1N = 1024Y
海量数据
PB.
RAID 冗余 数据的交互方式
磁盘阵列。
大数据解决了两个问题
1.存储
分布式存储
2.计算
分布式计算
分布式
由分布在不同主机上的进程协同在一起,才能构成整个应用。
B/S
Browser / http server:瘦客户端.
failure over //容灾(硬件故障) fault over //容错(软件故障)
云计算
1.服务。
3.虚拟化.
大数据的四个V特征
1.volume //体量大
2.variety //样式多.
结构化数据:关系型数据库里的数据
半结构化数据:excel
非结构化数据:文本
3.velocity //速度快
4.valueless //价值密度低
hadoop四个模块
1.common
2.hdfs 映射和化简
3.hadoop yarn
4.hadooop mapreduce(mr)
安装hadoop
1.安装jdk
a)下载jdk-8u65-linux-x64.tar.gz(不用rpm文件,它按照时是打散的)
b)tar开
$>su centos ; cd ~
$>mkdir downloads
$>cp /mnt/hdfs/downloads/bigdata/jdk-8u65-linux-x64.tar.gz ~/downlooads
$>tar -xzvf jdk-8u65-linux-x64.tar.gz
c)创建/soft文件夹
$>sudo mkdir /soft
$>sudo chown centos:centos /soft
d)移动tar开的文件到/soft下
$>mv ~/downloads/jdk-1.8.0_65 /soft/
e)创建符号连接
$>ln -s /soft/jdk-1.8.0_65 /soft/jdk
f)验证jdk安装是否成功
$>cd /soft/jdk/bin
$>./java -version
centos配置环境变量
1.编辑/etc/profile
$>sudo nano /etc/profile
...
export JAVA_HOME=/soft/jdk //导入export
export PATH=$PATH:$JAVA_HOME/bin //:linux的环境变量分隔符
2.使环境变量即刻生效
$>source /etc/profile
3.进入任意目录下,测试是否ok
$>cd ~
$>java -version
安装hadoop
1.安装hadoop
a)下载hadoop-2.7.3.tar.gz
b)tar开
$>su centos ; cd ~
$>cp /mnt/hdfs/downloads/bigdata/hadoop-2.7.3.tar.gz ~/downloads
$>tar -xzvf hadoop-2.7.3.tar.gz
c)无
d)移动tar开的文件到/soft下
$>mv ~/downloads/hadoop-2.7.3 /soft/
e)创建符号连接
$>ln -s /soft/hadoop-2.7.3 /soft/hadoop
f)验证jdk安装是否成功
$>cd /soft/hadoop/bin
$>./hadoop version
2.配置hadoop环境变量
$>sudo nano /etc/profile
...
export JAVA_HOME=/soft/jdk
exprot PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.生效
$>source /etc/profile
4、hdfs
/soft/hadoop/bin/hdfs hdfs-->是操作hadoop文件系统的执行文件
hdfs ->dfs->-ls /(一级一级的子命令)列出了centos的根目录下的东西
配置hadoop
1.standalone(local)本地模式(用的就是本地操作系统的文件系统)
nothing !
不需要启用单独的hadoop进程。
2.Pseudodistributed mode
伪分布模式。
a)进入${HADOOP_HOME}/etc/hadoop目录
b)编辑core-site.xml
fs.defaultFS
hdfs://localhost/
c)编辑hdfs-site.xml --》(replication)副本,伪分布模式只有一个节点,只能有一个副本(也可以说没有副本,只有自身),所以值为1
dfs.replication
1
d)编辑mapred-site.xml framework 框架,yarn
注意:cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
e)编辑yarn-site.xml --》resourcemanager.hostname资源管理器主机名 ,ux-services辅助服务
yarn.resourcemanager.hostname
localhost
yarn.nodemanager.aux-services
mapreduce_shuffle
文件件.d是目录,文件d是daemon,是守护进程即服务
f)配置SSH
1)检查是否安装了ssh相关软件包(openssh-server + openssh-clients + openssh)
$yum list installed | grep ssh
2)检查是否启动了sshd进程(sshd进程在openssh-server软件包中,必须在服务器端,ssh命令在openssh-client软件包中,安装在客户端)
$>ps -Af | grep sshd
3)在client侧生成公私秘钥对(生成秘钥对的命令是ssh-keygen,在openssh软件包中)。
(rsa是算法,不可逆的;-P(密码是空的)‘’,无内容 -f:是把生成秘钥对放在哪个文件夹下)
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
4)生成~/.ssh文件夹(存放秘钥的地方),里面有id_rsa(私钥) + id_rsa.pub(公钥)
5)追加公钥到~/.ssh/authorized_keys(认证的keys)文件中(文件名、位置固定)
$>cd ~/.ssh
$>cat id_rsa.pub >> authorized_keys
6)修改authorized_keys的权限为644.(只有自己具有写权限。所属组和其他人都不能具有写权限)
$>chmod 644 authorized_keys
7)测试
$>ssh localhost
hadoop
1.独立模式(standalone|local)
nothing!
