Robot Framework用户指南
Robot Framework用户指南
版本2.8.6
目录
- 1开始
- 1.1简介
- 1.2版权和许可
- 1.3安装说明
- 1.4示范
- 2创建测试数据
- 2.1测试数据语法
- 2.2创建测试用例
- 2.3创建测试套件
- 2.4使用测试库
- 2.5变量
- 2.6创建用户关键字
- 2.7资源和变量文件
- 2.8高级功能
- 3执行测试用例
- 3.1基本用法
- 3.2测试执行
- 3.3后处理输出
- 3.4配置执行
- 3.5创建输出
- 4扩展机器人框架
- 4.1创建测试库
- 4.2远程库接口
- 4.3使用监听器接口
- 4.4扩展机器人框架Jar
- 5个支持工具
- 5.1库文档工具(libdoc)
- 5.2测试数据文档工具(testdoc)
- 5.3测试数据清理工具(整洁)
- 5.4外部工具
- 6附录
- 6.1测试数据中的所有可用设置
- 6.2所有的命令行选项
- 6.3测试数据模板
- 6.4文档格式
- 6.5时间格式
- 6.6内部API
1开始
- 1.1简介
- 1.2版权和许可
- 1.3安装说明
- 1.4示范
1.1简介
Robot Framework是一个基于Python的,可扩展的关键字驱动的测试自动化框架,用于端到端验收测试和验收测试驱动开发(ATDD)。它可以用于测试分布式异构应用程序,其中验证需要涉及多种技术和接口。
- 1.1.1为什么使用Robot Framework?
- 1.1.2高级架构
- 1.1.3截图
- 1.1.4获取更多信息
- 项目页面
- 邮件列表
1.1.1为什么使用Robot Framework?
- 以统一的方式创建易于使用的表格语法来创建测试用例。
- 提供从现有关键字创建可重用的更高级关键字的功能。
- 以HTML格式提供易于阅读的结果报告和日志。
- 平台和应用程序是独立的。
- 提供一个简单的库API来创建自定义的测试库,可以用Python或Java本地执行。
- 提供命令行界面和基于XML的输出文件, 用于集成到现有的构建基础架构(持续集成系统)中。
- 为Web测试,Java GUI测试,运行进程,Telnet,SSH等提供对Selenium的支持。
- 支持创建数据驱动的测试用例。
- 内置对变量的支持,尤其适用于在不同环境下进行测试。
- 提供标记来分类和选择要执行的测试用例。
- 实现与源代码控制的轻松集成:测试套件只是可以用生产代码进行版本化的文件和目录。
- 提供测试用例和测试套件的级别设置和拆卸。
- 模块化体系结构支持创建测试,即使是具有多种不同接口的应用程
1.1.2高级架构
Robot Framework是一个通用的,应用程序和技术独立的框架。它有一个高度模块化的架构,如下图所示。
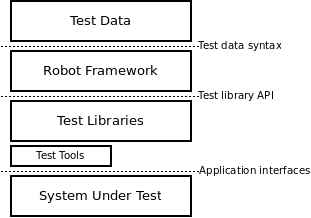
机器人框架结构
该测试数据是简单,易于编辑表格格式。当Robot Framework启动时,它处理测试数据,执行测试用例并生成日志和报告。核心框架不知道任何关于被测试的目标,与它的交互由测试库处理。库可以直接使用应用程序接口,也可以使用底层的测试工具作为驱动程序。
1.1.3截图
以下屏幕截图显示了测试数据的示例以及创建的 报告和日志。
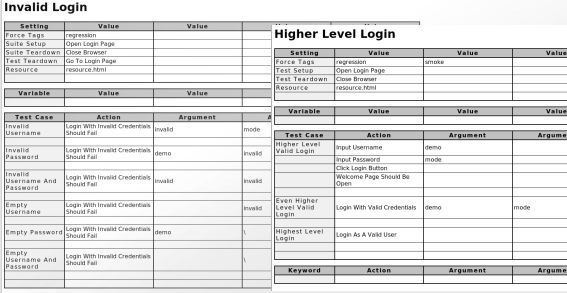
测试用例文件
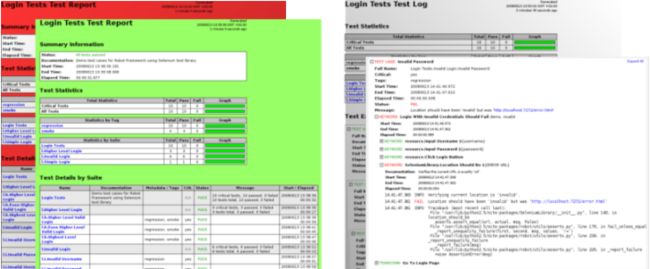
报告和日志
1.1.4获取更多信息
项目页面
寻找更多关于Robot Framework及其周围丰富生态系统信息的第一位是http://robotframework.org。Robot Framework本身托管在GitHub上。
邮件列表
有几个机器人框架邮件列表在哪里要求和搜索更多的信息。邮件列表档案是为所有人(包括搜索引擎)开放的,每个人都可以自由地加入这些列表。但是,只有列表成员才能发送邮件,并且为了防止垃圾邮件,新用户将被主持,这意味着您的第一封邮件可能需要一些时间。不要害怕把问题发送到邮件列表,但记得如何提出问题的智能方式。
- robotframework用户
- 有关所有Robot Framework相关问题的一般性讨论。问题和问题可以发送到这个列表。也用于所有用户的信息共享。
- robotframework通告
- 只有公告人的邮件列表,只有版主可以发送邮件。所有公告也发送到robotframework-users邮件列表,所以不需要加入这两个列表。
- robotframework-devel的
- 关于Robot Framework开发的讨论。
- robotframework提交
- 自动生成关于提交到版本控制系统的邮件,构建结果,新的和编辑的问题等等。可以用来跟踪Robot Framework的开发。
1.2版权和许可
Robot Framework本身,与它一起分发的测试库和支持工具,以及本用户指南和其他提供的文档都有以下版权声明。
版权所有2008-2014诺基亚解决方案和网络根据Apache许可证2.0版(“许可证”)获得许可;除遵守许可证外,不得使用此文件。您可以在获得许可证副本 http://www.apache.org/licenses/LICENSE-2.0除非适用法律要求或书面同意,软件根据许可证分发的数据按“现状”分发,没有任何形式的保证或条件,无论是明示的还是暗示的。请参阅许可证以获取有关权限和权限的特定语言根据许可证的限制。
1.3安装说明
这些说明包括在不同的操作系统上安装和卸载Robot Framework及其先决条件。如果你已经安装了pip,那么运行就足够了:
点安装robotframework
- 1.3.1简介
- 1.3.2先决条件
- Python安装
- Jython安装
- IronPython安装
- 配置PATH
- 设置https_proxy
- 1.3.3安装Robot Framework
- 包管理员(如点子)
- 从源代码安装
- 使用Windows安装程序
- 独立的JAR分发
- 手动安装
- 验证安装
- 在哪里安装文件
- 1.3.4卸载和升级
- 卸载
- 升级
- 1.3.5不同的入口点
- 跑步者脚本
- 直接入口点
1.3.1简介
Robot Framework是用Python实现的,也可以在Jython(JVM)和 IronPython(.NET)上运行。在安装框架之前,一个明显的先决条件是安装至少一个这样的解释器。请注意,Python 3尚不支持,但有一个非官方的Python 3端口可用。
下面列出了安装Robot Framework本身的不同方法,并在随后的章节中进行更详细的解释。
- 包管理员(如点子)
-
Python包管理器使安装变得微不足道。例如,pip用户只需要执行:
点安装robotframework
不过,使用包管理器会首先增加一个先决条件来安装包管理器本身。
- 从源代码安装
- 无论使用的是操作系统还是Python解释器,这种方法都可以工作。您可以通过从 PyPI下载和提取源代码或克隆 GitHub存储库来获取源代码。
- 使用Windows安装程序
- 有32位和64位Windows系统的图形化安装程序,都可以在 PyPI上找到。
- 独立的JAR分发
-
如果使用Jython运行测试就足够了,最简单的方法是从 Maven central下载独立的
robotframework-
.jar 。JAR发行包含Jython和Robot Framework,因此只需要安装 Java。 - 手动安装
- 如果您有特殊的需求而没有其他的工作,您可以随时进行自定义手动安装。
1.3.2先决条件
Robot Framework支持Python,Jython(JVM)和IronPython(.NET),也可以在PyPy上运行。在安装框架之前应该安装你想要使用的解释器。
一般来说,使用哪种解释器取决于所需的测试库和测试环境。一些库使用只能用于Python的工具或模块,而另一些则可能使用需要Jython或需要.NET的Java工具,因此需要使用IronPython。还有很多工具和库可以和所有的解释器一起运行。
如果您没有特殊需求或者只是想尝试框架,建议使用Python。这是最成熟的实现,比Jython或IronPython快得多(特别是启动时间更快),并且在大多数类UNIX操作系统上也很容易获得。另一个很好的选择是使用仅以Java为前提的独立JAR发行版。
Python安装
在大多数类UNIX系统(如Linux和OS X)上,您默认安装了Python。如果你使用的是Windows,或者需要自己安装Python,那么一个好的开始是http://python.org。在那里,你可以下载一个合适的安装程序,并获得有关安装过程和Python的更多信息。
Robot Framework目前支持Python版本2.5,2.6和2.7。计划将来也会支持Python 3,同时Python 2.5的支持将会被抛弃。Robot Framework 2.0和2.1支持Python 2.3和2.4。
在Windows上,建议将Python安装到所有用户,并以管理员身份运行安装程序。另外,不能设置环境变量 PYTHONCASEOK。
安装Python之后,您可能仍然需要配置PATH以使命令提示符下的pybot runner脚本可执行。
Jython安装
使用用Java实现的测试库或内部使用Java工具的测试库需要在Jython上运行Robot Framework,而Jython又需要Java Runtime Environment(JRE)或Java Development Kit(JDK)。安装这些Java实现中的任何一个都不在这些说明的范围内,但是如果需要,您可以从http://java.com找到更多信息。
安装Jython是一个相当简单的过程,第一步是从http://jython.org获取安装程序。安装程序是一个可执行的JAR包,可以像命令行一样运行java -jar jython_installer-。根据系统配置,也可以双击安装程序。
支持的最低Jython版本是2.5,需要Java 5(也称为Java 1.5)或更新版本。即将到来的Jython 2.7将需要最少的Java 7,而且将来对于Jython 2.5的支持也将是Robot Framework的最低限度。Robot Framework 2.0和2.1支持Jython 2.2。
安装Jython之后,您可能仍然需要配置PATH以在命令提示符下使jybot runner脚本可执行。
IronPython安装
IronPython允许在.NET平台上运行Robot Framework,并与C#和其他.NET语言和API进行交互。只支持IronPython 2.7。
当使用IronPython时,额外的依赖项是安装 elementtree 模块1.2.7预览版。这是必需的,因为 使用IronPython分发的elementtree模块已经 损坏。您可以通过下载源代码发行版,解压缩并ipy setup.py install在创建的目录中的命令提示符下运行来安装该程序包 。
安装IronPython之后,您可能仍然需要配置PATH以使命令提示符下的ipybot runner脚本可执行。
配置PATH
该PATH环境变量列出其中在一个系统中执行的命令是从搜索位置。为了使命令提示符更容易使用Robot Framework,建议将运行器脚本的安装位置添加到PATH中。跑步者脚本本身需要匹配的解释器在PATH中,因此解释器安装目录也必须添加到那里。
在类似UNIX的机器上使用Python时,Python本身和安装的脚本都应该自动在PATH中,不需要额外的操作。在Windows和其他解释器上,PATH必须单独配置。
什么目录添加到PATH
需要将哪些目录添加到PATH取决于解释器和操作系统。第一个位置是解释器的安装目录(例如C:\ Python27),另一个位置是解释器安装脚本的位置。Python和IronPython都将脚本安装到Windows安装目录下的Scripts目录(例如C:\ Python27 \ Scripts),Jython使用bin 目录而不管操作系统(例如C:\ jython2.5.3 \ bin)。
请注意,脚本和bin目录可能不会作为解释器安装的一部分创建,而只是在稍后安装Robot Framework或其他第三方模块时才创建。
在Windows上设置PATH
在Windows上,您可以按照以下步骤配置PATH。请注意,确切的设置名称可能在不同的Windows版本上有所不同,但基本方法应该仍然是相同的。
- 打开
Start > Settings > Control Panel > System > Advanced > Environment Variables。有User variables和System variables,和它们的区别是用户变量只影响当前用户,而系统变量影响所有用户。 - 要编辑现有的PATH值,请在值(例如)的末尾 选择
Edit并添加 。请注意分号()在分离不同的条目时非常重要。要添加一个新的PATH 值,选择并设置名称和值,这次没有前导分号。;; ;C:\Python27;C:\Python27\Scripts;New - 退出对话框
Ok以保存更改。 - 启动新的命令提示符以使更改生效。
请注意,如果你安装了多个版本的Python,在执行 pybot脚本总是会使用一个是第一个在PATH 无论在什么样的Python版本该脚本安装。为了避免这种情况,您可以随时使用直接入口点和解释器C:\Python26\python.exe -m robot.run。
还要注意,你不应该在你添加到PATH中的目录周围添加引号(例如"C:\Python27\Scripts")。引号可能会导致Python程序出现问题,即使目录路径包含空格,PATH也不需要它们。
在类UNIX系统上设置PATH
在类UNIX系统上,通常需要编辑某个系统范围或用户特定的配置文件。要编辑哪个文件以及如何依赖于系统,并且需要查阅操作系统文档以获取更多详细信息。
设置https_proxy
如果您打算使用pip进行安装并位于代理之后,则需要设置https_proxy环境变量。在安装pip和使用它来安装Robot Framework和其他Python包时都需要它。
如何设置https_proxy取决于操作系统,类似于 配置PATH。此变量的值必须是代理的URL,例如http://10.0.0.42:8080。
1.3.3安装Robot Framework
包管理员(如点子)
最流行的Python软件包管理器是pip,但也有其他的选择,比如Buildout和easy_install。这些说明只包括使用pip,但是其他软件包管理者也应该能够安装Robot Framework,至少如果他们从PyPI搜索软件包的话。
安装pip
使用点最难的部分是安装工具本身,但幸运的是,也不是太复杂。您可以从pip项目页面找到最新的安装说明。只要记住,如果您在代理之后,则需要在安装和使用pip之前设置https_proxy环境变量。
pip的一个更大的问题是,在编写本文时,只有Python支持它。即将到来的Jython 2.7应该支持它,甚至捆绑它,但目前还不清楚什么时候会被IronPython支持。
另一个小的限制是,只有Robot Framework 2.7和更新版本可以使用pip来安装。如果您需要安装较旧的版本,则必须使用其他安装方法。
使用点子
一旦你安装了pip,在命令行上使用它就非常简单了。最常用的用法如下所示,pip文档有更多信息和示例。
#安装最新版本点安装robotframework#升级到最新版本pip安装 - 升级robotframework#安装特定版本的 pip install robotframework == 2.8.5# 卸载点卸载robotframework
注意,pip 1.4和更新版本只会默认安装稳定的版本。如果您想要安装alpha,beta或release候选版本,则需要明确指定版本或使用--pre选项:
#安装2.9 beta 1 点安装robotframework == 2.9b1#即使是预发行版,也要安装最新版本pip install --pre robotframework
如果您仍然使用pip 1.3或更高版本,并且不想在预发行版本中获得最新版本,则需要明确指定要安装的稳定版本。
从源代码安装
此安装方法可以在任何支持的解释器的操作系统上使用。从源代码安装听起来有点可怕,但程序实际上是非常简单的。
获取源代码
通常,您可以通过下载获得源代码源代码分发包 的.tar.gz格式。PyPI提供了更新的软件包,但Robot Framework 2.8.1及更高版本可以从旧的Google Code下载页面找到。一旦你下载了软件包,你需要把它解压到某个地方,结果你得到一个名为的目录robotframework-。该目录包含安装它所需的源代码和脚本。
获取源代码的另一种方法是直接克隆项目的 GitHub存储库。默认情况下,您将获得最新的代码,但是您可以轻松切换到不同的发布版本或其他标签。
安装
Robot Framework是使用Python的标准setup.py 脚本从源代码安装的。该脚本位于包含源代码的目录中,可以使用任何受支持的解释器从命令行运行该脚本:
#用Python进行安装。创建`pybot`和`rebot`脚本。python setup.py安装#使用Jython进行安装。创建`jybot`和`jyrebot`脚本。jython setup.py安装#用IronPython安装。创建`ipybot`和`ipyrebot`脚本。ipy setup.py安装
该setup.py脚本接受几个参数,允许,例如,在安装到不需要管理员权限的非默认位置。它也用于创建不同的分发包。运行 python setup.py --help更多的细节。
使用Windows安装程序
有32位和64位Windows系统的独立图形安装程序,名称格式分别为robotframework-
Windows安装程序始终在Python上运行,并创建标准的pybot和 rebot runner脚本。与其他提供的安装程序不同,这些安装程序还会自动创建jybot和ipybot脚本。为了能够使用创建的运行脚本,包含它们的脚本目录和适当的解释器都需要在PATH中。
安装Robot Framework可能需要管理员权限。在这种情况Run as administrator下,在启动安装程序时从上下文菜单中选择。
独立的JAR分发
Robot Framework也作为一个独立的Java归档文件进行分发,它包含了Jython和Robot Framework,只需要Java依赖。将所有东西放在一个不需要安装的软件包中是一个简单的方法,但是它有一个缺点,它不能和普通的Python解释器一起工作。
这个软件包被命名为robotframework-
java -jar robotframework-2.8.5.jar mytests.txtjava -jar robotframework-2.8.5.jar - 变量名称:value mytests.txt
如果要使用Rebot 后处理输出或使用其他内置 支持工具,则需要将命令名称rebot,libdoc, testdoc或tidy作为JAR文件的第一个参数:
java -jar robotframework-2.8.5.jar rebot output.xmljava -jar robotframework-2.8.5.jar libdoc MyLibrary列表
有关不同命令的更多信息,请执行不带参数的JAR。
手动安装
如果您不想使用任何自动安装Robot Framework的方式,则可以按照以下步骤手动安装它:
- 获取源代码。所有的代码都在一个名为robot的目录(Python中的一个包)中。如果您有一个源代码发行版或版本控制签出,您可以从src目录中找到它,但是您也可以从早期的安装中获取它。
- 将源代码复制到你想要的地方。
- 创建您需要的跑步者脚本,或使用 您选择的解释器直接入口点。
验证安装
成功安装后,您应该能够使用--version选项执行已创建的运行脚本,并获得Robot Framework和解释器版本:
$ pybot --versionRobot Framework 2.8.5 ( linux2上的Python 2.7.3 )$ rebot --versionRebot 2.8.5 (在linux2上的Python 2.7.3 )$ jybot --versionRobot Framework 2.8.5 ( java1.7.0_60上的Jython 2.5.3 )
如果运行runner脚本失败,并显示一条消息,指出找不到或识别该命令,那么首先需要仔细检查PATH 配置。如果这样做没有帮助,在从互联网寻求帮助之前重新阅读这些说明中的相关部分,或者在robotframework-users邮件列表或其他地方寻求帮助。
在哪里安装文件
当使用自动安装程序时,Robot Framework源代码被复制到包含外部Python模块的目录中。在预装了Python的类UNIX操作系统上,此目录的位置各不相同。如果您自己安装了解释器,它通常 位于解释器安装目录下的Lib / site-packages,例如C:\ Python27 \ Lib \ site-packages。实际的Robot Framework代码位于一个名为robot的目录中。
Robot Framework运行器脚本被创建并复制到另一个特定于平台的位置。在类UNIX系统上使用Python时,通常使用/ usr / bin或/ usr / local / bin。在Windows和其他解释器上,脚本通常位于解释器安装目录下的脚本 或bin目录中。
1.3.4卸载和升级
卸载
如何卸载Robot Framework取决于原始的安装方法。请注意,如果您已经设置PATH或配置了您的环境,则需要单独撤消这些更改。
使用pip卸载
如果你有可用的pip,卸载就像安装一样简单:
点卸载robotframework
一个不错的点子功能是它可以卸载软件包,即使安装已经完成使用其他方法。
使用Windows安装程序后卸载
如果 已经使用Windows安装程序,则可以使用卸载 Control Panel > Add/Remove Programs。Robot Framework列在Python应用程序下。
手动卸载
该框架总是可以手动卸载。这需要删除创建的机器人目录和运行脚本。查看上面安装文件的部分,以了解可以在哪里找到它们。
升级
在升级或降级Robot Framework时,在两个次要版本(例如2.8.4到2.8.5)之间切换时,可以安全地在现有版本上安装新版本。这通常也适用于升级到新的主要版本,例如,从2.8.5到2.9,但卸载旧版本总是更安全。
pip软件包管理器的一个非常好的功能是它在升级时自动卸载旧版本。在更改为特定版本或升级到最新版本时都会发生这种情况:
pip安装robotframework == 2.7.1pip安装 - 升级robotframework
无论版本和安装方式如何,您都不需要重新安装前提条件或重新设置PATH环境变量。
1.3.5不同的入口点
跑步者脚本
Robot Framework具有不同的运行脚本,用于执行测试用例和基于早期测试结果的后处理输出。除此之外,这些脚本根据所使用的解释器而不同:
| 翻译员 | 测试执行 | 后期处理 |
|---|---|---|
| 蟒蛇 | pybot | rebot |
| Jython的 | jybot | jyrebot |
| IronPython的 | ipybot | ipyrebot |
在类UNIX操作系统(如Linux和OS X)上,运行脚本是使用Python实现的,在Windows上它们是批处理文件。无论操作系统如何,使用这些脚本都需要相应的解释器在PATH中。
直接入口点
除了上面的runner脚本之外,还可以通过直接使用选定的解释器执行框架的入口点来运行测试和后处理输出。可以使用Python的-m选项将它们作为模块执行, 并且如果知道安装框架的位置,则可以将它们作为脚本运行。下面的表格使用Python列出了入口点,下面的例子说明了在其他解释器中使用它们的方法。
| 入口点 | 作为模块运行 | 以脚本运行 |
|---|---|---|
| 测试执行 | python -m robot.run |
python path/robot/run.py |
| 后期处理 | python -m robot.rebot |
python path/robot/rebot.py |
#通过执行`robot.run`模块,用Python运行测试。python -m robot.run#运行`robot / run.py`脚本运行Jython测试。jython path / to / robot / run.py#通过执行`robot.rebot`模块,用IronPython创建报表/日志。ipy -m robot.rebot#运行`robot / rebot.py`脚本,用Python创建报告/日志。python path / to / robot / rebot.py
1.4示范
有几个演示项目介绍Robot Framework并帮助开始使用它。
- 快速入门指南
- 介绍机器人框架的最重要的功能,并作为一个可执行的演示。
- 机器人框架演示
- 简单的示例测试用例。演示还创建自定义测试库。
- 网络测试演示
- 演示如何创建测试和更高级别的关键字。被测系统是一个简单的网页,使用 Selenium2Library进行测试。
- SwingLibrary演示
- 演示如何使用 SwingLibrary来测试Java GUI应用程序。
- ATDD与机器人框架
- 演示如何在遵循验收测试驱动开发(ATDD)过程时使用Robot Framework。
2创建测试数据
- 2.1测试数据语法
- 2.2创建测试用例
- 2.3创建测试套件
- 2.4使用测试库
- 2.5变量
- 2.6创建用户关键字
- 2.7资源和变量文件
- 2.8高级功能
2.1测试数据语法
本节介绍Robot Framework的整体测试数据语法。以下部分将解释如何实际创建测试用例,测试套件等。
- 2.1.1文件和目录
- 2.1.2支持的文件格式
- HTML格式
- TSV格式
- 纯文本格式
- reStructuredText格式
- 2.1.3测试数据表
- 2.1.4解析数据的规则
- 忽略的数据
- 处理空白
- 逃离
- 将测试数据分成几行
2.1.1文件和目录
安排测试用例的层次结构如下:
- 测试用例在测试用例文件中创建。
- 测试用例文件会自动创建一个包含该文件中的测试用例的测试套件。
- 包含测试用例文件的目录构成了更高级别的测试套件。这样的测试套件目录具有从测试用例文件创建的套件作为其子测试套件。
- 测试套件目录也可以包含其他测试套件目录,并且这个分层结构可以根据需要深度嵌套。
- 测试套件目录可以有一个特殊的初始化文件。
除此之外,还有:
- 测试包含最低级关键字的库。
- 带有变量和更高级别用户关键字的资源文件。
- 变量文件提供比资源文件更灵活的创建变量的方法。
2.1.2支持的文件格式
Robot Framework测试数据以表格格式定义,使用超文本标记语言(HTML),制表符分隔值(TSV),纯文本或reStructuredText(reST)格式。这些格式的细节,以及它们的主要优点和问题,将在后面的章节中进行解释。要使用哪种格式取决于上下文,但如果没有特殊需要,则建议使用纯文本格式。
Robot Framework根据文件扩展名为测试数据选择一个解析器。该扩展名不区分大小写,HTML的扩展名为 .html,.htm和.xhtml, TSV的.tsv,.txt和纯文本的特殊.robot, 以及.resstructuredText的.rst和.rest。
不同的测试数据模板可用于HTML和TSV格式,以便开始编写测试。
注意
从Robot Framework 2.7.6开始,支持纯文本文件的特殊.robot扩展。
HTML格式
HTML文件支持表格周围的格式和自由文本。这样可以将附加信息添加到测试用例文件中,并允许创建看起来像正式测试规范的测试用例文件。HTML格式的主要问题是使用普通文本编辑器编辑这些文件并不容易。另一个问题是,HTML不能和版本控制系统一起工作,因为除了对实际测试数据的更改之外,更改产生的差异包含HTML语法。
在HTML文件中,测试数据是在单独的表中定义的(请参见下面的示例)。Robot Framework 根据第一个单元格中的文本识别这些测试数据表。认可的表格外的所有内容都被忽
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | 操作系统 | ||
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| $ {文} | 你好,世界! | ||
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 我的测试 | [文档] | 示例测试 | |
| 日志 | $ {文} | ||
| 我的关键字 | / tmp目录 | ||
| 另一个测试 | 应该是平等的 | $ {文} | 你好,世界! |
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 我的关键字 | [参数] | $ {PATH} | |
| 目录应该存在 | $ {PATH} |
编辑测试数据
HTML文件中的测试数据可以使用您喜欢的任何编辑器进行编辑,但建议您使用图形编辑器,在这里您可以真正看到表格。RIDE可以读取和写入HTML文件,但不幸的是,它会丢失所有的HTML格式以及测试用例表之外的可能的数据。
编码和实体引用
HTML实体引用(例如,ä)受支持。另外,可以使用任何编码,假设它在数据文件中被指定。正常的HTML文件必须使用META元素,如下例所示:
在本例中,XHTML文件应该使用XML前导码:
<?xml version =“1.0”encoding =“Big5”?>
如果没有指定编码,Robot Framework默认使用ISO-8859-1。
TSV格式
TSV文件可以在电子表格程序中进行编辑,因为语法非常简单,所以很容易以编程方式生成。它们使用普通的文本编辑器也很容易编辑,而且它们在版本控制中运行良好,但纯文本格式更适合于这些目的。
TSV格式可以在Robot Framework的测试数据中用于与HTML相同的目的。在TSV文件中,所有数据都在一个大表中。测试数据表可以从一个或多个星号(*)中识别出来,然后是一个普通的表名和一个可选的星号。第一个识别表之前的所有内容都被忽略,就像HTML数据中的表外数据一样。
| *设置* | *值* | *值* | *值* |
| 图书馆 | 操作系统 | ||
| *变量* | *值* | *值* | *值* |
| $ {文} | 你好,世界! | ||
| *测试用例* | *行动* | *论据* | *论据* |
| 我的测试 | [文档] | 示例测试 | |
| 日志 | $ {文} | ||
| 我的关键字 | / tmp目录 | ||
| 另一个测试 | 应该是平等的 | $ {文} | 你好,世界! |
| *关键词* | *行动* | *论据* | *论据* |
| 我的关键字 | [参数] | $ {PATH} | |
| 目录应该存在 | $ {PATH} |
编辑测试数据
您可以在任何电子表格程序(如Microsoft Excel)中创建和编辑TSV文件。保存文件时选择制表符分隔的格式,并记住将文件扩展名设置为.tsv。关闭所有自动更正并配置工具将文件中的所有值作为纯文本处理也是一个好主意。
使用任何文本编辑器编辑TSV文件都相对容易,尤其是编辑器支持从空格中可视地分离制表符时。RIDE也支持TSV格式。
Robot Framework首先将所有内容分割成行,然后根据表格字符将行分割成单元格,从而分析TSV数据。电子表格程序有时会用引号括住单元格(例如"my value"),而Robot Framework会删除它们。数据内部的可能引号加倍(例如 "my ""quoted"" value"),这也是正确处理的。如果您使用电子表格程序来创建TSV数据,则不需要注意这一点,但是如果以编程方式创建数据,则必须遵循与电子表格相同的引用约定。
编码
TSV文件总是需要使用UTF-8编码。由于ASCII是UTF-8的子集,因此自然也支持纯ASCII。
纯文本格式
纯文本格式非常容易使用任何文本编辑器进行编辑,并且在版本控制中也可以很好地工作。由于这些好处,它已成为Robot Framework最常用的数据格式。
纯文本格式在技术上与TSV格式类似,但单元之间的分隔符不同。TSV格式使用制表符,但是在纯文本格式中,可以使用两个或多个空格或用空格(|)包围的管道符号。
该测试数据表必须有自己的名字前的一个或多个星号类似于在TSV格式。否则,星号,并在表头可能的空间被忽略的话,例如,*** Settings ***和*Settings工作方式相同。与TSV格式类似,第一个表格之前的所有内容都将被忽略。
在纯文本文件中,选项卡会自动转换为两个空格。这允许与TSV格式类似地使用单个标签作为分隔符。但是,请注意,在纯文本格式中,多个选项卡被认为是单个分隔符,而在TSV格式中,每个选项卡都是分隔符。
空格分隔的格式
用作分隔符的空格的数量可以变化,只要至少有两个空格,就可以很好地对齐数据。这对于在文本编辑器中编辑TSV格式有明显的好处,因为TSV不能控制对齐。
***设置***库操作系统 ***变量***$ { MESSAGE } 你好,世界!*** 测试用例 ***我的测试 [ 文档] 示例测试 记录 $ { MESSAGE } 我的关键字/ tmp 另一个测试 应该是平等的 $ { MESSAGE } 你好,世界!***关键词***我的关键字 [ 参数] $ { path } 目录应该存在 $ { path }
因为空间被用作分离器,所有空单元必须被转义 与${EMPTY}变量或一个反斜杠。否则, 处理空白与其他测试数据没有区别,因为前导,尾随和连续空格必须始终转义。
小费
建议在关键字和参数之间使用四个空格。
管道和空间分隔的格式
空格分隔的格式最大的问题是可视化分隔关键字表单参数可能会非常棘手。这是一个问题,特别是如果关键字需要大量参数和/或参数包含空格。在这种情况下,管道和空间分隔变体可以更好地工作,因为它使单元边界更加可见。
| *设置* | *值* | | 图书馆 | OperatingSystem || *变量* | *值* | | $ { MESSAGE } | 你好,世界! || *测试案例* | *行动* | *参数* | | 我的测试 | [ 文档] | 示例测试| | | 日志 | $ { MESSAGE } | | | 我的关键字 | / tmp | | 另一个测试| 应该是平等的| $ { MESSAGE } | 你好,世界!| *关键字* | | 我的关键字| [ 参数] | $ { path } | | 目录应该存在| $ { path }
纯文本文件可以包含空格和空格分隔格式的测试数据,但是单行必须使用相同的分隔符。由管道和空间分隔的管线由强制性的管道进行识别,但管线末端的管道是可选的。管道两侧至少有一个空间(开始和结束处除外),但除了使数据更清楚以外,不需要对齐管道。
当使用管道和空间分隔格式时,不需要空白单元格(除了尾部空单元格)。唯一要考虑的是实际测试数据中由空格包围的可能管道必须使用反斜线进行转义:
| ***测试案例*** | | | | | 逃跑的管道 | $ { file count } = | 执行命令| ls -1 * .txt \ | wc -l | | | 应该是平等的| $ { file count } | 42 |
编辑和编码
纯文本格式比HTML和TSV最大的好处之一是使用普通文本编辑器进行编辑非常简单。许多编辑器和IDE(至少是Eclipse,Emacs,Vim和TextMate)也有支持语法突出显示Robot Framework测试数据的插件,并且还可以提供关键字完成等其他功能。RIDE也支持纯文本格式。
与TSV测试数据类似,纯文本文件始终应使用UTF-8编码。因此也支持ASCII文件。
认可的扩展
从Robot Framework 2.7.6开始,除了正常的.txt扩展名以外,还可以使用特殊的.robot扩展名保存纯文本测试数据文件。新的扩展使得将测试数据文件与其他纯文本文件区分开来变得更加容易。
reStructuredText格式
reStructuredText(reST)是一个易于阅读的纯文本标记语法,通常用于Python项目的文档(包括Python本身以及本用户指南)。reST文档通常被编译为HTML,但也支持其他输出格式。
在Robot Framework中使用reST允许您以简洁的文本格式混合丰富格式的文档和测试数据,使用简单的文本编辑器,差异工具和源代码管理系统可以轻松完成工作。实际上它结合了纯文本和HTML格式的许多好处。
在Robot Framework中使用reST文件时,有两种方法可以定义测试数据。您可以使用代码块并使用纯文本格式在其中定义测试用例,或者您可以像使用HTML格式一样使用表格。
注意
在Robot Framework中使用reST文件需要 安装Python docutils模块。
使用代码块
reStructuredText文档可以在所谓的代码块中包含代码示例。当这些文档被编译成HTML或其他格式时,代码块使用Pygments高亮语法。在标准的代码块中,开始使用code指令,但Sphinx使用code-block 或者sourcecode代替。代码块中的编程语言的名称作为指令的参数给出。例如,以下代码块分别包含Python和Robot Framework示例:
.. code :: python 高清 EXAMPLE_KEYWORD (): 打印 '你好,世界!'.. code :: robotframework *** 测试用例 *** 示例测试 示例关键字
当机器人框架解析reStructuredText的文件,可能它首先搜索code,code-block或sourcecode含有机器人框架测试数据块。如果找到这样的代码块,则它们包含的数据被写入到内存文件中并被执行。代码块之外的所有数据都被忽略。
代码块中的测试数据必须使用纯文本格式进行定义。如下例所示,支持空间和管道分离变体:
例子-------这个文本在代码块之外,因此被忽略。.. code :: robotframework ***设置*** 库操作系统 ***变量*** $ { MESSAGE } 你好,世界! *** 测试用例 *** 我的测试 [ 文档] 示例测试 记录 $ { MESSAGE } 我的关键字/ tmp 另一个测试 应该是平等的 $ { MESSAGE } 你好,世界!此外,这个文本是在代码块之外,并被忽略。上面的块使用空格分隔纯文本格式和下面的块使用管道分开的变体。.. code :: robotframework | ***关键字*** | | | | 我的关键字 | [ 参数] | $ { path } | | | 目录应该存在| $ { path } |
注意
使用反斜杠字符转义通常以这种格式工作。不需要双重转义,就像使用重新表格一样。
注意
支持代码块中的测试数据是Robot Framework 2.8.2中的一项新功能。
使用表格
如果reStructuredText文档不包含具有Robot Framework数据的代码块,则希望与表格中的数据类似于HTML格式。在这种情况下,Robot Framework将文档编译为内存中的HTML,并将其解析为完全像分析正常HTML文件一样。
Robot Framework 根据第一个单元格中的文本识别测试数据表,并且忽略所识别表格类型之外的所有内容。以下使用简单表格和网格表语法显示四个测试数据表格中的每一个的示例:
例子-------该文本在表格之外,因此被忽略。============ ================ ======= ======= 设定值的价值============ ================ ======= =======库操作系统============ ================ ======= =================== ================ ======= ======= 变量值的值============ ================ ======= =======$ {MESSAGE}你好,世界!============ ================ ======= ==================== ================== ============ ======= ====== 测试用例操作参数参数============= ================== ============ ======= ======我的测试[文档]示例测试\ Log $ {MESSAGE}\我的关键字/ tmp\另一个测试应该是相等的$ {MESSAGE}你好,世界!============= ================== ============ ======= ======此外,这个文本是在表之外,并被忽略。上面的表格被创建使用简单的表格语法和下面的表格使用网格表做法。+ ------------- + ------------------------ + ---------- - + ------------ +| 关键字| 行动| 参数| 参数|+ ------------- + ------------------------ + ---------- - + ------------ +| 我的关键字| [参数] | $ {path} | |+ ------------- + ------------------------ + ---------- - + ------------ +| | 目录应该存在| $ {path} | |+ ------------- + ------------------------ + ---------- - + ------------ +
注意
第一列简单表格中的空单元格需要转义。上面的例子使用\,但..也可以使用。
注意
由于反斜线字符是reST中的转义字符,因此指定一个反斜杠以使Robot Framework能看到它,需要使用另一个反斜杠来转义它\\。例如,一个新的行字符必须写成像\\n。由于反斜杠也用于在Robot Framework数据中进行转义,因此在使用reST表时指定文字反斜杠需要进行双重转义c:\\\\temp。
每次运行测试时基于reST文件生成HTML文件显然会增加一些开销。如果这是一个问题,那么使用外部工具分别将reST文件转换为HTML是一个好主意,并让Robot Framework只使用生成的文件。
编辑和编码
reStructuredText文件中的测试数据可以用任何文本编辑器进行编辑,许多编辑器也为其提供自动语法高亮显示。虽然,RIDE不支持reST格式。
Robot Framework要求使用UTF-8编码保存包含非ASCII字符的reST文件。
reST源文件中的语法错误
如果reStructuredText文档在语法上不正确(例如格式错误的表格),则解析该文档将失败,并且不能从该文件中找到测试用例。执行单个reST文件时,Robot Framework将在控制台上显示错误。当执行一个目录时,这样的解析错误通常会被忽略。
2.1.3测试数据表
测试数据分为以下四种类型的表格。这些测试数据表由表的第一个单元格标识,下表中的最后一列列出了可用作表名称的不同别名。
| 表名 | 用于 | 别名 |
|---|---|---|
| 设置表 |
1)导入 测试库, 资源文件和 变量文件
2)为 测试套件 和 测试用例定义元数据
|
设置,设置,元数据 |
| 变量表 | 定义可以在测试数据中的其他地方使用的变量 | 变量,变量 |
| 测试案例表 | 从可用关键字创建测试用例 | 测试用例,测试用例 |
| 关键字表格 | 从现有的低级关键字创建用户关键字 | 关键字,关键字,用户关键字,用户关键字 |
2.1.4解析数据的规则
忽略的数据
Robot Framework解析测试数据时,忽略:
- 在第一个单元格中没有以可识别的表名称开头的所有表格。
- 除了第一个单元格外,表格第一行的其他所有内容。
- 所有数据在第一个表之前。如果数据格式允许表格之间的数据,也被忽略。
- 所有空行,这意味着这些行可以用来使表更具可读性。
- 行尾的所有空单元,除非它们被转义。
- 所有单反斜杠(\)不用于转义时。
#当它是单元格的第一个字符时,所有跟在散列字符()后面的字符。这意味着可以使用散列标记在测试数据中输入注释。- 所有格式在HTML / reST测试数据。
当Robot Framework忽略一些数据时,这些数据在任何生成的报告中都不可用,另外,Robot Framework使用的大多数工具也忽略它们。要添加Robot Framework输出中可见的信息,请将其放置在测试用例或套件的文档或其他元数据中,或使用BuiltIn关键字“ 日志”或“注释”进行记录。
处理空白
Robot Framework处理空白的方式与在HTML源代码中处理空白的方式相同:
- 换行符,回车符和制表符被转换为空格。
- 所有单元格中的前导空白符将被忽略。
- 多个连续的空格被折叠成一个空格。
除此之外,不间断空间被正常空间所替代。这样做是为了避免在无意间使用不间断空间而不是普通空间时出现难以调试的错误。
如果需要引导,尾随或连续空格,则必须将其转义。换行符,回车,制表符和非换空间可以使用被创建转义序列 \n,\r,\t,和\xA0分别。
逃离
Robot Framework测试数据中的转义字符是反斜线(\)和额外的内置变量 ${EMPTY},${SPACE} 通常可用于转义。下面将讨论不同的转义机制。
转义特殊字符
反斜杠字符可用于转义特殊字符,以便使用它们的字面值。
| 字符 | 含义 | 例子 |
|---|---|---|
\$ |
美元符号永远不会启动一个标量变量。 | \${notvar} |
\@ |
在符号上,永远不会启动一个列表变量。 | \@{notvar} |
\% |
百分号,永远不会启动一个环境变量。 | \%{notvar} |
\# |
哈希符号,从不开始评论。 | \# not comment |
\= |
等号,从不是命名参数语法的一部分。 | not\=named |
\| |
管道字符,而不是管道分隔格式中的分隔符。 | | Run | ps \| grep xxx | |
\\ |
反斜杠字符,永远不会逃脱任何东西。 | c:\\temp, \\${var} |
形成转义序列
反斜杠字符还允许创建特殊的转义序列,这些转义序列被识别为否则在测试数据中难以或不可能创建的字符。
| 序列 | 含义 | 例子 |
|---|---|---|
\n |
换行字符。 | first line\n2nd line |
\r |
回车符 | text\rmore text |
\t |
制表符。 | text\tmore text |
\xhh |
十六进制值的字符hh。 |
null byte: \x00, ä: \xE4 |
\uhhhh |
十六进制值的字符hhhh。 |
snowman: \u2603 |
\Uhhhhhhhh |
十六进制值的字符hhhhhhhh。 |
love hotel: \U0001f3e9 |
注意
在测试数据中创建的所有字符串(包括字符 \x02)都是Unicode,必要时必须显式转换为字节字符串。这是可以做到,例如,使用 转换为字节或编码字符串的字节中的关键字内建和字符串库,分别或类似str(value)或value.encode('UTF-8') 在Python代码。
注意
如果无效的十六进制值与使用\x,\u 或\U逸出,最终的结果是没有反斜线字符原始值。例如,\xAX(未十六进制)和 \U00110000(过大的值)的结果与xAX 和U00110000分别。但是,这种行为在未来可能会改变。
注意
${\n}如果需要操作系统相关的行终止符(\r\n在Windows和 \n其他地方),可以使用内置变量。
注意
\n被忽略之后可能的未转义的空白字符。这意味着two lines\nhere并且 two lines\n here是等同的。这样做的动机是在使用HTML格式时允许包含换行符的长行,但是其他格式也使用相同的逻辑。此规则的一个例外是在扩展变量语法内不会忽略空白字符。
注意
\x,\u并且\U在Robot Framework 2.8.2中转义序列是新的。
防止忽略空单元格
如果需要将空值作为关键字的参数或其他参数,则通常需要将其转义以防止被忽略。无论测试数据格式如何,清空尾随的单元格都必须转义,并且在使用 空格分隔格式时,必须转义所有空值。
空单元格可以使用反斜线字符或内置变量 进行转义 ${EMPTY}。后者通常是推荐的,因为它更容易理解。此建议的一个例外是在使用空格分隔格式时,使用反斜线转义 for循环中的缩进单元格。所有这些情况在以下示例中首先以HTML格式显示,然后以空格分隔的纯文本格式显示:
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 使用反斜杠 | 做一点事 | 第一个arg | \ | |
| 使用$ {EMPTY} | 做一点事 | 第一个arg | $ {EMPTY} | |
| 非尾随空 | 做一点事 | 第二个arg | #在HTML中不需要转义 | |
| For循环 | :对于 | $ {VAR} | 在 | @ {} VALUES |
| 日志 | $ {VAR} | #这里也不需要转义 |
*** 测试用例 ***使用反斜杠 先做一些事arg \ 使用$ { EMPTY } 先做一些事情arg $ { EMPTY } 非尾随空 做些什么 $ { EMPTY } second arg #空格分隔格式所需的转义For循环 :FOR $ { var } IN @ { VALUES } \ Log $ { var } #这里也需要转义
防止无视空间
由于单元格中的前导空格,尾部空格和连续空格被忽略,因此如果需要将它们作为关键字的参数或以其他方式进行转义,则需要将其转义。与防止忽略空单元格一样,可以使用反斜线字符或使用内置变量来执行此操作 ${SPACE}。
| 用反斜杠转义 | 逃跑 ${SPACE} |
笔记 |
|---|---|---|
| 领先的空间 | ${SPACE}leading space |
|
| 尾随空间\ | trailing space${SPACE} |
反斜杠必须在空格之后。 |
| \ \ \ | ${SPACE} |
双方都需要反斜杠。 |
| 连续的\空格 | consecutive${SPACE * 3}spaces |
使用扩展的变量语法。 |
正如上面的例子所示,使用${SPACE}变量通常会使测试数据更容易理解。当需要多个空间时,与扩展变量语法结合使用尤其方便。
将测试数据分成几行
如果有更多的数据比随便一行,可以使用省略号(...)来继续前一行。在测试用例和用户关键字表中,省略号必须至少有一个空单元格。在设置和变量表中,它可以直接放置在设置或变量名下。在所有的表中,省略号之前的所有空单元都被忽略。
此外,只有一个值(主要是文档)的设置值可以分成几列。这些值将在解析测试数据时与空格一起连接。从Robot Framework 2.7开始,分割成多行的文档和测试套件元数据将与换行符一起连接。
下面的例子说明了上面讨论的所有语法。在前三个表中,测试数据还没有被拆分,接下来的三个数据表明,在将数据分成几行之后,需要的列数是多少。
| 设置 | 值 | 值 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|---|---|
| 默认标签 | 标签-1 | 标签-2 | 标签-3 | 标签-4 | 标签-5 | 标签-6 |
| 变量 | 值 | 值 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|---|---|
| @ {}清单 | 这个 | 名单 | 具有 | 相当 | 许多 | 项目 |
| 测试用例 | 行动 | 论据 | 精氨酸 | 精氨酸 | 精氨酸 | 精氨酸 | 精氨酸 | 精氨酸 |
|---|---|---|---|---|---|---|---|---|
| 例 | [文档] | 这个测试案例的文档。\ n这可能会相当长。 | ||||||
| [标签] | T-1 | T-2 | T-3 | T-4 | T-5 | |||
| 做X | 一 | 二 | 三 | 四 | 五 | 六 | ||
| $ {var} = | 得到X | 1 | 2 | 3 | 4 | 五 | 6 |
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 默认标签 | 标签-1 | 标签-2 | 标签-3 |
| ... | 标签-4 | 标签-5 | 标签-6 |
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| @ {}清单 | 这个 | 名单 | 具有 |
