分享一个控制台翻译工具
用起来长这样
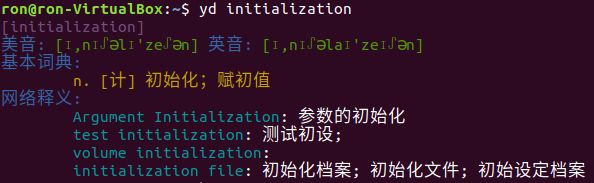
环境:
VirtualBox+Ubuntu 18.04.02
最近逛Ubuntu应用商店,看到网友做了这么一个东东,感觉想法挺不错的。学习Linux经常要阅读英文文档,手上有个控制台输出的翻译工具,CTRL-TAB切换到终端,只需敲打相关的命令就可以马上弄明白词义。整个过程连鼠标都不用碰,确实会比GUI翻译工具效率高出不少。

当然也有网友自己写了个linux终端翻译神器
,用一个文件来实现这个功能(用了很少的库),只是输出格式上还有待考究,而且没有读音标注。不过可以当成一个精简的范例来学习。
这里说一下yd应用安装下来是不能使用的,报错原因是main.py一处语法错误(引号不成对),文件目录显示2017年之后就没人维护了。想着源码都有,干脆自己动手改。
顺便说一下,这是snap商城的东西,安装目录都是只读的,所以还不能硬上。
环境搭建流程
-
将 /snap/yd/2/lib/python2.7/site-packages/youdao/ 这个目录拷贝到$HOME下。
-
把main.py那处语法错误改了。
-
安装所需要的库,必要的时候加上版本号
pip install termcolor
pip install requests
pip install peewee==2.9.1
pip install bs4
pip install lxml==3.7.3 -
main.py中有个和snap相关的目录要改,并且在这个目录下创建/dicts空目录。
SNAP = ‘/home/USER_NAME/youdao’
-
在$HOME/.bashrc中加入自定义命令
alias yd=‘python /home/USER_NAME/youdao/main.py’
-
source $HOME/.bashrc
然后就可以尽情地玩耍了。
功能描述
今天看了下代码,把用到的库的作用也整明白了(原来这就是爬虫),刚好看到main.py的帮助文档是空的。
def show_help():
desc = '''
== 说明 ==
* 功能描述
获取查询结果有两种方式:
1. 使用api的方式,直接返回json字符串
2. 使用页面方式,则需要借用BeautifulSoup解析返回的html
PS. 如果以上查询都失败(比如给句子加上标点),则使用有道翻译
查询记录保存在peewee数据库中,所有基于db的操作都与此有关
离线字典保存的目录,由config.config['stardict']指定
* 可选参数
-a 使用有道api查询,参考官网 http://fanyi.youdao.com/openapi?path=data-mode
-n 不用数据库中缓存的查询记录
-l 列出查询记录及累计次数
-d [key] 删除制定文本的查询记录,包括发音文件
-c 删除所有的查询记录,包括发音文件
-v 查询并播放发音,可使用 yd -v 重复播放上一查询记录的发音
-s [path] 指定离线字典的目录,默认为/dicts
-y 完全的在线查询。既不使用数据库查询记录,也不使用离线字典
'''
print desc
修复get_translation函数
[spider.py]
def get_translation(self, word):
"""
通过web版有道翻译抓取翻译结果
:param word:str 关键字
:return:list 翻译结果
"""
r = requests.get(self.translation_url+word)
if r.status_code != requests.codes.ok:
return None
pattern = re.compile(r'"translateResult":\[(\[.+\])\]')
m = pattern.search(r.text)
result = json.loads(m.group(1))
return [item['tgt'] for item in result]
可能因为有道翻译版本升级过,这里的get_translation并不好使,输入以下命名会有tb。
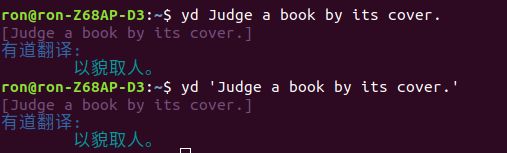
ron@ron-Z68AP-D3:~$ yd 'Judge a book by its cover.'
[Judge a book by its cover.]
