2018年"华为杯"数学建模获奖名单挖掘分析
2018年"华为杯"数学建模获奖名单挖掘分析
本文针对2018年"华为杯"数学建模6张拟获奖名单做一次简单的统计分析,以下分析结果仅代表思路,勿要以假乱真,权威结果统计以各大高校官方结果为准。以该2018年"华为杯"A,B,C,D,E,F共计6道题目的拟获奖名单为原材料。主要锻炼Python数据处理中的以下功能点的使用:
功能点:
1.把6张拟获奖名单进行拼接
··· 1.1.1.将6张表横向拼接;
··· 1.1.2.将6张表纵向拼接(后续处理主要使用按竖直方向拼接);
··· 1.1.3.简单的检索功能;
··· ··· ··· input:传入自己学校的名称即可整理出本校的参赛情况
··· ··· ···output:该校的参赛情况整合表
完成1中的处理针对单个高校信息的抽取已经可以完成,并在Excel表格中可以很容易的做出筛选和排序,并计算各个学校总的获奖率和每道题目对应的获奖率等等。但是要实现对全国参赛的上百组高校队伍的批量分析和统计,设计详细的数据结构存储数据是必须的。第二部分将实现对全国参赛的上百组高校队伍的参赛和获奖情况的批量分析和统计。
··· 1.1.4.对汇总表的数据探索
2.抽取参赛高校列表
3.分别抽取出来每个学校的参赛信息(按学校分群,高校名做索引)
4.统计每个学校的参赛信息
··· 4.1.设计存储每一个学校参赛相关信息的数据结构
··· 4.2.分别统计每一个大学的各个赛题参与和完成获奖情况
··· 这里由宏观到微观铺开整个数据结构的组织结果:
··· ···A.宏观(全部高校参赛情况对象字典,每一个高校参赛情况对象记为xuexiao1)
··· ···B.微观:xuexiao1对象的展开
··· ···C.xuexiao1对象中的"学校各题获奖明细"展开
5.统计shanghai地区大学的参赛情况
····5.1.统计shanghai地区大学的参赛情况
····5.2.统计shanghai地区部分大学的参赛获奖情况
····5.3.统计全国参赛的情况
注:由于学生队伍成员组队方式的灵活性,本文将以队伍为研究粒度来做统计分析。
6.参赛人数的统计
7.每个大学"答题明细"对象挖掘分析
以同济大学和SMU大学为例。
··· 7.2.1.两个学校6道赛题完成情况一览
··· 7.2.2.两个学校6道赛题一等奖情况一览
··· 7.2.3.高校数模战斗力排行榜(取战斗力前100名高校)
实现过程
1. 将6张拟获奖名单进行拼接
1.1.1.将6张表横向拼接;
import pandas as pd
import xlwt
import numpy as np
file_path=r'C:/Users/Administrator/Desktop/AAA/'
data_A=pd.read_excel(file_path+'2018年最终获奖名单_A题.xls',encode='gbk')
len(data_A) #678
data_A.columns.tolist()
#['序号', '题号', '队伍编号', '奖项', '队长姓名', '队长所在单位', '第一队友姓名', '第一队友所在单位', '第二队友姓名', '第二队友所在单位']
data_B=pd.read_excel(file_path+'2018年最终获奖名单_B题.xls',encode='gbk')
len(data_B) #1899
data_C=pd.read_excel(file_path+'2018年最终获奖名单_C题.xls',encode='gbk')
len(data_C) #5560
data_D=pd.read_excel(file_path+'2018年最终获奖名单_D题.xls',encode='gbk')
len(data_D) #557
data_E=pd.read_excel(file_path+'2018年最终获奖名单_E题.xls',encode='gbk')
len(data_E) #1509
data_F=pd.read_excel(file_path+'2018年最终获奖名单_F题.xls',encode='gbk')
len(data_F) #2004
data_all=pd.concat([data_A,data_B,data_C,data_D,data_E,data_F],axis=1)
#横向拼接设置axis=1,沿着水平方向来拼接。
print(data_all.head(10))
len(data_all) #5560
#data_all拼接后的维度大小为:rownum x 6*columnnum
rownum=max([len(data_A),len(data_B),len(data_C),len(data_D),len(data_E),len(data_F)])
columnnum=len(data_A.columns.tolist() )
print(data_all.head(5)) #出于尊重他人隐私的目的,详细的结果不在此给出,后续也希望参看该篇博客文章练习的同学勿轻易泄露他人信息为盼!!!
1.1.2.将6张表纵向拼接;
import pandas as pd
import xlwt
import numpy as np
file_path=r'C:/Users/Administrator/Desktop/AAA/'
data_A=pd.read_excel(file_path+'2018年最终获奖名单_A题.xls',encode='gbk')
len(data_A) #678
data_A.columns.tolist()
#['序号', '题号', '队伍编号', '奖项', '队长姓名', '队长所在单位', '第一队友姓名', '第一队友所在单位', '第二队友姓名', '第二队友所在单位']
data_B=pd.read_excel(file_path+'2018年最终获奖名单_B题.xls',encode='gbk')
len(data_B) #1899
data_C=pd.read_excel(file_path+'2018年最终获奖名单_C题.xls',encode='gbk')
len(data_C) #5560
data_D=pd.read_excel(file_path+'2018年最终获奖名单_D题.xls',encode='gbk')
len(data_D) #557
data_E=pd.read_excel(file_path+'2018年最终获奖名单_E题.xls',encode='gbk')
len(data_E) #1509
data_F=pd.read_excel(file_path+'2018年最终获奖名单_F题.xls',encode='gbk')
len(data_F) #2004
data_all=pd.concat([data_A,data_B,data_C,data_D,data_E,data_F],axis=0)
#横向拼接设置axis=0,沿着竖直方向来拼接。
print(data_all.head(10))
len(data_all) #5560
#data_all拼接后的维度大小为:rownum x columnnum
rownum=sum([len(data_A),len(data_B),len(data_C),len(data_D),len(data_E),len(data_F)]) #12207
columnnum=len(data_A.columns.tolist()) #10
print(data_all.head(5)) #出于尊重他人隐私的目的,详细的结果不在此给出,后续也希望参看该篇博客文章练习的同学勿轻易泄露他人信息为盼!!!