| ... | 相当 | 许多 | 项目 |
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | [文档] | 文档 | 为了这 | 测试用例。 |
| ... | 这可以得到 | 相当 | 长... | |
| [标签] | T-1 | T-2 | T-3 | |
| ... | T-4 | T-5 | ||
| 做X | 一 | 二 | 三 | |
| ... | 四 | 五 | 六 | |
| $ {var} = | 得到X | 1 | 2 | |
| ... | 3 | 4 | ||
| ... | 五 | 6 |
2.2创建测试用例
本节介绍整体测试用例语法。下一节将讨论使用测试用例文件和测试套件目录将测试用例组织到测试套件中的情况。
- 2.2.1测试用例语法
- 基本的语法
- 测试用例表中的设置
- “设置”表中的测试用例相关设置
- 2.2.2使用参数
- 强制性参数
- 默认值
- 可变数量的参数
- 命名的参数
- 免费的关键字参数
- 嵌入到关键字名称的参数
- 2.2.3失败
- 当测试用例失败时
- 错误消息
- 2.2.4测试用例名称和文档
- 2.2.5标记测试用例
- 2.2.6测试设置和拆卸
- 2.2.7测试模板
- 基本用法
- 嵌入参数的模板
- 带有for循环的模板
- 2.2.8不同的测试用例样式
- 关键字驱动的风格
- 数据驱动的风格
- 行为驱动的风格
2.2.1测试用例语法
基本的语法
测试用例在可用关键字的测试用例表中构建。关键字可以从测试库或资源文件中导入,也可以在测试用例文件本身的关键字表中创建。
测试用例表中的第一列包含测试用例名称。测试用例从该列中的某行开始,继续到下一个测试用例名称或表结尾。在表头和第一个测试之间有一些东西是错误的。
第二列通常有关键字名称。此规则的一个例外是,当关键字返回值设置变量时,第二个和可能的后续列包含变量名称,并且关键字名称位于后面。无论哪种情况,关键字名称后面的列都包含指定关键字的可能参数。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 有效登录 | 打开登录页面 | ||
| 输入名称 | 演示 | ||
| 输入密码 | 模式 | ||
| 提交证书 | |||
| 欢迎页面应该打开 | |||
| 设置变量 | 做一点事 | 第一个论点 | 第二个论据 |
| $ {value} = | 获得一些价值 | ||
| 应该是平等的 | $ {}值 | 期望值 |
测试用例表中的设置
测试用例也可以有自己的设置。设置名称始终位于第二列,通常是关键字,其值在后续列中。设置名称周围有方括号,以区别于关键字。下面列出了可用的设置,并在本节稍后进行介绍。
- [文档]
- 用于指定 测试用例文档。
- [标签]
- 用于 标记测试用例。
- [设置],[拆解]
- 指定 测试设置和拆卸。还分别有同义词 [Precondition]和[Postcondition]。
- [模板]
- 指定要使用的 模板关键字。测试本身将只包含用作该关键字参数的数据。
- [时间到]
- 用于设置 测试用例超时。 超时在他们自己的部分讨论。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 测试设置 | [文档] | 另一个虚拟测试 | |
| [标签] | 假 | 业主为johndoe | |
| 日志 | 你好,世界! |
2.2.2使用参数
前面的例子已经说明了不同论点的关键字,本节更深入地讨论了这个重要的功能。如何真正实现用不同参数的用户关键字和库关键字在不同的部分讨论。
关键字可以接受零个或多个参数,某些参数可能具有默认值。关键字接受哪些参数取决于其实现方式,通常搜索此信息的最佳位置是关键字的文档。在本节的示例中,文档预计将使用libdoc工具生成 ,但是相同的信息可用于通用文档工具(如javadoc)生成的文档。
强制性参数
大多数关键字都有一定数量的参数,必须始终给出。在关键字文档中,这是通过指定用逗号分隔的参数名来表示的first, second, third。在这种情况下,参数名称实际上并不重要,只是它们应该解释参数的作用,但具有与文档中指定的参数完全相同的参数是非常重要的。使用太少或太多的参数会导致错误。
下面的测试使用来自OperatingSystem库的关键字Create Directory和Copy File。他们的论点被指定为和,这意味着他们分别拿一个和两个参数。最后一个关键字,来自BuiltIn的No Operation, 不带任何参数。pathsource, destination
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 创建目录 | $ {TEMPDIR} /东东 | |
| 复制文件 | $ {} CURDIR /file.txt | $ {TEMPDIR} /东东 | |
| 没有操作 |
默认值
参数通常具有既可以给定也可以不给定的默认值。在文档中,默认值通常与参数名称用等号分隔name=default value,但是使用Java 实现的关键字可能会有 多个具有不同参数的相同关键字的实现。所有参数都可能有默认值,但是在带有默认值的参数后面不能有任何位置参数。
下面的示例使用默认值说明了使用 具有参数的“ 创建文件”关键字path, content=, encoding=UTF-8。试图使用它没有任何参数或超过三个参数将无法正常工作。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | 创建文件 | $ {TEMPDIR} /empty.txt | ||
| 创建文件 | $ {TEMPDIR} /utf-8.txt | Hyväesimerkki | ||
| 创建文件 | $ {TEMPDIR} /iso-8859-1.txt | Hyväesimerkki | ISO-8859-1 |
可变数量的参数
也可以创建接受任意数量参数的关键字。这些参数可以与强制参数和带有默认值的参数相结合,但所谓的可变参数总是最后一个参数。在文档中,它们通常在参数名称之前有一个星号*varargs,但是与Java库又有区别。
删除文件和加入路径下面的例子中使用的关键字分别具有参数*paths和base, *parts。前者可以与任意数量的参数一起使用,但后者至少需要一个参数。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | 删除文件 | $ {TEMPDIR} /f1.txt | $ {TEMPDIR} /f2.txt | $ {TEMPDIR} /f3.txt |
| @ {paths} = | 加入路径 | $ {TEMPDIR} | f1.txt | |
| ... | f2.txt | f3.txt | f4.txt |
命名的参数
命名的参数语法使得使用具有默认值的参数更加灵活,并且允许明确地标记某个参数值意味着什么。技术上命名的参数与Python中的关键字参数完全相同。
基本的语法
可以通过给参数赋予一个参数的名称前缀值来命名参数arg=value。当多个参数具有默认值时,这是特别有用的,因为可以仅命名一些参数并让其他人使用它们的默认值。例如,如果一个关键字接受参数arg1=a, arg2=b, arg3=c,并用一个参数arg3=override,参数调用 arg1并arg2获取它们的默认值,但arg3 获得值override。如果这听起来很复杂,下面的命名参数示例有希望使其更清楚。
命名的参数语法既是大小写又是空格敏感的。前者意味着,如果你有一个论点arg,你必须使用它 arg=value,既不,Arg=value也不ARG=value 工作。后者意味着在= 符号之前不允许有空格,并且之后可能的空格被认为是给定值的一部分。
当命名参数语法与用户关键字一起使用时,参数名称必须在没有${}装饰的情况下给出。例如,${arg1}=first, ${arg2}=second必须使用带有参数的用户关键字arg2=override。
例如,在命名参数之后使用普通的位置参数 | Keyword | arg=value | positional |不起作用。从Robot Framework 2.8开始,这会导致一个明显的错误。命名参数的相对顺序无关紧要。
注意
在Robot Framework 2.8之前,不能命名没有默认值的参数。
用变量命名参数
可以在两个命名的参数名称和值中使用变量。如果该值是单个标量变量,则将其按原样传递给关键字。这允许在使用命名参数语法时使用任何对象(不仅是字符串)作为值。例如,调用类似的关键字arg=${object} 会将变量传递${object}给关键字,而不会将其转换为字符串。
如果在命名参数名称中使用变量,则在将变量与参数名称进行匹配之前先解析变量。这是Robot Framework 2.8.6中的一个新功能。
命名的参数语法要求在关键字调用中直接写入等号。这意味着如果一个变量具有类似的值foo=bar,它永远不会触发命名的参数语法。当把关键字包装到其他关键字中时,这一点很重要。例如,如果一个关键字采用可变数量的参数,@{args} 并且使用相同的@{args}语法将其全部传递给另一个关键字,则这些值不会被识别为named。看下面的例子:
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 包装纸 | 壳=真 | #这不会作为启动进程的命名参数 |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 包装纸 | [参数] | @ {} ARGS | ||
| 启动过程 | MyProcess | @ {} ARGS | #命名参数不能从@ {args}中识别 |
转义命名参数语法
命名的参数语法仅在等号前的参数部分与关键字参数之一匹配时使用。可能有一个类似于字面值的位置参数foo=quux,还有一个与名称无关的参数foo。在这种情况下,参数 foo要么不正确地获取值,quux要么更可能是语法错误。
在偶然匹配的情况下,可以使用反斜杠字符来转义语法foo\=quux。现在参数将会得到一个字面的值foo=quux。请注意,如果没有名称参数,则不需要转义foo,但是由于它使情况更加明确,所以它可能是个好主意。
支持命名参数的地方
正如已经解释的那样,命名参数语法与关键字一起工作 除此之外,在使用测试库时,它也可以工作。
命名参数由用户关键字和大多数测试库支持。唯一的例外是使用静态库API的基于Java的库。使用Libdoc生成的库文档有一个注释,库是否支持命名参数。
注意
在Robot Framework 2.8之前,命名参数语法不适用于使用动态库API的测试库。
命名参数的例子
以下示例演示如何使用带有库关键字,用户关键字和导入Telnet测试库的命名参数语法。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | 远程登录 | 提示= $ | default_log_level = DEBUG |
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | 打开连接 | 10.0.0.42 | 端口= $(港口) | 别名=示例 |
| 列出文件 | 选项= -lh | |||
| 列出文件 | 路径= / TMP | 选项= -l |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 列出文件 | [参数] | $ {PATH} =。 | $ {}选项= | |
| 执行命令 | ls $ {options} $ {path} |
免费的关键字参数
Robot Framework 2.8增加了对Python风格的免费关键字参数 (**kwargs)的支持。这意味着关键字可以在使用name=value语法的关键字调用结束时接收所有参数,并且不会与任何其他参数(如kwargs)匹配。
免费的关键字参数支持变量类似于命名参数。在实践中,这意味着变量既可以在名称中使用,也可以在值中使用,但是转义符必须始终可以从字面上看到。例如,这两个foo=${bar}和${foo}=${bar}是有效的,只要所使用的变量存在。一个额外的限制是免费的关键字参数名称必须始终是字符串。对名称中的变量的支持是Robot Framework 2.8.6中的一个新功能,在此之前,可能的变量未被解决。
最初的free关键字参数只适用于基于Python的库,但Robot Framework 2.8.2扩展了对动态库API的支持 ,Robot Framework 2.8.3将其进一步扩展到基于Java的库和远程库接口。换句话说,现在所有的图书馆都支持kwargs。不幸的是用户关键字不支持他们,但是这个支持是为 Robot Framework 2.9而设计的。
有关使用kwargs的真实案例,我们来看看 Process Library 中的Run Process关键字。它有一个签名 ,这意味着它执行该命令,将其参数作为可变数量的参数,最后是可选的配置参数作为自由关键字参数 。command, *arguments, **configuration**configuration
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 论据 |
|---|---|---|---|---|---|
| 使用Kwargs | 运行进程 | COMMAND.EXE | ARG1 | ARG2 | CWD = / home / user的 |
| 运行进程 | COMMAND.EXE | 论据 | 壳=真 | ENV = $ {} ENVIRON |
如上例所示,使用带有free关键字参数的变量与使用命名参数语法完全相同。
有关在自定义测试库中使用kwargs语法的更多信息,请参阅创建测试库下的免费关键字参数(** kwargs)部分。
嵌入到关键字名称的参数
指定参数的完全不同的方法是将它们嵌入到关键字名称中。至少目前这个语法只支持用户关键字。
2.2.3失败
当测试用例失败时
如果任何关键字使用失败,则测试用例将失败。通常这意味着停止执行该测试用例,执行可能的测试拆卸,然后继续执行下一个测试用例。如果不希望停止测试执行,也可以使用特殊的可连续性故障。
错误消息
分配给失败测试用例的错误消息直接来自失败的关键字。错误信息通常是由关键字本身创建的,但有些关键字允许配置它们。
在某些情况下,例如,当使用可连续性故障时,测试用例可能会多次失败。在这种情况下,最终的错误信息是通过组合单个错误得到的。非常长的错误信息会自动从中间删除,使报告更易于阅读。完整的错误消息始终在日志文件中显示为关键字失败的消息。
默认情况下,错误消息是普通文本,但是从Robot Framework 2.8开始,它们可以包含HTML格式。这是通过使用标记字符串启动错误消息来启用的*HTML*。此标记将从报告和日志中显示的最终错误消息中删除。在下面的第二个示例中显示了在自定义消息中使用HTML。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 正常错误 | 失败 | 这是一个相当无聊的例子 | ||
| HTML错误 | $ {数} = | 获取号码 | ||
| 应该是平等的 | $ {}号 | 42 | * HTML *号码不是我的 MAGIC 号码。 |
2.2.4测试用例名称和文档
测试用例名直接来自测试用例表:它正是输入到测试用例列中的内容。一个测试套件中的测试用例应该有唯一的名称。与此相关,您也可以使用测试中的自动变量 ${TEST_NAME}来引用测试名称。无论何时执行测试,包括所有用户关键字,以及测试设置和测试拆卸都可用。
在[文件]设置,可以设置为测试条件下自由文档。该文本显示在命令行输出中,以及生成的测试日志和测试报告。
如果文档很长,可以将其分成几个 与空格连接的单元格。可以使用简单的 HTML格式,并且可以使用变量来使文档动态化。从Robot Framework 2.7开始,如果文档被分成多行,那么这些行本身就是使用换行符来 链接的。如果换行符已经以换行符结尾或换行符以反斜杠结尾,则不添加换行符。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 简单 | [文档] | 简单的文档 | |
| 没有操作 | |||
| 拆分 | [文档] | 这个文档有点长, | 它已被分成几列。 |
| 没有操作 | |||
| 很多线路 | [文档] | 在这里,我们有 | |
| ... | 一个自动换行符 | ||
| 没有操作 | |||
| 格式化 | [文档] | *这是大胆的*,_这是斜体和 | 这里是一个链接:http://robotframework.org |
| 没有操作 | |||
| 变量 | [文档] | 由$ {USER}在$ {HOST}处执行 | |
| 没有操作 |
测试用例具有清晰的描述性名称是非常重要的,在这种情况下,通常不需要任何文档。如果测试用例的逻辑需要记录,那么测试用例中的关键字通常需要更好的名称,并且需要增强,而不是添加额外的文档。最后,元数据(如上面最后一个例子中的环境和用户信息)通常可以更好地使用标签来指定。
2.2.5标记测试用例
在Robot Framework中使用标签是一种简单而强大的测试用例分类机制。标签是自由文本,至少可以用于以下目的:
- 标签显示在测试报告,日志中,当然还有测试数据中,所以它们为测试用例提供元数据。
- 关于测试用例的统计(总计,通过,失败是根据标签自动收集的)。
- 使用标签,您可以包含或排除要执行的测试用例。
- 使用标签,您可以指定哪些测试用例被认为是关键的。
在本节中,仅解释如何为测试用例设置标签,下面列出了不同的方法。这些方法自然可以一起使用。
- 强制设置表中的标签
-
测试用例文件中的所有测试用例总是使用此设置获取指定的标记。如果
test suite initialization file在子测试套件中使用,则所有的测试用例都会得到这些标签。 - 设置表中的默认标签
- 没有自己的[标签]设置的测试用例获取这些标签。从Robot Framework版本2.5开始,测试套件初始化文件不再支持默认标签。
- 测试用例表中的[标签]
-
测试用例总是获取这些标签。此外,它不会获得使用默认标签指定的可能标签,因此可以使用空值来覆盖默认标签。从Robot Framework 2.5.6开始,也可以使用值
NONE来覆盖默认标签。 - --settag命令行选项
- 所有执行的测试用例除了他们在其他地方获得的标签外,还获得使用此选项设置
- 设置标签,移除标签,失败和传递执行关键字
- 这些 BuiltIn关键字可用于在测试执行期间动态地操作标签。
标签是自由文本,但它们被标准化,以便它们被转换成小写字母,并且所有的空格都被删除。如果测试用例多次获取相同的标签,则除第一个以外的其他事件将被删除。假设这些变量存在,可以使用变量创建标签。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 强制标签 | REQ-42 | ||
| 默认标签 | 主人约翰 | 抽烟 |
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| $ {HOST} | 10.0.1.42 |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 没有自己的标签 | [文档] | 这个测试有标签 | 老板约翰,烟,需要-42 |
| 没有操作 | |||
| 用自己的标签 | [文档] | 这个测试有标签 | 不要,已经所有者的MRR,REQ-42 |
| [标签] | 业主MRX | 没有准备好 | |
| 没有操作 | |||
| 自己的标签与变量 | [文档] | 这个测试有标签 | host-10.0.1.42,req-42 |
| [标签] | 主机 - $ {HOST} | ||
| 没有操作 | |||
| 清空自己的标签 | [文档] | 这个测试有标签 | REQ-42 |
| [标签] | |||
| 没有操作 | |||
| 设置标签和删除标签关键字 | [文档] | 这个测试有标签 | mytag,老板约翰 |
| 设置标签 | mytag | ||
| 删除标签 | 抽烟 | req- * |
2.2.6测试设置和拆卸
Robot Framework与许多其他测试自动化框架具有相似的测试设置和拆卸功能。简而言之,测试设置是在测试用例之前执行的,在测试用例之后执行测试拆卸。在Robot Framework中,设置和拆卸只是普通的可能参数的关键字。
安装和拆卸总是一个关键字。如果他们需要处理多个单独的任务,则可以为此创建更高级别的用户关键字。另一种解决方案是使用Robot Framework 2.5中添加的BuiltIn关键字运行关键字来执行多个关键字。
测试拆解在两个方面是特殊的。首先,它也在测试用例失败时执行,因此可以用于清理活动,而不管测试用例的状态如何。从Robot Framework 2.5开始,即使其中一个失败,也将执行拆解中的所有关键字。这 继续失败功能也可以使用正常的关键字,但内部拆解它默认情况下。
在测试用例文件中为测试用例指定设置或拆卸的最简单方法是使用设置表中的测试设置和测试拆卸设置。个别测试用例也可以有自己的设置或拆卸。它们通过测试用例表中的[Setup]或[Teardown]设置进行定义, 它们覆盖可能的测试设置和 测试拆解设置。在[Setup]或[Teardown]设置后没有关键字 意味着没有设置或拆卸。从Robot Framework 2.5.6开始,还可以使用value NONE来指示测试没有设置/拆卸。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 测试设置 | 打开应用程序 | 应用程序A | |
| 测试拆解 | 关闭应用程序 |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 默认值 | [文档] | 安装和拆卸 | 从设置表 |
| 做一点事 | |||
| 重写的设置 | [文档] | 自己的设置,拆解 | 从设置表 |
| [建立] | 打开应用程序 | 应用程序B | |
| 做一点事 | |||
| 没有拆卸 | [文档] | 默认设置,不 | 彻底拆解 |
| 做一点事 | |||
| [拆除] | |||
| 没有拆卸2 | [文档] | 使用特殊的NONE, | 与2.5.6一起工作 |
| 做一点事 | |||
| [拆除] | 没有 | ||
| 使用变量 | [文档] | 安装和拆卸 | 作为变量给出 |
| [建立] | $ {设置} | ||
| 做一点事 | |||
| [拆除] | $ {} TEARDOWN |
通常当创建类似用例的测试用例时,术语先决条件 和后置条件优于术语设置和拆卸。机器人框架也支持这个术语,所以前提条件是设置和拆卸的后置条件的同义词。
| 测试设置 | 测试前提条件 |
| 测试拆解 | 测试后置条件 |
| [建立] | [前提] |
| [拆除] | [后置条件] |
要作为设置或拆卸执行的关键字的名称可以是变量。这有助于在不同的环境中通过将命令行中的关键字名称作为变量来进行不同的设置或拆卸。
注意
测试套件可以有自己的设置和拆卸。套件设置在该测试套件中的任何测试用例或子测试套件之前执行,类似地,套件拆除将在其后执行。
2.2.7测试模板
测试模板将普通的关键字驱动的测试用例转换为 数据驱动的测试。而关键字驱动测试用例的主体是由关键字及其可能的参数构成的,而带有模板的测试用例只包含template关键字的参数。不是每个测试和/或文件中的所有测试多次重复相同的关键字,而是可以仅在每个测试中使用它,或者每个文件只使用一次。
模板关键字可以接受正常的位置参数和命名参数,也可以接受嵌入到关键字名称的参数。与其他设置不同,使用变量定义模板是不可能的。
基本用法
以下示例测试用例说明了如何将可接受正常位置参数的关键字用作模板。这两个测试在功能上完全相同。
*** 测试用例 **正常的测试用例 关键字第一个参数的第二个参数 模板化测试用例 [ Template ] 示例关键字 第一个参数第二个参数
如示例所示,可以使用[模板] 设置为单个测试用例指定模板。另一种方法是使用“ 设置”表中的“ 测试模板 ”设置,在这种情况下,模板将应用于该测试用例文件中的所有测试用例。的[模板] 设置覆盖可能模板在设定表中设定,并为一个空值[模板]表示试验没有模板即使当测试模板被使用。从Robot Framework 2.5.6开始,也可以使用value NONE来指示一个测试没有模板。
如果模板化的测试用例在其正文中有多个数据行,则将逐个应用所有行的模板。这意味着多次执行相同的关键字,每行一次的数据。模板化测试也是非常特殊的,即使其中一个或多个失败,也执行所有的测试。也可以使用这种继续正常测试的失败模式,而用模板测试模式自动开启。
***设置***测试模板示例关键字 *** 测试用例 ***模板化测试用例 首轮第一轮第一轮2 第二轮1 轮第二轮2 第三轮1 轮第三轮2
使用默认值或可变参数的参数,以及使用 命名参数和免费的关键字参数,使用模板完全一样,否则工作。在参数中使用变量也是正常的。
嵌入参数的模板
从Robot Framework 2.8.2开始,模板支持嵌入式参数语法的变体。使用模板时,此语法的工作原理是,如果template关键字的名称中包含变量,则它们被视为参数的占位符,并替换为与模板一起使用的实际参数。然后使用生成的关键字,而不使用位置参数。举一个例子来说明:
*** 测试用例 ***具有嵌入参数的正常测试用例 1 + 1的结果应该是2 1 + 2的结果应该是3嵌入参数的模板 [ Template ] $ { calculation } 的结果应该是$ { expected } 1 + 1 2 1 + 2 3 ***关键词***$ { calculation } 的结果应该是$ { expected } $ { result } = Calculate $ { calculation } 应该相等 $ { result } $ { expected }
嵌入式参数与模板一起使用时,模板关键字名称中的参数数量必须与使用的参数数量相匹配。参数名称不需要匹配原始关键字的参数,但也可以使用不同的参数:
*** 测试用例 ***不同的参数名称 [ Template ] $ { foo } 的结果应该是$ { bar } 1 + 1 2 1 + 2 3 只有一些论据 [ 模板] $ { calculation } 的结果应该是3 1 + 2 4 - 1新的论点 [ 模板] 的$ { 意思} 的$ { 生命} 应该是42 结果21 * 2
嵌入参数与模板一起使用的主要好处是参数名称是明确指定的。使用普通参数时,通过命名包含参数的列可以达到同样的效果。这由下一节中的数据驱动样式示例来说明。
带有for循环的模板
如果模板与for循环一起使用,则模板将应用于循环内的所有步骤。在这种情况下,继续失败模式也被使用,这意味着,即使在失败的情况下,所有的步骤也是以所有的循环元素执行的。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 模板和 | [模板] | 示例关键字 | ||
| :对于 | $ {}项 | 在 | @ {} ITEMS | |
| $ {}项 | 第二个arg | |||
| :对于 | $ {}指数 | 在范围内 | 42 | |
| 第一arg | $ {}指数 |
2.2.8不同的测试用例样式
测试用例可以有几种不同的写法。描述某种工作流的测试用例可以用关键字驱动或行为驱动的风格来编写。数据驱动风格可用于测试具有不同输入数据的相同工作流程。
关键字驱动的风格
工作流程测试(如前面描述的有效登录测试) 是由几个关键字及其可能的参数构成的。他们的正常结构是,首先系统进入初始状态(在有效登录示例中打开登录页面),然后对系统进行一些操作(输入名称,输入密码,提交证书),最后验证系统表现如预期(欢迎页面应该打开)。
数据驱动的风格
编写测试用例的另一种风格是数据驱动的方法,其中测试用例只使用一个更高级别的关键字,通常创建为 用户关键字,隐藏实际的测试工作流程。当需要使用不同的输入和/或输出数据测试相同的场景时,这些测试非常有用。每次测试都可以重复相同的关键字,但测试模板功能允许指定关键字只使用一次。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 测试模板 | 用无效凭证登录应该失败 |
| 测试用例 | 用户名 | 密码 | |
|---|---|---|---|
| 无效的用户名 | 无效 | $ {VALID PASSWORD} | |
| 无效的密码 | $ {有效的用户} | 无效 | |
| 无效的用户名和密码 | 无效 | 随你 | |
| 空的用户名 | $ {EMPTY} | $ {VALID PASSWORD} | |
| 空密码 | $ {有效的用户} | $ {EMPTY} | |
| 空的用户名和密码 | $ {EMPTY} | $ {EMPTY} |
上面的例子有六个单独的测试,每一个对于每个无效的用户/密码组合,下面的例子说明了如何只有一个测试与所有的组合。当使用测试模板时,即使出现故障,也会执行测试中的所有回合,所以这两种样式之间没有实际的功能差异。在上面的例子中,单独的组合被命名,所以更容易看到他们测试什么,但是可能大量的这些测试可能会弄乱统计数据。使用哪种风格取决于上下文和个人喜好。
| 测试用例 | 用户名 | 密码 | |
|---|---|---|---|
| 无效的密码 | [模板] | 用无效凭证登录应该失败 | |
| 无效 | $ {VALID PASSWORD} | ||
| $ {有效的用户} | 无效 | ||
| 无效 | 随你 | ||
| $ {EMPTY} | $ {VALID PASSWORD} | ||
| $ {有效的用户} | $ {EMPTY} | ||
| $ {EMPTY} | $ {EMPTY} |
小费
在上面的两个例子中,列标题已被更改为与数据匹配。这是可能的,因为在第一行,除了第一个单元之外的其他单元被忽略。
行为驱动的风格
也可以编写测试用例作为非技术项目利益相关者必须理解的需求。这些可执行要求是通常称为验收测试驱动开发 (ATDD)或示例说明的过程的基石。
编写这些需求/测试的一种方式是由行为驱动开发(BDD)推广的Given-When-Then风格。当以这种风格编写测试用例时,初始状态通常用一个以Given开始的关键字来表示,这些动作被描述为关键字以 When开头,关键字以Then开头的期望。如果某个步骤有多个操作,则可以使用以And开头的关键字。
| 测试用例 | 步 |
|---|---|
| 有效登录 | 鉴于登录页面已打开 |
| 当有效的用户名和密码被插入时 | |
| 并提交证书 | |
| 那么欢迎页面应该打开 |
忽略Given / When / Then /和前缀
前缀考虑,当,然后和而被当匹配关键字进行搜索,如果没有与之相匹配的全名被发现丢弃。这适用于用户关键字和库关键字。例如,在上面的例子中, 给定的登录页面是打开的,可以使用或不使用单词Given来实现为用户关键字。忽略前缀还允许使用具有不同前缀的相同关键字。例如 欢迎页面应该打开也可以用作和欢迎页面应该打开。
将数据嵌入关键字
在编写具体示例时,将实际数据传递给关键字实现是有用的。用户关键字通过允许将参数嵌入关键字名称来支持这一点。
2.3创建测试套件
Robot Framework测试用例是在测试用例文件中创建的,可以将其组织到目录中。这些文件和目录创建一个分层测试套件结构。
- 2.3.1测试用例文件
- 2.3.2测试套件目录
- 警告无效的文件
- 初始化文件
- 2.3.3测试套件名称和文档
- 2.3.4免费测试套件元数据
- 2.3.5套件安装和拆卸
2.3.1测试用例文件
Robot Framework测试用例是使用测试用例文件中的测试用例表创建的。这样的文件自动从它包含的所有测试用例中创建一个测试套件。有多少测试用例没有上限,但建议少于十个,除非使用数据驱动的方法,一个测试用例只包含一个高级关键字。
设置表中的以下设置可用于自定义测试套件:
- 文档
- 用于指定 测试套件文档
- 元数据
- 用于将 免费测试套件元数据设置为名称 - 值对。
- 套房设置,套房拆解
- 指定 套件设置和拆卸。还分别具有同义词 Suite Precondition和Suite Postcondition。
注意
所有设置名称可以任选地包括在所述端部的结肠,例如文档:。这可以使读取设置更容易,特别是在使用纯文本格式时。这是Robot Framework 2.5.5中的一个新功能。
2.3.2测试套件目录
测试用例文件可以组织到目录中,这些目录创建更高级别的测试套件。从目录创建的测试套件不能直接提供任何测试用例,但是它包含其他测试用例,而不是测试用例。这些目录然后可以被放置到其他目录创建一个更高层次的套件。结构没有限制,所以可以根据需要组织测试用例。
当执行一个测试目录时,它所包含的文件和目录将按照如下递归的方式处理:
- 名称以点(。)或下划线(_)开头的文件和目录将被忽略。
- 名称为CVS的目录被忽略(区分大小写)。
- 没有识别扩展名(.html, .xhtml,.htm,.tsv,.txt,.rst或.rest)的文件被忽略(不区分大小写)。
- 其他文件和目录被处理。
如果处理的文件或目录不包含任何测试用例,则将其忽略(将消息写入syslog),并继续处理。
警告无效的文件
通常情况下,没有有效的测试用例表的文件会被写入syslog的消息忽略。从Robot Framework 2.5.5开始,可以使用命令行选项--warnonskippedfiles,将消息转变为测试执行错误中显示的警告。
初始化文件
从目录创建的测试套件可以具有与从测试用例文件创建的套件类似的设置。因为单独的一个目录不能有这样的信息,所以它必须放在一个特殊的测试套件初始化文件中。初始化文件与测试用例文件具有相同的结构和语法,只是它们不能包含测试用例表,并且不支持所有的设置。
初始化文件名必须始终为格式__init __。ext,其中扩展名必须匹配其中一种受支持的文件格式(例如, __init __。html或__init __。txt)。名称格式是从Python借用的,以这种方式命名的文件表示目录是一个模块。
初始化文件的主要用法是指定与测试用例文件类似的测试套件相关设置,但也可以设置一些测试用例相关的设置。初始化文件中创建或导入的变量和关键字在较低级别的测试套件中不可用,但是如果需要共享资源文件,则可以使用资源文件。
如何在初始化文件中使用不同的设置:
- 文档,元数据,套件设置,套件拆解
- 这些测试套件的具体设置与测试用例文件中的相同。
- 强制标签
- 指定的标签无条件地设置为该目录直接或递归包含的所有测试用例文件中的所有测试用例。
- 测试设置,测试拆解,测试超时
- 将测试设置/拆卸的默认值或测试超时设置为此目录包含的所有测试用例。可以在较低级别上被覆盖。在Robot Framework 2.7中添加了在初始化文件中定义测试超时的支持。
- 默认标签,测试模板
- 在初始化文件中不受支持。
| 设置 | 值 | 值 |
|---|---|---|
| 文档 | 示例套件 | |
| 套件设置 | 做一点事 | $ {文} |
| 强制标签 | 例 | |
| 图书馆 | SomeLibrary |
| 变量 | 值 | 值 |
|---|---|---|
| $ {文} | 你好,世界! |
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 做一点事 | [参数] | $ {} ARG | |
| 一些关键字 | $ {} ARG | ||
| 另一个关键字 |
2.3.3测试套件名称和文档
测试套件名称由文件或目录名称构成。名称被创建以便扩展被忽略,可能的下划线被空格替换,并且名字完全以小写字母为标题。例如,some_tests.html变成了一些测试,而 My_test_directory变成了我的测试目录。
注意
Robot Framework 2.5中创建测试套件名称的规则稍有变化。
文件或目录名称可以包含一个前缀来控制套件的执行顺序。前缀与基本名称分开两个下划线,在构造实际测试套件名称时,前缀和下划线都将被删除。例如文件 01__some_tests.txt和02__more_tests.txt创建测试套件的一些测试和更多的测试,分别与前者在后者之前执行。
测试套件的文档使用 “设置”表中的“ 文档”设置进行设置。它可以在测试用例文件中使用,或者在更高级别的套件中用在测试套件初始化文件中。测试套件文档具有与显示位置完全相同的特征以及如何将其作为测试用例文档创建。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 文档 | 一个示例测试套件 | 文档与 | *一些* _formatting_。 |
| ... | 见测试文档 | 获取更多文档 | 例子。 |
测试执行中可以覆盖顶级测试套件的名称和文档。这可以分别使用命令行选项--name和 - doc来完成,如设置元数据一节中所述。
2.3.4免费测试套件元数据
测试套件也可以具有除文档之外的其他元数据。此元数据是使用“ 元数据”设置在“设置”表中定义的。以这种方式设置的元数据显示在测试报告和日志中。
对元数据的名称和值位于下面的列 元数据。该值的处理方式与文档相似,也就是说可以将其分割为多个单元格(用空格连接)或多行(用换行符连接在一起),可以使用简单的HTML格式化工作,甚至可以使用变量。
| 设置 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|
| 元数据 | 版 | 2.0 | ||
| 元数据 | 更多信息 | 了解更多信息 | 关于* Robot Framework * | 请参阅http://robotframework.org |
| 元数据 | 执行在 | $ {HOST} |
对于顶级测试套件,也可以使用--metadata命令行选项设置元数据 。这将在“ 设置元数据”一节中更详细地讨论。
在Robot Framework 2.5之前,免费的元数据是用Meta:
2.3.5套件安装和拆卸
不仅测试用例而且测试套件都可以进行设置和拆卸。套件安装程序在运行套件的任何测试用例或子测试套件之前执行,并在其后执行测试拆卸。所有的测试套件都可以进行设置和拆卸; 从目录创建的套件必须在测试套件初始化文件中指定。
与测试用例类似,套件设置和拆卸是可能需要参数的关键字。它们分别在套件设置和套件拆卸设置的设置表中定义 。他们也有类似的同义词,套件先决条件和套件后置条件,作为测试案例的设置和拆解。关键字名称和可能的参数位于设置名称后面的列中。
如果套件设置失败,则其中的所有测试用例及其子测试套件将立即分配为失败状态,并且不会实际执行。这使得套件设置非常适合检查在运行测试用例之前必须满足的前提条件。
所有测试用例执行完毕后,通常会使用套件拆卸进行清理。即使同一套件的设置失败,也会执行该操作。如果套件拆卸失败,套件中的所有测试用例都被标记为失败,无论其原始执行状态如何。从Robot Framework 2.5开始,所有在teardowns中的关键字都会被执行,即使其中一个失败。
要作为设置或拆卸执行的关键字的名称可以是变量。这有助于在不同的环境中通过将命令行中的关键字名称作为变量来进行不同的设置或拆卸。
2.4使用测试库
测试库包含最低级别的关键字,通常称为 库关键字,它们实际上与被测系统进行交互。所有的测试用例总是使用某些库中的关键字,通常是通过更高级别的用户关键字。本节介绍如何使用测试库以及如何使用它们提供的关键字。创建测试库将在一个单独的章节中介绍。
- 2.4.1使用测试库
- 使用库设置
- 使用导入库关键字
- 库搜索路径
- 使用物理路径来图书馆
- 2.4.2设置自定义名称为测试库
- 2.4.3标准库
- 正常的标准库
- 远程库
- 2.4.4外部库
2.4.1使用测试库
使用测试库的说明在下面的小节中给出。
使用库设置
测试库通常使用“ 设置”表中的“ 库”设置导入,并在后续列中具有库名称。库名称区分大小写(它是实现库的模块或类的名称,必须完全正确),但其中的任何空格都将被忽略。使用包中的模块或Java库中的Python库时,必须使用包括模块或包名称的全名。
在库需要参数的情况下,它们在库名后面的列中列出。可以在测试库导入中使用默认值,可变数量的参数和命名参数,与使用关键字的参数类似。库名称和参数都可以使用变量进行设置。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | 操作系统 | ||
| 图书馆 | com.company.TestLib | ||
| 图书馆 | 我的图书馆 | ARG1 | ARG2 |
| 图书馆 | $ {}库 |
可以在测试用例文件, 资源文件和测试套件初始化文件中导入测试库。在所有这些情况下,导入库中的所有关键字都可以在该文件中使用。对于资源文件,这些关键字也可以在其他使用它们的文件中使用。
使用导入库关键字
采取测试库投入使用另一种可能性是使用关键字导入库从内建库。该关键字与库设置类似,使用库名称和可能的参数 。导入库中的关键字在使用Import Library关键字的测试套件中可用。这种方法在测试执行开始时库不可用的情况下非常有用,只有其他一些关键字可用。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | 做一点事 | |||
| 导入库 | 我的图书馆 | ARG1 | ARG2 | |
| KW从Mylibrary |
库搜索路径
指定要导入的测试库最常用的方法是使用其名称,就像本节所有示例中所做的那样。在这些情况下,Robot Framework会尝试从库搜索路径中查找实现库的类或模块。基本上,这意味着库代码及其所有可能的依赖关系必须在PYTHONPATH中,或者在Jython上运行测试时在 CLASSPATH中。设置库搜索路径在其自己的一节中进行解释。库也可以自动设置搜索路径,或者有特别的说明。例如,所有 标准库都自动在库搜索路径中。
这种方法的最大好处是,当库搜索路径被配置时,通常使用自定义的启动脚本,普通用户不需要考虑库的实际安装位置。缺点是将自己的,可能非常简单的库放到搜索路径中可能需要一些额外的配置。
使用物理路径来图书馆
指定要导入的库的另一种机制是在文件系统中使用它的路径。该路径被认为是相对于当前测试数据文件所在的目录相似于到资源和变量文件的路径。这种方法的主要优点是不需要配置库搜索路径。
如果库是一个文件,它的路径必须包含扩展名。对于Python库,扩展名自然是.py,对于Java库,扩展名可以是.class或.java,但类文件必须始终可用。如果Python库被实现为目录,则其路径必须有一个尾随正斜杠(/)。以下示例演示了这些不同的用法。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | PythonLib.py | ||
| 图书馆 | /absolute/path/JavaLib.java | ||
| 图书馆 | 相对/路径/ PythonDirLib / | 可能 | 参数 |
| 图书馆 | $ {}资源/Example.class |
这种方法的局限性在于,作为Python类实现的库必须位于与类相同名称的模块中。此外,使用此机制导入以JAR或ZIP包分发的库是不可能的。
2.4.2设置自定义名称为测试库
库名称显示在关键字名称之前的测试日志中,如果多个关键字具有相同的名称,则必须使用它们以使 关键字名称以库名称作为前缀。库名通常是从实现它的模块或类名得到的,但是在某些情况下,更改它是可取的:
- 需要用不同的参数多次导入同一个库。否则这是不可能的。
- 图书馆的名字很不方便。例如,如果Java库具有很长的包名称,就可能发生这种情况。
- 您希望使用变量在不同的环境中导入不同的库,但使用相同的名称引用它们。
- 图书馆名称有误导性或其他差。在这种情况下,更改实际名称当然是更好的解决方案。
用于指定新名称的基本语法是WITH NAME在库名后面加上文本 (不区分大小写),然后在下一个单元格中输入新名称。指定的名称显示在日志中,使用关键字的全名(LibraryName.Keyword名称)时,必须在测试数据中使用。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | com.company.TestLib | 与姓名 | TESTLIB |
| 图书馆 | $ {}库 | 与姓名 | 我的名字 |
库的可能参数被放置在原始库名称和WITH NAME文本之间的单元格中。以下示例说明了如何使用不同的参数多次导入同一个库:
| 设置 | 值 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|---|
| 图书馆 | SomeLibrary | 本地主机 | 1234 | 与姓名 | LocalLib |
| 图书馆 | SomeLibrary | server.domain | 8080 | 与姓名 | RemoteLib |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 我的测试 | LocalLib.Some关键字 | 一些arg | 第二个arg |
| RemoteLib.Some关键字 | 另一个arg | 随你 | |
| LocalLib.Another关键字 |
将自定义名称设置为测试库时,在导入“设置”表中的库时以及使用“ 导入库”关键字时都会起作用。
2.4.3标准库
一些测试库是通过Robot Framework分发的,这些库被称为标准库。该内建库是特殊的,因为它会自动投入使用,因此它的关键字总是可用的。其他标准库需要以与其他库相同的方式导入,但是不需要安装它们。
正常的标准库
下面列出了可用的常规标准库,并链接到他们的文档:
- 内建
- 集合
- 约会时间
- 对话框
- 操作系统
- 处理
- 截图
- 串
- 远程登录
- XML
远程库
除上面列出的常规标准库外,还有与其他标准库完全不同的远程库。它没有任何自己的关键字,但它作为Robot Framework和实际测试库实现之间的代理。这些库可以在核心框架以外的其他机器上运行,甚至可以使用Robot Framework本身不支持的语言来实现。
有关此概念的更多信息,请参阅单独的远程库接口部分。
2.4.4外部库
根据定义,任何不是标准库之一的测试库都是外部库。Robot Framework开源社区已经实现了几个通用库,比如Selenium2Library和SwingLibrary,这些库并 没有与核心框架一起打包。可以从http://robotframework.org找到公开可用的库列表。
通用和自定义库显然也可以由使用Robot Framework的团队来实现。有关该主题的更多信息,请参阅创建测试库部分。
不同的外部库可以有完全不同的机制来安装并使用它们。有时他们可能还需要另外安装一些依赖项。所有库应该有清楚的安装和使用文档,他们应该最好自动化安装过程。
2.5变量
- 2.5.1简介
- 2.5.2变量类型
- 标量变量
- 列出变量
- 使用列表变量作为标量
- 使用标量变量作为列表
- 环境变量
- Java系统属性
- 2.5.3创建变量
- 变量表
- 变量文件
- 在命令行中设置变量
- 从关键字返回值
- 使用设置测试/套件/全局变量关键字
- 2.5.4内置变量
- 操作系统变量
- 数字变量
- 布尔值和无/空变量
- 空间和空变量
- 自动变量
- 2.5.5变量优先级和范围
- 变量优先
- 变量范围
- 2.5.6高级变量功能
- 扩展的变量语法
- 扩展变量赋值
- 变量内部的变量
2.5.1简介
变量是Robot Framework的一个完整功能,可以在测试数据的大部分地方使用。通常,它们用于测试用例表和关键字表中关键字的参数,而且所有设置都允许其值中的变量。一个正常的关键字名称不能用变量指定,但是可以使用BuiltIn关键字 Run关键字来获得相同的效果。
Robot Framework本身有两种变量,标量和列表,它们分别具有语法${SCALAR}和语法@{LIST}。除此之外,环境变量可以直接与语法结合使用%{VARIABLE}。
在以下情况下建议使用变量:
- 当字符串在测试数据中经常变化时。使用变量只需要在一个地方进行这些更改。
- 创建独立于系统和独立于操作系统的测试数据时。使用变量而不是硬编码的字符串可以大大简化(例如,
${RESOURCES}而不是c:\resources或${HOST}不是10.0.0.1:8080)。因为变量可以在开始测试时从命令行设置,所以更改系统特定变量很容易(例如--variable HOST:10.0.0.2:1234 --variable RESOURCES:/opt/resources)。这也有利于本地化测试,这通常涉及使用不同的字符串运行相同的测试。 - 当需要将字符串以外的对象作为关键字的参数时。
- 当不同的关键字,即使在不同的测试库中,也需要进行通信。您可以将一个关键字的返回值分配给一个变量,并将其作为参数分配给另一个变量。
- 当测试数据中的值长或其他复杂时。比如,
${URL}比...更短http://long.domain.name:8080/path/to/service?foo=1&bar=2&zap=42。
如果在测试数据中使用不存在的变量,则使用它的关键字将失败。如果用于变量相同的语法需要为文字字符串,则必须用反斜杠转义为\${NAME}。
2.5.2变量类型
本节简要介绍了不同的变量类型。变量的创建和使用在下面的小节中有更详细的描述。
Robot Framework变量与关键字类似,不区分大小写,空格和下划线也被忽略。但是,建议将所有大写字母与全局变量(例如${PATH}或${TWO_WORDS})和小写字母一起使用,这些变量只在某些测试用例或用户关键字(例如${my_var}或 ${myVar})中可用。更重要的是,案件应该一贯使用。
与使用类似变量语法的某些编程语言不同,在Robot Framework测试数据中,花括号({和})是强制性的。基本上,变量名可以在花括号之间有任何字符。但是,建议仅使用从a到z的字母字符,数字,下划线和空格,甚至需要使用扩展变量语法。
标量变量
在测试数据中使用标量变量时,它们将被分配的值替换。虽然标量变量最常用于简单字符串,但您可以将任何对象(包括列表)分配给它们。例如${NAME},标量变量语法对于 大多数用户应该是熟悉的,因为它也被用在例如shell脚本和Perl编程语言中。
下面的例子说明了标量变量的用法。假设变量${GREET}和${NAME}提供与分配给串Hello并world分别,同时例如测试用例是等价的。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 字符串 | 日志 | 你好 | |
| 日志 | 你好,世界!! | ||
| 变量 | 日志 | $ {} GREET | |
| 日志 | $ {GREET},$ {NAME} !! |
当一个标量变量被用作测试数据单元中唯一的值时,标量变量将被替换为它所具有的值。该值可以是任何对象。当一个标量变量与其他东西(常量字符串或其他变量)一起被用在一个测试数据单元格中时,它的值首先被转换成一个Unicode字符串,然后被链接到该单元格中的任何东西。将值转换为字符串意味着对象的方法__unicode__(在Python中,__str__作为后备)或toString(在Java中)被调用。
注意
当使用命名参数 语法将参数传递给关键字时,变量值按原样使用argname=${var}。
下面的示例演示了在单独的单元格中还是与其他内容中的变量之间的区别。首先,让我们假设我们有一个变量${STR}设置为一个字符串,Hello, world!并${OBJ}设置为以下Java对象的一个实例:
公共 类 MyObj { public String toString () { return “嗨,tellus!” ; } }
通过设置这两个变量,我们可以得到以下测试数据:
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 对象 | KW 1 | $ {} STR | |
| KW 2 | $ {} OBJ | ||
| KW 3 | 我说“$ {STR}” | ||
| KW 4 | 你说“$ {OBJ}” |
最后,当这个测试数据被执行时,不同的关键字接收参数如下:
- KW 1获得一个字符串
Hello, world! - KW 2将一个对象存储到变量中
${OBJ} - KW 3获得一个字符串
I said "Hello, world!" - KW 4获得一个字符串
You said "Hi, tellus!"
