Hadoop分布式集群搭建流程记录
软件环境
- Hadoop版本:hadoop-2.7.2.tar.gz
- JAVA版本 :jdk-8u77-linux-x64.tar.gz
- Linux版本 :Ubuntu 15.04(64位)
主机IP
- Master.Hadoop XX.XX.XXX.173 Master节点
- Slave1.Hadoop XX.XX.XXX.171 工作节点1
- Slave2.Hadoop XX.XX.XXX.201 工作节点2
- Slave3.Hadoop XX.XX.XXX.156 工作节点3
Step1:Ubuntu基本配置
- 添加root登录 (可选)
```code
为root账户设置密码:sudo passwd root
测试root账户: su -
输入root密码,进入root终端
图形化界面下执行: gedit /usr/share/lightdm/lightdm.conf.d
在打开的文件末尾添加如下代码,保存并退出
user-session=ubuntu
greeter-show-manual-login=true
all-guest=false
重启计算机即可使用root登录图形界面
##注意
* 使用root登录后虽然方便,但要谨慎操作,防止误操作删除重要文件
***
* 更新Ubuntu源
* `gedit /etc/apt/sources.list` 打开源列表
* 清空原有的数据,并添加如下源
```code
#搜狐源:
deb http://mirrors.sohu.com/ubuntu/ vivid main restricted universe multiverse
deb http://mirrors.sohu.com/ubuntu/ vivid-security main restricted universe multiverse
deb http://mirrors.sohu.com/ubuntu/ vivid-updates main restricted universe multiverse
deb http://mirrors.sohu.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb http://mirrors.sohu.com/ubuntu/ vivid-backports main restricted universe multiverse
deb-src http://mirrors.sohu.com/ubuntu/ vivid main restricted universe multiverse
deb-src http://mirrors.sohu.com/ubuntu/ vivid-security main restricted universe multiverse
deb-src http://mirrors.sohu.com/ubuntu/ vivid-updates main restricted universe multiverse
deb-src http://mirrors.sohu.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb-src http://mirrors.sohu.com/ubuntu/ vivid-backports main restricted universe multiverse
#阿里源:
deb http://mirrors.aliyun.com/ubuntu/ vivid main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-backports main restricted universe multiverse
#网易源:
deb http://mirrors.aliyun.com/ubuntu/ vivid main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ vivid-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ vivid-backports main restricted universe multiverse
添加完毕保存并退出,执行sudo apt-get update以及sudo apt-get dist-upgrade
- 修改当前机器名
- 执行
gedit /etc/hostname将主机名改为对应的名称(Slave1.Hadoop等) - 配置host文件
- 为了让几台主机之间互相“认识”,我们必须修改主机的host,这是主机用来盘配置DNS服务的信息,记载Lan内
各主机对应的Hostname------IP关系 - 执行
gedit /etc/hosts以Master为例子,为每个节点加入类似如下数据: - XX.XX.XXX.171 Slave1.Hadoop
Step2:配置JAVA环境
- 为所有的节点部署JAVA环境
- 用root身份登录"Master.Hadoop"后在"/home"下创建"jdk"文件夹,再将"jdk-8u77-linux-x64.tar.gz"复制到"/home/jdk"文件夹中,然后解压即可。查看"/home/jdk"下面会发现多了一个名为"jdk-8u77-linux-x64"文件夹
,将其重命名为java8 - 执行命令
gedit /etc/profile打开profile文件,配置JAVA路径,在文件末尾添加如下命令:
export JAVA_HOME=/home/jdk/java8
export JRE_HOME=/home/jdk/java8/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
- 重启Ubuntu
Step3:配置SSH实现节点之间免密码安全连接
