【五】Spark SQL中HiveContext的使用(操作hive中的表)(提交到服务器上执行)(Hadoop HA)
HiveContext在基本的SQLContext上有了一些新的特性,可以用Hive QL写查询,可以读取Hive表中的数据,支持Hive的UDF。
要把hive/conf/hive-site.xml文件拷贝到spark/conf下。
cd /app/hive/conf
scp hive-site.xml root@node1:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hive-site.xml root@node2:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hive-site.xml root@node3:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hive-site.xml root@node4:/app/spark/spark-2.2.0-bin-2.9.0/conf/
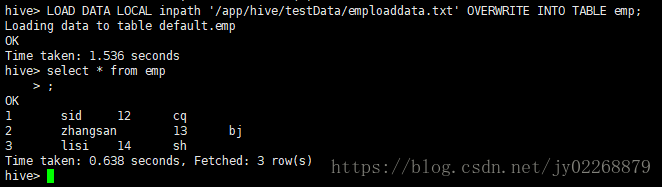
准备hive的emp表数据
cd /app/hive/testData
vi emploaddata.txt
1 sid 12 cq
2 zhangsan 13 bj
3 lisi 14 sh启动zookeeper
启动hadoop
启动hive
hive创建表emp
cd /app/hive/bin
hive
CREATE TABLE IF NOT EXISTS emp (
id int,
name String,
salary String,
destination String)
COMMENT 'Employee details'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;给emp表添加数据
LOAD DATA LOCAL inpath '/app/hive/testData/emploaddata.txt' OVERWRITE INTO TABLE emp;
项目目录
pom.xml
4.0.0
com.sid.com
sparksqltrain
1.0-SNAPSHOT
2008
2.11.8
2.2.0
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-hive_2.11
${spark.version}
src/main/scala
src/test/scala
org.scala-tools
maven-scala-plugin
compile
testCompile
${scala.version}
-target:jvm-1.5
org.apache.maven.plugins
maven-eclipse-plugin
true
ch.epfl.lamp.sdt.core.scalabuilder
ch.epfl.lamp.sdt.core.scalanature
org.eclipse.jdt.launching.JRE_CONTAINER
ch.epfl.lamp.sdt.launching.SCALA_CONTAINER
org.scala-tools
maven-scala-plugin
${scala.version}
HiveContext.scalapackage com.sid.com
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
object HiveContext {
def main(args: Array[String]): Unit = {
//创建相应的Context
val sparkConf = new SparkConf()
sparkConf//.setAppName("SQLContext").setMaster("local[3]")
val sc = new SparkContext(sparkConf)
//这个过时了,在spark1.X中这样用,2.X已经不用这个了
val hiveContext = new HiveContext(sc);
hiveContext.table("emp").show()
sc.stop()
}
}
打包

传到服务器上运行
cd /app/spark/spark-2.2.0-bin-2.9.0/bin
./spark-submit --class com.sid.com.HiveContext --master local[2] --name HiveContext --jars /app/mysql-connector-java-5.1.46.jar /app/spark/test_data/sparksqltrain-1.0-SNAPSHOT.jar
报错
Exception in thread "main" java.lang.IllegalArgumentException: java.net.UnknownHostException: hadoopcluster
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:374)
at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:310)
at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:176)
at org.apache.hadoop.hdfs.DFSClient.(DFSClient.java:668)
at org.apache.hadoop.hdfs.DFSClient.(DFSClient.java:604)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:148)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2598)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:256)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:228)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:313)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:194)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:314)
at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:2853)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153)
at org.apache.spark.sql.Dataset$$anonfun$55.apply(Dataset.scala:2837)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:2836)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2153)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2366)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:245)
at org.apache.spark.sql.Dataset.show(Dataset.scala:644)
at org.apache.spark.sql.Dataset.show(Dataset.scala:603)
at org.apache.spark.sql.Dataset.show(Dataset.scala:612)
at com.sid.com.HiveContext$.main(HiveContext.scala:15)
at com.sid.com.HiveContext.main(HiveContext.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:755)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.net.UnknownHostException: hadoopcluster
... 65 more
因为我的hadoop的HDFS配置了HA高可用,hadoopcluster是hadoop配置文件hdfs-site.xml中dfs.nameservices的值。
需要把hadoop的配置文件hdfs-site.xml core-site.xml也拷贝到每个spark的conf下
cd /app/hadoop/hadoop-2.9.0/etc/hadoop
scp hdfs-site.xml root@node1:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hdfs-site.xml root@node2:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hdfs-site.xml root@node3:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp hdfs-site.xml root@node4:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp core-site.xml root@node1:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp core-site.xml root@node2:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp core-site.xml root@node3:/app/spark/spark-2.2.0-bin-2.9.0/conf/
scp core-site.xml root@node4:/app/spark/spark-2.2.0-bin-2.9.0/conf/
cd /app/spark/spark-2.2.0-bin-2.9.0/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
追加一下内容
spark.files file:///app/spark/spark-2.2.0-bin-2.9.0/conf/hdfs-site.xml,file:///app/spark/spark-2.2.0-bin-2.9.0/conf/core-site.xml
重新执行spark作业