#保存全国竞赛汇总数据信息
data_all.to_excel(file_path+'2018全国研究生建模参赛信息汇总.xls',encoding='gbk')
1.1.3.简单的检索功能;
#1.检索自己学校的参赛情况
file_path=r'C:/Users/Administrator/Desktop/AAA/' #outputfile path
data_SMU=data_all[((data_all['队长所在单位']=='XX大学')|
(data_all['第一队友所在单位']=='XX大学')|
(data_all['第二队友所在单位']=='XX大学'))]
data_SMU.to_excel(file_path+'XX大学2018研究生建模参赛信息汇总.xls',encoding='gbk')
#2.#1.获奖队伍
prized=data_SMU[~(data_SMU['奖项']=='成功参与奖')]
#2.未获奖队伍
unprized=data_SMU[data_SMU['奖项']=='成功参与奖']
prized['奖项'].value_counts() #分别计算各个奖项获奖队伍数,默认是降序
"""
三等奖 63
二等奖 30
一等奖 3
"""
prizedCount=prized['奖项'].value_counts(ascending=True)
"""
一等奖 3
二等奖 30
三等奖 63
"""
unprizedCount=unprized['奖项'].value_counts() #计算成功参与奖的获奖队伍数
#成功参与奖 139
#2018华为杯全国研究生数学建模,XX大学队伍获奖率
prizedsum=np.sum(prizedCount[:])
prizeate=np.sum(prizedCount)/(np.sum(unprizedCount)+prizedsum) # 0.4393063583815029
prizeate # 0.4393063583815029
#XX大学总人数占2018年参赛队伍比重
rate=sum(sum(prizedCount)+unprizedCount)/data_all.shape[0] #参赛总人数=12207
rate
#3."""1.发现数据中: 一等奖(华为)和 一等奖同类异名,考虑去重复项并合并,使用正则表达式或者字符串替换"""
data_all['奖项']=data_all['奖项'].apply(lambda x:x.replace('一等奖(华为)','一等奖')) #同类异名的合并
#4.全国的获奖分层情况
chooses,category=[data_all['题号'].value_counts(ascending=True),data_all['奖项'].value_counts(ascending=True)]
chooses
category
totalNum=data_all.shape[0]
prize1_rate,prize2_rate,prize3_rate,unprize_rate=category/totalNum
print('\n一等奖: ',prize1_rate,'\n二等奖: ',prize2_rate,'\n三等奖: ',prize3_rate,'\n成功参与奖: ',unprize_rate)
#获奖人数&未获奖人数占比
lucky_count=sum(category[:3]) #获奖人数:4358
success_join_count=totalNum-lucky_count #未获奖人数:7849
print('2018年华为杯数学建模获奖率: ',prize1_rate+(prize2_rate+prize3_rate))
效果:
一等奖: 0.015073318587695584
二等奖: 0.13008929302859015
三等奖: 0.21184566232489555
成功参与奖: 0.6429917260588187
2018年华为杯数学建模获奖率: 0.3570082739411813
··· 1.1.4.对汇总表的数据探索
直接选中"2018全国研究生建模参赛信息汇总.xls"中的两列:“题号"和"奖项"即可做粗略的数据探索(excel中直接点击"插入”>"图表"即可自助生成很多好看的报表);
A.2018华为杯全国研究生数学建模各题队伍分布:
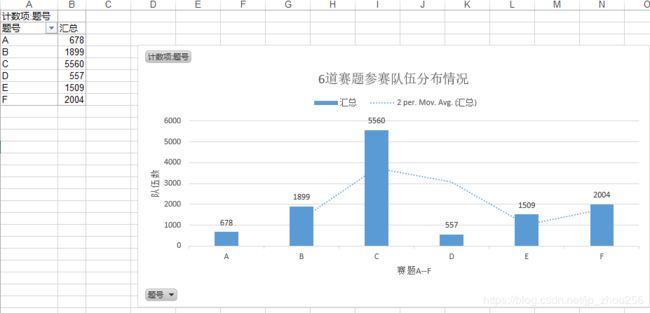
B.2018华为杯全国研究生数学建模奖项分布汇总:
1>宏观:
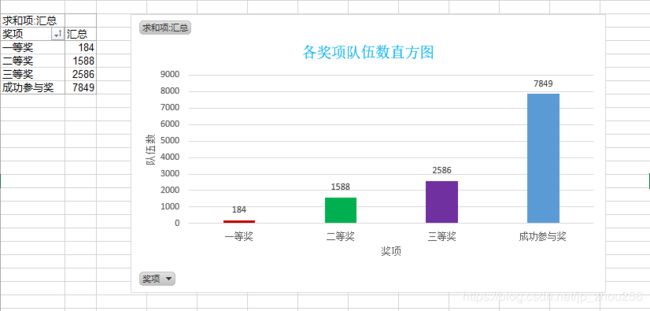
2>微观:
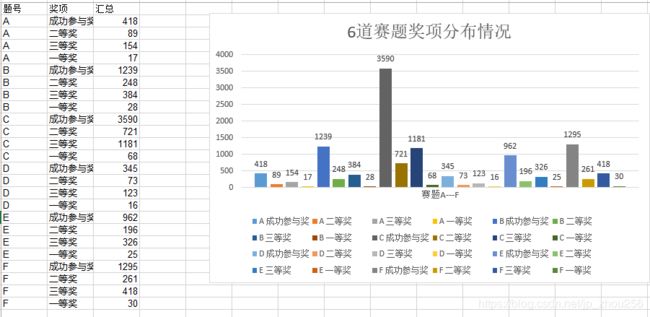
C.2018华为杯全国研究生数学建模一等奖的赛题分布:
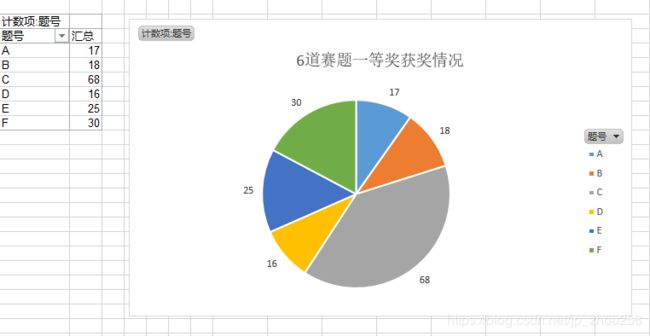
2.抽取参赛高校列表
#高校名称列表
import pandas as pd
university_list=list(pd.concat([data_all['队长所在单位'],data_all['第一队友所在单位'],data_all['第二队友所在单位']]).unique())
university_list
['华北电力大学',
'吉林大学',
'东北林业大学',
'同济大学',
'华东师范大学',
……
'美国康奈尔大学',
'重庆医科大学',
'北京语言大学',
'中共上海市委党校',
'香港大学',
'新加坡国立大学',
'中国人民公安大学',
'中国航天科技集团公司航天时代电子公司(13所)',
'中国航天科技集团公司第五研究院(511 所)',
'中国航天科技集团公司第一研究院(14所)',
'密歇根大学',
'国家海洋局第一海洋研究所',
'中国航天科工集团公司第三研究院(35所)',
'中国地震局地球物理研究所',
'中国航天科技集团公司第一研究院(703所)']
3.分别抽取出来每个学校的参赛信息(对学校分群)
#分别抽取出来每个学校的参赛信息
#university=[] #将各个大学分群
university={} #将各个大学分群
totalNum=data_all.shape[0] #参赛队伍总支数
for i in range(len(university_list)):
#grade.append(university_list[i]+str(i))
del data_SMU
data_SMU=data_all[((data_all['队长所在单位']==university_list[i])|(data_all['第一队友所在单位']==university_list[i])|(data_all['第二队友所在单位']==university_list[i]))].reset_index(drop=True)
del data_SMU['序号']
university[university_list[i]]=data_SMU
4.统计每个学校的参赛信息
4.1.设计存储每一个学校参赛相关信息的数据结构
xuexiao1={'学校名称':XX大学,
'参赛人数':1000,
'获奖总队伍数':480,
'未获奖总队伍数':1000-480,
'学校各题获奖比率':[{‘A’:18.5%},{‘B’:28.5%},{C’:15.5%},{‘D’:38.5%},{‘C’:58.5%},{‘D’:48.5%}],
'学校获奖比':480/1000
'学校各题获奖明细':{
'A':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1},
'B':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1},
'C':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1},
'D':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1},
'E':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1},
'F':{'一等奖队伍数':one_prize1, '一等奖获奖比率':one_rate1,'二等奖队伍数':two_prize1, '二等奖获奖比率':two_rate1, '三等奖队伍数':three_prize1,'三等奖获奖比率':three_rate1,'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1, '获奖队伍数':award_prize,'获奖比率':prized_rate1}
}
}
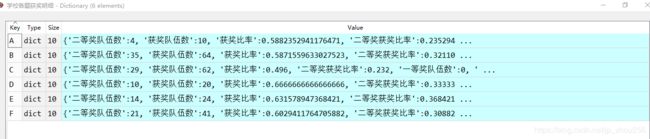
4.2.分别统计每一个大学的各个赛题参与和完成获奖情况
totalUniv={}
saiti_list=['A','B','C','D','E','F']
for i in range(len(university)):
#for i in range(5):
#print(university[university_list[0]]) #university为字典,学校名称为key
xiexiao={}
#xiexiao1=university[university_list[3]]
xiexiao1=university[university_list[i]]
#xiexiao1=university[university_list[77]] #3--同济大学,77--海事大学
#学校名称(三列中的众数)
zhongshu=pd.concat([xiexiao1['队长所在单位'],xiexiao1['第一队友所在单位'],xiexiao1['第二队友所在单位']]) #Series
xiexiao['学校名称']= zhongshu.value_counts().index[0] #value_counts默认是降序,选择众数对应的索引值即为学校.