本地文件系统。
不需要启用单独进程。
2.pseudo-distributed(伪分布模式)
等同于完全分布式,只有一个节点。
SSH: //(Socket),
//public + private
//server : sshd ps -Af | grep sshd
//clint : ssh
//ssh-keygen:生成公私秘钥。
//authorized_keys 需要使用644
//ssh 192.168.231.201 yes
[配置文件]
core-site.xml //fs.defaultFS=hdfs://localhost/
hdfs-site.xml //replication=1
mapred-site.xml //
yarn-site.xml //
3.full distributed(完全分布式)
处理不能启动五个进程的方法
1.rm -rf /tmp/*
2.
让命令行提示符显式完整路径
1.编辑profile文件,添加环境变量PS1
[/etc/profile] // \u是用户,@是固定的,\h是主机;‘pwd’:当前路径,‘’是强行命令解析;
export PS1='[\u@\h `pwd`]\$' //注意pwd包括的是反引号``
2.source
$>source /etc/profile
配置hadoop,使用符号连接的方式,让三种配置形态共存。
1.在/soft/hadoop/etc下创建三个配置目录,内容等同于hadoop目录
${hadoop_home}/etc/local
${hadoop_home}/etc/pesudo
${hadoop_home}/etc/full
2.创建符号连接
$>ln -s
3.对hdfs进行格式化
$>hadoop namenode -format
4.修改hadoop配置文件,手动指定JAVA_HOME环境变量(env是环境意思)
[${hadoop_home}/etc/hadoop/hadoop-env.sh]
...
export JAVA_HOME=/soft/jdk
...
5.启动hadoop的所有进程(start-all.sh是一个可执行文件,在/sort/hadoop/sbin/下面)
$>start-all.sh
6.启动完成后,出现以下5个进程
$>jps
33702 NameNode //名称节点是目录
33792 DataNode //数据节点
33954 SecondaryNameNode //辅助名称节点
29041 ResourceManager
34191 NodeManager
7.查看hdfs文件系统
$>hdfs dfs -ls /
8.创建目录 -p:parent父目录
$>hdfs dfs -mkdir -p /user/centos/hadoop
9.通过webui查看hadoop的文件系统
http://localhost:50070/
或者:hdfs dfs -ls /
10.停止hadoop所有进程
$>stop-all.sh
11.centos防火墙操作
[cnetos 6.5之前的版本]
$>sudo service firewalld stop //停止服务
$>sudo service firewalld start //启动服务
$>sudo service firewalld status //查看状态
[centos7]
$>sudo systemctl enable firewalld.service //"开机启动"启用
$>sudo systemctl disable firewalld.service //"开机自启"禁用
$>sudo systemctl start firewalld.service //启动防火墙
$>sudo systemctl stop firewalld.service //停止防火墙
$>sudo systemctl status firewalld.service //查看防火墙状态
[开机自启]
$>sudo chkconfig firewalld on //"开启自启"启用
$>sudo chkconfig firewalld off //"开启自启"禁用
kill -9 进程号 杀死进程 9是绝杀的意思
hadoop的端口
50070 //namenode http port
50075 //datanode http port
50090 //2namenode http port
8020 //namenode rpc port rpc用于远程通信的
50010 //datanode rpc port
hadoop四大模块
common //公共模块
hdfs //namenode(主控方) + datanode + secondarynamenode
mapred
yarn //resourcemanager + nodemanager
启动脚本
1.start-all.sh //启动所有进程
2.stop-all.sh //停止所有进程
3.start-dfs.sh //启动存储进程
NameNode ,DateNode,secondarynamenode
4.start-yarn.sh //启动计算进行
resourcemanager + nodemanager
[hdfs] start-dfs.sh stop-dfs.sh
NN
DN
2NN
[yarn] start-yarn.sh stop-yarn.sh
RM
NM
修改主机名
1./etc/hostname
s201
2./etc/hosts
127.0.0.1 localhost
192.168.231.201 s201
192.168.231.202 s202
192.168.231.203 s203
192.168.231.204 s204
完全分布式
1.克隆3台client(centos7)
右键centos-7-->管理->克隆-> ... -> 完整克隆
2.启动client
3.启用客户机共享文件夹。
4.修改hostname、hosts和静态ip地址文件
[/etc/hostname]
s202
[/etc/hosts]
192.168.43.202 s202
[/etc/sysconfig/network-scripts/ifcfg-ethxxxx]
...