注意
如果变量不能表示为Unicode,则将变量转换为Unicode显然会失败。例如,如果您尝试将字节序列用作关键字的参数,则可能发生这种情况,以便将值链接在一起${byte1}${byte2}。解决方法是创建一个包含整个值的变量,并在单元格中单独使用它(例如${bytes}),因为该值原样使用。
列出变量
列表变量是复合变量,可以有几个值分配给他们。总之,他们总是列表,可以包含无限数量的条目(也可以是空列表)。列表变量的主要好处是,它们允许您为更大的数据集分配一个名称。虽然列表变量通常只包含字符串,但其他内容也是可能的。
在测试数据中使用列表变量时,列表中的元素将作为新的单元插入到测试数据中。因此,如果列表变量包含两个元素,则包含列表变量的单元格将变成具有列表变量内容的两个单元格。请注意,具有列表变量的单元格不应包含其他内容。列表变量语法@{NAME}是从Perl借用的。
假设列表变量@{USER}设置为该值 ['robot','secret'],以下两个测试用例是等效的。
| 测试用例 | 行动 | 用户名 | 密码 |
|---|---|---|---|
| 字符串 | 登录 | 机器人 | 秘密 |
| 列表变量 | 登录 | @{用户} |
访问单个列表变量项目
也可以使用语法从列表变量中访问某个值@{NAME}[i],其中,i是所选值的索引。索引从零开始,尝试访问索引过大的值会导致错误。以这种方式访问的列表项可以类似地用作标量变量:
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 字符串 | 登录 | 机器人 | 秘密 |
| 标题应该是 | 欢迎机器人! | ||
| 列表变量 | 登录 | @{用户} | |
| 标题应该是 | 欢迎@ {USER} [0]! |
使用列表变量的设置
列表变量只能用于某些设置。它们可以用于导入库和变量文件的参数,但是库和变量文件名本身不能是列表变量。另外带有setups和teardowns的列表变量不能作为关键字的名字,但是可以用在参数中。与标签相关的设置,他们可以自由使用。在不支持列表变量的地方使用标量变量是可能的。
| 设置 | 值 | 值 | 评论 |
|---|---|---|---|
| 图书馆 | ExampleLibrary | @ {LIB ARGS} | #这工作 |
| 图书馆 | $ {}库 | @ {LIB ARGS} | #这工作 |
| 图书馆 | @ {姓名和家庭} | #这不起作用 | |
| 套件设置 | 一些关键字 | @ {KW ARGS} | #这工作 |
| 套件设置 | 为$ {keyword} | @ {KW ARGS} | #这工作 |
| 套件设置 | @{关键词} | #这不起作用 | |
| 默认标签 | @ {}标签 | #这工作 |
使用列表变量作为标量
可以使用列表变量作为包含列表的标量变量,只需替换@为$。这使得可以使用列表变量与列表相关的关键字,例如从BuiltIn和Collections库。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | @ {list} = | 创建列表 | 第一 | 第二 |
| 长度应该是 | $ {}名单 | 2 | ||
| 附加到列表 | $ {}名单 | 第三 | ||
| 长度应该是 | $ {}名单 | 3 | ||
| 从列表中删除 | $ {}名单 | 1 | ||
| 长度应该是 | $ {}名单 | 2 | ||
| 记录许多 | @ {}名单 |
请注意,列表变量值的可能更改不限于当前变量作用域。由于没有创建新变量,而是改变现有变量的状态,所有查看该变量的测试和关键字也会看到更改。如果这是一个问题,则可以使用Collections库中的Copy List关键字来创建变量的本地副本。
使用列表变量作为标量只有在没有与列表变量具有相同基本名称的标量变量时才起作用。在这些情况下,标量变量有优先权,而是使用其值。
使用标量变量作为列表
从Robot Framework 2.8开始,也可以使用标量变量作为列表变量。如果一个标量变量包含任何列表类似的对象,就可以通过更换被用作列表变量$与@。例如,对于for循环以及标量列表中的项目需要用作关键字的单独参数时,这是非常有用的。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 例 | $ {list} = | 创建列表 | 第一 | 第二 |
| 记录许多 | @ {}名单 | |||
| $ {string} = | 链状 | @ {}名单 | ||
| 应该是平等的 | $ {}字符串 | 第一秒 | ||
| :对于 | $ {}项 | 在 | @ {}名单 | |
| 日志 | $ {}项 |
如果标量变量包含任何非列表对象,例如字符串或整数,则将其用作列表变量将失败。完全像使用列表变量作为标量一样,使用标量变量作为列表仅在没有具有相同基本名称的列表变量时才起作用。
环境变量
Robot Framework允许使用语法在测试数据中使用环境变量%{ENV_VAR_NAME}。它们仅限于字符串值。
在执行测试之前在操作系统中设置的环境变量是可用的,可以使用关键字Set Environment Variable创建新的 环境变量,或者使用关键字Delete Environment Variable删除现有的环境变量,两者都可以在 OperatingSystem库中找到。因为环境变量是全局的,所以在一个测试用例中设置的环境变量可以用在其他的测试用例之后。但是,对环境变量的更改在测试执行后无效。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 环境变量 | 日志 | 当前用户:%{USER} | |
| 跑 | %{JAVA_HOME} $ {/} javac的 |
Java系统属性
使用Jython运行测试时,可以 使用与环境变量相同的语法来访问Java系统属性。如果存在同名的环境变量和系统属性,则使用环境变量。在Robot Framework 2.6中添加了对访问Java系统属性的支持。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 系统属性 | 日志 | %{user.name}在%{os.name}上运行测试 |
2.5.3创建变量
变量可以从以下小节中描述的不同来源中产生。
变量表
变量最常见的来源是测试用例文件和资源文件中的变量表。变量表很方便,因为它们允许在与测试数据的其余部分相同的位置创建变量,并且所需的语法非常简单。它们的主要缺点是值始终是字符串,不能动态创建。如果其中任何一个出现问题,则可以使用变量文件。
创建标量变量
最简单的变量赋值就是将一个字符串设置为一个标量变量。这是通过给${}变量表的第一列中的变量名(包括 )和第二个中的值来完成的。如果第二列为空,则将空字符串设置为值。也可以在值中使用已经定义的变量。
| 变量 | 值 | 值 |
|---|---|---|
| $ {NAME} | 机器人框架 | |
| $ {VERSION} | 2.0 | |
| $ {机器人} | $ {NAME} $ {VERSION} |
=在变量名之后使用等号也可以,但不是强制性的,使变量的分配略微更明确。
| 变量 | 值 | 值 |
|---|---|---|
| $ {NAME} = | 机器人框架 | |
| $ {VERSION} = | 2.0 |
创建列表变量
创建列表变量与创建标量变量一样简单。同样,变量名称位于变量表格的第一列,以及后续列中的值。一个列表变量可以有任意数量的值,从零开始,如果需要很多值,它们可以分成几行。
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| @ {NAMES} | 马蒂 | 铁炮 | |
| @ {} NAMES2 | @ {NAMES} | 雪峰 | |
| @{没有} | |||
| @{许多} | 一 | 二 | 三 |
| ... | 四 | 五 | 六 |
| ... | 七 |
变量文件
变量文件是创建不同类型的变量的最强大的机制。可以将变量分配给使用它们的任何对象,并且还可以动态地创建变量。变量文件的语法和变量文件的使用在资源和变量文件部分进行了解释。
在命令行中设置变量
变量可以在命令行中单独使用--variable(-v)选项设置,或者使用带有--variablefile(-V)选项的变量文件来设置 。从命令行设置的变量全局可用于所有已执行的测试数据文件,还可以覆盖变量表中相同名称和测试数据中导入的变量文件中的可能变量。
设置单个变量的语法是--variable name:value,其中name是没有${}和的变量的名称 value。通过多次使用此选项可以设置多个变量。只有标量变量可以使用这个语法来设置,并且只能得到字符串值。许多特殊字符很难在命令行中表示,但可以使用--escape 选项来转义。
- 变化例:价值- 变量HOST:localhost:7272 - 变量USER:机器人- 变量ESCAPED:Qquotes_and_spacesQ --escape quot:Q - 转义空间:_
在上面的例子中,变量是这样设置的
${EXAMPLE}获得价值value${HOST}并${USER}获得值localhost:7272和robot${ESCAPED}获得价值"quotes and spaces"
从命令行使用变量文件的基本语法是--variablefile path / to / variables.py,并将变量文件变为use部分有更多的细节。实际创建的变量取决于引用变量文件中的变量。
如果从命令行给出变量文件和单个变量,则后者具有更高的优先级。
从关键字返回值
关键字的返回值也可以设置为变量。这样即使在不同的测试库中也可以实现不同关键字 下面的例子说明了一个简单案例的语法:
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 返回 | $ {x} = | 得到X | 一个论点 |
| 日志 | 我们得到$ {x}! | ||
| 设置变量 | $ {var} = | 设置变量 | 例 |
| 应该是平等的 | $ {VAR} | 例 |
在上面的第一个例子中,Get X关键字返回的值首先被设置到变量中${x},然后被Log 关键字使用。这个语法适用于所有关键字返回的情况,变量被设置为关键字返回的值。在=变量名之后加上等号不是强制性的,而是推荐的,因为它使得赋值更加明确。
上面的第二个例子展示了如何使用BuiltIn Set Variable关键字来设置预定义的测试用例作用域变量。同样的方法显然也适用于用户关键字范围中的变量。如果所有测试共享相同的预定义变量,则建议使用 变量表。
如果一个关键字返回一个列表,或者任何类似列表的对象,也可以将返回值分配给几个标量变量和/或一个列表变量。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 返回倍数 | $ {scalar} = | 得到3 | ||
| $ {A} | $ {B} | $ {c} = | 得到3 | |
| $ {}第一 | @ {rest} = | 得到3 | ||
| @ {list} = | 得到3 |
假设关键字Get 3返回一个列表 [1, 2, 3],将创建以下变量:
${scalar}与价值[1, 2, 3]${a},${b}并且${c}与值1,2和3分别${first}与价值1和@{rest}价值[2, 3]@{list}与价值[1, 2, 3]
以这种方式设置的变量在其他方面与其他变量类似,但是它们仅在创建测试用例或关键字的范围内可用。因此,例如,在一个测试用例中设置一个变量并将其用于另一个测试用例是不可能的。这是因为一般情况下,自动化测试用例不应相互依赖,并且意外设置其他地方使用的变量可能会导致难以调试的错误。如果真的需要在一个测试用例中设置一个变量并在另一个测试用例中使用它,可以使用下一节中介绍的BuiltIn关键字。
使用设置测试/套件/全局变量关键字
该内建库有关键字设置测试变量, 设置套房变量和设置全局变量可用于测试执行过程中动态地设置变量。如果新范围内已经存在一个变量,则其值将被覆盖,否则将创建一个新变量。
使用Set Test Variable关键字设置的变量在当前执行的测试用例范围内的任何地方都是可用的。例如,如果您在用户关键字中设置变量,则在测试用例级别以及当前测试中使用的所有其他用户关键字中都可以使用该变量。其他测试用例不会看到用这个关键字设置的变量。
使用Set Suite Variable关键字设置的变量在当前执行的测试套件的范围内随处可见。因此,使用此关键字设置变量与使用测试数据文件中的变量表创建变量或从变量文件中导入变量具有相同的效果。其他测试套件(包括可能的子测试套件)将不会看到使用此关键字设置的变量。
设置变量设置全局变量的关键字是在设置这些之后执行的所有测试用例和套件全局可用。因此使用这个关键字设置变量与使用选项--variable或 --variablefile 从命令行创建的效果相同 。因为这个关键字可以在任何地方改变变量,所以应该小心使用。
注意
将测试/套件/全局变量关键字直接设置为测试,套件或全局变量范围, 并且不返回任何内容。另一方面,另一个BuiltIn关键字 Set Variable使用返回值设置局部变量。
2.5.4内置变量
Robot Framework提供了一些自动可用的内置变量。
操作系统变量
与操作系统相关的内置变量简化了测试数据的操作系统不可知性。
| 变量 | 说明 |
|---|---|
| $ {} CURDIR | 测试数据文件所在目录的绝对路径。这个变量是区分大小写的。 |
| $ {TEMPDIR} | 系统临时目录的绝对路径。在类UNIX系统中,这通常是/ tmp,并且在Windows c:\ Documents and Settings \ |
| $ {} EXECDIR | 执行测试执行的目录的绝对路径。 |
| $ {/} | 系统目录路径分隔符。/在类UNIX系统和\ Windows中。 |
| $ {:} | 系统路径元素分隔符。:在类UNIX系统和;Windows中。 |
| $ {\ n} | 系统行分隔符。\ n在类UNIX系统中和 \ r \ n在Windows中。2.7.5版本中的新功能 |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 创建二进制文件 | $ {CURDIR} $ {/} input.data | 这里有两行$ {\ n} |
| 设置环境变量 | CLASSPATH | $ {TEMPDIR} $ {:} $ {CURDIR} $ {/} foo.jar中 |
数字变量
变量语法可用于创建整数和浮点数,如下例所示。当一个关键字希望得到一个实际的数字,而不是一个看起来像一个数字的字符串时,这是非常有用的。
| 测试用例 | 行动 | 论据 | 论据 | 评论 |
|---|---|---|---|---|
| 示例1A | 连 | example.com | 80 | #Connect获取两个字符串作为参数 |
| 实例1B | 连 | example.com | $ {} 80 | #连接获取一个字符串和一个整数 |
| 例2 | 做X | $ {} 3.14 | $ { - 1E-4} | #X获得浮点数3.14和-0.0001 |
从机器人框架2.6开始,有可能也是从二进制,八进制,和十六进制值使用创建的整数0b,0o 和0x前缀分别。语法不区分大小写。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 应该是平等的 | $ {} 0b1011 | $ {11} |
| 应该是平等的 | $ {} 0o10 | $ {8} | |
| 应该是平等的 | $ {}为0xFF | $ {} 255 | |
| 应该是平等的 | $ {} 0B1010 | $ {}的0xA |
布尔值和无/空变量
也可以使用类似于数字的变量语法创建布尔值和Python None和Java null。
| 测试用例 | 行动 | 论据 | 论据 | 评论 |
|---|---|---|---|---|
| 布尔 | 设置状态 | $ {TRUE} | #设置状态获取布尔值作为参数 | |
| 创建Y | 某物 | $ {}假 | #创建Y获取一个字符串,布尔值为false | |
| 没有 | 做XYZ | $ {}无 | #XYZ是否将Python作为参数 | |
| 空值 | $ {ret} = | 获得价值 | ARG | #检查Get Value是否返回Java null |
| 应该是平等的 | $ {} RET | $ {}空 |
这些变量是不区分大小写的,例如${True}和 ${true}等价的。此外,${None}和 ${null}是同义词,因为Jython解释运行测试时,Jython的自动转换None,并 null以正确的格式在必要的时候。
空间和空变量
可以分别使用变量${SPACE}和空格来创建空格和空字符串 ${EMPTY}。这些变量是有用的,例如,否则需要使用反斜杠转义空格或空单元格。如果需要一个以上的空间,有可能使用扩展变量语法等 ${SPACE * 5}。在下面的例子中,应该是等于关键字获得相同的参数,但使用变量的那些比使用反斜杠更容易理解。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 一个空间 | 应该是平等的 | $ {空白} | \ \ \ |
| 四个空间 | 应该是平等的 | $ {SPACE * 4} | \ \ \ \ \ |
| 十个空间 | 应该是平等的 | $ {SPACE * 10} | \ \ \ \ \ \ \ \ \ \ |
| 引用空间 | 应该是平等的 | “$ {空白}” | “” |
| 引用的空间 | 应该是平等的 | “$ {SPACE * 2}” | “\” |
| 空 | 应该是平等的 | $ {EMPTY} | \ |
从Robot Framework 2.7.4开始,还有一个空的列表变量 @{EMPTY}。因为它没有内容,所以在测试数据中的某处使用时基本上会消失。例如,当使用template关键字而不带参数或在不同范围内重写列表变量时,使用测试模板是很有用的。修改的价值是不可能的。@{EMPTY}
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 模板 | [模板] | 一些关键字 | |
| @ {} EMPTY | |||
| 覆盖 | 设置全局变量 | @ {}清单 | @ {} EMPTY |
自动变量
一些自动变量也可以用在测试数据中。这些变量在测试执行过程中可能有不同的值,有些甚至一直不可用。更改这些变量的值不会影响原始值,但是可以使用BuiltIn库中的关键字动态更改一些值。
| 变量 | 说明 | 可得到 |
|---|---|---|
| $ {TEST NAME} | 当前测试用例的名称。 | 测试用例 |
| @ {TEST TAGS} | 包含当前测试用例的标签,按字母顺序排列。可以使用“ 设置标签”和“ 移除标签”关键字来动态修改 | 测试用例 |
| $ {TEST DOCUMENTATION} | 当前测试用例的文档。可以使用Set Test Documentation 关键字动态设置。Robot Framework 2.7新增功能 | 测试用例 |
| $ {测试状态} | 当前测试用例的状态,即PASS或FAIL。 | 测试拆解 |
| $ {TEST MESSAGE} | 当前测试用例的消息。 | 测试拆解 |
| $ {PREV TEST NAME} | 前一个测试用例的名称,如果尚未执行任何测试,则返回一个空字符串。 | 到处 |
| $ {PREV TEST STATUS} | 以前的测试用例的状态:PASS,FAIL,或没有执行测试时的空字符串。 | 到处 |
| $ {PREV TEST MESSAGE} | 前面的测试用例可能的错误信息。 | 到处 |
| $ {SUITE NAME} | 当前测试套件的全名。 | 到处 |
| $ {SUITE SOURCE} | 套件文件或目录的绝对路径。Robot Framework 2.5中的新功能 | 到处 |
| $ {SUITE DOCUMENTATION} | 当前测试套件的文档。可以使用Set Suite Documentation关键字动态设置。Robot Framework 2.7新增功能 | 到处 |
| $ {SUITE METADATA} | 当前测试套件的免费元数据。可以使用Set Suite Metadata关键字进行设置。Robot Framework 2.7.4新增功能 | 到处 |
| $ {SUITE STATUS} | 当前测试套件的状态,通过或失败。 | 套房拆解 |
| $ {SUITE MESSAGE} | 当前测试套件的完整信息,包括统计信息。 | 套房拆解 |
| $ {KEYWORD STATUS} | 当前关键字的状态,通过或失败。Robot Framework 2.7新增功能 | 用户关键字拆解 |
| $ {KEYWORD MESSAGE} | 当前关键字可能的错误信息。Robot Framework 2.7新增功能 | 用户关键字拆解 |
| $ {LOG LEVEL} | 当前日志级别。Robot Framework 2.8新增功能 | 到处 |
| $ {OUTPUT FILE} | 输出文件的绝对路径。 | 到处 |
| $ {LOG FILE} | 当没有创建日志文件时,日志文件或字符串NONE 的绝对路径。 | 到处 |
| $ {REPORT FILE} | 报告文件的绝对路径或未创建报告时的字符串NONE。 | 到处 |
| $ {DEBUG FILE} | 调试文件或字符串NONE 的绝对路径,当没有调试文件被创建。 | 到处 |
| $ {OUTPUT DIR} | 输出目录的绝对路径。 | 到处 |
套房相关的变量${SUITE SOURCE},${SUITE NAME}, ${SUITE DOCUMENTATION}和${SUITE METADATA}可已经在测试库和可变文件导入,除了机器人框架2.8和2.8.1,其中该支持被打破。尽管这些自动变量中的可能变量在导入时尚未解决。
2.5.5变量优先级和范围
来自不同来源的变量具有不同的优先级,并且可以在不同的范围内提供。
变量优先
命令行中的变量
在命令行中设置的变量具有在实际测试执行开始之前可以设置的所有变量的最高优先级。它们覆盖在测试用例文件中的变量表中以及在测试数据中导入的资源和变量文件中创建的可能变量。
单独设置变量(--variable选项)会覆盖使用变量文件设置的变量(--variablefile选项)。如果多次指定相同的单个变量,则最后指定的变量将覆盖较早的变量。这允许在启动脚本中设置变量的默认值,并从命令行覆盖它们。不过请注意,如果多个变量文件具有相同的变量,那么指定的文件中的变量文件将具有最高的优先级。
测试用例文件中的变量表
使用测试用例文件中的变量表创建的变量可用于该文件中的所有测试用例。这些变量会覆盖导入的资源和变量文件中具有相同名称的可能变量。
在变量表中创建的变量在创建它们的文件中的所有其他表中都可用。这意味着它们也可以在设置表中使用,例如,从资源文件和变量文件中导入更多的变量。
导入的资源和变量文件
从资源和变量文件导入的变量具有在测试数据中创建的所有变量的最低优先级。资源文件和变量文件的变量具有相同的优先级。如果多个资源和/或变量文件具有相同的变量,则首先导入的文件中的那些被使用。
如果资源文件导入资源文件或变量文件,则变量表中的变量比其导入的变量具有更高的优先级。所有这些变量都可用于导入此资源文件的文件。
请注意,从资源文件和变量文件导入的变量在导入文件的变量表中不可用。这是由于在导入资源文件和变量文件的设置表之前正在处理变量表。
测试执行期间设置的变量
在测试执行期间使用 关键字的返回值或 使用Set Test / Suite / Global Variable关键字设置的变量 始终会覆盖可能的现有变量。从某种意义上讲,他们因此具有最高的优先权,但另一方面,他们不会影响他们定义范围以外的变量。
内置变量
内置变量一样${TEMPDIR},并${TEST_NAME}拥有所有变量的最高优先级。它们不能被变量表或命令行覆盖,但是即使在测试执行期间它们也可以被重置。此规则的一个例外是 数字变量,如果没有发现 变量,则动态解析 数字变量。他们可以被覆盖,但这通常是一个坏主意。此外${CURDIR},由于在测试数据处理期间已经被替换,所以是特别的。
变量范围
根据创建的位置和方式,变量可以具有全局,测试套件,测试用例或用户关键字范围。
全球范围
测试数据中的全局变量都是可用的。这些变量通常在命令行中用 --variable和--variablefile选项设置,但是也可以在测试数据中的任何位置使用BuiltIn关键字设置全局变量来创建新的全局变量或更改现有的变量。另外内置的变量是全局的。
建议对所有全局变量使用大写字母。
测试套件范围
测试套件范围的变量在定义或导入的测试套件的任何地方都是可用的。它们可以在变量表中创建,从资源和变量文件导入,或者在测试执行过程中使用BuiltIn关键字 Set Suite变量设置。
测试套件范围不是递归的,这意味着更高级别测试套件中可用的变量在低级套件中不可用。如有必要,资源和变量文件可用于共享变量。
由于这些变量在使用它们的测试套件中可以被认为是全局的,因此建议也使用大写字母。
测试用例范围
测试用例中的关键字返回值中创建的变量 具有测试用例范围,并且仅在该测试用例中可用。创建它们的另一种可能性是在特定的测试用例的任何地方使用BuiltIn关键字 Set Test Variable。测试用例变量是本地的,应该使用小写字母。
用户关键字范围
用户关键字从传递给它们的参数中获取自己的变量, 并从它们使用的关键字返回值。这些变量也是本地的,应该使用小写字母。
2.5.6高级变量功能
扩展的变量语法
扩展变量语法允许访问分配给变量(例如${object.attribute})的对象的属性,甚至可以调用其方法(例如,${obj.getName()})。它与标量和列表变量一起工作,但主要用于前者
扩展变量语法是一个强大的功能,但应该小心使用它。访问属性通常不是问题,相反,因为包含具有多个属性的对象的一个变量通常比具有多个变量更好。另一方面,调用方法,尤其是当它们与参数一起使用时,可能会使测试数据变得相当复杂难以理解。如果发生这种情况,建议将代码移动到测试库中。
下面的例子说明了扩展变量语法的最常用的用法。首先假定我们有以下变量文件 和测试用例:
类 MyObject : def __init__ (self , name ): self 。name = name 高清 吃(自我, 什么): 返回 ' %s的吃%S ' % (自我。名称, 什么) def __str__ (self ): 返回 自我。名称OBJECT = MyObject ('Robot' )DICTIONARY = { 1 : 'one' , 2 : 'two' , 3 : 'three' }
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | KW 1 | $ {} OBJECT.name | |
| KW 2 | $ {OBJECT.eat( '黄瓜')} | ||
| KW 3 | $ {DICTIONARY [2]} |
当这个测试数据被执行时,关键字获取参数,如下所示:
- KW 1获得字符串
Robot - KW 2获得字符串
Robot eats Cucumber - KW 3获取字符串
two
扩展变量语法按以下顺序进行评估:
- 该变量使用完整的变量名称进行搜索。只有在没有找到匹配变量的情况下,扩展变量语法才会被计算。
- 基本变量的名称被创建。名称的主体由开放后的所有字符组成,
{直到首次出现不是字母数字字符或空格的字符。例如,基本变量${OBJECT.name}和${DICTIONARY[2]})是OBJECT和DICTIONARY分别。 - 搜索与身体匹配的变量。如果不匹配,则引发异常,测试用例失败。
- 大括号内的表达式被评估为一个Python表达式,以便基本变量名称被其值替换。如果由于语法无效而导致评估失败,或者查询的属性不存在,则会引发异常,并且测试失败。
- 整个扩展变量被替换为从评估返回的值。
如果使用的对象是用Java实现的,则扩展变量语法允许您使用所谓的bean属性来访问属性。实质上,这意味着如果你有一个getName 方法设置为一个变量的对象 ${OBJ},那么语法${OBJ.name}相当于但比它更清晰 ${OBJ.getName()}。前面例子中使用的Python对象可以用下面的Java实现来代替:
公共 类 MyObject : 私人 字符串 名称; public MyObject (String name ) { name = name ; } public String getName () { return name ; } public String eat (String what ) { return name + “吃” + what ; } public String toString () { return name ; } }
许多标准的Python对象,包括字符串和数字,都有明确或隐含地使用扩展变量语法的方法。有时这可能是非常有用的,并且减少了设置临时变量的需求,但是过度使用它并创建真正的模拟测试数据也是很容易的。下面的例子显示了一些相当不错的用法。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 串 | $ {string} = | 设置变量 | ABC |
| 日志 | $ {string.upper()} | #记录“ABC” | |
| 日志 | $ {string * 2} | #日志“abcabc” | |
| 数 | $ {number} = | 设置变量 | $ { - 2} |
| 日志 | $ {number * 10} | #日志-20 | |
| 日志 | $ {数.__ ABS()__} | #日志2 |
请注意,尽管在正常的Python代码中abs(number)被推荐 number.__abs__(),但是使用 ${abs(number)}不起作用。这是因为变量名称必须在扩展语法的开头。__xxx__ 在这样的测试数据中使用方法已经有点令人质疑了,通常将这种逻辑转移到测试库中会更好。
当使用标量变量作为列表时,扩展变量语法也可以工作。例如,如果分配给变量的对象${EXTENDED}具有attribute包含作为值的列表的属性,则可以将其用作列表变量@{EXTENDED.attribute}。
扩展变量赋值
从Robot Framework 2.7开始,可以使用关键字返回值和扩展变量语法的变体来设置存储到标量变量的对象的属性。假设我们${OBJECT}在前面的例子中有变量,可以像下面的例子那样设置属性。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | $ {OBJECT.name} = | 设置变量 | 新名字 |
| $ {OBJECT.new_attr} = | 设置变量 | 新的属性 |
使用以下规则评估扩展变量分配语法:
- 分配的变量必须是标量变量,并且至少有一个点。否则,不使用扩展分配语法,并且正常分配变量。
- 如果存在具有全名的变量(例如
${OBJECT.name}在上面的示例中),那么该变量将被分配新的值并且不使用扩展语法。 - 基本变量的名称被创建。名称的主体由开头
${和最后一个点之间的所有字符组成,例如OBJECTin${OBJECT.name}和foo.barin${foo.bar.zap}。如第二个例子所示,基本名称可能包含正常的扩展变量语法。 - 通过取最后一个点和结束点之间的所有字符
}(例如,namein)来创建要设置的属性的名称${OBJECT.name}。如果名称不是以字母或下划线开头,只包含这些字符和数字,则该属性被认为是无效的,并且不使用扩展语法。用全名创建一个新的变量。 - 搜索与基本名称匹配的变量。如果找不到变量,则不使用扩展语法,而是使用完整变量名称创建新变量。
- 如果找到的变量是字符串或数字,则忽略扩展语法,并使用全名创建新变量。这样做是因为你不能将新的属性添加到Python字符串或数字,这样新的语法也不会向后兼容。
- 如果所有先前的规则匹配,则将该属性设置为基本变量。如果设置因任何原因失败,则会引发异常,并且测试失败。
注意
与通常使用关键字返回值分配变量不同,使用扩展分配语法完成的变量更改不限于当前范围。由于没有创建新变量,而是改变现有变量的状态,所有查看该变量的测试和关键字也会看到更改。
变量内部的变量
变量也可以在变量内部使用,当使用这个语法时,变量从里到外被解析。例如,如果你有一个变量${var${x}},那么${x}首先解决。如果它有值name,那么最终值就是变量的值${varname}。可以有几个嵌套变量,但是解决最外层的失败,如果它们中的任何一个不存在的话。
在下面的示例中,Do X获取值,${JOHN HOME} 或者${JANE HOME}取决于Get Name返回 john或jane。如果它返回别的东西,解决 ${${name} HOME}失败。
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| $ {JOHN HOME} | /家/约翰· | ||
| $ {JANE HOME} | /家/简 |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | $ {name} = | 获取名称 | |
| 做X | $ {$ {name} HOME} |
2.6创建用户关键字
关键字表格用于通过将现有关键字组合在一起来创建新的更高级别的关键字。这些关键字称为用户关键字,以区别于 在测试库中实现的最低级库关键字。用于创建用户关键字的语法与创建测试用例的语法非常接近,这使得它易于学习。
- 2.6.1用户关键字语法
- 基本的语法
- 关键字表格中的设置
- 2.6.2用户关键字名称和文档
- 2.6.3用户关键字参数
- 位置参数
- 用户关键字的默认值
- 带有用户关键字的可变参数
- 2.6.4将参数嵌入到关键字名称中
- 基本的语法
- 嵌入的参数匹配太多
- 使用自定义正则表达式
- 行为驱动开发的例子
- 2.6.5用户关键字返回值
- 使用[返回]设置
- 使用特殊关键字返回
- 2.6.6用户关键词拆解
2.6.1用户关键字语法
基本的语法
在许多方面,整体用户关键字语法与测试用例语法相同 。用户关键字是在关键字表格中创建的,这些表格与测试用例表格的区别仅在于用于标识它们的名称。用户关键字名称与测试用例名称类似,位于第一列。用户关键字也可以从关键字中创建,可以从测试库中的关键字或其他用户关键字中创建 关键字名称通常在第二列,但是当从关键字返回值设置变量时,它们位于后续列中。
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 打开登录页面 | 打开浏览器 | HTTP://host/login.html | |
| 标题应该是 | 登录页面 | ||
| 标题应该以 | [参数] | $ {}预期 | |
| $ {title} = | 获取标题 | ||
| 应该开始 | $ {}称号 | $ {}预期 |
大多数用户关键字需要一些参数 这个重要的特性已经在上面的第二个例子中使用了,本节稍后会详细解释 ,与用户关键字返回值类似。
用户关键字可以在测试用例文件,资源文件和测试套件初始化文件中创建。在资源文件中创建的关键字可用于使用它们的文件,而其他关键字仅在创建它们的文件中可用。
关键字表格中的设置
用户关键字可以具有与测试用例相似的设置,并且它们具有相同的方括号语法,将它们与关键字名称分开。下面列出了所有可用的设置,并在本节稍后进行介绍。
- [文档]
- 用于设置 用户关键字文档。
- [参数]
- 指定 用户关键字参数。
- [返回]
- 指定 用户关键字返回值。
- [拆除]
- 指定 用户关键字拆解。从Robot Framework 2.6开始可用。
- [时间到]
- 设置可能的 用户关键字超时。 超时在他们自己的部分中讨论。
2.6.2用户关键字名称和文档
用户关键字名称在用户关键字表的第一列中定义。当然,这个名字应该是描述性的,并且有相当长的关键字名称是可以接受的。实际上,当创建类似用例的测试用例时,最高级别的关键字通常被定义为句子甚至段落。
用户关键字可以具有与 [文档]设置一致的文档,与测试用例文档完全一样。此设置记录测试数据中的用户关键字。它也显示在更正式的关键字文档中,libdoc工具可以从资源文件创建。最后,文档的第一行显示为测试日志中的关键字文档 。
有时需要删除关键字,替换为新关键字,或者由于其他原因而不推荐使用。用户关键字可以通过启动文档来标记为废弃*DEPRECATED*,这将在使用keyoword时引发警告。有关更多信息,请参阅 弃用关键字部分。
2.6.3用户关键字参数
大多数用户关键字需要一些参数。指定它们的语法可能是Robot Framework通常需要的最复杂的功能,但即使这样也相对容易,特别是在大多数情况下。参数通常与指定的[参数]设定,参数名称使用相同的语法作为变量,例如${arg}。
位置参数
指定参数最简单的方法(除了根本没有它们)只使用位置参数。在大多数情况下,这是所有需要的。
语法是这样的:首先给出[Arguments]设置,然后在随后的单元格中定义参数名称。每个参数都在自己的单元格中,使用与变量相同的语法。关键字必须与其签名中的参数名称一样多。实际的参数名称与框架无关,但从用户的角度来看,它们应该尽可能描述性的。建议在变量名中使用小写字母,或者as ${my_arg},${my arg}或者${myArg}。
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 一个参数 | [参数] | $ {} arg_name | ||
| 日志 | 得到了参数$ {arg_name} | |||
| 三个参数 | [参数] | $ {ARG1} | $ {ARG2} | $ {} ARG3 |
| 日志 | 第一个参数:$ {arg1} | |||
| 日志 | 第二个参数:$ {arg2} | |||
| 日志 | 第三个参数:$ {arg3} |
用户关键字的默认值
在创建用户关键字时,位置参数在大多数情况下是足够的。但是,有时关键字有一些或全部参数的默认值是有用的 。用户关键字也支持默认值,所需的新语法不会增加很多已经讨论过的基本语法。
总之,默认值被添加到参数,所以首先有等号(=),然后是值,例如${arg}=default。默认情况下可以有很多参数,但都必须在正常的位置参数之后给出。默认值可以包含 在套件或全局范围上创建的变量。
注意
缺省值的语法是空间敏感的。=符号之前的空格是不允许的,其后面的可能空格被认为是默认值本身的一部分。
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 一个带有默认值的参数 | [参数] | $ {arg} =默认值 | |
| [文档] | 这个关键字需要 | 0-1的参数 | |
| 日志 | 得到了参数$ {arg} | ||
| 两个带有默认值的参数 | [参数] | $ {arg1} =默认1 | $ {ARG2} = $ {}变量 |
| [文档] | 这个关键字需要 | 0-2的参数 | |
| 日志 | 第一个参数$ {arg1} | ||
| 日志 | 第二个参数$ {arg2} | ||
| 一个需要和一个默认 | [参数] | $ {}要求 | $ {}可选默认= |
| [文档] | 这个关键字需要 | 1-2个参数 | |
| 日志 | 必需:$ {required} | ||
| 日志 | 可选:$ {可选} |
当一个关键字接受几个具有默认值的参数,并且只有一些参数需要重写时,使用命名参数语法通常很方便 。当这个语法与用户关键字一起使用时,参数被指定而没有${} 装饰。例如,上面的第二个关键字可以像下面一样使用,${arg1}仍然会得到它的默认值。
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 两个带有默认值的参数 | arg2 =新值 |
由于所有的Pythonistas必须已经注意到,指定默认参数的语法在很大程度上受Python语法对函数默认值的启发。
带有用户关键字的可变参数