#chooses=xiexiao1['题号'].value_counts(ascending=True) #对应赛题选做队伍支数
##A=xiexiao1[xiexiao1['题号']].value_counts()
#prizeoption=xiexiao1['奖项'].unique()
#1.分析获奖总人数
xiexiao['参赛队伍']=len(xiexiao1)
#totalUniv[university_list[3]]=xiexiao
#totalUniv[university_list[i]]=xiexiao
#2.分析该学校的各个赛题完成情况
#2.1.选做A题的情况
#xiexiao1[xiexiao1['题号']=='A']['奖项'].value_counts(ascending=True) #返回A赛题对应的获奖情况
#2.2.六道赛题各自获奖情况一览表
"""
zhou=[1,2,4,5],zhou[-1],zhou[:-1]
"""
timu={}#存放六道赛题各自对应的获奖情况
sum_prize1=0
award_prize=0
for ii in range(len(saiti_list)):
#print(saiti_list[ii])
#things=things.index
#必须对things进行初始化,不然有的学校没有一等奖things[0]就错位了,就出错了.
things=xiexiao1[xiexiao1['题号']==saiti_list[ii]]['奖项'].value_counts(ascending=True)
#发现同济大学有B,但是B题目没有一等奖
#things=xiexiao1[xiexiao1['题号']==saiti_list[ii]]['奖项'].value_counts(ascending=True)
##赋初值,因为每个奖不一定都有.
one_rate1=0
two_rate1=0
three_rate1=0
non_rate1=0
prized_rate1=0
try:
#一等奖队伍数
try:
if ~things[things.index=='一等奖'].empty:
#print('1')
one_prize1=things[things.index=='一等奖'] #type(one_prize1)=Series
if len(one_prize1)==0:
one_prize1=0
elif len(one_prize1)==1:
#one_prize1=one_prize1.values[0,0] #将Series转换为二维数组
one_prize1=list(one_prize1)[0] #将Series转换为list在取值也可以
else:
one_prize1=0
except :
pass
finally:
print('one_prize1出错啦!!!!!!!!!!!')
#二等奖人数
try:
if ~things[things.index=='二等奖'].empty:
two_prize1=things[things.index=='二等奖']
if len(two_prize1)==0:
two_prize1=0
elif len(two_prize1)==1:
#one_prize1=one_prize1.values[0,0] #将Series转换为二维数组
two_prize1=list(two_prize1)[0] #将Series转换为list在取值也可以
else:
two_prize1=0
except :
pass
finally:
print('two_prize1出错啦!!!!!!!!!!!')
#三等奖队伍数
try:
if ~things[things.index=='三等奖'].empty:
three_prize1=things[things.index=='三等奖']
if len(three_prize1)==0:
three_prize1=0
elif len(three_prize1)==1:
#one_prize1=one_prize1.values[0,0] #将Series转换为二维数组
three_prize1=list(three_prize1)[0] #将Series转换为list在取值也可以
else:
three_prize1=0
except :
pass
finally:
print('three_prize1出错啦!!!!!!!!!!!')
#成功参与奖队伍数===未获奖人数
try:
if ~things[things.index=='成功参与奖'].empty:
non_prize1=things[things.index=='成功参与奖']
if len(non_prize1)==0:
non_prize1=0
elif len(non_prize1)==1:
#one_prize1=one_prize1.values[0,0] #将Series转换为二维数组
non_prize1=list(non_prize1)[0] #将Series转换为list在取值也可以
else:
non_prize1=0
except :
pass
finally:
print('non_prize1出错啦!!!!!!!!!!!')
#获奖队伍总数
award_prize=sum(things[:-1])
#某道赛题的参赛总队伍数
sum_prize1=sum(things)
#一等奖队伍与该赛题参赛队伍总数的占比
one_rate1=one_prize1/sum_prize1
#二等奖队伍与该赛题参赛队伍总数的占比
two_rate1=two_prize1/sum_prize1
#三等奖队伍与该赛题参赛队伍总数的占比
three_rate1=three_prize1/sum_prize1
#未获奖队伍与该赛题参赛队伍总数的占比
non_rate1=non_prize1/sum_prize1
#获奖队伍与该赛题参赛队伍总数的占比
prized_rate1=award_prize/sum_prize1
timu[saiti_list[ii]]={
'一等奖队伍数':one_prize1,
'一等奖获奖比率':one_rate1,
'二等奖队伍数':two_prize1,
'二等奖获奖比率':two_rate1,
'三等奖队伍数':three_prize1,
'三等奖获奖比率':three_rate1,
'成功参与奖队伍数':non_prize1,'未获奖比率':non_rate1,
'获奖队伍数':award_prize,'获奖比率':prized_rate1}
#del things
except :
pass
#finally:
# print('出错啦!!!!!!!!!!!')
#3.获奖总人数
try:
total_queue=0
for i1 in range(len(timu)):
try:
total_queue+=timu[saiti_list[i1]]['获奖队伍数']
except:
continue
xiexiao['获奖总队伍数']=total_queue
except:
pass
#4.未获奖总人数
try:
un_num=0
for i1 in range(len(timu)):
try:
un_num+=timu[saiti_list[i1]]['成功参与奖队伍数']
except:
continue
xiexiao['未获奖总队伍数']=un_num
except:
pass
#5.某赛题获奖情况本质上为一个list=[]对象
try:
rate_list={}
for i1 in range(len(timu)):
rate_list[saiti_list[i1]]=timu[saiti_list[i1]]['获奖比率']
xiexiao['学校各题获奖比率']=rate_list
except:
pass
#5.学校各道赛题完成获奖情况
try:
xiexiao['学校各题获奖明细']=timu
except:
pass
#5.学校获奖比
try:
xx_rate=total_queue/len(xiexiao1) #学校的参与竞赛总人数
xiexiao['学校获奖比']=xx_rate
except:
pass
#totalUniv.append(xiexiao)
totalUniv[university_list[i]]=xiexiao
del xiexiao1
#保存字典数据:使用DataFrame
import pandas as pd
data=pd.DataFrame(totalUniv,columns=totalUniv.keys()).T
columns_name=data.columns.tolist()
#各列数值不变的条件下来重命名各列
#data.columns=[['参赛队伍', '学校各题获奖明细', '学校各题获奖比率', '学校名称', '学校获奖比', '未获奖总队伍数', '获奖总队伍数']]
#各列随着名称先后顺序发生位置变化
data=pd.DataFrame(totalUniv,columns=totalUniv.keys()).T
#重新指定列的顺序
data=data[['学校名称','参赛队伍', '获奖总队伍数', '未获奖总队伍数','学校各题获奖明细', '学校各题获奖比率', '学校获奖比']]
#data[data['学校名称']=='XX大学']
data.to_csv('E:/jpzhou.csv',index=False)
这里由宏观到微观铺开整个数据结构的组织结果:
A.宏观:
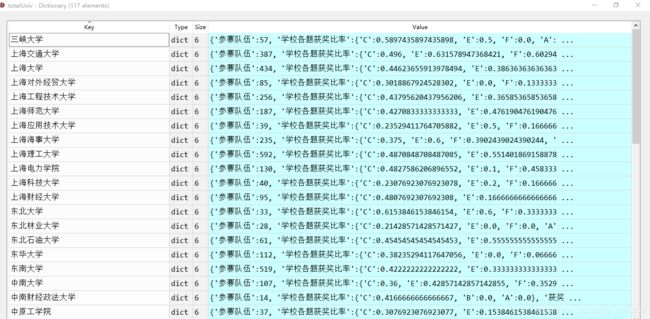
B.微观:xuexiao1对象的展开
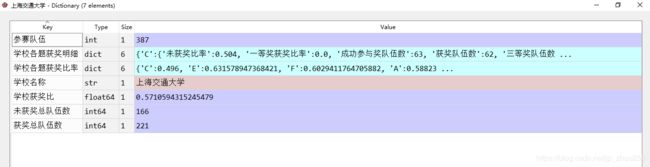
C.xuexiao1对象中的"学校各题获奖明细"展开
5.统计shanghai地区大学的参赛情况
····5.1.统计shanghai地区大学的参赛情况
#按照参赛人数对字典进行排序
join_party={}
for i in range(len(university_list)):
#for i in range(5):
#print(university[university_list[0]]) #university为字典,学校名称为key
try:
xiexiao1=totalUniv[university_list[i]]
num=int(xiexiao1['参赛队伍'])
join_party[str(university_list[i])]=num
print(xiexiao1)
except:
continue
univ_totalnum=list(sorted(join_party.items(),key=lambda x:x[1],reverse=True)) #默认升序,True为降序.
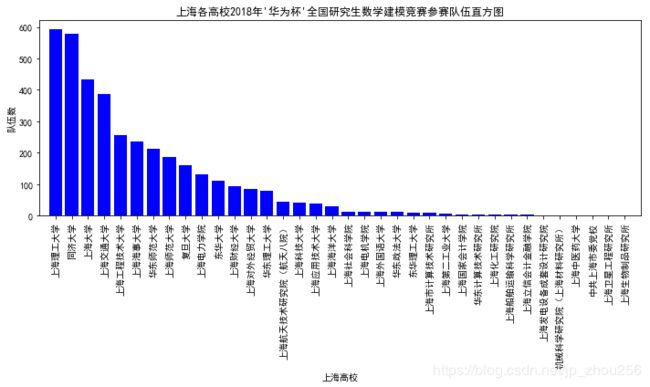
#上海各个高效参赛队伍直方图
#筛选出上海的高校
shanghai_univ=[]
for i in range(len(univ_totalnum)):
for item in ['上海','华东','东华','同济','复旦','解放军第二军医']:
if item in univ_totalnum[i][0]:
shanghai_univ.append(univ_totalnum[i])
else:
continue
#删除离群点非上海的高校
del shanghai_univ[9] #删除中国石油大学(华东)---青岛
del shanghai_univ[12] #华东交通大学----江西
#获得上海高校列表34所
#画出直方图
import matplotlib.pyplot as plt
plt.subplots(figsize=(10,6))
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文
plt.bar(range(len(shanghai_univ)),[shanghai_univ[i][1] for i in range(len(shanghai_univ))],color='blue',align='center')
plt.title("上海各高校2018年'华为杯'全国研究生数学建模竞赛参赛队伍直方图")
plt.xticks(range(len(shanghai_univ)),[shanghai_univ[i][0] for i in range(len(shanghai_univ))],rotation=90)
plt.xlim([-1,len(shanghai_univ)])
plt.xlabel("上海高校")
plt.ylabel("队伍数")
plt.tight_layout()
plt.show()
shanghai_university=shanghai_univ
type(shanghai_university[0][0])
type(shanghai_university[0][1])
shanghai_university=shanghai_univ
type(shanghai_university[0][0])
type(shanghai_university[0][1])
#将上海高校参赛数据入数据库保存
import sqlite3
conn=sqlite3.connect('E:/代码练习区256/MathModel/cmath2018.sqlite')
curs=conn.cursor()
#conn.close()
#在Python中一个分号算是一条语句,curs.execute(sql(i))只执行一条语句
curs.execute("drop table if EXISTS unives_shanghai");
#curs.close()
curs.execute("create table unives_shanghai(uid varchar(10) PRIMARY KEY,univ_name varchar(30),groupe_num int)")
#curs.execute("insert into unives_shanghai(uid,univ_name,groupe_num) values('123456','中国科学技术大学',240)") #% ('123456','中国科学技术大学',240))
id1='10247'+str(1)
name1=shanghai_university[1][0]
num1=shanghai_university[1][1]
#print("统计的数学===(%s,%s,%d)" % (id1,name1,num1))
#curs.execute("insert into unives_shanghai(uid,univ_name,groupe_num) values('%s','%s','%d')" % (id1,name1,num1)) #% ('123456','中国科学技术大学',240))