IPADDR=192.168.43.202
5.重启网络服务
$>sudo service network restart
6.修改/etc/resolv.conf文件
nameserver 192.168.231.2
7.重复以上3 ~ 6过程.
准备完全分布式主机的ssh
1.删除所有主机上的/home/centos/.ssh/*
2.在s201主机上生成密钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3.将s201的公钥文件id_rsa.pub远程复制到202 ~ 204主机上。(scp远程复制)
并放置/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s201:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s202:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s203:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s204:/home/centos/.ssh/authorized_keys
4.配置完全分布式(${hadoop_home}/etc/hadoop/)
1.[core-site.xml] //决定是namenode(名称节点)原因所在,所有节点都配置为哪一个节点,则该节点为名称节点
fs.defaultFS
hdfs://s201/
2.[hdfs-site.xml] //决定数据备份的个数
dfs.replication
3
3.[mapred-site.xml]
不变
4.[yarn-site.xml]
yarn.resourcemanager.hostname
s201
yarn.nodemanager.aux-services
mapreduce_shuffle
5.[slaves] //决定数据节点原因所在
s202
s203
s204
6 [hadoop-env.sh]
...
export JAVA_HOME=/soft/jdk
...
5.分发配置
$>cd /soft/hadoop/etc/
$>scp -r full centos@s202:/soft/hadoop/etc/
$>scp -r full centos@s203:/soft/hadoop/etc/
$>scp -r full centos@s204:/soft/hadoop/etc/
6.删除符号连接
$>cd /soft/hadoop/etc
$>rm hadoop
$>ssh s202 rm /soft/hadoop/etc/hadoop
$>ssh s203 rm /soft/hadoop/etc/hadoop
$>ssh s204 rm /soft/hadoop/etc/hadoop
7.创建符号连接
$>cd /soft/hadoop/etc/
$>ln -s full hadoop
$>ssh s202 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
$>ssh s203 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
$>ssh s204 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
8.删除临时目录文件
$>cd /tmp
$>rm -rf hadoop-centos
$>ssh s202 rm -rf /tmp/hadoop-centos
$>ssh s203 rm -rf /tmp/hadoop-centos
$>ssh s204 rm -rf /tmp/hadoop-centos
9.删除hadoop日志
$>cd /soft/hadoop/logs
$>rm -rf *
$>ssh s202 rm -rf /soft/hadoop/logs/*
$>ssh s203 rm -rf /soft/hadoop/logs/*
$>ssh s204 rm -rf /soft/hadoop/logs/*
10.格式化文件系统
$>hadoop namenode -format
11.启动hadoop进程
$>start-all.sh
12、测试成功开启
② 在namenode下,及s201下jps出现:
NameNode
SecondaryNameNode
ResourceManager
jps
① 在DataNode,s202/s203/s204下jps出现:
DataNode
NodeManager
jps
rsync
四个机器均安装rsync命令。
远程同步.
$>sudo yum install rsync
端口查看
netstat -ano | more
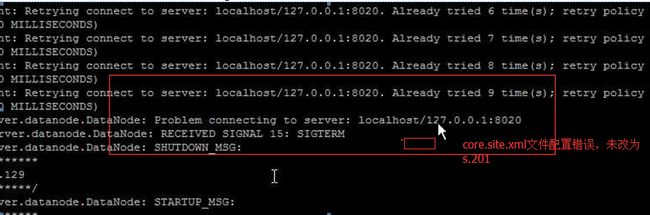
错误案例
出现错误,查看/soft/hadoop/logs日志排查
netstat -naop | grep 50010

进程杀死:kill -9 -4860
把数据节点的目录干掉,即对/tmp进行清理