- 这一步的意义如下:
- Master和Slave之间连接不能依靠手动输入密码,要在确保安全的情况下进行免密钥相互连接,所以我们要配置SSH免密码登录。
- 原理:以Master为例1,在Master上生成一个公钥和一个私钥,默认存储在
/home/username/.ssh目录下。
- 具体操作流程:
- 安装SSH: 执行
sudo apt-get install openssh-server - 启动服务时候遇到了
错误提示:ssh: Could not resolve hostname : Name or service not known,解决办法是在/etc/hosts里添加进该主机及对应的IP. - 执行:
ssh-keygen命令,生成无密码密钥对。 - 执行
ls -a | grep .ssh检查是否有两个密钥。 - 执行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys将公钥追加授权到key里面。 - 检查authorized_keys的权限,不对则使用
chmod 600 authorized_keys命令修改权限。 - 检查sshd_config文件(
gedit /etc/ssh/sshd_config),看下列三行是否注释掉,没注释掉则注释:
- 安装SSH: 执行
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
* 重启SSH服务,执行`service ssh restart`
* 将公钥拷贝到要实现免密码登录的远程主机上:执行`ssh-copyid [email protected]`拷贝到Slave1节点(本机是Masgter)
* 验证免密码登录:
* 本机执行`ssh [email protected]`即可免密码登录Slave1
* 其他节点之间同理操作,下面附上Slave2.Hadoop远程免密钥登录Master节点截图:

***
#Step4:Hadoop集群部署
* 实验室配置路径交代:
* 以Master配置为例,解压Hadoop,放在`/usr/hadoop`位置。
* 在"**/usr/hadoop**"下面创建**tmp**文件夹,并把Hadoop的安装路径添加到"**/etc/profile**"中
* 执行`gedit /etc/profile`,在最下面加上如下命令:
```code
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export $Path=$PATH:$HADOOP_HOME/bin
- 下面进行Hadoop的配置,需要配置的文件在
/usr/hadoop/etc/hadoop下- 分别是
slaves、core-site.xml、hadfs-site.xml、mapred-stie.xml、yarn-stie - slaves: 将作为 DataNode 的主机名写入该文件,每行一个(Master可以作为工作节点)
 Master节点的salves
Master节点的salves - core-site.xml 改为下面的配置:
- 分别是
fs.defaultFS
hdfs://Master.Hadoop:9000
hadoop.tmp.dir
/usr/hadoop/tmp
Abase for other temporary directories.
- 文件 hdfs-site.xml,默认的工作节点数(一个子节点则设为1):
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
1
dfs.namenode.name.dir
/usr/hadoop/tmp/dfs/name
dfs.datanode.data.dir
/usr/hadoop/tmp/dfs/data
- mapred-site.xml (先重命名,去掉.template),配置修改如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
- 文件 yarn-site.xml:
yarn.resourcemanager.hostname
Master.Hadoop
yarn.nodemanager.aux-services
mapreduce_shuffle
- 配置完成后,将Master上的
/usr/hadoop文件上传到各个节点上,执行命令;
cd /usr
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1.Hadoop:/usr/hadoop
在Slave1.Hadoop上执行:
sudo rm -r /usr/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr
sudo chown -R hadoop /usr/hadoop
另外你也可以使用U盘进行拷贝(亲测)
- 首次启动需要再Master上执行
hdfs namenode -format对NadmeNode格式化 - 启动Hadoop:
start-all.sh #这个可执行文件在`/usr/hadoop/sbin`下
通过命令 jps可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 如下进程:

测试启动结果
Slave节点可以看到如下进程:

Slave节点查看验证
注意:缺少进程代表出现问题,另外还需要在 Master 节点上通过命令
hdfs dfsadmin -report查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
- 通过Web页面查看hadoop集群:

通过Web查看集群
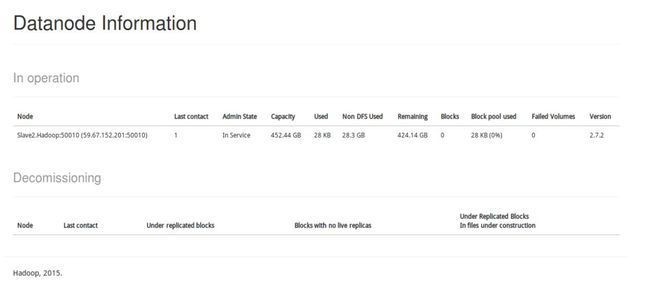
节点Slave2在线

通过Web查看集群