curs.execute("select * from unives_shanghai")
df1=curs.fetchall()
#for i in range(2,len(shanghai_university)):
for i in range(len(shanghai_university)):
try:
curs.execute("insert into unives_shanghai(uid,univ_name,groupe_num) values('%s','%s','%d')" % ('10247'+str(i),shanghai_university[i][0],shanghai_university[i][1]))
except Exception as ex: #异常的抛出
print("Exception: ", str(ex))
pass
curs.execute("select * from unives_shanghai")
df1=curs.fetchall()
#挑选出来上海地区参赛队伍数>=100的学校
curs.execute("select * from unives_shanghai where groupe_num>=100")
df1=curs.fetchall()
注释1:
insert错误
curs.execute(“insert into unives_shanghai(univ_name,groupe_num) values(%s,%d)” % (‘zhonguo’,240))
OperationalError: no such column: zhonguo
解决办法: values中%s需要打单冒号’ ‘或者双引号" "。
curs.execute("insert into unives_shanghai(uid,univ_name,groupe_num) values(’%s’,’%s’,’%d’)" % (id1,name1,num1)) #% (‘123456’,‘XX大学’,240))
····5.2.统计shanghai地区部分大学的参赛获奖情况
#筛选出来上海各个高校的获奖情况
shanghai_get={}
for i in range(len(shanghai_university)):
shanghai_get[shanghai_university[i][0]]=totalUniv[shanghai_university[i][0]]
#画出获奖高校获奖队伍数直方图
#排序前
import matplotlib.pyplot as plt
plt.subplots(figsize=(10,6))
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文
#for i in shanghai_get:
# print(i)
plt.bar(range(len(shanghai_get)),[shanghai_get[i]['获奖总队伍数'] for i in shanghai_get],color='blue',align='center')
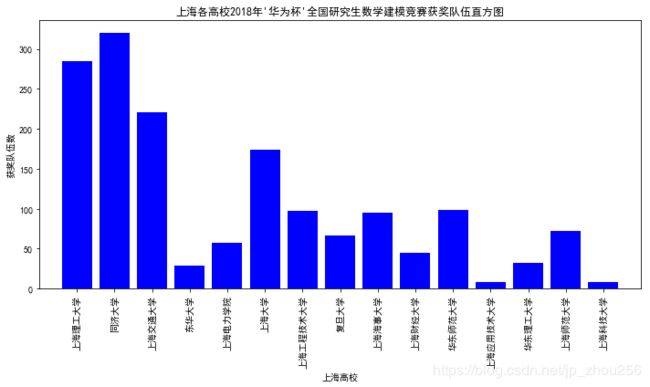
plt.title("上海各高校2018年'华为杯'全国研究生数学建模竞赛获奖队伍直方图")
plt.xticks(range(len(shanghai_get)),[shanghai_get[i]['学校名称'] for i in shanghai_get],rotation=90)
plt.xlim([-1,len(shanghai_get)])
plt.xlabel("上海高校")
plt.ylabel("获奖队伍数")
plt.tight_layout()
plt.show()
#排序后:数据复杂不好弄,单独取出来再做分析,简化操作过程
namename={}
for i in shanghai_get:
namename[i]=shanghai_get[i]['获奖总队伍数']
zhouzhou=sorted(namename.items(),key=lambda x:x[1],reverse=True)
import matplotlib.pyplot as plt
plt.subplots(figsize=(10,6))
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文
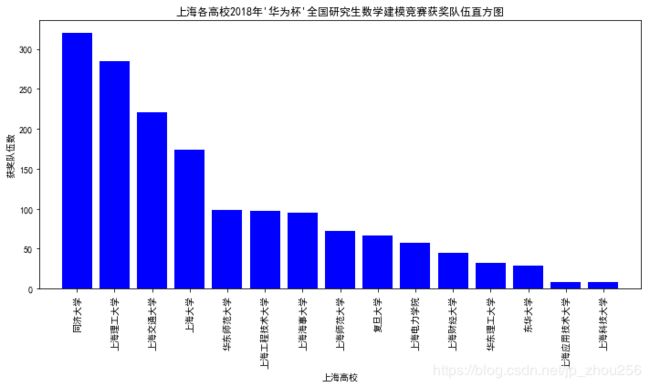
plt.bar(range(len(zhouzhou)),[zhouzhou[i][1] for i in range(len(zhouzhou))],color='blue',align='center')
plt.title("上海各高校2018年'华为杯'全国研究生数学建模竞赛获奖队伍直方图")
plt.xticks(range(len(zhouzhou)),[zhouzhou[i][0] for i in range(len(zhouzhou))],rotation=90)
plt.xlim([-1,len(zhouzhou)])
plt.xlabel("上海高校")
plt.ylabel("获奖队伍数")
plt.tight_layout()
plt.show()
import pandas as pd
data2=pd.DataFrame(shanghai_get,columns=shanghai_get.keys()).T
columns2=data2.columns.tolist()
data2=data2[[ '学校名称','参赛队伍', '获奖总队伍数', '未获奖总队伍数', '学校获奖比', '学校各题获奖比率']]
data2.to_csv('E:/上海高校数模获奖_data.csv',index=False)
A.排序前:
B.排序后:
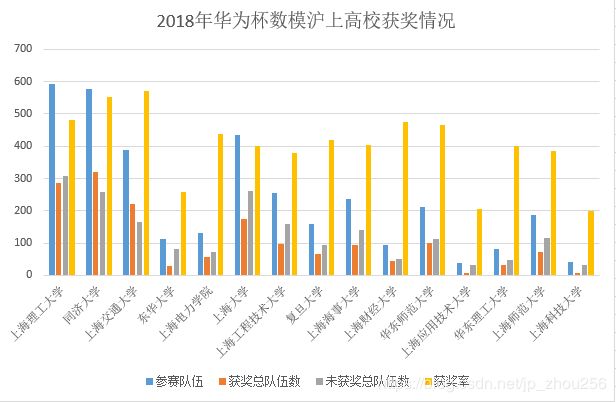
备注2:上图仅节选了部分代表性高校做展示,另外为方便数据展示,对高校获奖率*1000,沪上各个高校的实际获奖率=图上获奖率数值/1000。
5.3.统计全国的情况
#全国的情况
shouzhou=sorted(join_party.items(),key=lambda x:x[1],reverse=True)
import pandas as pd
data2=pd.DataFrame(shouzhou,columns=['学校','参赛队伍数'])
columns2=data2.columns.tolist()
data2.to_csv('E:/全国高校数模参赛人数_data.csv',index=True)
#全国有实力高效的获奖情况
import pandas as pd
data2=pd.DataFrame([totalUniv[i] for i in totalUniv],index=totalUniv.keys())
columns2=data2.columns.tolist()
#指定DataFrame各列的顺序
data2=data2[['学校名称', '参赛队伍', '获奖总队伍数','未获奖总队伍数', '学校各题获奖比率', '学校获奖比']]
#data2.reindex(range(len(data2.index.tolist()))) #直接传入想要的新index即可。但是很多东西没了
data2.to_csv('E:/全国数模获奖高校战果统计_data.csv',index=False)
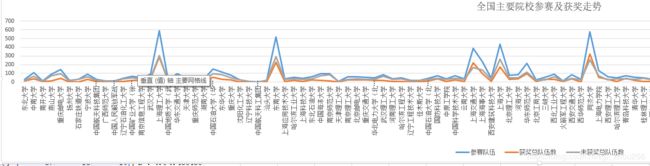
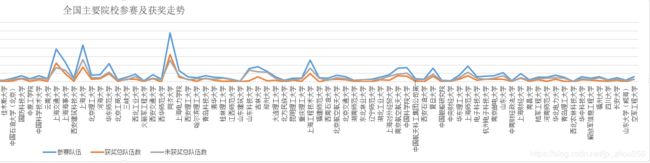 备注3:波峰部分都是参赛人数较多的院校。
备注3:波峰部分都是参赛人数较多的院校。
备注4:
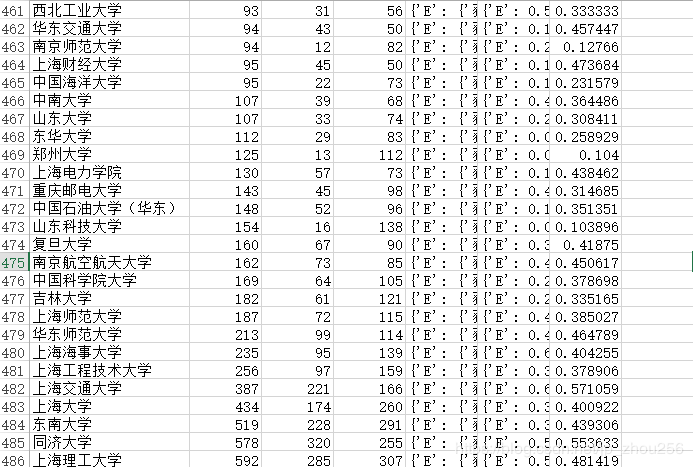
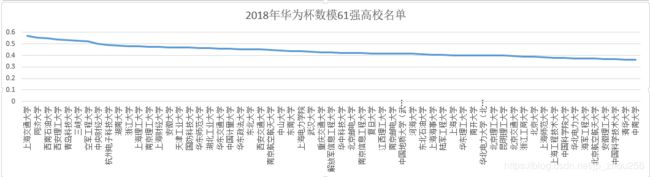 获奖率=该校获奖队伍数/该校参赛总队伍数,获奖率依然是一个学校整体实力的表征,尽管参赛人数少,可能获奖率高,一定程度上参赛队伍数众多的情况下,某个学校依然表现出整体的获奖率超过50%,不得不说这个学校整体学生的水平是值得点赞的!
