【ODPS】MapReduce基础
MapReduce处理数据过程主要分成2个阶段:Map阶段和Reduce阶段。首先执行Map阶段,再执行Reduce阶段。Map和Reduce的处理逻辑由用户自定义实现, 但要符合MapReduce框架的约定。
- 在正式执行Map前,需要将输入数据进行”分片”。所谓分片,就是将输入数据切分为大小相等的数据块,每一块作为单个Map Worker的输入被处理, 以便于多个Map Worker同时工作。
- 分片完毕后,多个Map Worker就可以同时工作了。每个Map Worker在读入各自的数据后,进行计算处理,最终输出给Reduce。Map Worker在输出数据时, 需要为每一条输出数据指定一个Key。这个Key值决定了这条数据将会被发送给哪一个Reduce Worker。Key值和Reduce Worker是多对一的关系, 具有相同Key的数据会被发送给同一个Reduce Worker,单个Reduce Worker有可能会接收到多个Key值的数据。
- 在进入Reduce阶段之前,MapReduce框架会对数据按照Key值排序,使得具有相同Key的数据彼此相邻。如果用户指定了”合并操作”(Combiner), 框架会调用Combiner,将具有相同Key的数据进行聚合。Combiner的逻辑可以由用户自定义实现。与经典的MapReduce框架协议不同,在ODPS中, Combiner的输入、输出的参数必须与Reduce保持一致。这部分的处理通常也叫做”洗牌”(Shuffle)。
- 接下来进入Reduce阶段。相同的Key的数据会到达同一个Reduce Worker。同一个Reduce Worker会接收来自多个Map Worker的数据。 每个Reduce Worker会对Key相同的多个数据进行Reduce操作。最后,一个Key的多条数据经过Reduce的作用后,将变成了一个值。
ODPS MapReduce的输入和输出是ODPS表或者分区(不允许用户自定输入输出格式,不提供类似文件系统的接口)
下面以WordCount为例,详解ODPS的MapReduce的执行过程。输入表只有一列,每条记录是一个单词,要求统计单词出现次数,写入另外一张表中(两列,一列单词,一列次数)
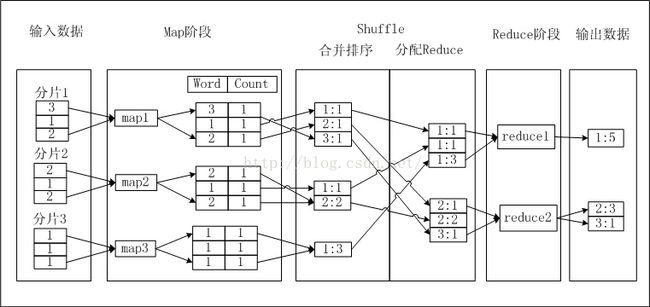
- Map处理输入,每获取一个单词,将单词的Count设置为1,并将此
- 在Shuffle阶段前期,首先对每个Map Worker的输出,按照Key值,即Word值排序。排序后进行Combine操作,即将Key值(Word值)相同的Count累加, 构成一个新的
- 在Shuffle阶段后期,数据被发送到Reduce端。Reduce Worker收到数据后依赖Key值再次对数据排序;
- 每个Reduce Worker对数据进行处理时,采用与Combiner相同的逻辑,将Key值(Word值)相同的Count累加,得到输出结果;
代码实现:
1、Mapper实现
package mr.test;
import java.io.IOException;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.mapred.MapperBase;
public class WCMapper extends MapperBase {
private Record word;
private Record one;
@Override
public void setup(TaskContext context) throws IOException {
word = context.createMapOutputKeyRecord();
one = context.createMapOutputValueRecord();
one.set(new Object[] { 1L });
}
@Override
public void map(long recordNum, Record record, TaskContext context)
throws IOException {
System.out.println("recordNum:"+recordNum);
for (int i = 0; i < record.getColumnCount(); i++) {
String[] words = record.get(i).toString().split("\\s+");
for (String w : words) {
word.set(new Object[] { w });
context.write(word, one);
}
}
}
@Override
public void cleanup(TaskContext context) throws IOException {
}
}
1)先通过setup()初始化Record实例,setup()只执行一次。
2)map()函数多每条Record都会调用一次,在这个函数内,循环遍历Record字段,对每个字段通过正则切分,然后输出
3)setup()和map()都会传入一个TaskContext实例,保存MR任务运行时的上下文信息。
4)cleanup()执行收尾工作
2、Reducer实现
package mr.test;
import java.io.IOException;
import java.util.Iterator;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.mapred.ReducerBase;
public class WCReducer extends ReducerBase {
private Record result;
@Override
public void setup(TaskContext context) throws IOException {
result = context.createOutputRecord();
}
@Override
public void reduce(Record key, Iterator values, TaskContext context)
throws IOException {
long count = 0;
while (values.hasNext()) {
Record val = values.next();
count += (Long) val.get(0);
}
result.set(0, key.get(0));
result.set(1, count);
context.write(result);
}
@Override
public void cleanup(TaskContext context) throws IOException {
}
}
1)同样reduce也提供setup和cleanup方法。
2)reduce函数是对每个key调用一次,在函数内,它遍历同一个key的不同值,对其进行累加操作,然后生成结果Record输出。
2)注意:map和reduce在输出上的区别为:Reduce调用的context.write(result)输出结果Record;Map是调用context.write(word,one)输出键值对形式。
3、Driver实现
package mr.test;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.data.TableInfo;
import com.aliyun.odps.mapred.JobClient;
import com.aliyun.odps.mapred.RunningJob;
import com.aliyun.odps.mapred.conf.JobConf;
import com.aliyun.odps.mapred.utils.InputUtils;
import com.aliyun.odps.mapred.utils.OutputUtils;
import com.aliyun.odps.mapred.utils.SchemaUtils;
public class WCDriver {
public static void main(String[] args) throws OdpsException {
if(args.length !=2){
System.out.println("参数错误");
System.exit(2);
}
JobConf job = new JobConf();
job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));
InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(),
job);
OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(),
job);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
RunningJob rj = JobClient.runJob(job);
rj.waitForCompletion();
}
}
1)先初始化一个JobConf实例
2)指定运行的Maper、Reduce类:
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
3)设置map的输出key和value的类型:
job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));