有时甚至默认值是不够的,需要一个关键字接受可变数量的参数。用户关键字也支持这个功能。所有这一切都需要具有列表变量, 如@{varargs}关键字签名中的最后一个参数。这个语法可以和前面描述的位置参数和默认值相结合,最后list变量获得所有与其他参数不匹配的剩余参数。列表变量因此可以具有任何数量的项目,甚至为零。
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 任何数量的参数 | [参数] | @ {}可变参数 | ||
| 记录许多 | @ {}可变参数 | |||
| 一个或多个参数 | [参数] | $ {}要求 | @{休息} | |
| 记录许多 | $ {}要求 | @{休息} | ||
| 必需,默认,可变参数 | [参数] | $ {} REQ | $ {选择} = 42 | @{其他} |
| 日志 | 必需:$ {req} | |||
| 日志 | 可选:$ {opt} | |||
| 日志 | 其他: | |||
| :FOR | $ {}项 | 在 | @{其他} | |
| 日志 | $ {}项 |
注意,如果上面的最后一个关键字与多个参数一起使用,那么第二个参数${opt}总是得到给定的值而不是默认值。即使给定值为空,也会发生这种情况。最后一个例子还说明了如何在for循环中使用用户关键字接受的可变数量的参数。这两个相当先进的功能的组合有时是非常有用的。
再一次,Pythonistas可能会注意到,可变数量的参数语法与Python中的非常接近。
2.6.4将参数嵌入到关键字名称中
Robot Framework还提供了另一种方法来将参数传递给用户关键字,而不是像上一节中所述那样在关键字名称后面的单元格中指定它们。该方法基于将参数直接嵌入到关键字名称中,其主要优点是使用真实和明确的句子作为关键字更容易。
基本的语法
一直以来,可以使用类似的关键字选择狗从列表,并选择从猫名单,但所有这些关键字必须一直是单独实施。将参数嵌入到关键字名称中的想法是,您只需要一个名称为“ Select $ {animal}”的关键字 。
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 从列表中选择$ {动物} | 打开页面 | 宠物选择 | |
| 从列表中选择项目 | animal_list | $ {}动物 |
关键字使用嵌入式参数不能带任何“正常”参数(用[参数]设置指定),否则就像其他用户关键字一样创建。名称中使用的参数自然可以在关键字中使用,并且根据关键字的调用方式而有不同的值。例如, 如果关键字像列表中的Select dog一样使用${animal},那么前面的值dog就是有效的。显然,在关键字中使用所有这些参数并不是强制性的,因此可以用作通配符。
除了空格和下划线在名称中不被忽略之外,这些关键字的使用方式与其他关键字相同。但是,它们与其他关键字不区分大小写。例如,上面的例子中的关键字可以用来 从列表中选择x,但不能像Select x fromlist那样。
嵌入式参数不支持像普通参数那样的默认值或可变数量的参数。调用这些关键字时使用变量是可能的,但这会降低可读性。还要注意,嵌入的参数只能用于用户关键字。
嵌入的参数匹配太多
使用嵌入式参数的一个棘手的部分是确保调用关键字时使用的值匹配正确的参数。这是一个问题,尤其是如果有多个参数和分隔它们的字符也可能出现在给定的值。例如,关键字选择$ {city} $ {team}如果与包含太多部分的城市一起使用,则无法正常工作,如Select Los Angeles LAkers。
这个问题的一个简单的解决方法是引用参数(例如 选择“$ {city}”“$ {team}”)并使用引用格式的关键字(例如选择“洛杉矶”“湖人”)。尽管如此,这种方法还不足以解决所有这类冲突,但仍然强烈建议使用这种方法,因为它使得参数从关键字的其余部分中脱颖而出。在定义变量时使用自定义正则表达式是一个更强大但更复杂的解决方案,将在下一节解释。最后,如果事情变得复杂,那么使用普通的位置参数可能会更好。
参数匹配太多的问题经常发生在创建关键字时忽略given / when / then /和前缀。例如, $ {name}回家比赛鉴于Janne回家,以便${name}获得价值Given Janne。像“$ {name}”这样的参数引用,可以很容易地解决这个问题。
使用自定义正则表达式
当调用带有嵌入参数的关键字时,这些值在内部使用正则表达式进行匹配 (简称为regexps)。默认的逻辑是这样的,名称中的每个参数都被一个.*?基本上匹配任何字符串的模式替换。这个逻辑通常工作得相当好,但正如上面所讨论的,有时候关键字比预期的要多。引用或以其他方式将参数与其他文本分开可能会有所帮助,但是,例如,以下测试失败,因为关键字 I执行带有“-lh”的“ls”与两个定义的关键字都匹配。
| 测试用例 | 步 |
|---|---|
| 例 | 我执行“ls” |
| 我用“-lh”执行“ls” |
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 我执行“$ {cmd}” | 跑 | $ {cmd},在 | |
| 我用“$ {opts}”执行“$ {cmd}” | 跑 | $ {cmd} $ {opts} |
解决这个问题的方法是使用一个自定义的正则表达式来确保关键字只匹配它在特定的上下文中的内容。为了能够使用这个特性,并且要充分理解本节中的例子,至少需要了解正则表达式语法的基础知识。
自定义嵌入式参数正则表达式在参数的基本名称之后定义,以便参数和正则表达式以冒号分隔。例如,一个只能匹配数字的参数可以像这样定义${arg:\d+}。下面的例子说明了使用自定义正则表达式。
| 测试用例 | 步 |
|---|---|
| 例 | 我执行“ls” |
| 我用“-lh”执行“ls” | |
| 我输入1 + 2 | |
| 我输入53 - 11 | |
| 今天是2011-06-27 |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 我执行“$ {cmd:[^”] +}“ | 跑 | $ {cmd},在 | ||
| 我用“$ {opts}”执行“$ {cmd}” | 跑 | $ {cmd} $ {opts} | ||
| 我输入$ {a:\ d +} $ {operator:[+ - ]} $ {b:\ d +} | 计算 | $ {A} | $ {}操作 | $ {B} |
| 今天是$ {date:\ d {4 \} - \ d {2 \} - \ d {2 \}} | 日志 | $ {}日期 |
在上面的例子中,我用“-lh”执行“ls”的关键字只匹配我用“$ {opts}”执行“$ {cmd}”。这是保证,因为自定义的正则表达式[^"]+在我执行“$ {CMD:[^”]}”指的是匹配的参数不能包含任何引号在这种情况下,没有必要定制正则表达式添加到其他的。我执行的变体。
小费
如果引用参数,则使用正则表达式可[^"]+ 保证参数仅匹配到第一个结束引号。
支持正则表达式语法
用Python实现,Robot Framework自然使用Python的 re模块,它具有非常标准的正则表达式语法。嵌入参数完全支持此语法,但(?...)不能使用格式的正则表达式扩展。还要注意匹配嵌入式参数是不区分大小写的。如果正则表达式语法无效,则创建关键字失败,并在测试执行错误中显示错误。
转义特殊字符
在自定义嵌入参数regexp中使用时,有一些特殊字符需要转义。首先,}模式中的花括号()可能需要使用单个反斜杠(\})进行转义,否则参数将会在那里结束。在前面的例子中,关键字 Today是$ {date:\ d {4 \} - \ d {2 \} - \ d {2 \}}。
反斜杠(\)是Python正则表达式语法中的一个特殊字符,因此如果您希望具有文字反斜杠字符,则需要将其转义。在这种情况下,最安全的转义序列是四个反斜杠(\\\\),但根据下一个字符,也可能有两个反斜杠。
还要注意,关键字名称和其中可能的嵌入式参数不应该使用正常的测试数据转义规则进行转义。这意味着,例如,表达式中的反斜杠${name:\w+}不应该被转义。
使用具有自定义嵌入式参数正则表达式
每当使用自定义嵌入式参数正则表达式时,Robot Framework会自动增强指定的正则表达式,以便匹配变量和匹配模式的文本。这意味着始终可以使用带有嵌入参数的关键字的变量。例如,下面的测试用例会使用前面例子中的关键字。
| 变量 | 值 |
|---|---|
| $ {DATE} | 2011-06-27 |
| 测试用例 | 步 |
|---|---|
| 例 | 我输入$ {1} + $ {2} |
| 今天是$ {DATE} |
自动匹配自定义正则表达式的变量的一个缺点是关键字获取的值可能并不匹配指定的正则表达式。例如,上例中的变量 ${DATE}可以包含任何值,而 今天$ {DATE}仍然会匹配相同的关键字。
行为驱动开发的例子
将参数作为关键字名称的一部分的最大好处在于,在以行为驱动样式编写测试用例时,可以更轻松地使用更高级的类似句子的关键字。下面的例子说明了这一点。还要注意,给定的前缀,时间和然后被排除在关键字定义之外。
| 测试用例 | 步 |
|---|---|
| 添加两个数字 | 鉴于我有计算器打开 |
| 当我加2和40 | |
| 那么结果应该是42 | |
| 添加负数 | 鉴于我有计算器打开 |
| 当我加1和-2 | |
| 那么结果应该是-1 |
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 我有$ {程序}打开 | 启动程序 | $ {方案} | |
| 我添加$ {number 1}和$ {number 2} | 输入号码 | $ {number 1} | |
| 按钮 | + | ||
| 输入号码 | $ {number 2} | ||
| 按钮 | = | ||
| 结果应该是$ {expected} | $ {result} = | 获得结果 | |
| 应该是平等的 | $ {}结果 | $ {}预期 |
注意
机器人框架中的嵌入式参数功能受到在流行的BDD工具Cucumber中如何创建步骤定义的启发。
2.6.5用户关键字返回值
与库关键字类似,用户关键字也可以返回值。通常,返回值是通过[Return] 设置定义的,但也可以使用BuiltIn关键字 返回关键字和返回关键字If。无论返回值如何,都可以将其分配给 测试用例和其他用户关键字中的变量。
使用[返回]设置
最常见的情况是用户关键字返回一个值,并将其分配给标量变量。使用[返回]设置时,通过在设置后的下一个单元格中具有返回值来完成此操作。
用户关键字也可以返回几个值,然后可以一次将它们分配给多个标量变量,列表变量或标量变量和列表变量。通过在[返回]设置之后的不同单元格中指定这些值,可以返回多个值。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 一个返回值 | $ {ret} = | 回报一个价值 | 论据 | |
| 一些关键字 | $ {} RET | |||
| 多个值 | $ {A} | $ {B} | $ {c} = | 回报三个价值观 |
| @ {list} = | 回报三个价值观 | |||
| $ {}标 | @ {rest} = | 回报三个价值观 |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 回报一个价值 | [参数] | $ {} ARG | ||
| 做一点事 | $ {} ARG | |||
| $ {value} = | 获得一些价值 | |||
| [返回] | $ {}值 | |||
| 回报三个价值观 | [返回] | FOO | 酒吧 | ZAP |
使用特殊关键字返回
内置的关键字返回从关键字和返回从关键字如果 允许用户关键词在关键词中间有条件返回。它们都接受可选的返回值,与上面讨论的[返回]设置完全相同。
下面的第一个例子在功能上与前面的 [Return]设置示例相同。第二个更高级的示例演示了在for循环内有条件地返回。
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 一个返回值 | $ {ret} = | 回报一个价值 | 论据 | |
| 一些关键字 | $ {} RET | |||
| 高级 | @ {list} = | 创建列表 | FOO | 巴兹 |
| $ {index} = | 查找索引 | 巴兹 | @ {}名单 | |
| 应该是平等的 | $ {}指数 | $ {1} | ||
| $ {index} = | 查找索引 | 不存在 | @ {}名单 | |
| 应该是平等的 | $ {}指数 | $ { - 1} |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 回报一个价值 | [参数] | $ {} ARG | ||
| 做一点事 | $ {} ARG | |||
| $ {value} = | 获得一些价值 | |||
| 从关键字返回 | $ {}值 | |||
| 失败 | 这不被执行 | |||
| 查找索引 | [参数] | $ {}元素 | @ {}项目 | |
| $ {指数=} | 设置变量 | $ {0} | ||
| :对于 | $ {}项 | 在 | @ {}项目 | |
| 从关键字返回If | '$ {item}'=='$ {element}' | $ {}指数 | ||
| $ {指数=} | 设置变量 | $ {index + 1} | ||
| 从关键字返回 | $ { - 1} | #也可以用[返回] |
注意
无论返回从关键字和返回从关键字如果 是可用的,因为机器人框架2.8。
2.6.6用户关键词拆解
从Robot Framework 2.6开始,用户关键字也可能会被拆除。它是使用[Teardown]设置定义的。
关键词teardown的工作方式与测试用例拆解相同。最重要的是,拆卸总是一个关键字,虽然它可以是另一个用户关键字,当用户关键字失败时也会被执行。另外,即使其中一个失败,拆解的所有步骤也会执行。但是,关键字拆解失败将会导致测试用例失败,并且测试中的后续步骤不会运行。作为拆解而执行的关键字的名称也可以是变量。
| 用户关键字 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 随着拆解 | 做一点事 | ||
| [拆除] | 日志 | 关键字拆解 | |
| 使用变量 | [文档] | 拆除给予 | 变量 |
| 做一点事 | |||
| [拆除] | $ {} TEARDOWN |
2.7资源和变量文件
测试用例文件和测试套件初始化文件中的用户关键字和变量只能在创建它们的文件中使用,但资源文件提供了共享它们的机制。由于资源文件结构非常接近测试用例文件,所以很容易创建它们。
变量文件提供了创建和共享变量的强大机制。例如,它们允许字符串以外的值动态创建变量。它们的灵活性来源于它们是使用Python代码创建的,这也使得它们比变量表更复杂一些。
- 2.7.1资源文件
- 使用资源文件
- 资源文件结构
- 记录资源文件
- 示例资源文件
- 2.7.2变量文件
- 把变量文件投入使用
- 直接创建变量
- 从特殊功能获取变量
- 将变量文件实现为Python或Java类
2.7.1资源文件
使用资源文件
资源文件使用“ 设置”表中的“ 资源”设置导入。设置名称后面的单元格中给出了资源文件的路径。
如果路径以绝对格式给出,则直接使用。在其他情况下,首先相对于导入文件所在的目录搜索资源文件。如果没有找到文件,则从PYTHONPATH的目录中搜索。路径可以包含变量,建议使用它们使路径与系统无关(例如,$ {RESOURCES} /login_resources.html或 $ {RESOURCE_PATH})。此外,/路径中的斜杠()会自动更改为Windows上的反斜杠(\)。
| 设置 | 值 | 值 |
|---|---|---|
| 资源 | myresources.html | |
| 资源 | ../data/resources.html | |
| 资源 | $ {}资源/common.tsv |
资源文件中定义的用户关键字和变量在使用该资源文件的文件中可用。类似地可用的也是来自由所述资源文件导入的库,资源文件和变量文件的所有关键字和变量。
资源文件结构
否则,资源文件的更高级别的结构与测试用例文件的结构相同,但是当然,它们不能包含测试用例表。另外,资源文件中的设置表只能包含导入设置(库,资源, 变量)和文档。变量表和关键字表的使用方式与测试用例文件完全相同。
如果多个资源文件具有相同名称的用户关键字,则必须使用它们,以便关键字名称前面带有不带扩展名的资源文件名(例如,myresources.Some Keyword和common.Some Keyword)。而且,如果多个资源文件包含相同的变量,则首先导入的文件被使用。
记录资源文件
在资源文件中创建的关键字可以使用 [文档]设置进行记录。从Robot Framework 2.1开始,资源文件本身可以在设置表中具有与测试套件相似的文档。
无论libdoc和RIDE使用这些文档,和他们自然可以为任何人打开资源文件。关键字文档的第一行是在运行时记录的,否则在测试执行过程中会忽略资源文档文档。
示例资源文件
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 文档 | 一个示例资源文件 | ||
| 图书馆 | SeleniumLibrary | ||
| 资源 | $ {}资源/common.html |
| 变量 | 值 | 值 | 值 |
|---|---|---|---|
| $ {HOST} | 本地主机:7272 | ||
| $ {} LOGIN_URL | HTTP:// $ {HOST} / | ||
| $ {} WELCOME_URL | HTTP:// $ {HOST} /welcome.html | ||
| $ {} BROWSER | 火狐 |
| 关键词 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 打开登录页面 | [文档] | 打开浏览器 | 登录页面 | |
| 打开浏览器 | $ {} LOGIN_URL | $ {} BROWSER | ||
| 标题应该是 | 登录页面 | |||
| 输入名称 | [参数] | $ {NAME} | ||
| 输入文本 | username_field | $ {NAME} | ||
| 输入密码 | [参数] | $ {}密码 | ||
| 输入文本 | password_field | $ {}密码 |
2.7.2变量文件
变量文件包含可以在测试数据中使用的变量。变量也可以使用变量表创建,也可以通过命令行进行设置,但变量文件允许动态创建变量,变量可以包含任何对象。
变量文件通常以Python模块的形式实现,创建变量有两种不同的方法:
- 直接创建变量
-
变量被指定为模块属性。在简单情况下,语法非常简单,不需要真正的编程。例如, 用指定的文本作为值
MY_VAR = 'my value'创建一个变量${MY_VAR}。 - 从特殊功能获取变量
-
变量文件可以有一个特殊的
get_variables(或getVariables)方法作为映射返回变量。因为该方法可以采取参数,所以这种方法非常灵活。
或者,可以将变量文件实现为 框架将实例化的Python或Java类。同样在这种情况下,可以创建变量作为属性或从一个特殊的方法获取它们。
把变量文件投入使用
设置表
所有测试数据文件都可以使用“ 设置”表中的“ 变量”设置导入变量 ,与使用“ 资源” 设置导入资源文件的方式相同 。与资源文件类似,导入变量文件的路径被认为是相对于导入文件所在的目录,如果没有找到,则从PYTHONPATH中的目录中搜索。该路径也可以包含变量,并在Windows上将斜杠转换为反斜杠。如果参数文件带有参数,则它们在路径之后的单元格中指定,并且它们也可以包含变量。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 变量 | myvariables.py | ||
| 变量 | ../data/variables.py | ||
| 变量 | $ {}资源/common.py | ||
| 变量 | taking_arguments.py | ARG1 | $ {ARG2} |
来自变量文件的所有变量都可以在导入它的测试数据文件中找到。如果导入了多个变量文件并且它们包含一个名称相同的变量,则最早导入的文件中的文件将被使用。另外,变量表中创建的变量和从命令行设置的变量会覆盖变量文件中的变量。
命令行
使变量文件变为可用的另一种方法是使用命令行选项 --variablefile。变量文件使用它们的路径引用,可能的参数用冒号(:)连接到路径:
--variablefile myvariables.py--variablefile path / variables.py--variablefile /absolute/path/common.py--variablefile taking_arguments.py:arg1:arg2
从Robot Framework 2.8.2开始,从命令行使用的变量文件也会从PYTHONPATH中搜索,类似于在设置表中导入的变量文件。
这些变量文件中的变量在全部测试数据文件中是全局可用的,与用--variable选项设置的 单个变量类似。如果同时使用了--variablefile和 --variable选项,并且有相同名称的变量,则使用--variable选项单独设置的 选项优先。
直接创建变量
基本的语法
当变量文件被使用时,它们被导入为Python模块,并且所有不以下划线(_)开头的全局属性被认为是变量。因为变量名是不区分大小写的,所以大小写都是可能的,但是一般情况下,大写字母被推荐用于全局变量和属性。
VARIABLE = “一个示例字符串” ANOTHER_VARIABLE = “这很简单!” INTEGER = 42 STRINGS = [ “one” , “two” , “kolme” , “four” ] NUMBERS = [ 1 , INTEGER , 3.14 ]
在上面的例子中,变量${VARIABLE}, ${ANOTHER VARIABLE}等,被创建。前两个变量是字符串,第三个是整数,后两个是列表。所有这些变量都是标量变量,即使是包含列表值的变量。要创建列表变量,变量名称必须以前缀LIST__(注意两个下划线)。
LIST__STRINGS = [ “list” , “of” , “strings” ] LIST__MIXED = [ “first value” , - 1.1 , None , True ]
上面两个例子中的变量都可以使用下面的变量表创建。
| 变量 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|
| $ {}变量 | 一个示例字符串 | |||
| $ {} ANOTHER_VARIABLE | 这很容易! | |||
| $ {整数} | $ {42} | |||
| $ {} STRINGS | 一 | 二 | kolme | 四 |
| $ {}号码 | $ {1} | $ {整数} | $ {} 3.14 | |
| @ {} STRINGS | 名单 | 的 | 字符串 | |
| @ {}混合 | 第一价值 | $ { - 1.1} | $ {}无 | $ {TRUE} |
注意
变量不会被变量文件中的字符串替换。例如,无论变量是否 存在,VAR = "an ${example}"都将创建${VAR}一个字符串值的 an ${example}变量${example}。
使用对象作为值
变量文件中的变量并不局限于像变量表一样只有字符串或其他基本类型。相反,他们的变量可以包含任何对象。在下面的例子中,变量 ${MAPPING}包含一个带有两个值的Java Hashtable(这个例子只在Jython上运行测试时才起作用)。
从 java.util import HashtableMAPPING = Hashtable ()映射。放(“一” , 1 )映射。把(“两” , 2 )
第二个示例创建${MAPPING}为Python字典,同时还有两个由在同一个文件中实现的自定义对象创建的变量。
MAPPING = { 'one' : 1 , 'two' : 2 }class MyObject : def __init__ (self , name ): self 。name = nameOBJ1 = MyObject ('John' )OBJ2 = MyObject ('Jane' )
动态创建变量
由于变量文件是使用真正的编程语言创建的,因此它们可以具有用于设置变量的动态逻辑。
导入 os 导入 随机导入 时间USER = os 。getlogin () #当前登录名RANDOM_INT = random 。randint (0 , 10 ) 在范围#随机整数[0,10] CURRENT_TIME = 时间。asctime () #时间戳像“星期四4月6日12点45分21秒2006年” 如果 时间。localtime ()[ 3 ] > 12 : AFTERNOON = True else : AFTERNOON = False
上面的例子使用标准的Python库来设置不同的变量,但是您可以使用自己的代码来构造这些值。下面的例子说明了这个概念,但是类似地,你的代码可以从数据库中读取数据,从外部文件中读取数据,甚至可以从用户那里获取数据。
导入 数学def get_area (直径): 半径 = 直径 / 2 面积 = 数学。pi * 半径 * 半径 返回 区域AREA1 = get_area (1 )AREA2 = get_area (2 )
选择包含哪些变量
当Robot Framework处理变量文件时,所有不以下划线开头的属性都是变量。这意味着即使在变量文件中创建的或从别处导入的函数或类也被认为是变量。例如,上例中会包含变量${math} 和${get_area}除了${AREA1}和 ${AREA2}。
通常情况下,额外的变量不会导致问题,但可以覆盖其他一些变量,导致难以调试的错误。忽略其他属性的一种可能性是用下划线作为前缀:
将 数学 作为 _math 导入def _get_area (直径): 半径 = 直径 / 2.0 面积 = _math 。pi * 半径 * 半径 返回 区域AREA1 = _get_area (1 )AREA2 = _get_area (2 )
如果存在大量的其他属性,而不是将它们全部前缀,那么使用特殊属性__all__并给它一个属性名称列表以作为变量进行处理往往更容易 。
导入 数学__all__ = [ 'AREA1' , 'AREA2' ]def get_area (直径): 半径 = 直径 / 2.0 面积 = 数学。pi * 半径 * 半径 返回 区域AREA1 = get_area (1 )AREA2 = get_area (2 )
注意
该__all__属性也是最初由Python用来决定在使用语法时要导入哪些属性from modulename import *。
从特殊功能获取变量
获取变量的另一种方法是在变量文件中使用一个特殊的 get_variables函数(也getVariables可能是camelCase语法 )。如果存在这样的函数,Robot Framework会调用它,并期望以Map变量名作为键和变量值作为值接收变量作为Python字典或Java 。变量被认为是标量,除非用前缀LIST__,值可以包含任何东西。下面的例子在功能上与上面直接创建变量的第一个例子相同 。
def get_variables (): variables = { “VARIABLE” : “一个字符串示例” , “ANOTHER_VARIABLE” : “这很容易!, “INTEGER” : 42 , “字符串” : [ “一” , “二” , “kolme” ,“ 四” ], “ 数字” : [ 1 , 42 , 3.14 ], “LIST__STRINGS” : [ “列表” , “的” : [ “first value” , - 1.1 , None , True ]} 返回 变量
get_variables也可以采取参数,这有利于改变实际创建的变量。该函数的参数设置与Python函数的其他参数一样。当在测试数据中使用变量文件时,变量文件的路径之后的单元格中指定了参数,而在命令行中,它们用冒号与路径分隔。
下面的虚拟示例显示了如何使用变量文件的参数。在更现实的例子中,参数可以是到外部文本文件或数据库读取变量的路径。
variables1 = { '的标量' : '标量变量' , 'LIST__list' : [ '列表' ,'可变' ]} variables2 = { '的标量' : '某些其他值' , 'LIST__list' : [ '某些' ,“其它' ,'value' ], 'extra' : 'variables1根本就没有这个' }def get_variables (arg ): 如果 arg == 'one' : return variables1 else : return variables2
将变量文件实现为Python或Java类
从Robot Framework 2.7开始,可以将变量文件实现为Python或Java类。
履行
因为变量文件总是使用文件系统路径导入,所以将它们创建为类有一些限制:
- Python类必须与它们所在的模块具有相同的名称。
- Java类必须存在于默认包中。
- Java类的路径必须以.java或.class结尾。在两种情况下都必须存在类文件。
无论实现语言如何,框架都将使用无参数来创建类的实例,变量将从实例中获取。与模块类似,变量可以直接在实例中定义为属性,也可以从特殊get_variables (或getVariables)方法中获取。
当变量直接在实例中定义时,将忽略包含可调用值的所有属性,以避免实例具有的可能方法创建变量。如果您确实需要可调用变量,则需要使用其他方法来创建可变文件。
例子
第一个示例使用Python和Java从属性创建变量。他们都创建变量${VARIABLE},@{LIST}从类属性和${ANOTHER VARIABLE}实例属性。
类 StaticPythonExample (对象): 变量 = '值' LIST__list = [ 1 , 2 , 3 ] _not_variable = '以下划线开始' def __init__ (self ): self 。another_variable = '另一个值'
公共 类 StaticJavaExample { 公共 静态 字符串 变量 = “值” ; 公共 静态 字符串[] LIST__list = { 1 , 2 , 3 }; private String notVariable = “is private” ; public String anotherVariable ; public StaticJavaExample () { anotherVariable = “another value” ; } }
第二个例子使用动态方法获取变量。他们两个只创建一个变量${DYNAMIC VARIABLE}。
类 DynamicPythonExample (object ): def get_variables (self , * args ): return { 'dynamic variable' : '' 。join (args )}
import java.util.Map ; import java.util.HashMap ;公共 类 DynamicJavaExample { 公共 Map < String , String > getVariables (String arg1 , String arg2 ) { HashMap < String , String > variables = new HashMap < String , String >(); 变量。put (“dynamic variable” , arg1 + “” + arg2 ); 返回 变量; } }
2.8高级功能
- 2.8.1处理同名的关键字
- 关键字范围
- 明确指定关键字
- 指定库和资源之间的显式优先级
- 2.8.2超时
- 测试用例超时
- 用户关键字超时
- 2.8.3 For循环
- 正常循环
- 使用几个循环变量
- 在范围内
- 退出循环
- 继续循环
- 从输出中删除不必要的关键字
- 重复单个关键字
- 2.8.4有条件执行
- 2.8.5并行执行关键字
2.8.1处理同名的关键字
Robot Framework使用的关键词是库关键字或用户关键字。前者来自标准库或外部库,而后者则使用相同的文件创建,然后从资源文件导入 。在使用多个关键字的情况下,通常有一些关键字具有相同的名称,本节将介绍如何处理这些情况下可能发生的冲突。
关键字范围
如果仅使用关键字名称,并且有多个关键字具有该名称,则Robot Framework将根据其范围尝试确定哪个关键字具有最高优先级。关键字的范围是根据创建关键字的方式确定的:
- 在使用该文件的同一文件中作为用户关键字创建。这些关键字具有最高的优先级,并且始终使用它们,即使其他关键字具有相同的名称也是如此。
- 在资源文件中创建,并直接或间接从另一个资源文件导入。这是第二高优先级。
- 在外部测试库中创建。如果不存在具有相同名称的用户关键字,则使用这些关键字。但是,如果标准库中有同名的关键字,则会显示警告。
- 在标准库中创建。这些关键字的优先级最低。
明确指定关键字
单独使用范围并不是一个足够的解决方案,因为在几个库或资源中可以有相同名称的关键字,因此它们提供了一种机制,只使用最高优先级的关键字。在这种情况下,可以使用关键字的全名,其中关键字名称以资源或库的名称作为前缀,而点是分隔符。
使用库关键字,长格式意味着只使用格式库名称。关键字 名称。例如,关键字运行 从OperatingSystem的库可作为 OperatingSystem.Run,即使有另一个运行 关键字别处。如果库位于模块或包中,则必须使用完整的模块或包名称(例如 com.company.Library.Some关键字)。如果使用WITH NAME语法将自定义名称赋予库,则必须在完整的关键字名称中使用指定的名称。
资源文件在完整的关键字名称中指定,类似于库名称。资源的名称是从没有文件扩展名的资源文件的基本名称派生的。例如,资源文件myresources.html中的关键字Example可以用作myresources.Example。请注意,如果多个资源文件具有相同的基本名称,则此语法不起作用。在这种情况下,文件或关键字必须重命名。关键字的全名不区分大小写,空格和下划线,与普通关键字名称类似。
指定库和资源之间的显式优先级
如果关键字之间存在多个冲突,那么以长格式指定所有关键字可能是相当多的工作。使用长格式还会导致无法创建动态测试用例或用户关键字,这些关键字的工作方式会有所不同,具体取决于可用的库或资源。一种解决这两个问题被明确指定使用关键字的关键字的优先级 设置库搜索顺序从内建库。
注意
尽管关键字的名称中包含单词库,但它也适用于从Robot Framework 2.6.2开始的资源文件。如上所述,尽管资源中的关键字总是比库中的关键字具有更高的优先级。
该设置库搜索顺序接受一个有序列表或库和资源作为参数。当测试数据中的关键字名称与多个关键字匹配时,将选择包含该关键字的第一个库或资源,并使用该关键字实现。如果未从任何指定的库或资源中找到关键字,则与未设置搜索顺序时相同的方式执行失败。
有关更多信息和示例,请参阅关键字的文档。
2.8.2超时
在这些情况下,关键字可能会出现问题,因为它们需要特别长时间才能执行或者无休止地运行。Robot Framework允许您为测试用例和用户关键字设置超时,如果测试或关键字在指定的时间内没有完成,那么当前正在执行的关键字会被强制停止。以这种方式停止关键字可能会使库或系统处于不稳定状态,只有当没有可用的安全选项时才建议超时。一般来说,应该实现库,以便关键字不会挂起,或者如果有必要,它们有自己的超时机制。
测试用例超时
测试用例超时可以通过使用设置表中的测试超时设置或测试用例表中的[超时] 设置来设置。测试超时的设置表定义了所有的测试用例的测试套件默认测试超时值,而[超时]在测试用例表适用超时到一个单独的测试案例和覆盖可能的默认值。
使用一个空的[Timeout]意味着即使使用Test Timeout,测试也没有超时。从Robot Framework 2.5.6开始,也可以为此使用值NONE。
无论定义测试超时的位置如何,设置名称后的第一个单元格都包含超时的持续时间。持续时间必须以“机器人框架”的时间格式给出,也就是直接以秒为单位或以像1 minute 30 seconds。必须注意的是,框架总是会有一些开销,因此不推荐超过一秒的超时。
发生测试超时时显示的默认错误消息是 Test timeout 。也可以使用自定义错误消息,并在超时时间后将这些消息写入单元。该消息可以拆分成多个单元格,类似于文档。超时值和错误消息都可能包含变量。
如果发生超时,则在超时到期时停止运行关键字,并且测试用例失败。但是,当测试超时发生时,作为测试拆卸执行的关键字不会被中断,因为它们通常从事重要的清理活动。如有必要,也可以用用户关键字超时中断这些关键字。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 测试超时 | 2分钟 |
| 测试用例 | 行动 | 论据 | 论据 | 论据 |
|---|---|---|---|---|
| 默认超时 | [文档] | 使用设置表中的超时 | ||
| 一些关键字 | 论据 | |||
| 覆盖 | [文档] | 覆盖默认值,使用10秒超时 | ||
| [时间到] | 10 | |||
| 一些关键字 | 论据 | |||
| 自定义消息 | [文档] | 覆盖默认值并使用自定义消息 | ||
| [时间到] | 1分10秒 | 这是我的自定义错误。 | 它继续在这里。 | |
| 一些关键字 | 论据 | |||
| 变量 | [文档] | 也可以使用变量 | ||
| [时间到] | $ {} TIMEOUT | |||
| 一些关键字 | 论据 | |||
| 没有超时 | [文档] | 空超时意味着即使在没有超时时 | 测试超时已被使用 | |
| [时间到] | ||||
| 一些关键字 | 论据 | |||
| 没有超时2 | [文档] | 空的超时使用无,使用 | 2.5.6 | |
| [时间到] | 没有 | |||
| 一些关键字 | 论据 |
用户关键字超时
可以使用 关键字表中的[超时]设置为用户关键字设置超时。包括如何给出超时值和可能的自定义消息的设置语法与测试用例超时使用的语法相同。如果未提供自定义消息,Keyword timeout 则在发生超时时使用默认错误消息。
| 关键词 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 计时关键字 | [文档] | 只设置超时值 | 而不是自定义消息。 |
| [时间到] | 1分42秒 | ||
| 做一点事 | |||
| 做其他事情 | |||
| 超时包装 | [参数] | @ {} ARGS | |
| [文档] | 这个关键字是一个包装 | 这会给另一个关键字增加一个超时。 | |
| [时间到] | 2分钟 | 原始关键字没有在2分钟内完成 | |
| 原始关键字 | @ {} ARGS |
用户关键字超时在执行该用户关键字时适用。如果整个关键字的总时间大于超时值,则停止当前执行的关键字。用户关键字超时也适用于测试用例拆解期间,而测试超时则不适用。
如果测试用例和它的一些关键字(或者几个嵌套的关键字)都有一个超时,那么活动超时是剩下最少的时间。
警告
在其他地方使用Python 2.5时,使用超时可能会减慢测试的执行速度。在Robot Framework 2.7超时之前,所有平台上的所有Python版本都会减慢执行速度。
2.8.3 For循环
在测试自动化中多次重复相同的动作是相当常见的需求。使用Robot Framework,测试库可以具有任何类型的循环结构,并且大部分时间循环都应该在其中实现。Robot Framework也有它自己的循环语法,例如,当需要重复来自不同库的关键字时,它是有用的。
for循环可以用于测试用例和用户关键字。除了非常简单的情况外,用户关键字更好,因为它们隐藏了for循环引入的复杂性。循环语法的基本语法 FOR item IN sequence是从Python派生而来,但在shell脚本或Perl中也可能有类似的语法。