获奖率=该校获奖队伍数/该校参赛总队伍数,获奖率依然是一个学校整体实力的表征,尽管参赛人数少,可能获奖率高,一定程度上参赛队伍数众多的情况下,某个学校依然表现出整体的获奖率超过50%,不得不说这个学校整体学生的水平是值得点赞的!
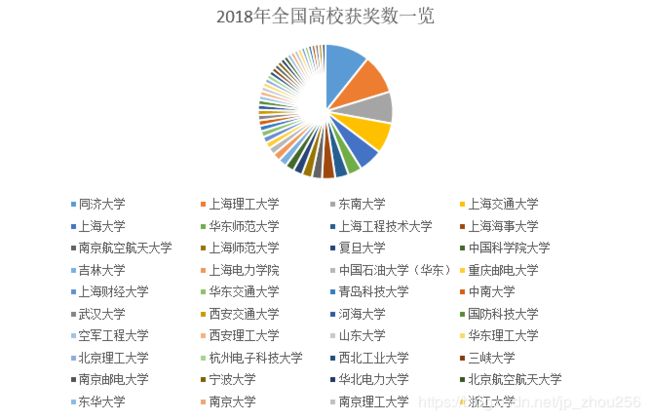
6.参赛人数的统计
#大致可以参考如下思路来尝试完成
mouxiaoTotalnum=0
for i in range(len(data_all)):
#三个队员均来自本校
if data_all[i]['队长所在单位']=='XX大学')&
(data_all[i]['第一队友所在单位']=='XX大学')&
(data_all[i]['第二队友所在单位']=='XX大学')):
mouxiaoTotalnum+=3
#仅两个队员均来自本校
elif ((data_all[i]['队长所在单位']=='XX大学')&
(data_all[i]['第一队友所在单位']=='XX大学')) or
((data_all[i]['第一队友所在单位']=='XX大学')&
(data_all[i]['第二队友所在单位']=='XX大学')) or
((data_all[i]['队长所在单位']=='XX大学') &
(data_all[i]['第二队友所在单位']=='XX大学')):
mouxiaoTotalnum+=2
#仅一个队员均来自本校
elif (data_all[i]['队长所在单位']=='XX大学') or
(data_all[i]['第一队友所在单位']=='XX大学') or
(data_all[i]['第二队友所在单位']=='XX大学'):
mouxiaoTotalnum+=1
7.每个大学"答题明细"对象挖掘分析
以同济大学和SMU大学为例。
#绘制SMU大学和同济大学的答题情况
"""
数据结构设计:
item\赛题 A B C D E F
1 A1 B1 C1 D1 E1 F1
2 A2 B2 C2 D2 E2 F2
3 A3 B3 C3 D3 E3 F3
4 A4 B4 C4 D4 E4 F4
5 A5 B5 C5 D5 E5 F5
6 A6 B6 C6 D6 E6 F6
7 A7 B7 C7 D7 E7 F7
8 A8 B8 C8 D8 E8 F8
9 A9 B9 C9 D9 E9 F9
10 A10 B10 C10 D10 E10 F10
11 A11 B11 C11 D11 E11 F11
"""
#知识点:
#1.使用矩阵(Array)的转置,np.Array().T
#2.tuple/List的转置使用列表的解析式
saiti_list=['A','B','C','D','E','F']
zhou111=[]
for i in range(6):
shou=[]
for j in range(11):
shou.append(saiti_list[i]+str(j+1))
zhou111.append(shou)
"""
['A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7', 'A8', 'A9', 'A10', 'A11']
['B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'B10', 'B11']
['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11']
['D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'D9', 'D10', 'D11']
['E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7', 'E8', 'E9', 'E10', 'E11']
['F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8', 'F9', 'F10', 'F11']
"""
#将list/tuple做转置
grid = [[row[i] for row in zhou111] for i in range(len(zhou111[0]))]
"""
['A1', 'B1', 'C1', 'D1', 'E1', 'F1']
['A2', 'B2', 'C2', 'D2', 'E2', 'F2']
['A3', 'B3', 'C3', 'D3', 'E3', 'F3']
['A4', 'B4', 'C4', 'D4', 'E4', 'F4']
['A5', 'B5', 'C5', 'D5', 'E5', 'F5']
['A6', 'B6', 'C6', 'D6', 'E6', 'F6']
['A7', 'B7', 'C7', 'D7', 'E7', 'F7']
['A8', 'B8', 'C8', 'D8', 'E8', 'F8']
['A9', 'B9', 'C9', 'D9', 'E9', 'F9']
['A10', 'B10', 'C10', 'D10', 'E10', 'F10']
['A11', 'B11', 'C11', 'D11', 'E11', 'F11']
"""
#SMU_data1=totalUniv[university_list[77]] #同济大学3,上海海事大学77.