有道翻译:
Traceback (most recent call last):
File "/home/ron/youdao/main.py", line 236, in <module>
main()
File "/home/ron/youdao/main.py", line 233, in main
query(keyword, use_db, use_api, play_voice, use_dict)
File "/home/ron/youdao/main.py", line 117, in query
show_result(result)
File "/home/ron/youdao/main.py", line 45, in show_result
print colored('\t'+'\n\t'.join(result['translation']), 'cyan')
TypeError: can only join an iterable
加个标点符号,api和web两个方式就跪了
 预期是拿到翻译’以貌取人’。
预期是拿到翻译’以貌取人’。
 既然原版的url访问方式不可行,就自己尝试实现这个功能好了。
既然原版的url访问方式不可行,就自己尝试实现这个功能好了。
[spider.py]
translation_url = u'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
def md5(self, str_data):
"""
md5加密
"""
md5_obj = hashlib.md5()
byte_data = str_data.encode('utf-8')
md5_obj.update(byte_data)
return md5_obj.hexdigest()
def get_translation(self, word):
"""
通过web版有道翻译抓取翻译结果
:param word:str 关键字
:return:list 翻译结果
"""
client = 'fanyideskweb' #判断是网页还是客户端
# 由于网页是用的js的时间戳(毫秒)跟python(秒)的时间戳不在一个级别,所以需要*1000
salt = str(int(time.time()*1000))
# 网上不同的攻略取的魔数是不一样的,可能对应不同的版本吧
c = "@6f#X3=cCuncYssPsuRUE"
# c = "rY0D^0'nM0}g5Mm1z%1G4"
# c = "ebSeFb%=XZ%T[KZ)c(sy!"
# 根据md5的方式:md5(u + d + f + c),拼接字符串生成sign参数。
sign = self.md5(client + word + salt + c)
# bv用到浏览器的版本编号
navigatorAppVersion = '5.0 (X11)'
bv = self.md5(navigatorAppVersion)
data = {
'i':word,
'from':'AUTO',
'to':'AUTO', #判断是自动翻译还是人工翻译
'smartresult':'dict',
'client':client,
'salt':salt, #当前时间戳
'sign':sign, #获取加密串
'ts':salt,
'bv':bv,
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME', #判断按回车提交或者点击按钮提交的方式
'typoResult':'false',
}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate', #
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Content-Length': '259', #
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'fanyi.youdao.com',
'Origin':'http://fanyi.youdao.com/', #请求头最初是从youdao发起的,Origin只用于post请求
'Referer':'http://fanyi.youdao.com/', #Referer则用于所有类型的请求
'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0',
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.post(self.translation_url, headers=headers, data=data)
pattern = re.compile(r'"translateResult":\[(\[.+\])\]')
m = pattern.search(r.text)
result = json.loads(m.group(1))
return [item['tgt'] for item in result]
效果
参考文献:
Python网络爬虫(八) - 利用有道词典实现一个简单翻译程序
解答了大部分问题,但是我的浏览器里多了两个参数ts bv。
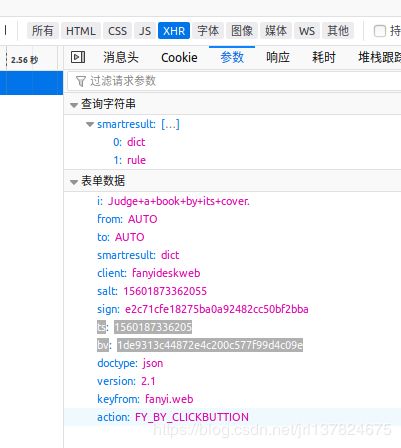
有道翻译的爬取
很不爽这里面没有说清楚为什么替换了url。不过有意思的是itchat这个玩意。
 破解有道翻译反爬虫机制
破解有道翻译反爬虫机制
代码直接可用,只是加标点会有tb。
ron@ron-Z68AP-D3:~$ python3 test.py
请输入Judge a book by its cover.
判断一本书的好坏湾。
Traceback (most recent call last):
File "test.py", line 68, in <module>
youdao(input("请输入"))
File "test.py", line 64, in youdao
for i in strs_datas['smartResult']['entries']:
KeyError: 'smartResult'
ron@ron-Z68AP-D3:~$ python3 test.py
请输入Judge a book by its cover
通过封面来判断一本书的好坏
以貌取人