正常循环
在正常循环中,一个变量是从一个值列表中分配的,每个迭代一个值。语法开始于:FOR,其中需要冒号来将语法从普通关键字中分离出来。下一个单元格包含循环变量,后续单元格必须有 IN,最后的单元格包含要迭代的值。这些值可以包含变量,包括列表变量。
for循环中使用的关键字位于下一行,它们必须向右缩进一个单元格。for循环结束时,缩进返回到正常或表结束。直接嵌套for循环不受支持,但可以在for循环中使用一个用户关键字,并在那里有另一个for循环。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 参数 |
|---|---|---|---|---|---|
| 例1 | :对于 | $ {}动物 | 在 | 猫 | 狗 |
| 日志 | $ {}动物 | ||||
| 日志 | 第二关键字 | ||||
| 日志 | 外循环 | ||||
| 例2 | :对于 | $ {VAR} | 在 | 一 | 二 |
| ... | $ {3} | 四 | $ {}最后 | ||
| 日志 | $ {VAR} |
上面例1中的for循环被执行两次,所以首先循环变量${animal}有值cat,然后 dog。该循环由两个Log关键字组成。在第二个例子中,循环值被分成两行,循环共运行五次。
小费
如果以纯文本格式文件使用循环,请记住 使用反斜杠转义缩进的单元格:
*** 测试用例 ***例1 :对于$ { 动物}在 猫的狗 \ Log $ { animal } \ Log 第二个关键字 记录外部循环
使用带有列表变量的循环通常很方便。下面的例子说明了这一点,其中@{ELEMENTS}包含一个任意长的元素列表,并且关键字Start Element与它们一一对应。也可以通过使用列表变量来遍历包含列表的标量变量的值。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 参数 |
|---|---|---|---|---|---|
| 例 | :对于 | $ {}元素 | 在 | @ {} ELEMENTS | |
| 开始元素 | $ {}元素 |
使用几个循环变量
也可以使用几个循环变量。语法与正常for循环相同,但所有循环变量都列在FOR和IN之间的单元格中。可以有任意数量的循环变量,但是数值的数量必须能够被变量的数量平分。
如果有很多值要迭代,那么在循环变量下面组织它们通常是很方便的,如下例的第一个循环所示:
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 参数 |
|---|---|---|---|---|---|
| 例 | :对于 | $ {}指数 | $ {}英语 | $ {}芬兰 | 在 |
| ... | 1 | 猫 | kissa | ||
| ... | 2 | 狗 | koira | ||
| ... | 3 | 马 | hevonen | ||
| 做X | $ {}英语 | ||||
| Y应该是 | $ {}芬兰 | $ {}指数 | |||
| :对于 | $ {NAME} | $ {ID} | 在 | @{雇主} | |
| 创建 | $ {NAME} | $ {ID} |
在范围内
早期的for循环总是迭代一个序列,这也是最常见的用例。有时,执行一定次数的for循环仍然很方便,Robot Framework FOR index IN RANGE limit为此具有特殊的语法。这个语法来源于类似的Python成语。
与其他for循环类似,for范围循环以:FOR开头, 循环变量在下一个单元格中。在这种格式中,只能有一个循环变量,它包含当前的循环索引。下一个单元格必须包含IN RANGE和后续的单元格循环限制。
在最简单的情况下,只指定循环的上限。在这种情况下,循环索引从零开始并增加1,直到但不包括限制。也可以给出开始和结束限制。然后索引从开始限制开始,但与简单情况相似地增加。最后,还可以给出指定要使用的增量的步长值。如果步骤是否定的,则用作递减。
从Robot Framework 2.5.5开始,可以使用简单的算术运算,如范围限制的加减法。当限制用变量指定时,这是特别有用的。
| 测试用例 | 行动 | 论据 | 论据 | 精氨酸 | 精氨酸 | 精氨酸 |
|---|---|---|---|---|---|---|
| 只有上限 | [文档] | 循环 | 值 | 从0开始 | 到9 | |
| :对于 | $ {}指数 | 在范围内 | 10 | |||
| 日志 | $ {}指数 | |||||
| 开始和结束 | [文档] | 循环 | 值 | 从1 | 到10 | |
| :对于 | $ {}指数 | 在范围内 | 1 | 11 | ||
| 日志 | $ {}指数 | |||||
| 也给一步 | [文档] | 循环 | 值 | 5,15, | 和25 | |
| :对于 | $ {}指数 | 在范围内 | 五 | 26 | 10 | |
| 日志 | $ {}指数 | |||||
| 消极的一步 | [文档] | 循环 | 值 | 13,3, | 和-7 | |
| :对于 | $ {}指数 | 在范围内 | 13 | -13 | -10 | |
| 日志 | $ {}指数 | |||||
| 算术 | [文档] | 算术 | 同 | 变量 | ||
| :对于 | $ {}指数 | 在范围内 | $ {VAR} +1 | |||
| 日志 | $ {}指数 |
退出循环
通常情况下,循环会被执行,直到所有的循环值被迭代或循环内使用的关键字失败。如果需要更早地 退出循环, 则可以使用BuiltIn关键字Exit For Loop和Exit For Loop If来完成此操作。它们break 在Python,Java和许多其他编程语言中的工作方式类似。
退出For循环和退出For循环如果关键字可以直接在for循环中或循环使用的关键字中使用。在这两种情况下,循环后测试执行都会继续。在for循环之外使用这些关键字是错误的。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 论据 |
|---|---|---|---|---|---|
| 退出示例 | $ {}文本= | 设置变量 | $ {EMPTY} | ||
| :对于 | $ {VAR} | 在 | 一 | 二 | |
| 运行关键字如果 | '$ {var}'=='two' | 退出循环 | |||
| $ {}文本= | 设置变量 | $ {文本} $ {VAR} | |||
| 应该是平等的 | $ {}文 | 一 |
在上面的例子中,可以使用Exit For Loop If 而不是使用Exit For Loop和Run关键字If来运行。有关这些关键字的更多信息(包括更多使用示例),请参阅BuiltIn库中的文档。
注意
Exit For Loop关键字添加了Robot Framework 2.5.2和 Exit For Loop如果在2.8中。
继续循环
除了提前退出for循环之外,还可以在所有关键字执行之前继续执行循环的下一次迭代。这可以使用BuiltIn关键字Continue For Loop 和Continue For Loop来完成。如果continue在许多编程语言中工作得像语句一样。
继续For循环并继续循环如果关键字可以直接在for循环或循环使用的关键字中使用。在这两种情况下,该迭代中的关键字的其余部分都会被跳过,并继续执行下一次迭代。如果在最后一次迭代中使用这些关键字,则在循环之后继续执行。在for循环之外使用这些关键字是错误的。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 论据 | 论据 |
|---|---|---|---|---|---|---|
| 继续例子 | $ {}文本= | 设置变量 | $ {EMPTY} | |||
| :对于 | $ {VAR} | 在 | 一 | 二 | 三 | |
| 继续循环如果 | '$ {var}'=='two' | |||||
| $ {text} = | 设置变量 | $ {文本} $ {VAR} | ||||
| 应该是平等的 | $ {}文 | onethree |
有关这些关键字的更多信息(包括使用示例),请参阅BuiltIn库中的文档。
注意
双方继续循环和持续循环如果 在机器人框架2.8的溶液。
从输出中删除不必要的关键字
对于具有多次迭代的循环来说,通常会创建大量的输出并显着增加生成的输出和日志文件的大小。从Robot Framework 2.7开始,可以使用--RemoveKeywords FOR命令行选项从输出中删除不必要的关键字。
重复单个关键字
对于仅需要重复单个关键字的情况,For循环可能过度。在这些情况下,使用BuiltIn关键字重复关键字往往更容易 。这个关键字需要一个关键字和多少次重复作为参数。重复关键字的时间可以有一个可选的后缀times或x 使语法更易于阅读。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 论据 |
|---|---|---|---|---|---|
| 例 | 重复关键字 | 五 | 一些关键字 | ARG1 | ARG2 |
| 重复关键字 | 42次 | 我的关键字 | |||
| 重复关键字 | $ {VAR} | 另一个KW | 论据 |
Robot Framework也有一个特殊的语法来重复一个关键字。这个语法在2.0.4版本中已被弃用, 而被重复使用,并在2.5版本中被删除。
2.8.4有条件执行
一般来说,不建议在测试用例中甚至用户关键字中使用条件逻辑,因为这会使得它们难以理解和维护。相反,这种逻辑应该在测试库中,在那里它可以用自然的编程语言结构来实现。然而,有些条件逻辑有时候会很有用,即使Robot Framework没有实际的if / else结构,也有几种方法可以得到相同的结果。
- 可以使用变量指定用作测试用例和测试套件的设置或拆卸的关键字的名称。这有助于改变它们,例如,从命令行。
- 该内建关键字运行关键字取关键词来实际执行作为参数,因此它可以是一个变量。例如,变量的值可以从早期的关键字动态获得,或者从命令行获得。
- 在内置的关键字投放关键字如果和运行关键字除非执行一个名为关键字只有当某个表达式分别是真还是假。它们非常适合创建简单的if / else结构。有关示例,请参阅前者的文档。
- 另一个BuiltIn关键字Set Variable If可以用来根据给定的表达式动态地设置变量。
- 有几个BuiltIn关键字只有在测试用例或测试套件失败或通过时才允许执行一个named关键字。
2.8.5并行执行关键字
在2.5版本之前,Robot Framework具有并行执行关键字的特殊语法。此功能被删除,因为它很少使用,它从来没有完全工作。
当需要并行执行时,必须在测试库级执行,以便库在后台执行代码。通常,这意味着库需要一个关键字,例如Start Something来启动执行并立即返回,另一个关键字如 Get Results From Something等到结果可用并返回。有关示例,请参阅OperatingSystem库关键字“ 启动进程” 和“ 读取进程输出 ”。
3执行测试用例
- 3.1基本用法
- 3.2测试执行
- 3.3后处理输出
- 3.4配置执行
- 3.5创建输出
3.1基本用法
Robot Framework测试用例是从命令行执行的,最终的结果是默认情况下是XML格式的输出文件和HTML 报告和日志。执行完成后,可以将输出文件合并在一起,或者使用反弹工具进行后期处理。
- 3.1.1开始测试执行
- 概要
- 指定要执行的测试数据
- 3.1.2使用命令行选项
- 使用选项
- 短期和长期的选择
- 设置选项值
- 简单的模式
- 标签模式
- ROBOT_OPTIONS和REBOT_OPTIONS环境变量
- 3.1.3测试结果
- 命令行输出
- 生成的输出文件
- 返回码
- 执行期间的错误和警告
- 3.1.4转义复杂的字符
- 3.1.5参数文件
- 参数文件语法
- 使用参数文件
- 从标准输入读取参数文件
- 3.1.6获取帮助和版本信息
- 3.1.7创建启动脚本
- 修改Java启动参数
- 3.1.8调试问题
- 使用Python调试器(pdb)
3.1.1开始测试执行
概要
pybot | jybot | ipybot [options] data_sourcespython | jython | ipy -m robot.run [options] data_sourcespython | jython | ipy path / to / robot / run.py [options] data_sourcesjava -jar robotframework.jar [options] data_sources
测试执行通常使用pybot,jybot 或ipybot runner脚本启动。这些脚本在其他方面是相同的,但是第一个使用Python执行测试,第二个使用Jython,最后一个使用IronPython。或者,可以使用 robot.run 入口点作为模块或使用任何解释器的脚本,也可以使用独立的JAR分发。
无论执行方式如何,要执行的测试数据的路径(或多个路径)在命令之后作为参数给出。此外,可以使用不同的命令行选项以某种方式更改测试执行或生成的输出。
指定要执行的测试数据
Robot Framework测试用例是在文件和目录中创建的,并且通过将所讨论的文件或目录的路径提供给选定的运行器脚本来执行。路径可以是绝对的,或者更常见的是相对于执行测试的目录。给定的文件或目录创建顶级测试套件,它得到它的名字,除非与覆盖--name选项,从文件或目录名。下面的例子说明了不同的执行可能性。请注意,在这些例子中,以及本节中的其他例子中,只使用了pybot脚本,但是其他的执行方法也可以类似地使用。
pybot test_cases.htmlpybot路径/ to / my_tests /pybot c:\ robot \ tests.txt
也可以一次给几个测试用例文件或目录的路径,用空格分隔。在这种情况下,Robot Framework自动创建顶级测试套件,指定的文件和目录成为其子测试套件。创建的测试套件的名称是通过将它们与&符号(&)和空格连接在一起从子套件名称获得的。例如,下面第一个示例中的顶级套件的名称是“ 我的测试和您的测试”。这些自动创建的名称通常非常长且复杂。在大多数情况下,最好使用--name选项来覆盖它,如下面的第二个例子所示:
pybot my_tests.html your_tests.htmlpybot --name示例路径/ to / tests / pattern _ *。html
3.1.2使用命令行选项
Robot Framework提供了许多命令行选项,可以用来控制测试用例如何执行以及生成什么输出。本节介绍选项语法,以及实际存在的选项。在本章其他地方讨论它们如何使用。
使用选项
如果使用选项,则必须始终在运行程序脚本和数据源之间提供选项。例如:
pybot -L调试my_tests.txtpybot --include smoke --variable HOST:10.0.0.42 path / to / tests /
短期和长期的选择
选项总是有一个很长的名字,比如--name,最常用的选项也有一个简短的名字,比如 -N。除此之外,长期选项只要是唯一的,就可以缩短。例如,--logle DEBUG作品虽然--lo log.html没有,因为前者只匹配 --loglevel,但后者匹配了几个选项。在手动执行测试用例时,缩短和缩短选项是实用的,但在启动脚本中建议使用较长的选项,因为它们更容易理解。
长选项格式是不区分大小写的,这便于以易于阅读的格式书写选项名称。例如,--SuiteStatLevel 相当于,但比更易于阅读--suitestatlevel。
设置选项值
大多数选项都需要在选项名称后面给出的值。短期和长期的选项都接受与选项名称分隔的值,如在--include tag 或中-i tag。如果选项较长,分隔符也可以是等号,如果--include=tag选项较短,则可以省略分隔符-itag。
有些选项可以多次指定。例如, --variable VAR1:value --variable VAR2:another设置两个变量。如果多次使用只有一个值的选项,则最后给出的值是有效的。
简单的模式
许多命令行选项都将参数作为简单模式。这些 像glob的图案按照以下规则进行匹配:
*是一个匹配任何字符串的通配符,甚至是一个空字符串。?是匹配任何单个字符的通配符。- 除非另有说明,否则模式匹配是大小写,空格和下划线不敏感的。
例子:
--test示例*#不区分大小写,匹配名称以“Example”开始的测试。- 包括f ?? #匹配以“f”或“F”开头且长度为三个字符的标签进行测试。
标签模式
大多数标签相关选项接受参数作为标记的图案。他们都相同的特征简单的模式,但他们也支持AND, OR和NOT运营商解释如下。这些运算符可用于将两个或更多个别标签或模式组合在一起。
-
AND要么& -
如果所有个体模式匹配,则整个模式匹配。
AND并且&是等同的。--include fooANDbar#匹配包含标签“foo”和“bar”的测试。--exclude xx&yy&zz#匹配包含标签'xx','yy'和'zz'的测试。
-
OR -
整个模式匹配,如果任何个人模式匹配。
--include fooORbar#匹配包含标签“foo”或标签“bar”的测试。- 排除xxORyyORzz#匹配包含任何标签“xx”,“yy”或“zz”的测试。
-
NOT -
如果左侧的图案匹配,但是右侧的图案不匹配,则整个图案匹配。如果多次使用,则第一个之后的模式都
NOT不能匹配。--include fooNOTbar#匹配包含标记“foo”但不标记“bar”的测试。--exclude xxNOTyyNOTzz#匹配包含标签'xx'但不包含标签'yy'或标签'zz'的测试。
- 杂
-
上述运营商也可以一起使用。运算符优先级,从最高到最低,是
AND,OR和NOT。--include xANDyORz#匹配包含标签'x'和'y'或标签'z'的测试。--include xORyNOTz#匹配包含标记“x”或“y”但不标记“z”的测试。--include xNOTyANDz#匹配包含标签“x”但不包含标签“y”和“z”的测试。
注意
所有操作员都区分大小写,并且必须用大写字母来书写。
注意
OR 运营商是Robot Framework 2.8.4中的新成员。
ROBOT_OPTIONS和REBOT_OPTIONS环境变量
环境变量ROBOT_OPTIONS和REBOT_OPTIONS可分别用于指定测试执行和结果后处理的默认选项。选项及其值必须定义为空格分隔的列表,并且它们放置在命令行上任何显式选项的前面。这些环境变量的主要用例是为某些选项设置全局默认值,以避免每次运行测试或使用重复使用时都需要重复这些值。
export ROBOT_OPTIONS = “--critical regression --tagdoc mytag:Example_doc”pybot tests.txt导出REBOT_OPTIONS = “--reportbackground绿色:黄色:红色”rebot --name示例output.xml
注意
在Robot Framework 2.8.2中增加了对ROBOT_OPTIONS和REBOT_OPTIONS环境变量的支持。
3.1.3测试结果
命令行输出
测试执行最显着的输出是显示在命令行中的输出。所有执行的测试套件和测试用例以及它们的状态都会实时显示在那里。下面的例子显示了执行一个简单的测试套件的输出只有两个测试用例:
================================================== ============================示例测试套件================================================== ============================第一次测试::可能的测试文档| PASS |-------------------------------------------------- ----------------------------第二个测试| 失败|错误消息显示在这里================================================== ============================示例测试套件| 失败|2个关键测试,1个通过,1个失败总共2次测试,1次合格,1次失败================================================== ============================输出:/path/to/output.xml报告:/path/to/report.html日志:/path/to/log.html
从Robot Framework 2.7开始,只要测试用例中的顶级关键字结束,控制台上也会有一个通知。如果关键字通过,则使用绿点,如果失败,则使用红F。这些标记被写入到行尾,当测试本身结束时,它们被测试状态覆盖。如果控制台输出重定向到文件,则写入标记将被禁用。
生成的输出文件
命令行输出非常有限,通常需要单独的输出文件来检查测试结果。如上例所示,默认情况下生成三个输出文件。第一个是XML格式,包含所有关于测试执行的信息。第二个是更高级的报告,第三个是更详细的日志文件。这些文件和其他可能的输出文件将在“ 不同的输出文件 ”一节中详细讨论。
返回码
运行脚本将整体测试执行状态传递给使用返回代码运行的系统。当执行成功启动并且没有严重测试失败时,返回码为零。下表列出了所有可能的退货代码。
| RC | 说明 |
|---|---|
| 0 | 所有关键测试都通过了 |
| 1-249 | 返回的关键测试数量失败。 |
| 250 | 250个或更多严重故障。 |
| 251 | 帮助或版本信息打印。 |
| 252 | 无效的测试数据或命令行选项。 |
| 253 | 测试执行由用户停止。 |
| 255 | 意外的内部错误。 |
返回代码应该在执行后始终易于使用,这样可以很容易地自动确定总体执行状态。例如,在bash shell中,返回码是特殊变量$?,在Windows中是%ERRORLEVEL% 变量。如果您使用一些外部工具来运行测试,请参阅其文档以了解如何获取返回码。
从Robot Framework 2.5.7开始,即使使用--NoStatusRC命令行选项发生严重故障,也可以将返回码设置为0 。例如,在可以确定测试执行的总体状态之前需要后处理结果的持续集成服务器中,这可能是有用的。
注意
同样的返回码也用于rebot。
执行期间的错误和警告
在测试执行过程中,可能会出现意想不到的问题,例如无法导入库或资源文件或不推荐使用的关键字 。根据严重程度的不同,这些问题被分类为错误或警告,并写入控制台(使用标准错误流), 在日志文件中单独的“ 测试执行错误”部分中显示,也写入Robot Framework自己的 系统日志中。通常这些错误是由Robot Framework核心生成的,但是库可以使用日志级别的WARN来编写警告。下面的例子说明了错误和警告在日志文件中的样子。
| 20090322 19:58:42.528 | 错误 | 第2行元素表中的“设置”文件中的“/home/robot/tests.html”文件错误:资源文件“resource.html”不存在 |
| 20090322 19:58:43.931 | 警告 | 关键字“SomeLibrary.Example关键字”已被弃用。改为使用关键字“其他关键字”。 |
3.1.4转义复杂的字符
由于空格用于将选项彼此分开,所以在选项值中使用它们是有问题的。一些选项,如 --name,自动将下划线转换为空格,但是其他空格必须转义。另外,很多特殊字符在命令行上使用起来很复杂。因为用反斜杠或引用这些值来转义复杂的字符并不总是奏效,Robot Framework有它自己的通用转义机制。另一种可能性是使用参数文件,其中可以用纯文本格式指定选项。这两种机制在执行测试和后处理输出时都有效,而且一些外部支持工具具有相同或相似的功能。
在Robot Framework的命令行转义机制中,有问题的字符被自由选择的文本转义。要使用的命令行选项是--escape(-E),它采用格式的参数what:with,其中what是要转义的字符的名称,是用于转义 with的字符串。下表列出了可以转义的字符:
| 字符 | 名称使用 | 字符 | 名称使用 |
|---|---|---|---|
| & | 功放 | ( | paren1 |
| “ | 者 | ) | paren2 |
| @ | 在 | % | 百分 |
| \ | bslash | | | 管 |
| : | 结肠 | ? | 寻求 |
| , | 逗号 | “ | QUOT |
| { | curly1 | ; | SEMIC |
| } | curly2 | / | 削减 |
| $ | 美元 | 空间 | |
| ! | exclam | [ | square1 |
| > | GT | ] | square2 |
| # | 哈希 | * | 星 |
| < | LT |
以下示例使语法更清晰。在第一个示例中,元数据X获取值Value with spaces,在第二个示例中,变量${VAR}分配给 "Hello, world!":
--escape空间:_ --metadata X:Value_with_spaces-E space:SP -E quot:QU -E逗号:CO -E exclam:EX -v VAR:QUHelloCOSPworldEXQU
请注意,所有给定的命令行参数(包括测试数据的路径)都会被转义。因此需要仔细选择转义字符序列。
3.1.5参数文件
参数文件允许将全部或部分命令行选项和参数放置到外部文件中,以供读取。这可以避免在命令行上出现问题的字符问题。如果需要大量选项或参数,则参数文件也会阻止命令行上使用的命令过长。
参数文件与--argumentfile(-A)选项以及可能的其他命令行选项一起使用。
参数文件语法
参数文件可以包含命令行选项和测试数据的路径,每行一个选项或数据源。支持短期和长期期权,但建议使用后者,因为它们更容易理解。参数文件可以包含任何字符而不会转义,但行首和尾部的空格将被忽略。此外,以散列标记(#)开头的空行和行将被忽略:
--doc这是一个例子(“特殊字符”可以!)- 元数据X:带空格的值- 变量VAR:你好,世界!#这是一条评论路径/要/我的/测试
在上面的例子中,选项和它们的值之间的分隔符是单个空格。在Robot Framework 2.7.6及更新版本中,可以使用等号(=)或任意数量的空格。举例来说,以下三行是相同的:
- 一个例子--name =一个例子- 一个例子
如果参数文件包含非ASCII字符,则必须使用UTF-8编码进行保存。
使用参数文件
参数文件可以单独使用,以便它们包含测试数据的所有选项和路径,或者包含其他选项和路径。当一个参数文件和其他参数一起使用时,它的内容被放置到参数文件选项所在的相同位置的原始参数列表中。这意味着参数文件中的选项可以覆盖之前的选项,而选项之后的选项可以覆盖它们。可以多次使用--argumentfile选项,甚至可以递归使用:
pybot --argumentfile all_arguments.txtpybot --name示例--argumentfile other_options_and_paths.txtpybot --argumentfile default_options.txt --name示例my_tests.htmlpybot -A first.txt -A second.txt -A third.txt tests.txt
从标准输入读取参数文件
从Robot Framework 2.5.6开始,STDIN 可以使用特殊参数文件名从标准输入流而不是文件读取参数。这在使用脚本生成参数时非常有用:
generate_arguments.sh | pybot --argumentfile STDINgenerate_arguments.sh | pybot --name示例--argumentfile STDIN tests.txt
3.1.6获取帮助和版本信息
在执行测试用例和后处理输出时,可以通过选项--help(-h)获得命令行帮助。这些帮助文本有一个简短的概述,并简要介绍可用的命令行选项。
所有运行脚本也支持使用--version选项获取版本信息。这些信息还包含Python或Jython版本以及平台类型:
$ pybot --versionRobot Framework 2.7(linux2上的Python 2.6.6)$ jybot --versionRobot Framework 2.7(java1.6.0_21上的Jython 2.5.2)C:\> rebot --versionRebot 2.7(win32上的Python 2.7.1)
3.1.7创建启动脚本
测试用例通常由持续集成系统或其他机制自动执行。在这种情况下,需要有一个用于启动测试执行的脚本,并且还可能以某种方式为后处理输出。当手动运行测试时,类似的脚本也很有用,特别是如果需要大量的命令行选项或者设置测试环境很复杂。
在类UNIX环境中,shell脚本为创建自定义启动脚本提供了一个简单而强大的机制。Windows批处理文件也可以使用,但它们更加有限,通常也更复杂。一个独立于平台的替代方案是使用Python或其他一些高级编程语言。不管语言如何,建议使用长选项名称,因为它们比短名称更易于理解。
在第一个示例中,使用不同的浏览器执行相同的Web测试,然后将结果合并。这对于shell脚本来说很简单,因为实际上您只需要列出所需的命令:
#!/斌/庆典pybot - 变量浏览器:Firefox - 名称Firefox - 日志无 - 报告无 - 输出/ fx.xml登录pybot - 变量浏览器:IE - 名称IE - 日志无 - 报告无 - 输出/ ie.xml登录rebot --name登录--outputdir out --output login.xml out / fx.xml out / ie.xml
用Windows批处理文件实现上面的例子也不是很复杂。最重要的是要记住,因为pybot和rebot是作为批处理文件实现的,所以在从另一个批处理文件运行时必须使用call。否则,执行将在第一批文件完成时结束。
@ echo off call pybot --variable BROWSER:Firefox --name Firefox --log none --report none --output out \ fx.xml login call pybot --variable BROWSER:IE --name IE --log none -报告没有 - 输出\ ie.xml登录 调用重定向 - 名称登录--outputdir出--output login.xml出\ fx.xml出\ ie.xml
在下面的例子中,lib目录下的jar文件在开始执行测试之前被放入CLASSPATH中。在这些示例中,启动脚本要求提供执行的测试数据的路径作为参数。即使已经在脚本中设置了一些选项,也可以自由使用命令行选项。所有这些使用bash都是相当直接的:
#!/斌/庆典cp =。用于 lib / *。jar中的jar; 做cp = $ cp:$ jar done export CLASSPATH = $ cpjybot --ouputdir / tmp / logs --suitestatlevel 2 $ *
使用Windows批处理文件来实现这一点稍微复杂一些。困难的部分是在For循环中设置包含所需JAR的变量,因为某些原因,如果没有辅助函数,这是不可能的。
@ 回声 了设置 CP =。对于 %%罐子中(LIB \ * JAR)就( 叫 :set_cp %%罐子)设置 CLASSPATH = %CP%jybot --ouputdir c:\ temp \ logs --suitestatlevel 2%*goto :eof:: Helper在for循环中设置变量:set_cp set CP = %CP% ; %1 转到 :eof
修改Java启动参数
有时使用Jython时,需要更改Java启动参数。最常见的用例是增加JVM最大内存大小,因为当输出非常大时,默认值可能不足以创建报告和日志。有几种方法来配置JVM选项:
-
直接修改Jython启动脚本(jython shell脚本或 jython.bat批处理文件)。这是一个永久的配置。
-
设置JYTHON_OPTS环境变量。这可以在操作系统级别永久完成,也可以在自定义启动脚本中执行。
-
将所需的Java参数-J选项传递给Jython启动脚本,将其传递给Java。使用直接入口点时,这特别容易:
jython -J-Xmx1024m -m robot.run some_tests.txt
3.1.8调试问题
测试用例可能会失败,因为被测系统无法正常工作,在这种情况下,测试发现了一个错误,或者因为测试本身是错误的。在命令行输出和报告文件中显示了解释失败的错误消息,有时单独的错误消息足以查明问题。但是,更多的情况是,不需要日志文件,因为它们还有其他日志消息,并显示哪个关键字实际上失败了。
当测试的应用程序导致失败时,错误消息和日志消息应该足以理解是什么引起的。如果不是这样,测试库不能提供足够的信息,需要加强。在这种情况下,手动运行相同的测试,如果可能的话,也可能会揭示更多关于这个问题的信息。
测试用例本身或关键字引起的故障有时很难调试。例如,如果错误消息告诉用关键字的参数数量错误,修复问题显然很容易,但是如果关键字丢失或以意想不到的方式失败,找到根本原因可能会更困难。查找更多信息的第一个地方是日志文件中的执行错误部分。例如,关于失败的测试库导入的错误可以很好地解释为什么由于缺少关键字而导致测试失败。
如果日志文件默认情况下不提供足够的信息,则可以使用较低的日志级别执行测试。例如,回溯显示代码中发生故障的位置是使用DEBUG级别记录的,并且当问题出现在单个关键字中时,这些信息是无价的。
如果日志文件仍然没有足够的信息,启用系统日志并查看它提供的信息是一个好主意。也可以在测试用例中添加一些关键字来查看正在发生的事情。特别是BuiltIn关键字日志和日志变量是有用的。如果没有其他的工作,总是可以从邮件列表或其他地方搜索帮助。
使用Python调试器(pdb)
也可以使用Python标准库中的pdb模块设置断点并交互式地调试正在运行的测试。通过插入来调用pdb的典型方法
导入 pdb ; pdb 。set_trace ()
然而,在想要打入调试器的位置,Robot Framework无法正常工作,因为标准输出流在关键字执行期间被重定向。相反,您可以使用以下内容:
import sys , pdb ; pdb 。PDB (标准输出= SYS 。__stdout__ )。set_trace ()
3.2测试执行
本节描述如何执行从解析的测试数据创建的测试套件结构,如何在失败后继续执行测试用例,以及如何优雅地停止整个测试的执行。
- 3.2.1执行流程
- 执行套件和测试
- 设置和拆解
- 执行顺序
- 通过执行
- 3.2.2继续失败
- 关键字的特殊失败
- 运行关键字并继续失败关键字
- 执行继续在teardowns自动
- 所有顶级关键字都在测试有模板时执行
- 3.2.3优雅地停止测试执行
- 紧迫
Ctrl-C - 使用信号
- 使用关键字
- 当第一个测试用例失败时停止
- 停止解析或执行错误
- 拆卸拆卸
- 紧迫
3.2.1执行流程
执行套件和测试
测试用例总是在测试套件中执行。从测试用例文件创建的测试套件直接进行测试,而从目录创建的套件具有儿童测试套件,该测试套件具有测试或其子套件。默认情况下,在执行套件中的所有测试运行,但也可以选择测试使用的选项--test,--suite,--include和--exclude。不包含测试的套件将被忽略。
执行从顶层测试套件开始。如果套件有测试,它们将逐个执行,如果套件有套件,则按深度优先顺序递归执行。当一个单独的测试用例被执行时,它所包含的关键字将按顺序运行。正常情况下,当前测试的执行结束,如果任何关键字失败,但它也有可能 在失败后继续。下面的章节将讨论确切的执行顺序以及可能的设置和拆卸对执行的影响。
设置和拆解
可以在测试套件,测试用例和 用户关键字级别上使用安装和拆卸。
套房设置
如果一个测试套件有一个设置,它将在其测试和子套件之前执行。如果套件设置通过,测试执行继续正常。如果失败,套件及其子套件包含的所有测试用例都被标记为失败。子测试套件中的测试和可能的套件设置和拆卸不会执行。
套件设置通常用于设置测试环境。因为如果套件安装失败,测试不运行,所以很容易使用套件设置来验证环境处于可以执行测试的状态。
套房拆解
如果一个测试套件被拆除,它将在所有的测试用例和子套件之后执行。无论测试状态如何,即使匹配套件设置失败,套件拆卸也会执行。如果套件拆卸失败,套件中的所有测试都会在报告和日志中标记为失败。
拆解套件主要用于执行后清理测试环境。为确保完成所有这些任务,即使其中一些失败,也会执行拆卸中使用的所有关键字。
测试设置
在测试用例的关键字之前执行可能的测试设置。如果设置失败,则不执行关键字。测试设置的主要用途是为特定测试用例设置环境。
测试拆解
在测试用例执行完毕后,可能的测试拆卸被执行。无论测试状态如何,测试设置失败都会执行。
类似于套件拆解,拆卸测试主要用于清理活动。即使他们的一些关键字失败,它们也被完全执行。
关键字拆解
用户关键字不能有设置,但是可以有与其他拆解一样的拆解。关键字teardowns在关键字被执行后运行,否则,不管状态如何,并且即使他们的一些关键字失败,它们也会被完全执行。
执行顺序
测试套件中的测试用例按照在测试用例文件中定义的顺序执行。更高级别的测试套件中的测试套件将根据文件或目录名以不区分大小写的字母顺序执行。如果从命令行给出多个文件和/或目录,则按照给定的顺序执行它们。
如果需要在目录中使用特定的测试套件执行顺序,则可以将01和 02等前缀添加到文件和目录名称中。如果生成的测试套件名称与套件的基本名称用两个下划线分隔,则这些前缀不包括在生成的测试套件名称中:
01__my_suite.html - >我的套房02__another_suite.html - >另一套房
如果套件内测试套件的字母顺序有问题,一个很好的解决方法是按要求的顺序分别给出它们。这很容易导致过长的启动命令,但参数文件允许很好地列出每行一个文件的文件。
也可以使用--randomize选项随机化执行顺序。
通过执行
通常情况下,如果所有包含的关键字都被执行并且没有失败,则认为测试用例,设置和拆卸被认为通过。从Robot Framework 2.8开始,还可以使用BuiltIn关键字 Pass Execution和Pass Execution如果以PASS状态停止执行并跳过剩余的关键字。
如何通过执行和通过执行如果在不同的情况下行为如下:
- 当用于任何设置或拆卸(套件,测试或关键字)时,这些关键字将通过该设置或拆卸。已启动的关键字可能被拆除。测试执行或状态不受影响。
- 当在设置或拆卸之外的测试用例中使用时,关键字将通过特定的测试用例。可能的测试和关键字teardowns被执行。
- 使用这些关键字之前发生的可能的继续性故障以及之后执行的拆解失败将会使执行失败。
- 必须给出一个解释消息,说明执行被中断的原因,还可以修改测试用例标签。有关更多详细信息和用法示例,请参阅这些关键字的 文档。
在测试过程中通过执行,安装或拆卸应谨慎使用。在最糟糕的情况下,会导致测试跳过所有可能在测试应用程序中发现问题的部分。在执行不能继续执行外部因素的情况下,通过测试用例并使其不关键通常更安全。
3.2.2继续失败
通常情况下,当任何关键字失败时,测试用例会立即停止。此行为缩短了测试执行时间,并防止后续关键字挂起或以其他方式导致被测系统处于不稳定状态时出现问题。这有一个缺点,就是后面的关键字往往会给出关于系统状态的更多信息。
在Robot Framework 2.5之前,处理故障的唯一方法是不要立即终止测试执行,而是使用BuiltIn关键字 运行关键字和忽略错误以及运行关键字和期望错误。为此目的使用这些关键字往往会增加测试用例的复杂性,而且在Robot Framework 2.5中添加了以下功能,以便在故障发生后继续执行。
关键字的特殊失败
库关键字使用异常报告失败,并且可以使用特殊异常来告诉核心框架,无论失败如何,执行都可以继续。测试库API章节解释了如何创建这些异常。
当测试结束并且出现一个或多个可持续的故障时,测试将被标记为失败。如果有多个失败,则会在最终错误消息中枚举所有错误:
发生了几个故障:1)第一个错误信息。2)第二个错误消息...