SMU_data1=totalUniv[university_list[3]]
MingXi=SMU_data1['学校各题获奖明细']
huizongTable=[]
saiti_list=['A','B','C','D','E','F']
mixname=MingXi[saiti_list[i]].keys()
#指定按照这个顺序来实现信息抽取
itemlist=['一等奖队伍数','一等奖获奖比率','二等奖队伍数', '二等奖获奖比率', '三等奖队伍数', '三等奖获奖比率','获奖队伍数','获奖比率','成功参与奖队伍数', '未获奖比率']
len(itemlist)
renlist=['获奖队伍数','成功参与奖队伍数']
for i in range(len(saiti_list)):
item=MingXi[saiti_list[i]] #取到每一道题的作答情况
shou=[]
#for j in range(10):
# shou.append(item[itemlist[j]])
item1=item[itemlist[0]] #一等奖队伍数
shou.append(item1)
item2=item[itemlist[1]]*100 #一等奖获奖比率,为方便可视化这里*100
shou.append(item2)
item3=item[itemlist[2]] #二等奖队伍数
shou.append(item3)
item4=item[itemlist[3]]*100 #二等奖获奖比率
shou.append(item4)
item5=item[itemlist[4]] #三等奖队伍数
shou.append(item5)
item6=item[itemlist[5]]*100 #三等奖获奖比率
shou.append(item6)
item7=item[itemlist[6]] #获奖队伍数
shou.append(item7)
item8=item[itemlist[7]]*100 #获奖比率
shou.append(item8)
item9=item[itemlist[8]] #成功参与奖队伍数
shou.append(item9)
item10=item[itemlist[9]]*100 #未获奖比率
shou.append(item10)
zongren=item[renlist[0]]+item[renlist[1]]
shou.append(zongren)
huizongTable.append(shou)
#将汇总表做转置
#ScoreTable= [[row[i] for row in huizongTable] for i in range(len(huizongTable[0]))]
ScoreTable=np.array(huizongTable).T #转换成为numpy.array()后直接复制到Excel中处理分析即可
#空白记事本中替换无关的[,],',等等,换行顶格写,直接粘贴到Excel可以识别自动填充cell。
def Audit_Univ(output_path,univ_index):
#SMU_data1=totalUniv[university_list[3]]
SMU_data1=totalUniv[university_list[univ_index]]
MingXi=SMU_data1['学校各题获奖明细']
huizongTable=[]
saiti_list=['A','B','C','D','E','F']
#mixname=MingXi[saiti_list[i]].keys()
#指定按照这个顺序来实现信息抽取
itemlist=['一等奖队伍数','一等奖获奖比率','二等奖队伍数', '二等奖获奖比率', '三等奖队伍数', '三等奖获奖比率','获奖队伍数','获奖比率','成功参与奖队伍数', '未获奖比率']
len(itemlist)
renlist=['获奖队伍数','成功参与奖队伍数']
for i in range(len(saiti_list)):
item=MingXi[saiti_list[i]] #取到每一道题的作答情况
shou=[]
#for j in range(10):
# shou.append(item[itemlist[j]])
item1=item[itemlist[0]] #一等奖队伍数
shou.append(item1)
item2=item[itemlist[1]]*100 #一等奖获奖比率,为方便可视化这里*100
shou.append(item2)
item3=item[itemlist[2]] #二等奖队伍数
shou.append(item3)
item4=item[itemlist[3]]*100 #二等奖获奖比率
shou.append(item4)
item5=item[itemlist[4]] #三等奖队伍数
shou.append(item5)
item6=item[itemlist[5]]*100 #三等奖获奖比率
shou.append(item6)
item7=item[itemlist[6]] #获奖队伍数
shou.append(item7)
item8=item[itemlist[7]]*100 #获奖比率
shou.append(item8)
item9=item[itemlist[8]] #成功参与奖队伍数
shou.append(item9)
item10=item[itemlist[9]]*100 #未获奖比率
shou.append(item10)
zongren=item[renlist[0]]+item[renlist[1]]
shou.append(zongren)
huizongTable.append(shou)
#将汇总表做转置
#ScoreTable= [[row[i] for row in huizongTable] for i in range(len(huizongTable[0]))]
ScoreTable=np.array(huizongTable).T
#答案拼接方式
output_path1=output_path+'2018华为杯数学建模成绩_'+university_list[univ_index]+'.csv'
import pandas as pd
index_list=[]
for i in range(len(itemlist)):
index_list.append(itemlist[i])
index_list.append('参赛人数')
data_univ=pd.DataFrame(ScoreTable,columns=saiti_list,index=index_list)
data_univ.to_csv(output_path1)
#统计数据输出
outpath_audit='E:/2018年华为杯数学建模分析汇总/audit1112/'
Audit_Univ(outpath_audit,3)
#生成所有参赛院校的成绩报表(然后在Excel表格中可以轻松地操作这些数据---散点图、折线图、直方图、饼图等等)
for i in range(len(university_list)):
Audit_Univ(outpath_audit,i)
7.1.运行之后的表数据如下:
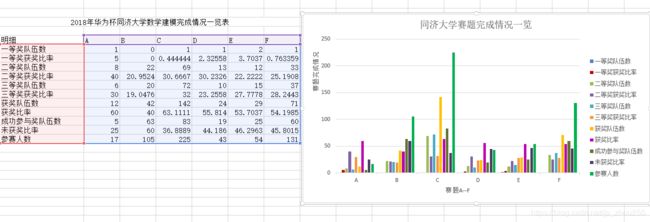
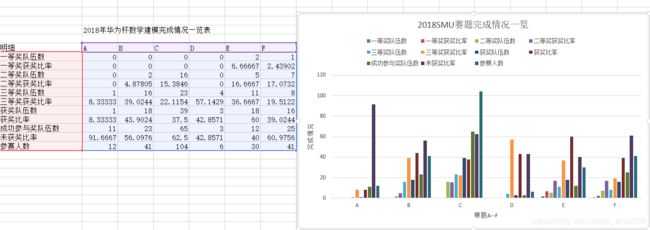
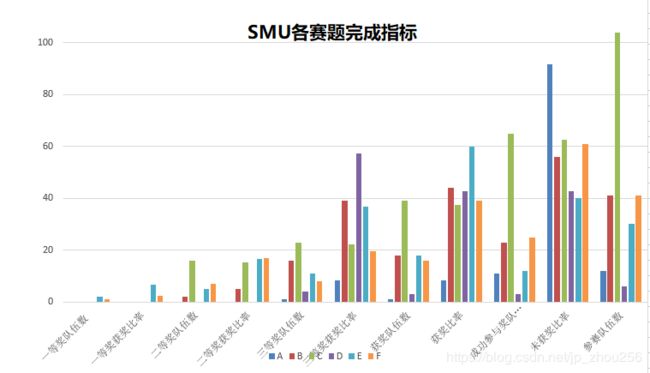
2018年华为杯SMU数学建模完成情况一览表
······明细·· A B C D E F
一等奖队伍数 0 0 0 0 2 1
一等奖获奖比率 0 0 0 0 6.66667 2.43902
二等奖队伍数 0 2 16 0 5 7
二等奖获奖比率 0 4.87805 15.3846 0 16.6667 17.0732
三等奖队伍数 1 16 23 4 11 8
三等奖获奖比率 8.33333 39.0244 22.1154 57.1429 36.6667 19.5122
获奖队伍数 1 18 39 3 18 16
获奖比率 8.33333 43.9024 37.5 42.8571 60 39.0244
成功参与奖队伍数 11 23 65 3 12 25
未获奖比率 91.6667 56.0976 62.5 42.8571 40 60.9756
参赛人数 ··12 41 104 6 30 41
2018年华为杯同济大学数学建模完成情况一览表
·····明细 A B C D E F
一等奖队伍数 1 0 1 1 2 1
一等奖获奖比率 5 0 0.444444 2.32558 3.7037 0.763359
二等奖队伍数 8 22 69 13 12 33
二等奖获奖比率 40 20.9524 30.6667 30.2326 22.2222 25.1908
三等奖队伍数 6 20 72 10 15 37
三等奖获奖比率 30 19.0476 32 23.2558 27.7778 28.2443
获奖队伍数 12 42 142 24 29 71