如果继续失败后发生正常故障,测试执行也会结束。同样在这种情况下,所有的失败将被列在最终的错误信息中。
可能分配给变量的失败关键字的返回值始终是Python None。
运行关键字并继续失败关键字
BuiltIn关键字运行关键字并继续失败允许将任何故障转换为可继续的故障。这些失败是由框架完全相同的方式处理源于图书馆关键字的可持续失败。
执行继续在teardowns自动
为确保所有的清理活动都得到了保证,在测试和套件拆卸过程中将自动启用继续失败模式。实际上这意味着在拆解中,所有级别的关键字总是被执行。
所有顶级关键字都在测试有模板时执行
使用测试模板时,总是执行所有的数据行,以确保测试所有不同的组合。在这种使用方式中,继续限于顶级关键字,并且在其内部,如果存在不可持续的故障,则执行正常结束。
3.2.3优雅地停止测试执行
有时需要在所有测试完成之前停止测试执行,但是要创建日志和报告。下面将解释如何完成这一点的不同方法。在所有这些情况下,其余的测试用例都被标记为失败。
注意
这些功能大部分都是Robot Framework 2.5中的新功能。
紧迫 Ctrl-C
Ctrl-C在运行测试的控制台中按下时停止执行。在Python上运行测试时,立即停止执行,但是使用Jython只会在当前执行的关键字结束后才结束。
如果Ctrl-C再次按下,则执行立即结束,不会创建报告和日志。
使用信号
在类似Unix的机器上,可以使用信号INT和终止测试执行TERM。这些信号可以使用kill命令从命令行发送,发送信号也可以很容易地自动化。
对于Jython,信号与按下有相同的限制Ctrl-C。同样,第二个信号强制停止执行。
使用关键字
执行也可以通过执行的关键字来停止。为此,有一个单独的致命错误 BuiltIn关键字,并且自定义关键字在失败时可以使用致命异常。
当第一个测试用例失败时停止
如果使用选项--exitonfailure,如果任何关键测试失败,测试执行立即停止。其余的测试也被标记为失败。
注意
在Robot Framework 2.8之前,这个行为是通过使用--runmode exitonfailure来实现的。选项--runmode 已在2.8中被弃用,将来将被删除。
停止解析或执行错误
Robot Framework可以将失败的关键字导致的失败与 例如无效设置导致的错误或测试库导入失败分开。默认情况下,这些错误被报告为测试执行错误,但错误本身不会使测试失败,否则会影响执行。但是,如果使用 --exitonerror选项,则所有此类错误都将被视为致命错误,并停止执行,因此剩余的测试将被标记为失败。在执行甚至开始之前遇到的解析错误,这意味着没有测试实际运行。
注意
--Exitonerror是Robot Framework 2.8.6中的新功能。
拆卸拆卸
默认情况下,即使使用上述方法之一停止测试执行,也会执行已启动的测试和套件的拆除。这允许清理活动运行,不管执行结束如何。
当使用--skipteardownonexit选项停止执行时也可以跳过拆卸 。例如,如果清理任务需要很长时间,这可能很有用。
注意
在Robot Framework 2.8之前,这个行为是通过使用--runmode skipteardownonexit来实现的。选项--runmode 已在2.8中被弃用,将来会被删除。
3.3后处理输出
在测试执行过程中生成的XML输出文件可以在之后由作为Robot Framework必不可少的一部分的rebot工具进行后期处理。它在测试执行期间生成测试报告和日志时自动使用,并且单独使用它可以创建自定义报告和日志以及合并和合并结果。
- 3.3.1使用rebot工具
- 概要
- 指定选项和参数
- 返回代码与rebot
- 3.3.2创建不同的报告和日志
- 3.3.3组合输出
- 3.3.4合并输出
- 合并重新执行的测试
- 合并套件执行的部分
3.3.1使用rebot工具
概要
rebot | jyrebot | ipyrebot [options] robot_outputspython | jython | ipy -m robot.rebot [options] robot_outputspython | jython | ipy path / to / robot / rebot.py [options] robot_outputsjava -jar robotframework.jar rebot [options] robot_outputs
rebot runner脚本运行在Python上,但也有分别运行在Jython和IronPython上的jyrebot 和ipyrebot runner脚本。推荐使用rebot,因为它比替代品快得多。除了使用这些脚本之外,可以使用 robot.rebot 入口点作为模块或使用任何解释器的脚本,也可以使用独立的JAR分发。
指定选项和参数
使用rebot的基本语法与开始测试执行时的基本语法完全相同 ,而且大多数命令行选项也是相同的。主要的区别是rebot的参数是 XML输出文件而不是测试数据文件或目录。
返回代码与rebot
来自rebot的返回代码与运行测试时的返回代码完全相同。
3.3.2创建不同的报告和日志
您可以使用rebot来创建在测试执行期间自动创建的相同报告和日志。当然,创建完全相同的文件是不明智的,但是,例如,一个报告包含所有测试用例,而另一个报告只包含一些测试子集可能是有用的:
rebot output.xmlrebot path / to / output_file.xmlrebot --include smoke --name Smoke_Tests c:\ results \ output.xml
另一个常见用法是在运行测试时创建输出文件(可以禁用日志和报告生成 --log NONE --report NONE),以及稍后生成日志和报告。例如,测试可以在不同的环境中执行,输出到中心位置的文件以及在那里创建的报告和日志。如果在Jython上运行测试时生成报告和日志花费了大量时间,这种方法也可以很好地工作。禁用日志和报告生成并稍后使用重新生成可以节省大量时间并使用更少的内存。
3.3.3组合输出
rebot的一个重要特点是能够结合不同测试执行轮次的输出。例如,此功能可以在不同的环境下运行相同的测试用例,并从所有输出生成总体报告。合并输出非常简单,只需要输出几个输出文件即可:
rebot output1.xml output2.xmlrebot输出/ *。xml
当输出结合时,会创建一个新的顶级测试套件,以便给定输出文件中的测试套件是其子套件。当多个测试数据文件或目录被执行时,这种方式也是相同的,在这种情况下,顶级测试套件的名称是通过用&符号(&)和空格连接子代名称来创建的。这些自动生成的名称并不是那么好,使用--name来提供更有意义的名称通常是个好主意:
rebot --name Browser_Compatibility firefox.xml opera.xml safari.xml ie.xmlrebot --include smoke --name Smoke_Tests c:\ results \ *。xml
3.3.4合并输出
如果相同的测试被重新执行或单个测试套件被分段执行,则结合上面讨论的结果创建了不必要的顶层测试套件。在这些情况下,最好是合并结果。合并是通过使用--merge选项来完成的,它改变了rebot如何 组合两个或多个输出文件。这个选项本身没有参数,所有其他的命令行选项也可以正常使用:
rebot --merge --name示例 - 关键回归original.xml merged.xml
下面讨论两个主要的用例,说明实际中的合并工作。
合并重新执行的测试
通常需要重新执行一个测试子集,例如,在被测系统或测试本身中修复一个bug后。这可以通过以下方式实现选择测试用例的名称(--test和 --suite选项),标签(--include和--exclude),或由先前的状态(--rerunfailed)。
将重新执行结果与使用默认组合输出方法的原始结果结合起来效果 不佳。主要的问题是你得到单独的测试套件,并可能已经固定的故障也显示出来。在这种情况下,最好使用--merge(-R) 选项来告诉rebot合并结果。实际上这意味着来自后面的测试运行的测试替换原来的测试。这个用法最好用一个实际的例子来说明 - 使用 --rerunfailed和 - 合并在一起:
pybot - 输出original.xml测试#首先执行所有的测试pybot --rununfailed original.xml --output rerun.xml tests#然后重新执行失败rebot --merge original.xml rerun.xml#最后合并结果
合并测试的消息包含结果已被替换的注释。该消息还显示测试的旧状态和消息。
合并结果必须始终具有相同的顶级测试套件。在原始输出中找不到的合并输出中的测试和套件被添加到结果输出中。下一节将讨论实际操作。
注意
合并重新执行的结果是Robot Framework 2.8.4中的一个新特性。在Robot Framework 2.8.6之前,跳过合并输出中的新测试或套件,并使用现今不推荐使用的--rerunmerge选项进行合并 。
合并套件执行的部分
--merge选项的另一个重要用例是合并运行测试套件时得到的结果,例如使用--include 和--exclude选项:
pybot --include smoke --output smoke.xml测试#首先运行一些测试pybot - 排除smoke - 输出others.xml测试#然后运行其他rebot --merge smoke.xml others.xml#最后合并结果
合并这样的输出时,结果输出包含从所有给定的输出文件中找到的所有测试和套件。如果从多个输出中发现一些测试,则最新的结果将取代之前部分中介绍的较早的结果。此外,这种合并策略要求顶级测试套件在所有输出中都是相同的。
3.4配置执行
本节介绍可用于配置测试执行或后处理输出的不同命令行选项。下一节将讨论与生成的输出文件相关的选项。
- 3.4.1选择测试用例
- 通过测试套件和测试用例名称
- 按标签名称
- 重新执行失败的测试用例
- 当没有测试匹配选择
- 3.4.2设置临界点
- 3.4.3设置元数据
- 设置名称
- 设置文档
- 设置免费元数据
- 设置标签
- 3.4.4调整库搜索路径
- 自动在PYTHONPATH中的位置
- 设置PYTHONPATH
- 设置CLASSPATH
- 使用--pythonpath选项
- 3.4.5设置变量
- 3.4.6空运
- 3.4.7随机化执行顺序
- 3.4.8控制台输出
- 控制台宽度
- 控制台颜色
- 控制台标记
- 3.4.9设置监听器
3.4.1选择测试用例
Robot Framework提供了几个命令行选项来选择要执行的测试用例。使用反弹工具后处理输出时,也可以使用相同的选项。
通过测试套件和测试用例名称
可以使用命令行选项--suite(-s)和--test(-t)分别选择测试套件和测试用例。这两个选项都可以多次使用来选择几个测试套件或案例。这些选项的参数是不区分大小写和空间的,也可以有简单的匹配多个名字的模式。如果同时使用--suite和 --test选项,则仅选择具有匹配名称的匹配套件中的测试用例。
- 测试例子- 测试mytest - 测试你最喜欢的- 测试例子*- 测试mysuite.mytest--test * .suite.mytest- 例子 - ??--suite mysuite - 测试mytest - 测试你的*
注意
使用长名称(例如mysuite.mytest)选择测试用例与Robot Framework 2.5.6及更新版本一起使用。
使用--suite选项或多或少与只执行适当的测试用例文件或目录相同。一个主要的好处是可以根据其父套件选择套件。这个语法是指定用点分隔的父和子套件名称。在这种情况下,可以执行父组件的设置和拆卸。
- 父母亲--suite myhouse.myhousemusic --test jack *
使用--test选项选择单个测试用例在创建测试用例时非常实用,但在自动运行测试时非常有限。该--suite选项可以在这种情况下是有用的,但在一般情况下,通过标签名称选择测试用例更加灵活。
按标签名称
可以使用--include(-i)和--exclude(-e)选项分别包含和排除测试用例的标签名称 。如果使用--include选项,则只有具有匹配标记的测试用例被选中,而具有匹配标记的--exclude选项测试用例则不是。如果两者都使用,则只选择与前一个选项匹配的标签,而不选择与后者匹配的标签。
- 包括例子- 排除not_ready- 包括回归 - 排除long_lasting
无论--include和--exclude可以多次使用,以匹配多个标签。在这种情况下,如果测试的标签与任何包含的标签匹配,并且没有与任何排除的标签匹配的标签,则选择一个测试。
除了指定标签的完全匹配,则有可能使用 标记的模式,其中*和?是通配符和 AND,OR和NOT运营商可以被用于单个标签或图案组合在一起:
- 包括功能4?- 排除错误*- 包括fooandbar- 排除xxORyyORzz- 包括fooNOTbar
通过标签选择测试案例是一个非常灵活的机制,并允许许多有趣的可能性
- 在其他测试之前执行的测试子集(通常称为烟雾测试)可以被标记
smoke并执行--include smoke。 - 未完成的测试可以被委托给使用标签的版本控制,例如
not_ready和从测试执行中排除--exclude not_ready。 sprint-在rebot --include sprint-42 output.xml)。
重新执行失败的测试用例
命令行选项--rerunfailed(-R)可以用来从早期的输出文件中选择所有失败的测试以重新执行。例如,如果运行所有测试需要花费大量时间,并且想要反复修复失败的测试用例,则此选项非常有用。
pybot测试#首先执行所有测试pybot --rerunfailed output.xml测试#然后重新执行失败
在这个选项后面,这个选项会选择失败的测试,因为它们是用--test选项单独选择的。它可以通过进一步微调所选测试的名单--test,--suite, --include和--exclude选项。
使用不是源自执行现在运行的相同测试的输出会导致未定义的结果。另外,如果输出不包含失败的测试,则是错误的。使用特殊值NONE作为输出与完全不指定此选项相同。
小费
重新执行结果和原始结果可以 使用--merge命令行选项合并在一起。
注意
重新执行失败的测试是Robot Framework 2.8中的一项新功能。以前的机器人框架2.8.4该选项被命名为 - 运行失败。旧的名字仍然有效,但将来会被删除。
当没有测试匹配选择
默认情况下,当没有测试符合选择标准时,测试执行失败,出现如下错误:
[错误]包含“xxx”的套件“示例”不包含测试用例。
由于没有生成输出,如果执行测试并自动处理结果,则此行为可能会有问题。幸运的是,在这种情况下,还可以使用命令行选项--RunEmptySuite来强制执行套件。结果正常输出被创建,但显示零执行测试。当一个空目录或不包含测试的测试用例文件被执行时,同样的选项也可以用来改变行为。
处理带有rebot的输出文件时也会出现类似的情况。可能没有测试与使用的过滤标准匹配,或者输出文件不包含任何开始的测试。默认情况下,在这些情况下执行 rebot失败,但是它有一个单独的 --ProcessEmptySuite选项,可以用来改变行为。实际上,在运行测试时,此选项与--RunEmptySuite的工作方式相同。
注意
--RunEmptySuite选项被添加到2.7.2的Robot Framework 2.6和--ProcessEmptySuite中。
3.4.2设置临界点
测试执行的最终结果是基于关键测试确定的。如果单个关键测试失败,整个测试运行被认为是失败的。另一方面,非关键测试用例可能会失败,整体状态仍然被认为是合格的。
所有的测试用例在默认情况下都被认为是关键的,但是这可以通过--critical(-c)和--noncritical(-n) 选项来改变。这些选项指定哪些测试关键的基础上的标签,类似于--include和 --exclude用于选择由标签测试。如果只使用 - 关键字,那么具有匹配标签的测试用例就非常重要。如果只有--noncritical使用,不匹配的标签测试是至关重要的。最后,如果两者都被使用,那么仅使用关键标签进行测试,但是没有非关键标签是至关重要的。
无论--critical和--noncritical也支持同样的标记图案为--include和--exclude。这意味着,模式匹配的情况下,空间和下划线不敏感的,*并且? 被支撑为通配符,和AND,OR并且NOT 运营商可以被用于创建组合花样。
- 临界回归- 非重要的not_ready- 关键的iter- * - 关键要求 - * - 非关键要求-6
设置关键性的最常见用例是在测试执行中没有准备好测试用例或测试功能仍在开发中。这些测试也可以使用--exclude选项完全排除在测试执行之外,但将它们包括在非关键测试中可以让您看到何时开始通过测试。
执行测试时设置的严重性不存储在任何地方。如果你想保持相同的临界时,处理后的输出与rebot,你需要使用--critical和/或--noncritical也与它:
#使用rebot从执行期间创建的输出中创建新的日志和报告pybot - 临界回归--outputdir所有my_tests.htmlrebot --name烟雾 - 包括烟雾 - 临界回归--outputdir smoke all / output.xml#不需要使用 - 关键/ - 在没有创建日志或报告时不重要jybot --log NONE --report NONE my_tests.htmlrebot --critical feature1 output.xml
3.4.3设置元数据
设置名称
当Robot Framework分析测试数据时,测试套件名称是从文件和目录名称创建的。但是,顶级测试套件的名称可以通过命令行选项--name(-N)覆盖 。给定名称中的下划线将自动转换为空格,并且名称中的单词大写。
设置文档
除了在测试数据中定义文档之外,顶层套件的文档还可以通过命令行提供--doc(-D)选项。给定文档中的下划线被转换为空格,并且可能包含简单的HTML格式。
设置免费元数据
免费的测试套件元数据也可以通过命令行--metadata(-M)给出。参数必须是格式 name:value,其中name要设置的元数据的名称 value是其值。名称和值中的下划线将转换为空格,而后者可能包含简单的HTML格式。此选项可能会多次使用来设置多个元数据。
3.4.4调整库搜索路径
当测试库被使用时,Robot Framework使用Python或Jython解释器从系统导入实现库的模块。搜索这些模块的位置称为 PYTHONPATH,在Jython上运行测试或使用jar分发时,也使用Java CLASSPATH。
调整库搜索路径以便找到库是成功执行测试的必要条件。除了查找测试库之外,搜索路径还用于查找在命令行上设置的监听器。有各种方法可以改变 PYTHONPATH和CLASSPATH,但不管选择的方法如何,建议使用自定义的启动脚本。
自动在PYTHONPATH中的位置
Python和Jython安装将自己的库目录自动放入 PYTHONPATH中。这意味着使用Python自己的打包系统打包的测试库会自动安装到库搜索路径中的一个位置。Robot Framework也把包含标准库的目录和执行测试的目录放到PYTHONPATH中。
设置PYTHONPATH
有几种方法可以在系统中修改PYTHONPATH,但最常见的方法是在测试执行之前设置一个名称相同的环境变量。Jython实际上并不正常使用PYTHONPATH 环境变量,但是Robot Framework可以确保在其中列出的位置被添加到库搜索路径中,而不管解释器如何。
设置CLASSPATH
CLASSSPATH与Jython一起使用或使用独立的jar时使用。
使用Jython时,最常用的方法是改变CLASSPATH,就像设置PYTHONPATH一样设置一个环境变量。请注意,不是使用 CLASSPATH,即使使用Java实现库和侦听器,始终可以使用Jython中的PYTHONPATH。
在使用独立jar分发时,由于命令不读取CLASSPATH环境变量,CLASSPATH必须设置稍微不同。在这种情况下,有两种不同的方法来配置CLASSPATH,如下所示:java -jar
java -cp lib / testlibrary.jar:lib / app.jar:robotframework-2.7.1.jar org.robotframework.RobotFramework example.txtjava -Xbootclasspath / a:lib / testlibrary.jar:lib / app.jar -jar robotframework-2.7.1.jar example.txt
使用--pythonpath选项
Robot Framework还有一个单独的命令行选项 --pythonpath(-P),用于将目录或存档添加到 PYTHONPATH中。多个路径可以用冒号(:)或多次使用这个选项来分隔。给定的路径也可以是匹配多个路径的全局模式,但通常必须 转义。
例子:
--pythonpath libs /--pythonpath /opt/testlibs:mylibs.zip:yourlibs--pythonpath mylib.jar --pythonpath lib / STAR.jar --escape star:STAR
3.4.5设置变量
变量可以在命令行中单独 使用--variable(-v)选项或通过变量文件 使用--variablefile(-V)选项来设置。变量和变量文件在单独的章节中进行了解释,但以下示例说明了如何使用这些选项:
- 变量名称:值- 可变操作系统:Linux - 变量IP:10.0.0.42--variablefile path / to / variables.py--variablefile myvars.py:possible:arguments:这里- 变量环境:Windows - 变量文件c:\ resources \ windows.py
3.4.6空运
Robot Framework支持所谓的空运行模式,否则测试运行正常,但是来自测试库的关键字根本不会被执行。干运行模式可用于验证测试数据; 如果干运行通过,数据应该在语法上是正确的。该模式使用选项--dryrun触发。
空运行执行可能由于以下原因而失败:
- 使用未找到的关键字。
- 使用错误数量的参数的关键字。
- 使用具有无效语法的用户关键字。
除了这些故障之外,还会显示正常执行错误,例如,无法解析测试库或资源文件导入时。
注意
空运行模式不验证变量。未来版本中可能会取消此限制。
注意
在Robot Framework 2.8之前,使用选项--runmode dryrun激活干运行模式。选项--runmode已在2.8中被弃用,将来将被删除。
3.4.7随机化执行顺序
测试执行顺序可以使用选项--randomize
-
tests - 每个测试套件内的测试用例都是以随机顺序执行的。
-
suites - 所有测试套件都是以随机顺序执行的,但套件内的测试用例按照定义的顺序运行。
-
all - 测试用例和测试套件都是以随机顺序执行的。
-
none - 测试和套件的执行顺序都不是随机的。该值可用于覆盖使用 --randomize设置的较早值 。
从Robot Framework 2.8.5开始,可以给定一个自定义种子来初始化随机生成器。如果要使用与先前相同的顺序重新运行测试,这很有用。种子是作为--randomize格式的值的一部分给出的
例子:
pybot - 随机测试my_test.txtpybot - 随机大小:12345路径/到/测试
注意
之前机器人框架2.8,随机化是使用选项触发 --runmode <模式>,其中Random:Test, Random:Suite或Random:All。这些值的工作方式与为--randomize匹配值的方式相同。选项--runmode已在2.8中被弃用,将来将被删除。
3.4.8控制台输出
控制台宽度
控制台中测试执行输出的宽度可以使用选项--monitorwidth(-W)来设置。默认宽度是78个字符。
小费
在很多像UNIX一样的机器上,你可以使用$COLUMNS 像--monitorwidth $COLUMNS。
控制台颜色
所述--monitorcolors(-C)选项用于控制是否颜色应在控制台输出被使用。颜色是使用ANSI颜色实现的,除了在默认情况下使用Windows API的Windows。从Jython访问这些API是不可能的,因此颜色不能在Windows上使用Jython。
该选项支持以下不区分大小写的值:
-
auto - 将输出写入控制台时启用颜色,但在将输出重定向到文件或其他位置时启用颜色。这是默认的。
-
on - 输出重定向时也使用颜色。在Windows上不起作用。
-
ansi -
相同
on但使用在Windows ANSI色也。例如,将输出重定向到了解ANSI颜色的程序时很有用。Robot Framework 2.7.5中的新功能 -
off - 颜色被禁用。
-
force - 向后兼容Robot Framework 2.5.5及更早版本。不应该使用。
注意
auto在Robot Framework 2.5.6中添加了对Windows和模式的颜色支持。
控制台标记
从Robot Framework 2.7开始,当测试用例中的顶级关键字结束时,控制台上会显示特殊标记.(成功)和 F(失败)。这些标记允许在高级别的测试执行之后,当测试用例结束时它们被擦除。
从Robot Framework 2.7.4开始,可以使用--monitormarkers(-K)选项配置标记的使用时间。它支持以下不区分大小写的值:
-
auto - 将标准输出写入控制台时启用标记,但不将其重定向到文件或其他位置。这是默认的。
-
on - 标记总是被使用。
-
off - 标记被禁用。
3.4.9设置监听器
所谓的监听器可以用来监视测试执行。它们通过命令行选项--listener被使用 ,并且指定的监听器必须与测试库类似地位于模块搜索路径中。
3.5创建输出
执行测试时会创建多个输出文件,并且所有文件都与测试结果有关。本节讨论创建了哪些输出,如何配置它们的创建位置以及如何微调其内容。
- 3.5.1不同的输出文件
- 输出目录
- 输出文件
- 日志文件
- 报告文件
- XUnit兼容的结果文件
- 调试文件
- 时间戳输出文件
- 设置标题
- 设置背景颜色
- 3.5.2日志级别
- 可用的日志级别
- 设置日志级别
- 可见的日志级别
- 3.5.3分割日志
- 3.5.4配置统计信息
- 配置显示的套件统计
- 包括和排除标签统计
- 生成组合标签统计信息
- 从标签名称创建链接
- 添加文档到标签
- 3.5.5删除和展开关键字
- 删除关键字
- 拼合关键字
- 3.5.6设置执行的开始和结束时间
- 3.5.7系统日志
3.5.1不同的输出文件
本节介绍可以创建哪些不同的输出文件以及如何配置它们的创建位置。输出文件是使用命令行选项进行配置的,它们将输出文件的路径作为参数。可以使用特殊的值NONE (不区分大小写)来禁止创建特定的输出文件。
输出目录
所有输出文件都可以使用绝对路径来设置,在这种情况下,它们被创建到指定的位置,但是在其他情况下,路径被视为相对于输出目录。默认输出目录是从哪里开始执行的目录,但可以使用--outputdir(-d)选项来更改。用这个选项设置的路径也是相对于执行目录而言的,当然也可以作为绝对路径给出。无论如何获取单个输出文件的路径,它的父目录都是自动创建的,如果它不存在的话。
输出文件
输出文件包含机器可读XML格式的所有测试执行结果。日志,报告和xUnit文件通常是基于它们生成的,也可以将它们组合在一起,或者用Rebot进行后处理。
小费
从Robot Framework 2.8开始,生成报告和xUnit 文件作为测试执行的一部分不再需要处理输出文件。运行测试时禁用日志生成可以节省内存。
命令行选项--output(-o)确定相对于输出目录创建输出文件的路径。当运行测试时,输出文件的默认名称是output.xml。
当使用Rebot后处理输出时,除非显式使用--output选项,否则不会创建新的输出文件。
从Robot Framework 2.6开始,可以在运行具有特殊值的测试时禁止创建输出文件NONE。在Robot Framework 2.6和2.7版本中,这个自动禁用也会创建日志和报告文件,但是从2.8版本开始,这个不再做了。如果不需要输出,则应全部禁用--output NONE --report NONE --log NONE。
日志文件
日志文件包含有关以HTML格式执行的测试用例的详细信息。它们具有显示测试套件,测试用例和关键字详细信息的分层结构。几乎每次当测试结果要被详细研究时都需要日志文件。即使日志文件也有统计信息,报告更适合获取更高级别的概述。
命令行选项--log(-l)确定创建日志文件的位置。除非使用特殊值NONE,否则始终创建日志文件,其默认名称为 log.html。
日志文件开始的一个例子

一个关键字详细信息可见的日志文件示例
报告文件
报告文件包含HTML格式的测试执行结果的概述。他们有基于标签和执行测试套件的统计数据,以及所有执行的测试用例列表。当生成报告和日志时,报告都会链接到日志文件,以便轻松导航到更详细的信息。如果所有关键测试都通过,则背景色为绿色,否则为亮红色,因此从报告中很容易看到整体测试执行状态。
命令行选项--report(-r)确定报告文件的创建位置。与日志文件类似,除非NONE用作值,否则始终创建报告,其默认名称为report.html。
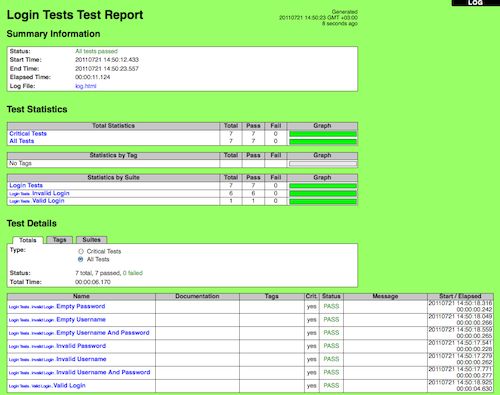
成功执行测试的示例报告文件
测试执行失败的示例报告文件
XUnit兼容的结果文件
XUnit结果文件包含xUnit兼容XML格式的测试执行摘要。这些文件可以用作理解xUnit报告的外部工具的输入。例如,Jenkins持续集成服务器支持基于xUnit兼容结果生成统计信息。
小费
詹金斯还有一个独立的机器人框架插件。
除非明确使用命令行选项--xunit(-x),否则不会创建XUnit输出文件 。这个选项需要一个到生成的xUnit文件(相对于输出目录)的路径作为一个值。
因为xUnit报告没有非关键测试的概念,所以xUnit报告中的所有测试都将被标记为合格或不合格,在关键测试和非关键测试之间没有区别。如果这是一个问题, 可以使用--xunitskipnoncritical选项将非关键测试标记为跳过。跳过的测试会以类似的格式得到包含测试用例的实际状态和可能的消息的消息FAIL: Error message。
注意
--xunitskipnoncritical是Robot Framework 2.8中的一个新选项。
调试文件
调试文件是在测试执行过程中写入的纯文本文件。所有来自测试库的消息都被写入,以及关于开始和结束测试套件,测试用例和关键字的信息。调试文件可用于监视测试执行。例如,可以使用单独的 fileviewer.py 工具,或者在类UNIX系统中使用tail -f命令。
除非明确使用命令行选项--debugfile(-b),否则不会创建调试文件 。
时间戳输出文件
本节列出的所有输出文件可以使用选项--timestampoutputs(-T)自动加盖时间戳。使用此选项时,格式中的时间戳YYYYMMDD-hhmmss会放在扩展名和每个文件的基本名称之间。例如,下面的示例将创建输出文件,如 output-20080604-163225.xml和mylog-20080604-163225.html:
pybot --timestampoutputs --log mylog.html --report NONE tests.html
设置标题
日志和报告的默认标题是通过在测试日志或 测试报告前添加顶级测试套件的名称来生成的。可以使用选项--logtitle和--reporttitle分别从命令行给出自定义标题。给定标题中的下划线将自动转换为空格。
例:
pybot --logtitle Smoke_Test_Log --reporttitle Smoke_Test_Report --include smoke my_tests /
设置背景颜色
默认情况下,报告文件在所有重要测试通过时都具有绿色背景, 否则为红色背景。这些颜色可以通过使用--reportbackground命令行选项进行自定义,该选项以冒号作为参数分隔两个或三个颜色:
--reportbackground蓝色:红色--reportbackground绿色:黄色:红色--reportbackground#00E:#E00
如果您指定了两种颜色,则将使用第一种颜色,而不使用默认的绿色,而使用第二种颜色而不使用默认的红色。例如,这允许使用蓝色而不是绿色来为色盲人士更容易地分离背景。
如果您指定了三种颜色,则第一个将在所有测试成功时使用,第二个仅在非关键测试失败时使用,而第二个在出现严重故障时使用。因此,这个功能允许在非关键测试失败时使用单独的背景颜色,例如黄色。
指定的颜色用作body 元素backgroundCSS属性的值。该值按原样使用,可以是HTML颜色名称(例如red),十六进制值(例如#F00或#FF0000)或RGB值(例如rgb(255,0,0))。默认的绿色和红色分别使用十六进制值#9F6和#F33。
3.5.2日志级别
可用的日志级别
日志文件中的消息可以具有不同的日志级别。一些消息是由Robot Framework本身编写的,而且执行的关键字可以使用不同的级别记录信息。可用的日志级别是:
-
FAIL - 当关键字失败时使用。只能由Robot Framework自己使用。
-
WARN - 用于显示警告。它们也显示在 控制台和日志文件中的“测试执行错误”部分,但不会影响测试用例状态。
-
INFO - 正常消息的默认级别。默认情况下,该级别以下的消息不会显示在日志文件中。
-
DEBUG - 用于调试目的。例如,用于记录库在内部进行的操作是有用的。当关键字失败时,会自动使用此级别记录代码中发生故障的位置。
-
TRACE - 更详细的调试级别。关键字参数和返回值是使用这个级别自动记录的。
设置日志级别
默认情况下,INFO不在日志级别的日志消息被记录下来,但是可以使用--loglevel(-L)选项从命令行更改该阈值 。该选项将任何可用的日志级别作为参数,并且该级别成为新的阈值级别。一个特殊的值NONE也可以用来完全禁用日志记录。
从机器人框架2.5.2开始,也可以使用 --loglevel选项也当处理后的输出与 rebot。例如,这允许最初使用该TRACE级别运行测试,并随后生成较小的日志文件以供普通查看INFO。默认情况下,执行过程中包含的所有消息也将包含在rebot中。执行期间忽略的消息无法恢复。
另一种更改日志级别的方法是在测试数据中使用BuiltIn 关键字Set Log Level。它采用与--loglevel选项相同的参数,并且还返回旧的级别,以便稍后可以恢复,例如在测试拆卸中。
可见的日志级别
从Robot Framework 2.7.2开始,如果日志文件包含位于DEBUG或TRACE级别的消息, 则右上角会显示可见的日志级别下拉列表。这允许用户从视图中删除选定级别以下的消息。这在运行测试时尤其有用 TRACE。
显示可见日志级别的示例日志下拉菜单
默认情况下,下拉列表将被设置为日志文件中的最低级别,以便显示所有消息。使用--loglevel选项可以更改默认的可见日志级别,方法是在用 冒号分隔的正常日志级别之后给定默认级别:
--loglevel DEBUG:INFO
在上面的示例中,测试是使用级别运行的DEBUG,但是日志文件中的默认可见级别是INFO。
3.5.3分割日志
通常情况下,日志文件只是一个HTML文件。当他的测试用例数量增加时,文件的大小会变得很大,打开浏览器是不方便的,甚至是不可能的。从Robot Framework 2.6开始,可以使用--splitlog选项将日志的各个部分拆分成外部文件,并在需要时透明地加载到浏览器中。
分割日志的主要好处是单个日志部分非常小,即使测试数据量非常大,也可以打开和浏览日志文件。一个小缺点是日志文件占用的整体大小增加。
从技术上讲,与每个测试用例相关的测试数据都保存在与主日志文件相同的文件夹中的JavaScript文件中。这些文件具有诸如log-42.js之类的名称,其中log是主日志文件的基本名称,并且42是递增的索引。
注意
当复制日志文件时,您还需要复制所有 日志 - *。js文件或者某些信息将会丢失。
3.5.4配置统计信息
有迹象表明,可用于配置和调整的内容几个命令行选项由标签统计,通过统计套房,并通过标签测试详细信息在不同的输出文件表。所有这些选项在执行测试用例和后处理输出时都有效。
配置显示的套件统计
当执行更深层次的套件结构时,在Statistics by Suite表中显示所有测试套件级别可能会使表格难以阅读。Bt默认显示所有套件,但是您可以使用命令行选项--suitestatlevel来控制此套件,该套件将套件级别显示为参数:
--suitestatlevel 3
包括和排除标签统计
当使用多个标签时,标签统计表可能变得相当拥挤。如果发生这种情况,该命令行选项 --tagstatinclude和--tagstatexclude可用于选择哪些标签显示,类似于 --include和--exclude用于选择测试案例:
--tagstatinclude some-tag --tagstatinclude another-tag--tagstatexclude所有者 - *--tagstatinclude prefix- * --tagstatexclude prefix-13
生成组合标签统计信息
命令行选项--tagstatcombine可用于生成汇总来自多个标记的统计信息的汇总标记。组合的标签是使用标签模式指定的, *并且?作为通配符被支持AND, OR并且NOT运算符可以用于将各个标签或模式组合在一起。
以下示例说明了使用不同的模式创建组合标记统计信息,下图显示了由Tag生成的统计信息表片段 :
--tagstatcombine所有者 - *--tagstatcombine smokeANDmytag--tagstatcombine smokeNOTowner-janne *
组合标签统计的例子
如上例所示,添加的组合统计量的名称默认情况下只是给定的模式。如果这样做不够好,可以在模式之后用冒号(:)分隔它们来给定一个自定义名称。名字中可能的下划线被转换为空格:
--tagstatcombine prio1ORprio2:High_priority_tests
从标签名称创建链接
您可以使用命令行选项--tagstatlink将外部链接添加到“ 标记统计信息”表。此选项的参数以格式给出,其中 指定要分配链接的标签是要创建的链接,并且是要提供给链接的名称。tag:link:nametaglinkname
tag可能是一个单一的标签,但更常见的是一个简单的模式 ,*匹配任何东西,并?匹配任何单个字符。当tag是这样一种模式,以通配符匹配可以在使用link和title的语法%N,其中“N”是从1开始的匹配的索引。
以下示例说明了此选项的用法,下图显示了使用这些选项执行示例测试数据时,由Tag生成的统计信息摘要表的片段:
--tagstatlink mytag:http://www.google.com:Google--tagstatlink jython-bug- *:http://bugs.jython.org/issue_%1:Jython-bugs--tagstatlink所有者 - *:mailto:%[email protected]?subject = Acceptance_Tests:Send_Mail

来自标签名称的链接示例
3.5.5删除和展开关键字
输出文件的大部分内容来自关键字及其日志消息。在创建更高级别的报告时,根本不需要日志文件,在这种情况下,关键字及其消息只是占用了不必要的空间。日志文件本身也可能会变得过大,特别是如果它们包含for循环或其他构造重复某些关键字多次。
在这些情况下,可以使用命令行选项--removekeywords和 --flattenkeywords来处理或拼合不必要的关键字。它们可以在执行测试用例和后处理输出时使用。在执行期间使用时,它们只影响日志文件,而不影响XML输出文件。与rebot他们同时影响日志,并可能产生新的输出XML文件。
删除关键字
该--removekeywords选项完全删除关键字和他们的消息。它具有以下操作模式,可以多次使用以启用多种模式。 除非使用模式,否则包含警告的关键字不会被删除ALL。
-
ALL - 无条件地删除所有关键字的数据。
-
PASSED - 从通过的测试用例中删除关键字数据 在大多数情况下,使用此选项创建的日志文件包含足够的信息来调查可能的故障。
-
FOR - 从最后一个 循环中除去 for循环的所有迭代。
-
WUKS - 删除 BuiltIn关键字中的 所有失败的关键字等到关键字成功,除了最后一个关键字。
-
NAME: -
从关键字状态中删除与给定模式匹配的所有关键字的数据。该模式与关键字的全名相匹配,前缀为可能的库或资源文件名。该模式是大小写,空格和下划线不敏感,它支持与通配符 和 简单模式。
*?
例子:
rebot --removekeywords all --output removed.xml output.xmlpybot --removekeywords传递--removekeywords为tests.txtpybot --removekeywords名称:HugeKeyword --removekeywords名称:resource。* tests.txt
在解析输出文件并基于它生成内部模型之后,删除关键字。因此,它不会像拼合关键字那样减少内存使用量。
注意
对于使用支持--removekeywords执行测试,以及时FOR和WUKS在机器人框架2.7添加模式。
注意
NAME: 模式被添加到机器人框架2.8.2。
拼合关键字
该--flattenkeywords选项变平匹配的关键字。实际上,这意味着匹配的关键字将递归地从其子关键字中获取所有日志消息,否则将丢弃子关键字。展平支持以下模式:
-
FOR - 完全展平 循环。
-
FORITEM - 逐个展开循环迭代。
-
NAME: -
拼合与给定模式匹配的关键字。模式匹配规则与 删除关键字使用
NAME:模式相同。
例子:
pybot --flattenkeywords名称:HugeKeyword --flattenkeywords名称:resource。* tests.txtrebot --flattenkeywords foritem --output flattened.xml original.xml
当最初解析输出文件时,已经完成了拼合关键字。这可以节省大量的内存,特别是深度嵌套的关键字结构。
注意
扁平化的关键词是机器人框架2.8.2中的新功能,并 FOR和FORITEM模式在机器人框架2.8.5添加。
3.5.6设置执行的开始和结束时间
当组合输出使用rebot,可以设置使用选项组合的测试套件的开始和结束时间--starttime 和--endtime分别。这很方便,因为默认情况下,组合套件没有这些值。当给定开始时间和结束时间时,也会根据它们计算经过时间。否则,经过的时间是通过将儿童测试套件的经过时间加在一起而得到的。
从Robot Framework 2.5.6开始,也可以使用上述选项来设置单个套件在使用rebot时的开始和结束时间 。对单个输出使用这些选项总是会影响套件的已用时间。
时间必须以格式的时间戳给出YYYY-MM-DD hh:mm:ss.mil,其中所有分隔符都是可选的,毫秒到小时之间的部分可以省略。例如,2008-06-11 17:59:20.495相当于既20080611-175920.495和 20080611175920495,也仅仅20080611会工作。
例子:
rebot --starttime 20080611-17:59:20.495 output1.xml output2.xmlrebot --starttime 20080611-175920 --endtime 20080611-180242 * .xmlrebot --starttime 20110302-1317 --endtime 20110302-11418 myoutput.xml
3.5.7系统日志
机器人框架有它自己的纯文本系统日志写信息
- 处理和跳过的测试数据文件
- 导入测试库,资源文件和变量文件
- 执行测试套件和测试用例
- 创建输出
通常用户从不需要这些信息,但在调查测试库或Robot Framework本身的问题时,它可能非常有用。系统日志不是默认创建的,但是可以通过设置环境变量ROBOT_SYSLOG_FILE来启用它,使其包含所选文件的路径。
系统日志与普通日志文件具有相同的日志级别,但不同的是FAIL它具有ERROR 级别。要使用的阈值级别可以使用ROBOT_SYSLOG_LEVEL环境变量进行更改 ,如下例所示。除了控制台和正常的日志文件之外,可能的意外错误和警告也会写入系统日志中。
#!/斌/庆典导出ROBOT_SYSLOG_FILE = /tmp/syslog.txt 导出ROBOT_SYSLOG_LEVEL = DEBUGpybot --name Syslog_example路径/ to / tests
4扩展机器人框架
- 4.1创建测试库
- 4.2远程库接口
- 4.3使用监听器接口
- 4.4扩展机器人框架Jar
4.1创建测试库
Robot Framework的实际测试功能由测试库提供。现有的库有很多,其中一些甚至与核心框架捆绑在一起,但仍然经常需要创建新的库。这个任务不是太复杂,因为正如本章所示,Robot Framework的库API非常简单直接。
- 4.1.1简介
- 支持的编程语言
- 不同的测试库API
- 4.1.2创建测试库类或模块
- 测试库名称
- 提供参数来测试库
- 测试库范围
- 指定库版本
- 指定文档格式
- 图书馆充当监听者
- 4.1.3创建静态关键字
- 什么方法被认为是关键字
- 关键字名称
- 关键字参数
- 默认值为关键字
- 可变数量的参数(
*varargs) - 免费的关键字参数(
**kwargs) - 参数类型
- 使用装饰器
- 4.1.4与Robot Framework通信
- 报告关键字状态
- 停止测试执行
- 尽管失败,继续测试执行
- 记录信息
- 程序化日志API
- 在库初始化期间记录
- 返回值
- 使用线程时的通信
- 4.1.5分发测试库
- 记录库
- 测试库
- 打包库
- 弃用关键字
- 4.1.6动态库API
- 获取关键字名称
- 运行关键字
- 获取关键字参数
- 获取关键字文档
- 获得通用库文档
- 用动态库命名参数语法
- 免费关键字参数与动态库
- 概要
- 4.1.7混合库API
- 获取关键字名称
- 运行关键字
- 获取关键字参数和文档
- 概要
- 4.1.8使用Robot Framework的内部模块
- 可用的API
- 使用BuiltIn库
- 4.1.9扩展现有的测试库
- 修改原始源代码
- 使用继承
- 直接使用其他库
- 从Robot Framework获取活动的库实例
- 使用动态或混合API的库
4.1.1简介
支持的编程语言
Robot Framework本身是用Python编写的,自然扩展的测试库可以使用相同的语言来实现。在Jython上运行框架时,也可以使用Java实现库。纯Python代码同时适用于Python和Jython,假定它不使用Jython上没有的语法或模块。当使用Python时,也可以使用Python C API来实现带有C的库,尽管使用ctypes模块与Python库中的C代码交互通常更容易 。
使用这些本机支持的语言实现的库也可以充当使用其他编程语言实现的功能的包装。这种方法的一个很好的例子是远程库,而另外一种广泛使用的方法是将外部脚本或工具作为单独的进程运行。
小费
Robot Framework测试库的Python教程开发人员 涵盖了足够的Python语言,以便开始使用它来编写测试库。它还包含一个简单的示例库和测试用例,可以在您的机器上执行和调查。
不同的测试库API
Robot Framework有三个不同的测试库API。
静态API
最简单的方法是使用直接映射到 关键字名称的模块(使用Python)或类(使用Python或Java) 。关键字也采取与实施它们的方法相同的 论据。关键字 报告具有异常的 失败,通过写入标准输出进行 日志记录,并可以使用该语句 返回值
return。
动态API
动态库是实现一个方法来获取他们实现的关键字名称的类,另一个方法是用给定的参数执行一个named关键字。可以在运行时动态确定要实现的关键字的名称以及它们的执行方式,但报告状态,记录和返回值与静态API中的类似。
混合API
这是静态和动态API之间的混合。图书馆是类的方法告诉他们实现的关键字,但这些关键字必须直接可用。除了发现什么关键字被实现之外,其他的一切都和静态API类似。
所有这些API都在本章中描述。一切都基于静态API的工作原理,所以首先讨论它的功能。然后,动态库API和混合库API如何与它们不同,然后分别讨论它们。
本章中的例子主要是关于使用Python,但是对于仅限于Java的开发人员也应该很容易理解。在API差别很小的情况下,这两种用法都用适当的例子来解释。
4.1.2创建测试库类或模块
测试库可以作为Python模块和Python或Java类来实现。
测试库名称
导入库时使用的测试库的名称与实现它的模块或类的名称相同。例如,如果您有一个Python模块MyLibrary(即文件MyLibrary.py),它将创建一个名为MyLibrary的库 。同样,一个Java类YourLibrary,当它不在任何包中时,就会创建一个具有这个名称的库。
Python类总是在模块内。如果实现库的类的名称与模块的名称相同,Robot Framework允许在导入库时删除类名。例如,类MyLib在MyLib.py 文件可以被用作与仅举库MyLib中。这也适用于子模块,例如,如果parent.MyLib模块有类MyLib,只需使用parent.MyLib就 可以导入它。如果模块名称和类名称不同,则必须使用模块和类名称来使用库,例如 mymodule.MyLibrary或parent.submodule.MyLib。
非默认包中的Java类必须与全名一起使用。例如,类MyLib在com.mycompany.myproject 包必须用名称导入com.mycompany.myproject.MyLib。
注意
使用子模块删除类名仅适用于Robot Framework 2.8.4及更高版本。在早期版本中,您还需要包含像parent.MyLib.MyLib这样的类名称。
小费
如果库名称很长,例如Java包名称很长,则建议使用WITH NAME语法为库提供一个更简单的别名。
提供参数来测试库
所有作为类实现的测试库都可以使用参数。这些参数是在库名后面的Setting表中指定的,当Robot Framework创建一个导入库的实例时,它将它们传递给它的构造函数。作为模块实现的库不能采取任何参数,所以试图使用这些结果的错误。
库需要的参数个数与库构造函数接受的参数个数相同。参数的缺省值和变量的数目与关键字参数的工作方式类似,只是没有Java库的可变参数支持。传递给库的参数以及库名称本身都可以使用变量来指定,所以可以通过变量来修改它们,例如从命令行。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | 我的图书馆 | 10.0.0.1 | 8080 |
| 图书馆 | AnotherLib | $ {VAR} |
上例中使用的库的示例实现,第一个是Python,第二个是Java:
从 示例 导入 连接class MyLibrary : def __init__ (self , host , port = 80 ): self 。_conn = 连接(主机, int (端口)) def send_message (self , message ): self 。_conn 。发送(消息)
公共 类 AnotherLib { private String setting = null ; public AnotherLib (字符串 设置) { 设置 = 设置; } 公共 无效 doSomething () { 如果 设置。等于(“42” ) { //做某事... } } }
测试库范围
作为类实现的库可以具有内部状态,可以通过关键字和参数来改变库的构造函数。因为状态可以影响关键字的实际行为,所以确保在一个测试用例中的更改不会意外地影响其他测试用例是非常重要的。这些依赖关系可能会产生难以调试的问题,例如,当添加新的测试用例并且不一致地使用库时。
Robot Framework试图保持测试用例彼此独立:默认情况下,它为每个测试用例创建新的测试用例实例。但是,这种行为并不总是可取的,因为有时测试用例应该能够共享一个共同的状态。另外,所有的库都没有状态,创建它们的新实例根本就不需要。
测试库可以控制何时用类属性创建新的库ROBOT_LIBRARY_SCOPE。这个属性必须是一个字符串,它可以有以下三个值:
-
TEST CASE - 每个测试用例都会创建一个新的实例。一个可能的套件设置和套件拆卸共享另一个实例。这是默认的。
-
TEST SUITE - 为每个测试套件创建一个新的实例。从测试用例文件创建并包含测试用例的最低级测试套件具有自己的实例,而更高级别的套件都可以为其可能的设置和拆卸获取自己的实例。
-
GLOBAL - 在整个测试执行过程中只有一个实例被创建,它被所有的测试用例和测试套件共享。从模块创建的库始终是全局的。
注意
如果使用不同的参数多次导入库,则不管范围如何,都会创建一个新实例。
当TEST SUITE或GLOBAL范围与有状态测试库使用,建议图书馆有清理国家一些特殊的关键字。然后可以使用该关键字,例如,在套件设置或拆卸中,以确保下一个测试套件中的测试用例可以从已知状态开始。例如, SeleniumLibrary使用GLOBAL范围来在不同的测试用例中使用相同的浏览器,而不必重新打开它,并且它还具有关闭所有浏览器关键字,用于轻松关闭所有打开的浏览器。
使用TEST SUITE范围的示例Python库:
class ExampleLibrary : ROBOT_LIBRARY_SCOPE = '测试套件' def __init__ (self ): self 。_counter = 0 def count (self ): 自我。_counter + = 1 打印 自己。_计数器 def clear_counter (self ): self 。_counter = 0
使用GLOBAL范围的示例Java库:
公共 类 ExampleLibrary { public static final String ROBOT_LIBRARY_SCOPE = “GLOBAL” ; 私人 诠释 计数器 = 0 ; public void count () { counter + = 1 ; 系统。出去。println (counter ); } public void clearCounter () { counter = 0 ; } }
指定库版本
当一个测试库被使用时,Robot Framework会尝试确定它的版本。然后将这些信息写入系统日志 以提供调试信息。库文档工具 Libdoc也将这些信息写入到它生成的关键字文档中。
版本信息是从属性看 ROBOT_LIBRARY_VERSION,类似于测试库范围是从读ROBOT_LIBRARY_SCOPE。如果 ROBOT_LIBRARY_VERSION不存在,则尝试从__version__属性中读取信息。这些属性必须是类或模块属性,具体取决于库是作为类还是模块实现的。对于Java库,版本属性必须声明为static final。
一个示例Python模块使用__version__:
__version__ = '0.1'def 关键字(): 通过
一个Java类使用ROBOT_LIBRARY_VERSION:
公共 类 VersionExample { public static final String ROBOT_LIBRARY_VERSION = “1.0.2” ; public void keyword () { } }
指定文档格式
从Robot Framework 2.7.5开始,库文档工具Libdoc 支持多种格式的文档。如果您想使用Robot Framework自己的文档格式以外的其他功能,可以使用ROBOT_LIBRARY_DOC_FORMAT属性指定源代码中的格式, 范围和版本均使用自己的ROBOT_LIBRARY_*属性进行设置 。
文档格式可能不区分大小写的值是 ROBOT(默认)HTML,TEXT(纯文本)和reST(reStructuredText)。使用该reST格式需要在生成文档时安装docutils模块。
设置文档格式由以下分别使用reStructuredText和HTML格式的Python和Java示例说明。有关记录测试库的更多信息,请参见记录库部分和Libdoc章节。
“”一个用于*文档格式*演示目的的库。这个文档是使用reStructuredText__创建的。这是一个唯一\ Keyword 的链接。__ http://docutils.sourceforge.net “”“ROBOT_LIBRARY_DOC_FORMAT = 'reST'def 关键字(): “”“**没有**看到这里。甚至没有在下面的表。 ======= ===== ===== 这里的表 没有什么可看的。 ======= ===== ===== “”“ 通行证
/ ** *用于文档格式演示目的的库。* *本文档使用 HTML 创建。*这是一个链接到唯一`关键字`。* / public class DocFormatExample { public static final String ROBOT_LIBRARY_DOC_FORMAT = “HTML” ; / ** 没有在这里看到。甚至不在下面的表格中。 * **
标签可能会毁坏日志文件。表 这里 具有 * 没有 < td> to see。 * * / public void keyword () { } } 图书馆充当监听者
侦听器接口允许外部侦听器获得有关测试执行的通知。例如,当套件,测试和关键字开始和结束时,就会调用它们。有时,获取这样的通知对于测试库也是有用的,并且可以通过使用
ROBOT_LIBRARY_LISTENER属性来注册自定义的监听器 。该属性的值应该是要使用的侦听器的实例,可能是库本身。有关更多信息和示例,请参阅将库作为侦听器部分。4.1.3创建静态关键字
什么方法被认为是关键字
当使用静态库API时,Robot Framework使用反射来查找库类或模块实现的公共方法。它将排除以下划线开头的所有方法,并且在Java库中也会
java.lang.Object忽略仅在其中实现的方法 。所有不被忽略的方法都被认为是关键字。例如,下面的Python和Java库实现了单个关键字My Keyword。class MyLibrary : def my_keyword (self , arg ): 返回 自我。_helper_method (arg ) def _helper_method (self , arg ): return arg 。upper ()公共 类 MyLibrary { public String myKeyword (String arg ) { return helperMethod (arg ); } private String helperMethod (String arg ) { return arg 。toUpperCase (); } }当库被实现为Python模块时,也可以通过使用Python的
__all__属性限制关键字的方法 。如果__all__使用,只有在其中列出的方法可以是关键字。例如,下面的库实现关键字示例关键字和第二个示例。没有__all__,它也会实现关键字 不显示为关键字和当前线程。最重要的用法__all__是确保导入的帮助程序方法(current_thread例如下面的示例)不会意外暴露为关键字。从 线程 导入 current_thread__all__ = [ 'example_keyword' , 'second_example' ]def example_keyword (): if current_thread ()。名 == “MainThread” : 打印 “在主线程中运行”def second_example (): passdef not_exposed_as_keyword (): 传递注意
__all__从Robot Framework 2.5.5开始支持该属性。关键字名称
将测试数据中使用的关键字名称与方法名称进行比较,以查找实现这些关键字的方法。名称比较不区分大小写,空格和下划线也被忽略。例如,该方法
hello映射到关键字名称 Hello,hello甚至hello。同样两个do_nothing和doNothing方法可以用来作为 不作为测试数据关键字。示例Python库在MyLibrary.py文件中作为模块实现:
def hello (name ): print “Hello,%s !” % 姓名def do_nothing (): 通过示例Java库在MyLibrary.java文件中作为类实现:
公共 类 MyLibrary { public void hello (String name ) { System 。出去。println (“Hello,” + name + “!” ); } public void doNothing () { }}下面的例子说明了如何使用上面的示例库。如果您想亲自尝试,请确保该库位于库搜索路径中。
使用简单的示例库 设置 值 值 值 图书馆 我的图书馆
测试用例 行动 论据 论据 我的测试 没做什么 你好 世界 关键字参数
使用静态和混合API,关键字需要多少个参数的信息直接来自实现它的方法。使用动态库API的库有其他方法来共享这些信息,所以这一部分与它们无关。
最常见也是最简单的情况是关键字需要确切数量的参数。在这种情况下,Python和Java方法都只是简单地使用这些参数。例如,实现一个没有参数的关键字的方法也没有参数,一个实现一个参数的关键字的方法也需要一个参数,依此类推。
使用不同数量参数的Python关键字示例:
def no_arguments (): print “关键字没有参数”。def one_argument (arg ): print “关键字有一个参数” %s “。 % argdef three_arguments (a1 , a2 , a3 ): print “关键字有三个参数” %s “,” %s “和” %s “。 % (a1 , a2 , a3 )注意
Java库使用静态库API的主要限制是它们不支持命名的参数语法。如果这是一个阻止程序,可以使用Python或切换到动态库API。
默认值为关键字
关键字使用的某些参数具有默认值通常很有用。Python和Java有不同的方法处理默认值的语法,在为Robot Framework创建测试库时,可以使用这些语言的自然语法。
Python的默认值
在Python中,一个方法总是只有一个实现,并且在方法签名中指定了可能的默认值。所有Python程序员都熟悉的语法如下所示:
def one_default (arg = 'default' ): print “参数具有值%s ” % argdef multiple_defaults (arg1 , arg2 = 'default 1' , arg3 = 'default 2' ): print “获得参数%s ,%s 和%s ” % (arg1 , arg2 , arg3 )上面的第一个示例关键字可以用于零个或一个参数。如果没有给出任何参数,则
arg获取该值default。如果只有一个参数,则arg获取该值,并且使用多个参数调用关键字将失败。在第二个示例中,总是需要一个参数,但第二个和第三个参数具有默认值,因此可以使用具有一到三个参数的关键字。
使用可变数量的参数的关键字 测试用例 行动 论据 论据 论据 默认 一个默认 一个默认 论据 多个默认值 要求arg 多个默认值 要求arg 可选的 多个默认值 要求arg 可选1 可选2 Java的默认值
在Java中,一个方法可以有不同签名的几个实现。Robot Framework将所有这些实现视为一个关键字,可以使用不同的参数。这个语法可以用来提供对默认值的支持。下面的例子说明了这一点,它与前面的Python例子在功能上是一致的:
public void oneDefault (String arg ) { System 。出去。println (“Argument has value” + arg ); }public void oneDefault () { oneDefault (“default” ); }public void multipleDefaults (String arg1 , String arg2 , String arg3 ) { System 。出去。println (“有参数” + arg1 + “,” + arg2 + “和” + arg3 ); }public void multipleDefaults (String arg1 , String arg2 ) { multipleDefaults (arg1 , arg2 , “default 2” ); }public void multipleDefaults (String arg1 ) { multipleDefaults (arg1 , “default 1” ); }可变数量的参数(
*varargs)Robot Framework还支持带有任意数量参数的关键字。与默认值类似,在Python和Java中,测试库中使用的实际语法也是不同的。
Python的变量数量是可变的
Python支持接受任意数量参数的方法。在库中也使用相同的语法,正如下面的示例所示,它也可以与其他指定参数的方法结合使用:
高清 any_arguments (* ARGS ): 打印 “得到了论据:” 对 ARG 在 ARGS : 打印 ARG高清 one_required (所需, * 等): 打印 “要求:%S \ n 其他:” % 需要 用于 ARG 在 别人: 打印 ARGdef also_defaults (req , def1 = “default 1” , def2 = “default 2” , * rest ): print req , def1 , def2 , rest
使用具有可变数量参数的关键字 测试用例 行动 论据 论据 论据 可变参数 任何参数 任何参数 论据 任何参数 arg 1 arg 2 arg 2 ... arg 4 arg 5 一个必需 要求arg 一个必需 要求arg 另一个arg 完后还有 还默认 需要 还默认 需要 这两个 有默认值 还默认 1 2 3 ... 4 五 6 Java的变量数量可变
Robot Framework支持用于定义可变数量的参数的Java可变参数语法。例如,以下两个关键字在功能上与以上具有相同名称的Python示例相同:
public void anyArguments (String ... varargs ) { System 。出去。println (“有参数:” ); for (String arg: varargs ) { System 。出去。println (arg ); } }public void oneRequired (String required , String ... others ) { System 。出去。println (“Required:” + required + “\ n其他:” ); for (String arg: others ) { System 。出去。println (arg ); } }
java.util.List如果使用自由关键字参数(** kwargs),也可以使用可变数量的参数,或者从Robot Framework 2.8.3开始, 作为最后一个参数,或者倒数第二个参数。以下示例说明了这一点,它们在功能上与以前的示例相同:public void anyArguments (String [] varargs ) { System 。出去。println (“有参数:” ); for (String arg: varargs ) { System 。出去。println (arg ); } }public void oneRequired (String required , List < String > others ) { System 。出去。println (“Required:” + required + “\ n其他:” ); for (String arg: others ) { System 。出去。println (arg ); } }注意
只
java.util.List支持可变参数,不支持其任何子类型。使用Java关键字来支持可变数量的参数有一个限制:只有当方法有一个签名时才有效。因此,使用默认值和可变参数的Java关键字是不可能的。除此之外,只有Robot Framework 2.8和更新的支持使用带库构造函数的可变参数。
免费的关键字参数(
**kwargs)Robot Framework 2.8使用Python的
**kwargs语法添加了对free关键字参数的支持 。创建测试用例下的Free关键字参数部分讨论了如何使用测试数据中的语法。在本节中,我们看看如何在自定义测试库中实际使用它。用Python免费提供关键字参数
如果您已经很熟悉kwargs是如何与Python一起工作的,那么了解它们如何与Robot Framework测试库一起工作是相当简单的。下面的例子显示了基本功能:
def example_keyword (** stuff ): 用于 名称, 值 的 东西。items (): 打印 名称, 值
使用关键字 **kwargs测试用例 行动 论据 论据 论据 关键字参数 示例关键字 你好=世界 #记录“hello world”。 示例关键字 富= 1 条= 42 #记录'foo 1'和'bar 42'。 基本上,关键字调用结束时的所有使用 命名参数语法的
name=value参数,不匹配任何其他参数,都会以kwargs的形式传递给关键字。为了避免使用类似文字值foo=quux作为一个自由关键字参数,它必须被转义 像foo\=quux。以下示例说明了普通参数,可变参数和kwargs如何协同工作:
高清 various_args (阿根廷, * 可变参数, ** kwargs ): 打印 'ARG:' , ARG 的 值 在 可变参数: 打印 '可变参数:' , 值 的 名称, 值 中的 排序(kwargs 。项目()): 打印 “kwarg: ' , 名字, 价值
使用正常的参数,可变参数和kwargs在一起 测试用例 行动 论据 论据 论据 论据 位置 各种各样的参议院 你好 世界 #记录“arg:hello”和“vararg:world”。 命名 各种各样的参议院 ARG =值 #记录“参数:值”。 Kwargs 各种各样的参议院 a = 1时 B = 2 C = 3 #记录“kwarg:1”,“kwarg:b 2”和“kwarg:c 3”。 各种各样的参议院 C = 3 a = 1时 B = 2 #同上。顺序无关紧要。 位置和kwargs 各种各样的参议院 1 2 千瓦= 3 #Logs'arg:1','vararg:2'和'kwarg:kw 3'。 命名和kwargs 各种各样的参议院 ARG =值 你好=世界 #记录“arg:value”和“kwarg:hello world”。 各种各样的参议院 你好=世界 ARG =值 #同上。顺序无关紧要。 对于上例中使用签名的真实世界示例,请参阅Process Library 中的Run Process和Start Keyword关键字 。
与Java免费的关键字参数
从Robot Framework 2.8.3开始,Java库也支持免费的关键字参数语法。Java本身没有kwargs语法,但是关键字可以有
java.util.Map最后一个参数来指定它们接受kwargs。如果一个Java关键字接受kwargs,Robot Framework会自动
name=value将关键字调用结尾处的所有参数打包为一个关键字Map并将其传递给关键字。例如,下面的示例关键字可以像以前的Python示例一样使用:公共 无效 exampleKeyword (地图< 字符串, 字符串> 的东西): 对 (字符串 键: 东西。中的keySet ()) 系统。出去。的println (键 + “” + 的东西。获得(键));public void variousArgs (String arg , List < String > varargs , Map < String , Object > kwargs ): System 。出去。println (“arg:” + arg ); for (String varg: varargs ) 系统。出去。println (“vararg:” + varg ); for (字符串 键: 克瓦格斯。keySet ()) 系统。出去。的println (“kwarg:” + 键 + “” + kwargs 。获得(键));注意
kwargs参数的类型必须是正确的
java.util.Map,而不是它的任何子类型。注意
与varargs支持类似,支持kwargs的关键字不能有多个签名。
参数类型
通常,关键字参数以字符串形式出现在Robot Framework中。如果关键字需要其他类型,则可以使用 变量或将字符串转换为关键字中所需的类型。使用 Java关键字时,基本类型也会自动被强制转换。
使用Python的参数类型
由于Python中的参数没有任何类型信息,因此在使用Python库时不可能自动将字符串转换为其他类型。调用实现具有正确数量参数的关键字的Python方法总是成功的,但如果参数不兼容,则执行失败。幸运的是,将关键字中的参数转换为合适的类型非常简单:
def connect_to_host (address , port = 25 ): port = int (port ) #...使用Java的参数类型
Java方法的参数有类型,所有的基类都是自动处理的。这意味着测试数据中的正常字符串参数在运行时被强制纠正类型。可以被强制的类型是:
- 整数类型(
byte,short,int,long)- 浮点类型(
float和double)- 该
boolean类型- 上述类型的对象版本,例如
java.lang.Integer对关键字方法的所有签名中具有相同或兼容类型的参数进行强制转换。在下面的例子中,转换可以做到的关键字
doubleArgument和compatibleTypes,但不适合conflictingTypes。public void doubleArgument (double arg ) {}public void compatibleTypes (String arg1 , Integer arg2 ) {} public void compatibleTypes (String arg2 , Integer arg2 , Boolean arg3 ) {}public void conflictingTypes (String arg1 , int arg2 ) {} public void conflictingTypes (int arg1 , String arg2 ) {}如果测试数据有一个包含数字的字符串,则强制与数字类型一起工作,而布尔型数据必须包含字符串
true或false。只有当原始值是来自测试数据的字符串时才会进行强制转换,但当然仍然可以使用包含这些关键字的正确类型的变量。如果关键字有冲突的签名,使用变量是唯一的选择。
使用自动类型强制 测试用例 行动 论据 论据 论据 强迫 双重论据 3.14 双重论据 2E16 # 科学计数法 兼容的类型 你好,世界! 1234 兼容的类型 你好,我们又见面了! -10 真正 没有强制 双重论据 $ {} 3.14 冲突类型 1 $ {2} #必须使用变量 冲突类型 $ {1} 2 从Robot Framework 2.8开始,参数类型强制也适用于 Java库构造函数。
使用装饰器
编写静态关键字时,使用Python的修饰器修改它们有时是有用的。然而,装饰器修改函数签名,并可以混淆机器人框架的内省,当确定哪些参数关键字接受。使用Libdoc创建库文档时以及使用 RIDE时,这是特别有问题的。为了避免这个问题,要么不要使用装饰器,要么使用方便的装饰器模块 来创建保留签名的装饰器。
4.1.4与Robot Framework通信
在调用实现关键字的方法后,可以使用任何机制与被测系统进行通信。然后,它可以发送消息到Robot Framework的日志文件,返回可以保存到变量的信息,最重要的是,报告关键字是否通过。
报告关键字状态
报告关键字状态只需使用例外即可完成。如果执行的方法引发异常,则关键字状态为
FAIL,如果正常返回,则状态为PASS。日志,报告和控制台中显示的错误消息是从异常类型及其消息中创建的。与通用的异常(例如,
AssertionError,Exception,和RuntimeError),仅使用异常消息,并与其他人,在格式被创建的消息ExceptionType: Actual message。从Robot Framework 2.8.2开始,可以避免将异常类型作为前缀添加到失败消息中,也可以使用非泛型异常。这是通过添加一个特殊的
ROBOT_SUPPRESS_NAME属性值为True你的例外。蟒蛇:
class MyError (RuntimeError ): ROBOT_SUPPRESS_NAME = TrueJava的:
公共 类 MyError 扩展 RuntimeException { 公共 静态 最终 布尔 ROBOT_SUPPRESS_NAME = true ; }在所有情况下,对于用户而言,异常消息尽可能是信息性的,这一点很重要。
错误消息中的HTML
从Robot Framework 2.8开始,也可以通过用文本开始消息来获得HTML格式的错误消息
*HTML*:引发 AssertionError (“* HTML * Robot Framework rulez !!” )当在库中引发异常时(例如上面的示例)以及用户在测试数据中提供错误消息时,可以使用此方法。
自动切割长信息
如果错误信息超过40行,则会自动从中间删除,防止报告过长,难以阅读。完整的错误消息总是显示在关键字失败的日志消息中。
回溯
异常的回溯也使用
DEBUG日志级别进行记录。这些消息默认情况下在日志文件中不可见,因为它们对于普通用户来说很少有意思。开发库时,通常使用运行测试是一个好主意--loglevel DEBUG。停止测试执行
从Robot Framework 2.5开始,有可能使测试用例失败,从而 停止整个测试的执行。这是通过在关键字引发的异常上设置一个特殊的
ROBOT_EXIT_ON_FAILURE属性True来完成的。这在下面的例子中说明。蟒蛇:
class MyFatalError (RuntimeError ): ROBOT_EXIT_ON_FAILURE = TrueJava的:
公共 类 MyFatalError 延伸 的RuntimeException { 公共 静态 最终 布尔 ROBOT_EXIT_ON_FAILURE = 真; }尽管失败,继续测试执行
从Robot Framework 2.5开始,即使出现故障,也可以继续执行测试。从测试库发出信号的方式是添加一个特殊的
ROBOT_CONTINUE_ON_FAILURE属性,True用来传递失败的异常。下面的例子说明了这一点。蟒蛇:
类 MyContinuableError (RuntimeError ): ROBOT_CONTINUE_ON_FAILURE = 真Java的:
公共 类 MyContinuableError 延伸 RuntimeException { 公共 静态 最终 布尔 ROBOT_CONTINUE_ON_FAILURE = true ; }记录信息
异常消息不是向用户提供信息的唯一方式。除此之外,方法还可以简单地通过写入标准输出流(stdout)或标准错误流(stderr)来将消息发送到日志文件,甚至可以使用不同的 日志级别。另外一种更好的记录方式是使用编程式日志记录API。
默认情况下,由方法写入标准输出的所有内容都将作为具有日志级别的单个条目写入日志文件
INFO。写入标准错误的消息的处理方式与此类似,但是在关键字执行完成之后,它们会回传到原始标准错误。因此,如果需要在执行测试的控制台上显示一些消息,则可以使用stderr。使用日志级别
要使用其它日志级别高于
INFO或创建多个邮件,明确地通过嵌入水平进入格式邮件指定的日志级别*LEVEL* Actual log message,其中*LEVEL*必须在一行的开头,LEVEL是可用的日志记录级别之一TRACE,DEBUG,INFO,WARN,FAIL和HTML。警告
具有
WARN级别的消息会自动写入控制台,并记入日志文件中单独的“测试执行错误”部分。这使得警告比其他消息更加明显,并允许使用它们向用户报告重要但非关键的问题。记录HTML
通常由库所记录的所有内容都将被转换成可以安全地表示为HTML的格式。例如,
foo将显示在日志完全一样,而不是foo。如果图书馆想要使用格式化,链接,显示图像等,他们可以使用一个特殊的伪日志级别HTML。Robot Framework会将这些消息直接写入日志中INFO,这样他们可以使用任何他们想要的HTML语法。请注意,这个功能需要谨慎使用,因为,例如,一个放置不好的使用公共日志记录API时,各种日志记录方法都具有可选的
html属性,可将其设置True为启用HTML格式的日志记录。
时间戳
默认情况下,当执行的关键字结束时,通过标准输出或错误流记录的消息会得到它们的时间戳。这意味着时间戳不准确,调试问题尤其是长时间运行的关键字可能会产生问题。
从Robot Framework 2.6开始,如果有需要的话,关键字可以为他们记录的消息添加一个准确的时间戳。自Unix时代起,时间戳必须以毫秒为单位给出,并且它必须放置在用冒号分隔的日志级别之后:
*信息:1308435758660 *带时间戳的信息* HTML:1308435758661 *带有时间戳的 HTML 消息
如下面的例子所示,添加时间戳很容易使用Python和Java。如果您使用的是Python,那么使用编程式日志记录API来获取准确的时间戳就更容易了。明确添加时间戳的一大好处是,这种方法也适用于远程库接口。
蟒蛇:
进口 时间DEF EXAMPLE_KEYWORD (): 打印 '* INFO:%d 时间戳*消息' % (时间。时间()* 1000 )
Java的:
public void exampleKeyword () { System 。出去。的println (“* INFO:” + 系统。的currentTimeMillis () + “*消息具有时间戳” ); }
记录到控制台
如果图书馆需要写一些东西给控制台,他们有几个选择。如前所述,写入标准错误流的警告和所有消息都写入日志文件和控制台。这两个选项都有一个局限性,只有在当前执行的关键字结束之后,这些消息才会终止到控制台。一个好处是,这些方法与基于Python和Java的库一起工作。
另一个选项,只能用于Python,正在写邮件到sys.__stdout__或sys.__stderr__。使用这种方法时,消息立即写入控制台,根本不写入日志文件:
导入 系统def my_keyword (arg ): sys 。__stdout__ 。写('有arg %s \ n ' % arg )
最后的选择是使用公共日志API:
从 robot.api 导入 记录器def log_to_console (arg ): 记录器。控制台('有arg %s ' % arg )def log_to_console_and_log_file (arg ) 记录器。info (' got arg %s ' % arg , also_console = True )
记录示例
在大多数情况下,这个INFO级别是足够的。低于它的级别, DEBUG并且TRACE,是用来写字的调试信息非常有用。这些消息通常不会显示,但它们可以方便地调试库中的可能的问题。该WARN级别可以用来使消息更加可见,并且HTML如果需要任何种类的格式化是有用的。
以下示例阐明了如何使用不同级别的日志进行工作。Java程序员应该把代码print 'message' 看作伪代码的意思System.out.println("message");。
打印 “图书馆的你好” 打印 '*警告*来自图书馆的警告。打印 '*信息*再次您好!打印 “这将成为之前的消息的一部分。打印 '*信息*这是一个新的消息。打印 '*信息*这是普通文字。print '* HTML *这是粗体。打印 '* HTML * 机器人框架'
| 16:18:42.123 | 信息 | 你好,从图书馆。 |
| 16:18:42.123 | 警告 | 来自图书馆的警告。 |
| 16:18:42.123 | 信息 | 再一次问好! 这将是以前的消息的一部分。 |
| 16:18:42.123 | 信息 | 这是一个新的消息。 |
| 16:18:42.123 | 信息 | 这是普通文字。 |
| 16:18:42.123 | 信息 | 这是大胆的。 |
| 16:18:42.123 | 信息 | 机器人框架 |
程序化日志API
与使用标准输出和错误流相比,程序化API提供了更清晰的信息记录方式。目前这些接口仅适用于Python基础测试库。
公共日志记录API
Robot Framework 2.6有一个新的基于Python的日志记录API,用于将消息写入日志文件和控制台。测试库可以使用这个API,logger.info('My message')而不是像标准输出一样记录print '*INFO* My message'。除了使用更加清洁的编程接口之外,此API还具有日志消息具有准确时间戳的优点。一个明显的限制是使用这个日志API的测试库对Robot Framework有依赖性。
公共日志API 在https://robot-framework.readthedocs.org中作为API文档的一部分进行了详细记录。以下是一个简单的用法示例:
从 robot.api 导入 记录器def my_keyword (arg ): 记录器。调试('有参数%s ' % arg ) do_something () 记录器。info ('这个是一个无聊的例子' , html = True ) 记录器。控制台('Hello,console!' )
使用Python的标准logging模块
除了新的公共日志API外,Robot Framework 2.6还为Python的标准日志记录模块添加了一个内置的支持。这可以使模块的根记录器接收的所有消息自动传播到Robot Framework的日志文件。此API 也会生成具有准确时间戳的日志消息,但不支持记录HTML消息或将消息写入控制台。下面这个简单的例子也说明了一个很大的好处,就是使用这个日志API不会对Robot Framework产生任何依赖。
导入 日志def my_keyword (arg ): 日志记录。调试('有参数%s ' % arg ) do_something () 日志记录。info ('这是一个无聊的例子' )
该logging模块的日志级别与Robot Framework略有不同。它的级别DEBUG,INFO并直接映射到匹配的机器人框架日志级别和WARNING 以上的一切都映射到WARN。自定义级别低于 DEBUG被映射到DEBUG之间的一切, DEBUG并且WARNING被映射到INFO。
在库初始化期间记录
在测试库导入和初始化期间,库也可以记录。这些消息不像正常的日志消息那样出现在日志文件中,而是写入系统日志。这允许记录关于库初始化的任何有用的调试信息。使用该WARN级别记录的消息也可以在 日志文件的测试执行错误部分中看到。
在导入和初始化期间进行记录可以使用 标准输出和错误流以及编程式日志记录API。这两个都在下面演示。
Java库在初始化期间通过stdout进行日志记录:
公共 类 LoggingDuringInitialization { 公共 LoggingDuringInitialization () { 系统。出去。println (“* INFO *初始化库” ); } public void keyword () { // ... } }
导入期间使用日志记录API的Python库日志记录:
从 robot.api 导入 记录器记录器。调试(“导入库” )def 关键字(): #...
注意
如果你在初始化过程中记录了一些东西,例如在Python __init__或Java构造函数中,根据测试库的作用域,这些消息可能被记录多次。
注意
在Robot初始化期间对日志消息写入syslog的支持是Robot Framework 2.6中的一个新特性。
返回值
关键字返回到核心框架的最后一种方式是返回从测试系统中检索或通过其他方式生成的信息。返回的值可以分配给测试数据中的变量,然后用作其他关键字的输入,即使是来自不同的测试库。
使用returnPython和Java方法中的语句返回值。通常,将一个值分配到一个 标量变量中,如下例所示。这个例子还说明可以返回任何对象并使用 扩展变量语法来访问对象属性。
从 mymodule 导入 MyObjectdef return_string (): return “Hello,world!”def return_object(name ): return MyObject (name )
| $ {string} = | 返回字符串 | |
| 应该是平等的 | $ {}字符串 | 你好,世界! |
| $ {object} = | 返回对象 | 机器人 |
| 应该是平等的 | $ {} object.name | 机器人 |
关键字还可以返回值,以便可以将它们分配到几个标量变量中,列表变量或标量变量和列表变量中。所有这些用法都要求返回的值是Python列表或元组,或者Java数组,列表或迭代器。
def return_two_values (): 返回 '第一个值' , '第二个值'def return_multiple_values (): return [ 'a' , 'list' , 'of' , 'strings' ]
| $ {VAR1} | $ {var2} = | 返回两个值 | |
| 应该是平等的 | $ {VAR1} | 第一价值 | |
| 应该是平等的 | $ {} VAR2 | 第二值 | |
| @ {list} = | 返回两个值 | ||
| 应该是平等的 | @ {列表} [0] | 第一价值 | |
| 应该是平等的 | @ {列表} [1] | 第二值 | |
| $ {} S1 | $ {} S2 | @ {li} = | 返回多个值 |
| 应该是平等的 | $ {s1} $ {s2} | 一个列表 | |
| 应该是平等的 | @ {li} [0] @ {li} [1] | 的字符串 |
使用线程时的通信
如果库使用线程,它通常应该只从主线程与框架进行通信。例如,如果一个工作者线程有报告失败或某些事情要记录,它应该首先将信息传递给主线程,然后主线程可以使用本节中介绍的异常或其他机制来与框架进行通信。
当线程在其他关键字运行时在后台运行时,这一点尤为重要。在这种情况下与框架进行通信的结果是未定义的,并且可以在最坏的情况下导致崩溃或损坏的输出文件。如果关键字在后台启动,则应该有另一个关键字来检查工作线程的状态并相应地收集收集的信息。
注意
从Robot Framework 2.6.2开始,非主线程使用编程式日志记录API记录的信息被忽略。
4.1.5分发测试库
记录库
没有关于它包含什么关键字的文档的测试库以及这些关键字所做的事情是没用的。为了便于维护,强烈建议将图书馆文档包含在源代码中并由其生成。基本上,这意味着在Python中使用docstrings,在Java中使用Javadoc,如下面的示例所示。
class MyLibrary : “”“这是一个带有一些文档的示例库。”“” def keyword_with_short_documentation (self , argument ): “”“这个关键字只有一个简短的文档”“” pass def keyword_with_longer_documentation (self ): “”“文档的第一行就在这里。 更长的文档继续在这里,它可以包含 多行或段落。 “” 通过
/ ** *这是一个包含一些文档的示例库。* / public class MyLibrary { / ** *这个关键字只有一个简短的文档 * / public void keywordWithShortDocumentation (String argument ) { } / ** *文档的第一行是在这里。 * *更长的文档继续在这里,它可以包含 *多行或段落。 * / public void keywordWithLongerDocumentation () { }}
Python和Java都有创建如上所述的库的API文档的工具。但是,这些工具的输出对于某些用户来说可能是稍微技术性的。另一种选择是使用Robot Framework自己的文档工具Libdoc。此工具可以使用静态库API(如上面的库)从Python和Java库创建库文档,但也可以使用动态库API和混合库API处理库。
关键字文档的第一行用于特殊用途,并应包含对关键字的简短描述。它被用作一个简短的文档,比如作为Libdoc的一个工具提示,也显示在测试日志中。但是,后者不能与使用静态API的Java库一起工作,因为它们的文档在编译时会丢失,在运行时不可用。
默认情况下,文档被认为是遵循Robot Framework的 文档格式规则。这个简单的格式允许经常使用的样式,比如*bold*和_italic_,表格,列表,链接等从机器人框架2.7.5开始,可以使用HTML也,纯文本和新结构化格式。有关 如何设置库源代码和Libdoc章节中的格式的更多信息,请参阅指定文档格式部分 。
注意
如果要在Python库的文档中使用非ASCII字符,则必须使用UTF-8作为源代码编码,或者将Unicode文档创建为Unicode。
测试库
任何非平凡的测试库都需要进行彻底的测试,以防止其中的错误。当然,这个测试应该是自动化的,以便在库改变时重新运行测试。
Python和Java都有出色的单元测试工具,而且它们非常适合测试库。与使用它们进行一些其他测试相比,使用它们没有什么重大差别。熟悉这些工具的开发人员不需要学习任何新东西,不熟悉这些工具的开发人员也应该学习它们。
使用Robot Framework本身也可以很方便地测试库,这样就可以对它们进行实际的端到端验收测试。为此,在BuiltIn库中有许多有用的关键字。值得一提的是运行关键字和期望错误,这对于测试关键字报告错误是非常有用的。
是否使用单元级或接受级测试方法取决于上下文。如果需要模拟被测试的实际系统,则在单元级别上通常更容易。另一方面,验收测试确保关键字通过Robot Framework工作。如果你不能决定,当然可以使用这两种方法。
打包库
库实现,记录和测试后,仍然需要分发给用户。对于由单个文件组成的简单库,通常要求用户将该文件复制到某处并相应地设置库搜索路径。应该打包更复杂的库以使安装更容易。
由于库是正常的编程代码,因此可以使用普通的打包工具进行打包。使用Python,很好的选择包括Python标准库包含的 distutils和更新的 setuptools。这些工具的好处是,库模块安装到库搜索路径中自动的位置。
使用Java时,将库打包到JAR归档中是很自然的。 在运行测试之前,必须将JAR包放入库搜索路径中,但创建一个可自动执行的启动脚本很容易。
弃用关键字
有时需要用新的关键字替换现有的关键字,或者将其全部删除。只是通知用户有关更改可能并不总是足够的,并且在运行时得到警告更有效。为了支持这一点,Robot Framework有能力标记不赞成使用的关键字。这样可以更轻松地从测试数据中找到旧关键字并删除或替换它们。
关键字通过使用文档开始被弃用 *DEPRECATED*。执行这些关键字时,将包含其余短文档的警告写入 控制台,并写入日志文件中单独的“测试执行错误”部分。例如,如果执行以下关键字,则会在日志文件中显示如下所示的警告。
def example_keyword (argument ): “”“* DEPRECATED *改用关键字`Other Keyword`。 这个关键字做了一些给定的参数,并返回结果。 “”“ return do_something (argument )
| 20080911 16:00:22.650 | 警告 | 关键字“SomeLibrary.Example关键字”已被弃用。改为使用关键字“其他关键字”。 |
这个弃用系统适用于大多数测试库以及 用户关键字。唯一的例外是在使用静态库接口的Java测试库中实现的关键字,因为它们的文档在运行时不可用。使用这样的关键字,可以使用用户关键字作为包装,并将其弃用。
有一个计划,实施一个工具,可以使用弃用信息自动替换弃用的关键字。该工具很可能会从文档中获取新关键字的名称,以便在反引号内搜索单词(`)。因此,它会从前面的例子中找到其他关键字。请注意,Libdoc也使用相同的语法自动创建内部链接。
4.1.6动态库API
动态API在很大程度上类似于静态API。例如,报告关键字状态,日志记录和返回值的工作方式完全相同。最重要的是,与其他库相比,导入动态库和使用关键字没有区别。换句话说,用户不需要知道他们的库使用什么API。
静态库和动态库之间的区别仅在于Robot Framework如何发现库实现的关键字,这些关键字具有哪些参数和文档,以及关键字是如何实际执行的。使用静态API,所有这些都是使用反射(Java库的文档除外)完成的,但是动态库具有用于这些目的的特殊方法。
动态API的好处之一是,您可以更灵活地组织库。使用静态API,您必须在一个类或模块中包含所有关键字,而使用动态API,则可以将每个关键字作为单独的类来实现。但是,这个用例对于Python来说并不是那么重要,因为它的动态能力和多重继承已经给了很大的灵活性,并且还有可能使用混合库API。
动态API的另一个主要用例是实现一个库,以便它可以作为可能在其他进程或甚至另一台机器上运行的实际库的代理。这种代理库可能非常薄,而且由于关键字名称和所有其他信息是动态获取的,所以当新的关键字添加到实际库时,不需要更新代理。
本节介绍动态API如何在Robot Framework和动态库之间起作用。Robot Framework如何实现这些库并不重要(例如,如何将调用run_keyword方法映射到正确的关键字实现),并且可能有许多不同的方法。但是,如果您使用Java,则可能需要 在实现自己的系统之前检查 JavalibCore。这个可重复使用的工具集合支持多种创建关键字的方式,而且它很可能已经有了一个满足您需求的机制。