获奖比率 60 40 63.1111 55.814 53.7037 54.1985
成功参与奖队伍数 5 63 83 19 25 60
未获奖比率 25 60 36.8889 44.186 46.2963 45.8015
参赛人数 17 105 225 43 54 131
7.2.将生成的.csv文件打开可以在Excel中直接做分析量化,在此不再赘述。如:
2018华为杯数学建模成绩_同济大学.csv
2018华为杯数学建模成绩_SUM大学.csv
部分可视化分析效果如下:
7.2.1.两个学校6道赛题完成情况一览:
A.同济大学:
B.SMU大学:
7.2.2.两个学校6道赛题一等奖情况一览:
A.同济大学:

B.SMU大学:

7.2.3.高校数模战斗力排行榜(取战斗力前100名高校)
高校战斗力由各个等次的奖做加权求和。
一等奖权重:one_weight=0.3,二等奖权重:two_weight=0.17,
三等奖权重:three_weight=0.09,成功参与奖权重:canyu_weight=0.02
iter_zhanli={}
def Audit_Univ(output_path,univ_index):
#SMU_data1=totalUniv[university_list[3]]
SMU_data1=totalUniv[university_list[univ_index]]
MingXi=SMU_data1['学校各题获奖明细']
huizongTable=[]
saiti_list=['A','B','C','D','E','F']
#mixname=MingXi[saiti_list[i]].keys()
#指定按照这个顺序来实现信息抽取
itemlist=['一等奖队伍数','一等奖获奖比率','二等奖队伍数', '二等奖获奖比率', '三等奖队伍数', '三等奖获奖比率','获奖队伍数','获奖比率','成功参与奖队伍数', '未获奖比率']
len(itemlist)
renlist=['获奖队伍数','成功参与奖队伍数']
zhanlili=0 #统计每个学校总的战斗力
for i in range(len(saiti_list)):
try:
item=MingXi[saiti_list[i]] #取到每一道题的作答情况
except:
continue
shou=[]
#战斗力值矩阵
zhandouli=0
one_prizeli=0
one_weight=0.3
two_prizeli=0
two_weight=0.17
three_prizeli=0
three_weight=0.09
canyu_prizeli=0
canyu_weight=0.02
#for j in range(10):
# shou.append(item[itemlist[j]])
item1=item[itemlist[0]] #一等奖队伍数
one_prizeli+=item1*one_weight #一等奖战斗力值累计
shou.append(item1)
item2=item[itemlist[1]]*100 #一等奖获奖比率,为方便可视化这里*100
shou.append(item2)
item3=item[itemlist[2]] #二等奖队伍数
two_prizeli+=item3*two_weight #二等奖战斗力值累计
shou.append(item3)
item4=item[itemlist[3]]*100 #二等奖获奖比率
shou.append(item4)
item5=item[itemlist[4]] #三等奖队伍数
three_prizeli+=item5*three_weight #三等奖战斗力值累计
shou.append(item5)
item6=item[itemlist[5]]*100 #三等奖获奖比率
shou.append(item6)
item7=item[itemlist[6]] #获奖队伍数
shou.append(item7)
item8=item[itemlist[7]]*100 #获奖比率
shou.append(item8)
item9=item[itemlist[8]] #成功参与奖队伍数
canyu_prizeli+=item9*canyu_weight
shou.append(item9)
item10=item[itemlist[9]]*100 #未获奖比率
shou.append(item10)
zongren=item[renlist[0]]+item[renlist[1]]
shou.append(zongren)
#计算每道题目贡献出来的战斗力值
zhandouli=canyu_prizeli+three_prizeli+two_prizeli+one_prizeli
shou.append(zhandouli)
huizongTable.append(shou)
zhanlili+=zhandouli
#将汇总表做转置
#ScoreTable= [[row[i] for row in huizongTable] for i in range(len(huizongTable[0]))]
ScoreTable=np.array(huizongTable).T
#各个学校的总战斗力值
iter_zhanli[university_list[univ_index]]=zhanlili
#答案拼接方式
output_path1=output_path+'2018华为杯数学建模成绩_'+university_list[univ_index]+'.csv'
import pandas as pd
index_list=[]
for i in range(len(itemlist)):
index_list.append(itemlist[i])
index_list.append('参赛人数')
index_list.append('战斗力值')
#data_univ=pd.DataFrame(ScoreTable,columns=saiti_list,index=index_list)
#data_univ.to_csv(output_path1)
#统计数据输出
outpath_audit='E:/2018年华为杯数学建模分析汇总/audit1112/'
#Audit_Univ(outpath_audit,3)
#生成所有参赛院校的成绩报表(然后在Excel表格中可以轻松地操作这些数据---散点图、折线图、直方图、饼图等等)
for i in range(len(university_list)):
Audit_Univ(outpath_audit,i)
#各个高校战斗力值排名,因为紧靠获奖人数/参赛总人数会拉低很多参赛人数多的高校的战斗力值的量化
#对各个高校的战斗力值字典进行排序(各个奖项按照权重做加和获得)
energyli=sorted(iter_zhanli.items() ,key=lambda x:x[1],reverse=True)
import matplotlib.pyplot as plt
plt.subplots(figsize=(30,15))
numnum1=100
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文
#plt.bar(range(len(energyli)),[energyli[i][1] for i in range(len(energyli))],color='blue',align='center')
plt.bar(range(len(energyli[:numnum1])),[energyli[i][1] for i in range(numnum1)],color='blue',align='center')
plt.title("全国各高校2018年'华为杯'全国研究生数学建模高校战斗力排行榜")
#plt.xticks(range(len(energyli)),[energyli[i][0] for i in range(len(energyli))],rotation=45)
#plt.xlim([-1,len(energyli)])
plt.xticks(range(numnum1),[energyli[i][0] for i in range(numnum1)],rotation=90)
plt.xlim([-1,numnum1])
plt.xlabel("高校名称")
plt.ylabel("战斗力能量值")
plt.tight_layout()
plt.show()
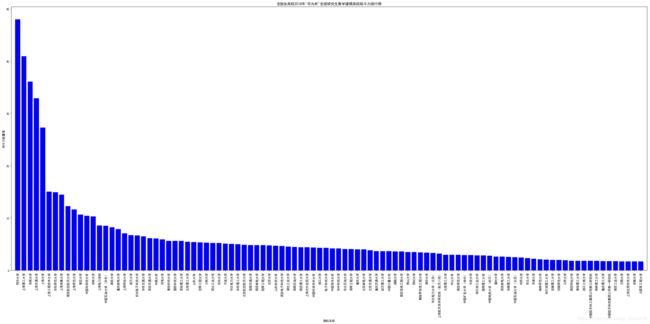
8.不足
本文代码确实较多,相比较**Jean_V**的代码不够简洁。
https://blog.csdn.net/CSDN_wujian/article/details/83961212
另外,针对组队的情况,如果是一个队来自于三个院校,本文是给每个高校都投票一次,可能存在给某些院校多累计了队伍数,比各个高校官方发布数量略高,但是好处是各个高校中藏富于民的部分也都考虑在内了,总体的趋势跟各个高校官方差别甚微。在Jean_V的代码中每个队伍只投票一次,即:以队长所在高校为准来做统计分析。