获取关键字名称
动态库告诉他们用这个get_keyword_names方法实现了什么关键字 。该方法还具有getKeywordNames使用Java时推荐的别名 。此方法不能接受任何参数,它必须返回包含库实现的关键字名称的字符串列表或数组。
如果返回的关键字名称包含多个单词,则可以用空格或下划线或camelCase格式将它们返回。例如['first keyword', 'second keyword'], ['first_keyword', 'second_keyword']和 ['firstKeyword', 'secondKeyword']都会被映射到关键字 的第一关键字和第二关键字。
动态库必须总是有这个方法。如果缺失,或者由于某种原因调用失败,则该库被认为是一个静态库。
运行关键字
动态库有一个特殊的run_keyword(别名 runKeyword)方法来执行他们的关键字。当测试数据中使用动态库中的关键字时,Robot Framework使用库的run_keyword方法来执行它。这个方法有两个或三个参数。第一个参数是一个字符串,其中包含要以与返回的格式相同的格式执行的关键字的名称get_keyword_names。第二个参数是给测试数据中关键字的参数列表或数组。
可选的第三个参数是一个字典(Java中的地图),它可以获得传递给关键字的可能的关键字参数(**kwargs)。有关在动态库中使用kwargs的更多详细信息,请参见动态库的免费关键字参数。
获得关键字名称和参数后,库可以自由执行关键字,但必须使用相同的机制作为静态库与框架进行通信。这意味着使用异常来报告关键字状态,通过写入标准输出或使用提供的日志API进行日志记录,并使用return语句run_keyword返回某些内容。
每个动态库必须同时拥有get_keyword_names和 run_keyword方法,但动态API中的其余方法是可选的。下面的例子展示了一个在Python中实现的工作,虽然很简单,动态的库。
类 DynamicExample : def get_keyword_names (self ): return [ 'first keyword' , 'second keyword' ] def run_keyword (self , name , args ): print “运行带参数%s的关键字' %s ' 。%(名称,参数)
获取关键字参数
如果一个动态库只实现了get_keyword_names和 run_keyword方法,Robot Framework没有关于实现的关键字需要的参数的任何信息。例如,上面例子中的First Keyword和Second Keyword都可以和任意数量的参数一起使用。这是有问题的,因为大多数真正的关键字需要一定数量的关键字,在这种情况下,他们需要检查参数计数本身。
动态库可以通过使用get_keyword_arguments (别名getKeywordArguments)方法告诉Robot Framework它实现的关键字是什么参数。此方法将关键字的名称作为参数,并返回包含由该关键字接受的参数的字符串列表或数组。
与静态关键字类似,动态关键字可以要求任意数量的参数,具有默认值,并接受可变数量的参数和可用的关键字参数。下表说明了如何表示所有这些不同变量的语法。请注意,这些示例对列表使用Python语法,但Java开发人员应该使用Java列表或字符串数组。
| 预期的论点 | 如何表示 | 例子 | 限制(最小/最大) |
|---|---|---|---|
| 没有参数 | 空的清单。 |
[]
|
0/0
|
| 一个或多个论点 | 包含参数名称的字符串列表。 |
['one_argument']
['a1', 'a2', 'a3']
|
1/1
3/3
|
| 参数的默认值 | 默认值与名称分开=。默认值始终被认为是字符串。 |
['arg=default value']
['a', 'b=1', 'c=2']
|
0/1
1/3
|
| 可变数量的参数(可变参数) | 最后(或者倒数第二个用kwargs)的参数* 在它的名字前面。 |
['*varargs']
['a', 'b=42', '*rest']
|
0 /任何
1 /任何
|
| 免费的关键字参数(kwargs) | 最后的参数 **在它的名字之前。 |
['**kwargs']
['a', 'b=42', '**kws']
['*varargs', '**kwargs']
|
0/0
1/2
0 /任何
|
当get_keyword_arguments使用时,机器人框架自动计算关键字多少位置参数需要和它支持自由关键字参数或没有。如果关键字与无效参数一起使用,则会发生错误,run_keyword甚至不会被调用。
返回的实际参数名称和默认值也很重要。他们都需要命名参数的支持和Libdoc 工具需要他们能够创造一个有意义的库文件。
如果get_keyword_arguments缺少或返回None或 null某个关键字,该关键字将获得一个接受所有参数的参数说明。这个自动参数规范是 [*varargs, **kwargs]或者[*varargs],依赖有三个参数或不 run_keyword 支持kwargs。
获取关键字文档
动态库可以实现的最后一个特殊方法是 get_keyword_documentation(别名 getKeywordDocumentation)。它将一个关键字名称作为参数,并且如方法名称所示,将其文档作为字符串返回。
返回的文档与关键字文档字符串的用法类似,用Python实现静态库。主要的用例是将关键字的文档写入由Libdoc生成的库文档中。此外,文档的第一行(直到第一行\n)显示在测试日志中。
获得通用库文档
该get_keyword_documentation方法也可用于指定整个库文档。在执行测试时不会使用这个文档,但它可以使Libdoc生成的文档好得多。
动态库可以提供通用库文档和与使用库相关的文档。前者是通过get_keyword_documentation具有特殊价值的召唤而 获得的__intro__,而后者是通过价值获得的 __init__。如何使用Libdoc最好地测试文档。
基于Python的动态库也可以直接在代码中指定通用库文档作为库类及其__init__方法的文档字符串。如果直接从代码和get_keyword_documentation方法中获得非空文档 ,则后者具有优先权。
注意
Robot Framework 2.6.2及更新版本支持获取通用库文档。
用动态库命名参数语法
从Robot Framework 2.8开始,动态库API也支持命名的参数语法。使用语法工作基于参数名称和使用该 方法从库中获得的默认值get_keyword_arguments。
对于大多数部分来说,命名参数语法与动态关键字完全一样,就像它支持它的任何其他关键字一样。唯一的特例是一个关键字有多个参数的情况,其中只有一些是默认值。在这种情况下,框架会根据get_keyword_arguments方法返回的缺省值填充跳过的可选参数。
以下示例说明了在动态库中使用命名的参数语法。所有的例子都使用一个关键字Dynamic 来指定参数指定 [arg1, arg2=xxx, arg3=yyy]。最后一列显示关键字实际被调用的参数。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 跟随 |
|---|---|---|---|---|---|
| 只有位置 | 动态 | 一个 | # [一个] | ||
| 动态 | 一个 | b | #[a,b] | ||
| 动态 | 一个 | b | C | #[a,b,c] | |
| 命名 | 动态 | 一个 | ARG2 = B | #[a,b] | |
| 动态 | 一个 | b | ARG3 = C | #[a,b,c] | |
| 动态 | 一个 | ARG2 = B | ARG3 = C | #[a,b,c] | |
| 动态 | ARG1 =一 | ARG2 = B | ARG3 = C | #[a,b,c] | |
| 填写跳过 | 动态 | 一个 | ARG3 = C | #[a,xxx,c] |
免费关键字参数与动态库
从Robot Framework 2.8.2开始,动态库也可以支持 免费的关键字参数(**kwargs)。这种支持的强制性前提是该run_keyword方法有三个参数:第三个参数在使用时会得到kwargs。Kwargs作为字典(Python)或Map(Java)传递给关键字。
关键字接受什么参数取决于get_keyword_arguments 返回值。如果最后一个参数开始**,该关键字被识别为接受kwargs。
以下示例说明了如何在动态库中使用免费关键字参数语法。所有的例子都使用一个关键字Dynamic 来指定参数指定 [arg1=xxx, arg2=yyy, **kwargs]。最后一列显示关键字实际被调用的参数。
| 测试用例 | 行动 | 论据 | 论据 | 论据 | 跟随 |
|---|---|---|---|---|---|
| 没有参数 | 动态 | #[],{} | |||
| 只有位置 | 动态 | 一个 | # [一个], {} | ||
| 动态 | 一个 | b | #[a,b],{} | ||
| 只有kwargs | 动态 | a = 1时 | #[],{a:1} | ||
| 动态 | a = 1时 | B = 2 | C = 3 | #[],{a:1,b:2,c:3} | |
| 位置和kwargs | 动态 | 一个 | B = 2 | #[a],{b:2} | |
| 动态 | 一个 | B = 2 | C = 3 | #[a],{b:2,c:3} | |
| 命名和kwargs | 动态 | ARG1 =一 | B = 2 | #[a],{b:2} | |
| 动态 | ARG2 =一 | B = 2 | C = 3 | #[xxx,a],{b:2,c:3} |
概要
下表列出了动态API中的所有特殊方法。方法名称以下划线格式列出,但其camelCase别名的工作方式完全相同。
| 名称 | 参数 | 目的 |
|---|---|---|
get_keyword_names |
返回实施的关键字的名称。 | |
run_keyword |
name, arguments, kwargs |
用给定的参数执行指定的关键字。kwargs是可选的。 |
get_keyword_arguments |
name |
返回关键字的参数说明。可选方法。 |
get_keyword_documentation |
name |
返回关键字“和库的文档。可选方法。 |
用Java编写一个正式的接口规范是可能的,如下所示。但是,请记住,图书馆不需要实现任何显式的接口,因为机器人框架直接与反射检查,如果库具有所需get_keyword_names和 run_keyword方法或者其驼峰的别名。此外, get_keyword_arguments和get_keyword_documentation 完全是可选的。
公共 接口 RobotFrameworkDynamicAPI { List < String > getKeywordNames (); 对象 runKeyword (字符串 名称, 列表 参数); Object runKeyword (String name , List arguments , Map kwargs ); List < String > getKeywordArguments (String name ); String getKeywordDocumentation (String name );}
注意
除了使用List,还可以使用像Object[]或者数组String[]。
使用动态API的一个很好的例子是Robot Framework自己的 远程库。
4.1.7混合库API
顾名思义,混合库API就是静态API和动态API的混合体。就像使用动态API一样,使用混合API只能作为一个类来实现库。
获取关键字名称
关键字名称的获取方式与动态API完全相同。在实践中,库需要让 get_keyword_namesor getKeywordNames方法返回库实现的关键字名称列表。
运行关键字
在混合API中,没有run_keyword执行关键字的方法。相反,Robot Framework使用反射来查找实现关键字的方法,类似于静态API。使用混合API的库可以直接实现这些方法,更重要的是,它可以动态地处理它们。
在Python中,用这个方法动态地处理缺失的方法是很容易的 __getattr__。大多数Python程序员可能都熟悉这种特殊的方法,他们可以立即理解下面的例子。其他人可能会首先查阅Python参考手册更容易。
从 某处 导入 external_keyword类 HybridExample : def get_keyword_names (self ): return [ 'my_keyword' , 'external_keyword' ] def my_keyword (self , arg ): print “我的关键字用%s 调用” % arg def __getattr__ (self , name ): if name == 'external_keyword' : return external_keyword raise AttributeError (“不存在的属性' %s '” % name )
请注意,__getattr__不像run_keyword动态API 那样执行实际的关键字 。相反,它只返回一个由Robot Framework执行的可调用对象。
还有一点需要注意的是,Robot Framework使用相同的名称get_keyword_names来查找实现它们的方法。因此,在类中实现的方法的名称必须以与定义的格式相同的格式返回。例如,上面的库不能正常工作,如果 get_keyword_names返回My Keyword而不是my_keyword。
混合API对于Java来说并不是非常有用,因为不可能用它来处理丢失的方法。当然,也可以在库类中实现所有的方法,但是与静态API相比,这并没有什么好处。
获取关键字参数和文档
当使用这个API时,Robot Framework使用反射来查找实现关键字的方法,类似于静态API。在获得对该方法的引用后,它将以与使用静态API相同的方式从其中搜索参数和文档。因此,不需要像动态API那样获取参数和文档的特殊方法。
概要
在Python中实现测试库时,混合API具有与实际动态API相同的动态功能。一个很大的好处是,没有必要有特殊的方法来获取关键字参数和文档。只有真正的动态关键字需要处理,__getattr__而其他的则可以直接在主库类中实现。
由于明确的优势和相同的功能,在使用Python时,混合API在大多数情况下是比动态API更好的选择。一个值得注意的例外是将库实现为其他地方实际库实现的代理,因为那么实际的关键字必须在别处执行,并且代理只能传递关键字名称和参数。
使用混合API的一个很好的例子是Robot Framework自己的 Telnet库。
4.1.8使用Robot Framework的内部模块
使用Python实现的测试库可以使用Robot Framework的内部模块,例如获取有关执行的测试和使用的设置的信息。但是,这个与框架进行通信的强大机制应该谨慎使用,因为所有Robot Framework的API并不是用于外部的,它们可能会在不同的框架版本之间发生根本性的变化。
可用的API
从Robot Framework 2.7开始,API文档单独存在于Read the Docs服务中。如果您不确定如何使用某些API或正在使用它们向前兼容,请发送问题到邮件列表。
使用BuiltIn库
要使用的最安全的API是在BuiltIn库中实现关键字的方法 。对关键字的更改很少见,而且始终是这样做的,因为旧的用法首先被弃用。最有用的方法之一是replace_variables允许访问当前可用的变量。下面的例子演示了如何获得 ${OUTPUT_DIR}这是许多方便的自动变量之一。它也可以使用图书馆设置新的变量set_test_variable,set_suite_variable和 set_global_variable。
进口 os.path中从 robot.libraries.BuiltIn 进口 内建DEF do_something (参数): 输出 = do_something_that_creates_a_lot_of_output (参数) outputdir = 内建() 。replace_variables ('$ {OUTPUTDIR}' ) path = os 。路径。join (outputdir , 'results.txt' ) f = open (path , 'w' ) f 。写(输出) f 。关() 打印 '* HTML *输出写入 results.txt
使用方法的唯一方法BuiltIn就是所有 run_keyword方法变体都必须专门处理。使用run_keyword方法的方法必须使用模块中的 方法自己注册为运行关键字。这个方法的文档解释了为什么需要这样做,显然也是如何做到这一点。register_run_keywordBuiltIn
4.1.9扩展现有的测试库
本节介绍了如何向现有测试库添加新功能以及如何在自己的库中使用它们的不同方法。
修改原始源代码
如果您有权访问要扩展的库的源代码,则可以直接修改源代码。这种方法的最大问题是,你可能很难更新原始库而不影响你的改变。对于用户来说,使用具有与原始功能不同的功能的库也可能会引起混淆。重新包装图书馆也可能是一个很大的额外任务。
如果增强功能是通用的,并且您计划将其提交给原始开发人员,则此方法非常有效。如果您的更改应用于原始库,则会将其包含在将来的版本中,并缓解上面讨论的所有问题。如果更改是非通用的,或者由于某些其他原因您无法将其提交回来,那么后面部分中解释的方法可能会更好。
使用继承
扩展现有库的另一个直接方法是使用继承。下面的例子说明了这一点,即将SeleniumLibrary中的关键字添加到新的 标题。这个例子使用Python,但是显然可以用Java代码以相同的方式扩展现有的Java库。
从 SeleniumLibrary 导入 SeleniumLibrary类 ExtendedSeleniumLibrary (SeleniumLibrary ): def title_should_start_with (self , expected ): title = self 。get_title () 如果 不是 标题。startswith (预期): raise AssertionError (“标题' %s '没有以' %s '开始” % (title , expected ))
与修改原始库相比,这种方法有一个很大的不同之处在于新库的名称与原始库不同。一个好处是,你可以很容易地告诉你正在使用一个自定义的库,但一个大问题是,你不能轻易地使用原来的新库。首先,你的新图书馆将有相同的关键字,原来的意思,总是有 冲突。另一个问题是,图书馆不分享他们的状态。
当您开始使用新的库并希望从头开始添加自定义增强功能时,此方法可以很好地工作。否则本节中解释的其他机制可能会更好。
直接使用其他库
因为测试库在技术上只是类或模块,所以使用另一个库的简单方法是导入它并使用它的方法。当方法是静态的并且不依赖于库状态时,这种方法效果很好。前面使用Robot Framework的BuiltIn库的例子说明了这一点。
如果图书馆有国家,然而,事情可能不会像你所希望的那样工作。您在库中使用的库实例不会与框架使用的相同,因此执行的关键字所做的更改对您的库不可见。下一节将介绍如何访问框架使用的同一个库实例。
从Robot Framework获取活动的库实例
Robot Framework 2.5.2添加了新的BuiltIn关键字Get Library Instance,它可以用来从框架本身获取当前活动的库实例。这个关键字返回的库实例与框架本身使用的相同,因此看到正确的库状态没有问题。尽管此功能可用作关键字,但它通常通过导入BuiltIn库类来直接在测试库中使用,如前所述。下面的例子说明了如何使用继承来实现相同的标题应该从关键字开始。
从 robot.libraries.BuiltIn 导入 BuiltIndef title_should_start_with (预期): seleniumlib = BuiltIn ()。get_library_instance ('SeleniumLibrary' ) title = seleniumlib 。get_title () 如果 不是 标题。startswith (预期): raise AssertionError (“标题' %s '没有以' %s '开始” % (title , expected ))
这种方法显然比直接导入库并在库有状态时使用它更好。继承的最大好处是可以正常使用原始库,并在需要时使用新库。这在下面的例子中得到了证明,在这个例子中,来自前面例子的代码可以在新的库SeLibExtensions中使用。
| 设置 | 值 | 值 | 值 |
|---|---|---|---|
| 图书馆 | SeleniumLibrary | ||
| 图书馆 | SeLibExtensions |
| 测试用例 | 行动 | 论据 | 论据 |
|---|---|---|---|
| 例 | 打开浏览器 | HTTP://例子 | #SeleniumLibrary |
| 标题应该以 | 例 | #SeLibExtensions |
使用动态或混合API的库
使用动态或混合库API的测试库通常有自己的系统如何扩展它们。有了这些库,您需要向图书馆开发人员询问指导,或查阅图书馆文档或源代码。
4.2远程库接口
远程库接口提供了在不同于机器人框架本身运行的机器上安装测试库的方法,也可以使用除本机支持的Python和Java之外的其他语言来实现库。对于测试库用户而言,远程库看起来与其他测试库几乎相同,使用远程库接口开发测试库也非常接近创建常规测试库。
- 4.2.1简介
- 4.2.2使用远程库
- 导入远程库
- 启动和停止远程服务器
- 4.2.3支持的参数和返回值类型
- 4.2.4远程协议
- 必需的方法
- 获取远程关键字名称和其他信息
- 执行远程关键字
- 不同的参数语法
4.2.1简介
使用远程库API有两个主要原因:
- 在不同机器上运行Robot Framework的地方可能有实际的库。这为分布式测试提供了有趣的可能。
- 测试库可以使用任何支持XML-RPC协议的语言来实现 。在写这篇文章的时候,已经有针对Python,Java,Ruby,.NET,Clojure,Perl和node.js的现成的远程服务器。
远程库接口由作为标准库之一的远程库提供。这个库没有自己的关键字,但它作为核心框架和其他地方实现的关键字之间的代理。远程库通过远程服务器与实际库实现进行交互,远程库和服务器使用XML-RPC通道上的简单远程协议进行通信。所有这些的高层架构如下图所示:
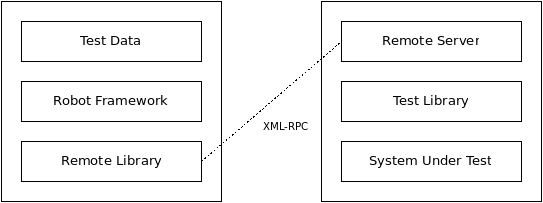
带有远程库的Robot Framework体系结构
注意
远程客户端使用Python的标准xmlrpclib模块。它不支持由某些XML-RPC服务器实现的自定义XML-RPC扩展。
4.2.2使用远程库
导入远程库
远程库需要知道远程服务器的地址,否则导入并使用它提供的关键字与其他库的使用方式没有什么不同。如果您需要在测试套件中多次使用远程库,或者只是想给它一个更具描述性的名称,则可以使用WITH NAME语法将其导入。
| 设置 | 值 | 值 | 值 | 值 | 值 |
|---|---|---|---|---|---|
| 图书馆 | 远程 | http://127.0.0.1:8270 | 与姓名 | 例1 | |
| 图书馆 | 远程 | http://example.com:8080/ | 与姓名 | 例题 | |
| 图书馆 | 远程 | http://10.0.0.2/example | 1分钟 | 与姓名 | 示例3 |
上面第一个示例使用的URL也是远程库在未给出地址的情况下使用的默认地址。同样,端口 8270是远程服务器默认使用的端口。(82和70分别是字母R和ASCII码F)。
注意
连接本地机器时,建议使用地址127.0.0.1代替localhost。这避免了至少在Windows上的地址解析速度非常慢。在Robot Framework 2.8.4之前,远程库本身localhost默认使用的速度可能很慢。
注意
请注意,如果URI在服务器地址之后不包含路径 ,则远程库使用的xmlrpclib模块将/RPC2默认使用 路径。实际上使用 http://127.0.0.1:8270与使用相同 http://127.0.0.1:8270/RPC2。根据远程服务器的不同,这可能是也可能不是问题。即使路径是正确的,如果地址有路径,也不会追加额外的路径/。例如,既http://127.0.0.1:8270/不会也 http://127.0.0.1:8270/my/path不会被修改。
上面的最后一个例子展示了如何给远程库提供一个自定义超时作为可选的第二个参数。最初连接到服务器时以及连接意外关闭时使用超时。超时可以在机器人的框架来给出的时间格式像60s或2 minutes 10 seconds。
默认超时时间通常是几分钟,但取决于操作系统及其配置。请注意,设置比关键字执行时间短的超时将会中断关键字。
注意
支持超时是Robot Framework 2.8.6中的一项新功能。超时不适用于Python / Jython 2.5或IronPython。
启动和停止远程服务器
在导入远程库之前,必须启动提供实际关键字的远程服务器。如果在启动测试执行之前启动服务器,则可以使用上例中的常规 库设置。或者,其他关键字(例如OperatingSystem或SSH库)可以启动服务器,但是您可能需要使用Import Library关键字, 因为在测试执行开始时库不可用。
如何远程服务器可以停止取决于如何实现。通常服务器支持以下方法:
- 无论使用哪个库,远程服务器都应该提供Stop Remote Server关键字,这个关键字可以被执行的测试轻松使用。
- 远程服务器应该
stop_remote_server在其XML-RPC接口中有方法。 - 击中
Ctrl-C在服务器运行应停止服务器控制台上。 - 服务器进程可以使用操作系统提供的工具来终止(例如kill)。
注意
可以配置服务器,以便用户不能使用Stop Remote Server关键字或stop_remote_server 方法停止它 。
4.2.3支持的参数和返回值类型
由于XML-RPC协议不支持所有可能的对象类型,因此在远程库和远程服务器之间传输的值必须转换为兼容类型。这适用于远程库传递给远程服务器和返回值服务器返回到远程库的关键字参数。
远程库和Python远程服务器都按照以下规则处理Python值。其他远程服务器的行为应该类似。
- 字符串,数字和布尔值传递没有修改。
- Python
None被转换为空字符串。 - 所有列表,元组和其他可迭代对象(字符串和字典除外)都以列表形式传递,以便递归地转换其内容。
- 字典和其他映射作为字符传递,以便将它们的键转换为字符串并将值转换为支持的类型。
- 包含无法用XML表示的ASCII范围字节的字符串(例如空字节)作为内部使用XML-RPC base64数据类型的二进制对象发送。接收到的二进制对象会自动转换为字节字符串。
- 其他类型转换为字符串。
注意
在Robot Framework 2.8.3之前,根据上述规则只处理列表,元组和字典。通用的迭代和映射不被支持。
二进制支持在Robot Framework 2.8.4中是新的。
4.2.4远程协议
本节介绍在远程库和远程服务器之间使用的协议。这些信息主要针对想要创建新的远程服务器的人员。提供的Python和Ruby服务器也可以用作示例。
远程协议是在XML-RPC之上实现的,XML-RPC是一个使用XML over HTTP的简单远程过程调用协议。大多数主流语言(Python,Java,C,Ruby,Perl,Javascript,PHP等)都支持XML-RPC,无论是内置的还是扩展的。
必需的方法
远程服务器是一个XML-RPC服务器,其动态库API必须在其公共接口中具有相同的方法。只有 get_keyword_names和run_keyword实际需要,但get_keyword_arguments并 get_keyword_documentation还建议。请注意,在方法名称中使用camelCase格式目前是不可能的。如何实现实际的关键字与远程库无关。远程服务器既可以作为真正的测试库的包装,就像提供的Python和Ruby服务器一样,也可以自己实现关键字。
远程服务器还应该stop_remote_server 在其公共接口中使用方法来缓解这些问题。他们还应该自动将此方法公开为Stop Remote Server 关键字,以允许在测试数据中使用它,而不管测试库如何。允许用户停止服务器并不总是可取的,服务器可能支持以某种方式禁用该功能。该方法,也暴露的关键字,应该返回True 或False取决于停止允许与否。这使外部工具知道停止服务器是否成功。
提供的Python远程服务器可以用作参考实现。
获取远程关键字名称和其他信息
远程库获取远程服务器使用get_keyword_names方法提供的关键字列表。此方法必须将关键字名称作为字符串列表返回。
远程服务器可以也应该实现 get_keyword_arguments和get_keyword_documentation 提供关于关键字的更多信息的方法。这两个关键字都将关键字的名称作为参数。参数必须以与动态库相同的格式返回为字符串列表,并且文档必须以字符串形式返回。
从Robot Framework 2.6.2开始,远程服务器还可以提供 通用库文档,以在使用libdoc工具生成文档时使用。
执行远程关键字
当远程库希望服务器执行某个关键字时,它会调用远程服务器的run_keyword方法,并将关键字名称,参数列表以及可能的免费关键字参数字典传递给它 。基本类型可以直接用作参数,但是更复杂的类型可以转换为支持的类型。
服务器必须在包含下表中解释的项目的结果字典(或映射,取决于术语)中返回执行结果。请注意,只有status条目是强制性的,其他条目如果不适用,则可以省略。
| 名称 | 说明 |
|---|---|
| 状态 | 强制执行状态。通过或失败。 |
| 产量 | 可能的输出写入日志文件。必须以单个字符串形式给出,但可以包含多个消息和格式不同的日志级别*INFO* First message\n*HTML* 2nd\n*WARN* Another message。也可以将时间戳嵌入到日志消息中*INFO:1308435758660* Message with timestamp。 |
| 返回 | 可能的返回值。必须是受支持的类型之一。 |
| 错误 | 可能的错误消息。仅在执行失败时使用。 |
| 追溯 | 当执行失败时,可能的堆栈跟踪使用DEBUG级别写入日志文件。 |
| 可持续 | 当设置为True或TruePython中考虑的任何值时 ,发生的故障被认为是可以 继续的。Robot Framework 2.8.4中的新功能 |
| 致命 | 像continuable,但表示发生的故障是致命的。在Robot Framework 2.8.4中也是新的。 |
不同的参数语法
远程库是一个动态库,通常它根据与任何其他动态库相同的规则处理不同的参数语法。这包括强制参数,默认值,可变参数,以及命名参数语法。
另外,免费的关键字参数(**kwargs)与其他动态库的工作方式大致相同。首先, get_keyword_arguments必须返回一个**kwargs与其他动态库完全相同的参数说明。主要区别在于远程服务器的run_keyword方法必须有可选的第三个参数来获取用户指定的kwargs。第三个参数必须是可选的,因为出于向后兼容的原因,run_keyword只有在测试数据中使用了kwargs时,远程库才会将kwargs传递给方法。
在实践中run_keyword应该看起来像下面的Python和Java示例,这取决于语言如何处理可选参数。
def run_keyword (name , args , kwargs = None ): #...
public Map run_keyword (String name , List args ) { // ... }public Map run_keyword (String name , List args , Map kwargs ) { // ... }
注意
远程库支持**kwargs从Robot Framework 2.8.3开始。
4.3使用监听器接口
Robot Framework有一个监听器接口,可以用来接收有关测试执行的通知。监听器是具有特定方法的类或模块,可以用Python和Java实现。侦听器接口的使用示例包括外部测试监视器,测试失败时发送邮件消息以及与其他系统通信。
- 4.3.1听取使用者的意见
- 4.3.2可用的监听器接口方法
- 监听器接口版本
- 侦听器接口方法签名
- 4.3.3听众记录
- 4.3.4听众示例
- 4.3.5测试库作为监听器
- 注册侦听器
- 调用监听器方法
4.3.1听取使用者的意见
监听器从--listener 选项的命令行中被使用,所以监听器的名字被作为参数赋予它。侦听器名称是从实现侦听器接口的类或模块的名称获得的,类似于从实现它们的类获得测试库名称。指定的侦听器必须位于同一个模块搜索路径中,在这些路径中搜索测试库的时间。其他选项与给测试库类似地给出监听器文件的绝对路径或相对路径 。通过多次使用此选项可以使多个侦听器可用。
也可以从命令行给侦听器类提供参数。在侦听器名称(或路径)之后使用冒号作为分隔符指定参数。这种方法只提供字符串类型的参数和参数,显然不能包含冒号。但是,听众应该很容易去解决这些限制。
例子:
pybot --listener MyListener tests.htmljybot --listener com.company.package.Listener tests.htmlpybot --listener path / to / MyListener.py tests.htmlpybot --listener module.Listener --listener AnotherListener tests.htmlpybot --listener ListenerWithArgs:arg1:arg2pybot --listener path / to / MyListener.java:参数tests.html
4.3.2可用的监听器接口方法
Robot Framework在测试执行开始时用给定的参数创建一个监听器类的实例。在测试执行期间,当测试套件,测试用例和关键字开始和结束时,Robot Framework调用监听器的方法。当输出文件准备就绪时,它也调用适当的方法,最后调用close方法。监听器不需要实现任何官方接口,只需要实际需要的方法即可。
监听器接口版本
Robot Framework 2.1中更改了与测试执行进度有关的方法签名。这个改变是为了使新的信息可以添加到监听器接口而不会破坏现有的监听器。旧的签名将继续工作,但在未来版本中将被弃用,所以所有新的收听者都应该使用下表中描述的签名来实现。旧监听器接口的最新详细描述可以在Robot Framework 2.0.4的用户指南中找到。
注意
侦听器必须ROBOT_LISTENER_API_VERSION 定义属性才能被识别为新的样式侦听器。ROBOT_LISTENER_API_VERSION属性的值 必须是2,可以是字符串,也可以是整数。下面的例子被实现为新的样式监听器。
侦听器接口方法签名
与测试执行进度相关的所有侦听器方法都具有相同的签名method(name, attributes),其中attributes 是包含事件详细信息的字典。下表列出了侦听器接口中的所有可用方法以及attributes字典的内容(如果适用)。字典的键是字符串。所有这些方法也有camelCase别名。因此,例如,startSuite是一个同义词start_suite。
| 方法 | 参数 | 属性/说明 |
|---|---|---|
| start_suite | 名称,属性 | 属性字典中的键:
|
| end_suite | 名称,属性 | 属性字典中的键:
|
| start_test | 名称,属性 | 属性字典中的键:
|
| end_test | 名称,属性 | 属性字典中的键:
|
| start_keyword | 名称,属性 | 属性字典中的键:
|
| end_keyword | 名称,属性 | 属性字典中的键:
|
| log_message | 信息 | 当执行关键字写入日志消息时调用。
|
| 信息 | 信息 | 当框架本身写入系统日志 消息时调用。message是一个与log_message方法具有相同键的字典。 |
| 输出文件 | 路径 | 写入输出文件时调用完成。该路径是文件的绝对路径。 |
| LOG_FILE | 路径 | 写入日志文件完成后调用。该路径是文件的绝对路径。 |
| 报告文件 | 路径 | 写入报告文件完成后调用。该路径是文件的绝对路径。 |
| DEBUG_FILE | 路径 | 写入调试文件完成后调用。该路径是文件的绝对路径。 |
| 关 | 在所有的测试套件以及测试用例中被调用,都被执行。 |
下面的正式Java接口规范中还显示了可用的方法及其参数。的内容java.util.Map attributes如上述的表中。应该记住,一个监听器不需要实现任何明确的接口或者具有所有这些方法。
公共 接口 RobotListenerInterface { public static final int ROBOT_LISTENER_API_VERSION = 2 ; 无效 startSuite (字符串 名称, Java的。UTIL 。地图 属性); 无效 endSuite (字符串 名称, Java的。UTIL 。地图 属性); 无效 startTest (字符串 名称, Java的。UTIL。地图 属性); 无效 endTest (字符串 名称, Java的。UTIL 。地图 属性); 无效 startKeyword (字符串 名称, Java的。UTIL 。地图 属性); 无效 endKeyword (字符串 名称, Java的。UTIL 。地图 属性); 无效 的LogMessage (java的。UTIL 。地图 消息); 空隙 消息(的java 。util的。地图 信息); void outputFile (String path ); void logFile (String path ); void reportFile (String path ); void debugFile (String path ); void close (); }
4.3.3听众记录
Robot Framework 2.6引入了新的程序化日志API,也是侦听器可以利用的。但是,有一些限制,下面的表格解释了不同的监听器方法如何记录消息。
| 方法 | 说明 |
|---|---|
| start_keyword,end_keyword,log_message | 消息被记录到 执行关键字下的普通日志文件中。 |
| start_suite,end_suite,start_test,end_test | 消息被记录到系统日志。正常日志文件的执行错误部分也显示警告。 |
| 信息 | 消息通常记录到系统日志中。如果在执行关键字时使用此方法,则会将消息记录到正常的日志文件中。 |
| 其他方法 | 消息只记录到系统日志。 |
注意
为避免递归,侦听器记录的消息不会发送到侦听器方法log_message和message。
警告
听众在Robot Framework 2.6.2之前有严重的问题。因此不建议在早期版本中使用此功能。
4.3.4听众示例
第一个简单的例子是在Python模块中实现的。主要说明使用监听器接口不是很复杂。
ROBOT_LISTENER_API_VERSION = 2def start_test (name , attrs ): print '执行测试%s ' % nameDEF start_keyword (名称, ATTRS ): 打印 '执行关键字%s的带有参数的%S ' % (名, ATTRS [ 'ARGS' ])def log_file (path ): 打印 '测试日志可用在%s ' % 路径def close (): print'All tests executed'
第二个仍然使用Python的例子稍微复杂一些。它将所有的信息写入一个临时目录中的文本文件,而不需要太多格式化。文件名可能来自命令行,但也有一个默认值。请注意,在实际使用中, 通过命令行选项--debugfile可用的调试文件功能可能比此示例更有用。
导入 os.path 导入 tempfile类 PythonListener : ROBOT_LISTENER_API_VERSION = 2 def __init__ (self , filename = 'listen.txt' ): outpath = os 。路径。加入(临时文件。gettempdir (), 文件名) 自我。outfile = open (outpath , 'w' ) def start_suite (self , name , attrs ): self 。outfile 。写(“ %s ' %s ' \ n ” % (name , attrs [ 'doc' ])) def start_test (self , name , attrs ): tags = '' 。加入(attrs [ 'tags' ]) 自我。outfile 。write (“ - %s ' %s '[ %s ] ::” % (name , attrs [ 'doc' ], tags )) def end_test (self , name , attrs ): if attrs [ 'status' ] == 'PASS' : self 。outfile 。写('PASS \ n ' ) 否则: 自我。outfile 。写('FAIL:%s \ n ' % attrs [ 'message' ]) def end_suite (self , name , attrs ): self 。outfile 。写(' %s \ n %s \ n ' % (attrs [ 'status' ], attrs [ 'message' ])) def close (self ): self 。outfile 。close ()
第三个例子实现了与前一个例子相同的功能,但使用Java而不是Python。
import java.io. * ; import java.util.Map ; import java.util.List ;公共 类 JavaListener { public static final int ROBOT_LISTENER_API_VERSION = 2 ; public static final String DEFAULT_FILENAME = “listen_java.txt” ; 私人 BufferedWriter outfile = null ; public JavaListener () 抛出 IOException { this (DEFAULT_FILENAME ); } 公共 JavaListener (字符串 文件名) 抛出 IOException { 字符串 tmpdir = 系统。getProperty (“java.io.tmpdir” ); 字符串 sep = 系统。getProperty (“file.separator” ); 字符串 outpath = tmpdir + sep + 文件名; outfile = new BufferedWriter (new FileWriter (outpath )); } public void startSuite (String name , Map attrs ) throws IOException { outfile 。写(名称 + “ '” + ATTRS 。获得(“DOC” ) + “' \ n” ); } public void startTest (String name , Map attrs ) throws IOException { outfile 。写(“ - ” + 名字 + “ '” + ATTRS 。获得(“DOC” ) + “'[” ); 列表 标签 = (列表)attrs 。get (“tags” ); for (int i = 0 ; i < 标签。size (); 我++) { outfile 。写(标签。获得(我) + “” ); } outfile 。写(“] ::” ); } public void endTest (String name , Map attrs ) throws IOException { String status = attrs 。获得(“状态” )。toString (); 如果 (状态。等号(“PASS” )) { OUTFILE 。写(“PASS \ n” ); } 其他 { OUTFILE 。写(“FAIL:” + ATTRS 。得到(“message” ) + “\ n” ); } } public void endSuite (String name , Map attrs ) throws IOException { outfile 。写(ATTRS 。获得(“状态” ) + “\ n”个 + ATTRS 。获得(“消息” ) + “\ n”个); } public void close () throws IOException { outfile 。close (); }}
4.3.5测试库作为监听器
有时,测试库也可以获取有关测试执行的通知。这允许他们在测试套件或整个测试执行结束时自动执行某些清理活动。
注意
这个功能是Robot Framework 2.8.5中的新功能。
注册侦听器
一个测试库可以通过使用ROBOT_LIBRARY_LISTENER 属性注册一个监听器。此属性的值应该是要使用的侦听器的实例。它可能是一个完全独立的听众,或者图书馆本身可以作为一个听众。为避免在后一种情况下将侦听器方法暴露为关键字,可以用下划线作为前缀。例如,而不是使用end_suite或endSuite,有可能使用_end_suite或_endSuite。
以下示例说明如何使用外部侦听器以及库作为侦听器本身:
导入 my.project.Listener ;public class JavaLibraryWithExternalListener { public static final Listener ROBOT_LIBRARY_LISTENER = new Listener (); public static final String ROBOT_LIBRARY_SCOPE = “GLOBAL” ; //实际的库代码在这里... }
类 PythonLibraryAsListener本身(object ): ROBOT_LIBRARY_SCOPE = 'TEST SUITE'ROBOT_LISTENER_API_VERSION = 2 def __init__ (self ): self 。ROBOT_LIBRARY_LISTENER = 自我 高清 _end_suite (自我, 名称, ATTRS ): 打印 '套件%S (%S )结束。' % (name , attrs [ 'id' ]) #实际库代码在这里...
正如上面已经演示的秒示例,库监听器可以 像使用任何其他监听器一样使用属性来指定监听器接口版本ROBOT_LISTENER_API_VERSION。
调用监听器方法
库的侦听器将获得有关导入库的套件中的所有事件的通知。在实践中,这意味着start_suite, end_suite,start_test,end_test,start_keyword, end_keyword,log_message,和message方法被调用的套房内。
如果库每次创建一个新的侦听器实例,那么实际使用的侦听器实例将根据测试库范围而改变。除了之前列出的侦听器方法外,close 当库超出范围时,方法被调用。
有关所有这些方法的更多信息,请参阅上面的Listener接口方法签名部分。
4.4扩展机器人框架Jar
使用包含在标准JDK安装中的jar命令,将额外的测试库或支持代码添加到Robot Framework jar非常简单。Python代码必须放在jar目录下的lib目录下,Java代码可以直接放到jar的根目录,根据包结构。
例如,要将Python包添加mytestlib到jar中,首先将mytestlib目录复制到 名为Lib的目录下,然后在包含Lib的目录中运行以下命令:
jar uf /path/to/robotframework-2.7.1.jar Lib
要将编译的java类添加到jar中,您必须具有与Java包结构相对应的目录结构,并将其递归添加到zip中。
例如,要添加类MyLib.class,在包中org.test,该文件必须位于org / test / MyLib.class中,您可以执行:
jar uf /path/to/robotframework-2.7.1.jar org
5个支持工具
- 5.1库文档工具(libdoc)
- 5.2测试数据文档工具(testdoc)
- 5.3测试数据清理工具(整洁)
- 5.4外部工具
5.1库文档工具(libdoc)
- 5.1.1一般用法
- 5.1.2编写文件
- 5.1.3文档语法
- 5.1.4内部链接
- 5.1.5代表论点
- 5.1.6 Libdoc示例
Libdoc是一种为HTML和XML格式的测试库和资源文件生成关键字文档的工具。前者格式适用于人类,后者适用于RIDE和其他工具。Libdoc也没有特别的命令来显示控制台上的库或资源信息。
文档可以创建为:
- 用Python或Java使用普通静态库API 实现的测试库,
- 使用动态API测试库,包括远程库和
- 资源文件。
此外,可以使用Libdoc早期创建的XML规范作为输入。
Libdoc内置于Robot Framework中,并自2.7版本开始自动包含在安装中。使用较早的版本,您需要单独下载libdoc.py脚本。这些版本之间的命令行使用稍有变化,但文档语法仍然相同。
5.1.1一般用法
概要
python -m robot.libdoc [options] library_or_resource output_filepython -m robot.libdoc [options] library_or_resource list | show | version [names]
选项
-f, --format 指定是否生成HTML或XML输出。如果不使用此选项,则格式将从输出文件的扩展名获得。 -F, --docformat 指定源文档格式。可能的值是Robot Framework的文档格式,HTML,纯文本和reStructuredText。默认值可以在测试库源代码中指定,初始默认值是 robot。Robot Framework 2.7.5中的新功能-N, --name 设置记录的库或资源的名称。 -V, --version 设置记录的库或资源的版本。测试库的默认值是 从源代码中获得的。 -P, --pythonpath 与运行测试时类似的搜索库和资源的其他位置。 -E, --escape 转义控制台中有问题的字符。 what是要转义的字符的名称,是用来转义with的字符串。可用的转义符在--help 输出中列出。-h, --help 打印此帮助。
另类执行
虽然在上面的简介中,Libdoc仅用于Python,但它也适用于Jython和IronPython。在记录Java库时,实际上需要Jython。
在大纲中,Libdoc作为已安装的模块(python -m robot.libdoc)执行。除此之外,它也可以作为脚本运行:
python path / robot / libdoc.py [options]参数
如果您已经完成手动安装,那么作为脚本执行可能非常有用, 否则只需将机器人目录与源代码放在系统中的某处即可。
指定库或资源文件
Python库和具有名称或路径的动态库
当记录用Python实现的库或使用 动态库API时,可以通过仅使用库名称或库源代码的路径来指定库。在前一种情况下,使用库搜索路径搜索库, 并且其名称必须与Robot Framework测试数据中的格式相同。
如果这些库在导入时需要参数,则参数必须与库名或使用两个冒号的路径连接 MyLibrary::arg1::arg2。如果参数改变了库提供的关键字,或者改变了它的文档,那么使用 --name选项也可以相应地改变库的名字。
带有路径的Java库
使用静态库API实现的Java测试库可以通过给包含库实现的源代码文件的路径指定。此外,在执行Libdoc时,必须从CLASSPATH中找到作为Java JDK发行版的一部分的tools.jar。请注意,为Java库生成文档仅适用于Jython。
具有路径的资源文件
资源文件必须始终使用路径指定。如果路径不存在,那么资源文件也会像在执行测试用例时那样从PYTHONPATH中的所有目录中搜索 。
生成文档
在生成HTML或XML格式的文档时,必须将输出文件指定为库/资源名称或路径之后的第二个参数。输出格式是从扩展名自动获得,但也可以使用--format选项设置。
例子:
python -m robot.libdoc OperatingSystem OperatingSystem.htmlpython -m robot.libdoc - 名称MyLibrary Remote :: http://10.0.0.42:8270 MyLibrary.xmlpython -m robot.libdoc test / resource.html doc / resource_doc.htmljython -m robot.libdoc --version 1.0 MyJavaLibrary.java MyJavaLibrary.htmljython -m robot.libdoc my.organization.DynamicJavaLibrary my.organization.DynamicJavaLibrary.xml
在控制台上查看信息
Libdoc有三个特殊的命令在控制台上显示信息。使用这些命令而不是输出文件的名称,并且还可以使用其他参数。
-
list - 列出库/资源包含的关键字的名称。可以通过传递可选模式作为参数来限制显示特定关键字。如果其名称包含给定模式,则列出关键字。
-
show -
显示库/资源文档。可以通过传递名称作为参数来限制显示某些关键字。如果其名称与任何给定名称匹配,则显示关键字。特别的论据
intro将只显示图书馆介绍和进口部分。 -
version - 显示库版本
给予的可选模式list,show对大小写和空间不敏感。两者都接受*和?作为通配符。
例子:
python -m robot.libdoc对话框列表python -m robot.libdoc Selenium2Library列表浏览器python -m robot.libdoc Remote :: 10.0.0.42:8270显示python -m robot.libdoc对话框显示PauseExecution执行*python -m robot.libdoc Selenium2Library显示介绍python -m robot.libdoc Selenium2Library版本
5.1.2编写文件
本节讨论为使用静态库API以及动态库 和资源文件的基于Python和Java的测试库编写文档。创建测试库和资源文件在用户指南的其他地方有更详细的描述。
Python库
使用静态库API的 Python库的文档 简单地写为库类或模块的文档字符串以及实现关键字的方法。方法文档的第一行被认为是关键字的简短文档(例如,在生成的HTML文档中用作链接中的工具提示),因此它应该尽可能描述,但不能太长。
下面这个简单的例子说明了如何编写文档,本章最后还有一个比较长的例子,它也包含了生成文档的一个例子。
类 ExampleLib : “”“库用于演示目的。 这个库只用在一个例子中,它没有做任何有用的事情。 “”” def my_keyword (self ): “”“什么都没有。”“” 传递 def your_keyword (self , arg ): “”“带一个参数,*不做任何事情*。 例如: | 您的关键字| xxx | | 您的关键字| yyy | “” 通过
小费
如果要在Python库文档中使用非ASCII字符,则必须使用UTF-8作为源代码编码,或者将Unicode文档创建为docstrings。
有关Python文档字符串的更多信息,请参阅PEP-257。
Java库
使用静态库API的 Java库的文档被编写为库类和方法的普通Javadoc注释。在这种情况下,Libdoc实际上在内部使用Javadoc工具,因此 包含它的tools.jar必须位于CLASSPATH中。这个jar文件是普通Java SDK发行版的一部分,应该 在Java SDK安装的bin目录中找到。
下面这个简单的例子与之前的Python例子具有完全相同的文档(和功能)。
/ ** *用于演示目的的库。* *这个库只用于一个例子,它没有做任何有用的事情。* / public class ExampleLib { / ** *什么都不做。 * / public void myKeyword ()