基于centos的Hadoop2.x环境搭建
hadoop2.0环境搭建
1.安装vmware
这里就不介绍如何安装了,不清楚可在网上找一些教程
2.vmware安装centos6
2.1centos系统安装
打开vmware 点击文件 ,点击文件 ->新建虚拟机 新建虚拟机
选择“典型”点击“下一步”
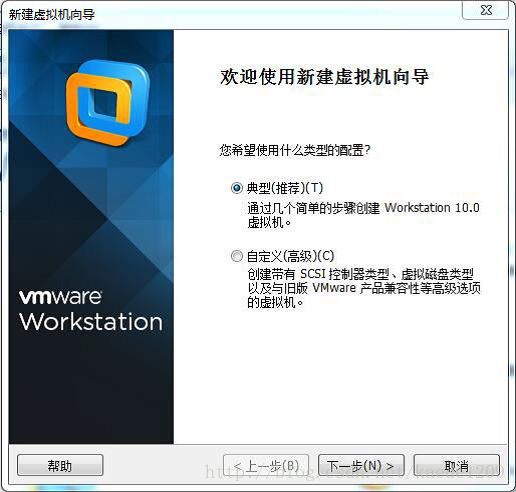
选择“安装程序光盘映像文件”,选择指定的centos系统的iso文件,点击下一步
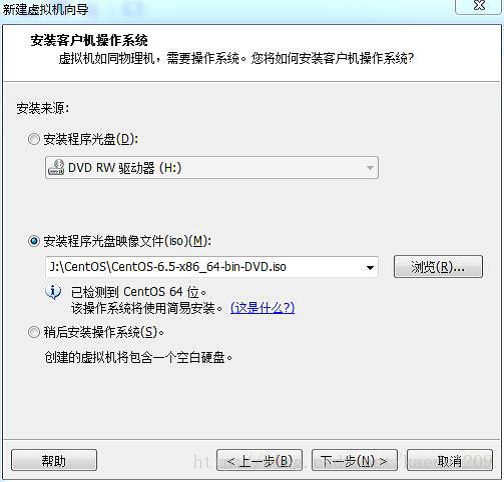
填写一下信息。点击下一步
例如 全名:zkpk 密码:zkpk 确认:zkpk

虚拟机名称:HadoopMaster 选择安装位置,点击下一步
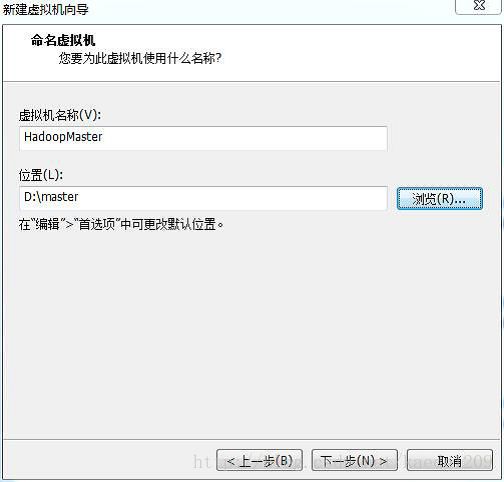
磁盘大小可选择默认值也可以调大。

进入下面页面:
等待安装完成,系统自动重启


输入密码登录系统
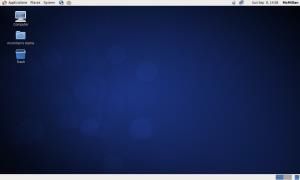
系统安装完毕
克隆HadoopSlave
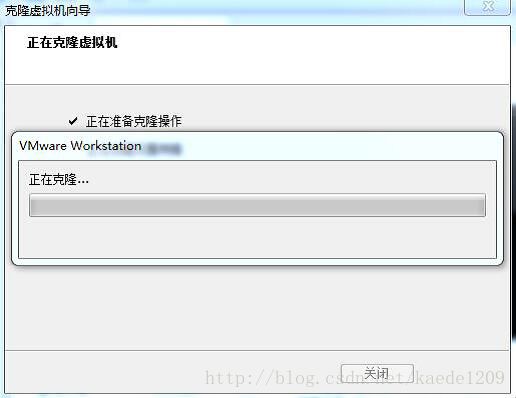
点击下图所示的“克隆”选项

点击下一步看到如下界面
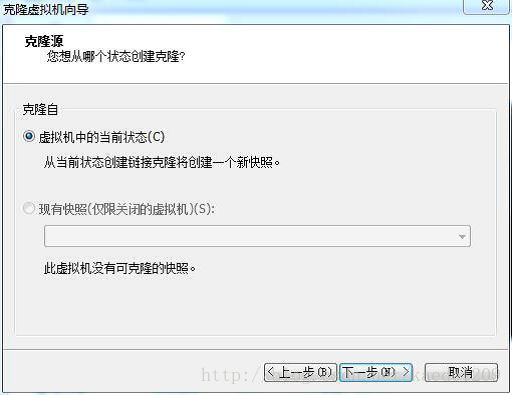
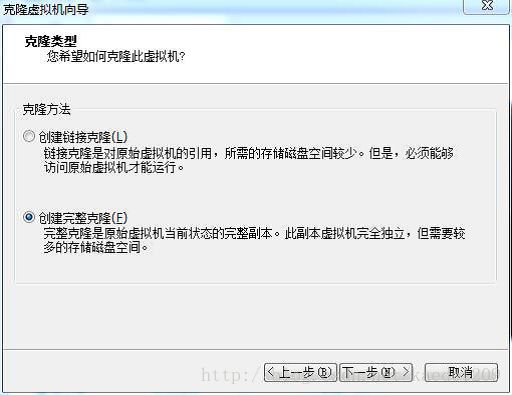
使用默认选项,点击下一步,选择创建完整克隆,点击下一步,如图所示
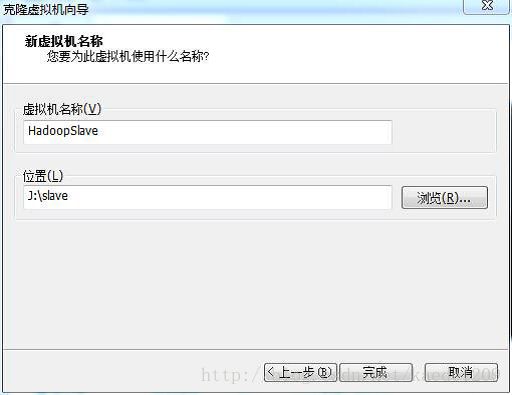
将虚拟机重命名为HadoopSlave,选择一个存储位置(10G)点击完成
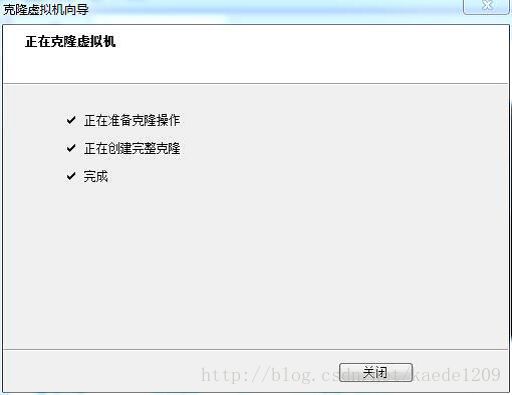
完成克隆
可以用xshell连接虚拟机,xftp传输文件到虚拟机。
3 centos安装Hadoop
3.1 Linux系统配置
一下操作步骤需要在HadoopMaster和HadoopSlave节点上分别完成操作,都使用root用户,从当前切换root用户的命令如下:
[zkpk@master ~]$ su root
输入密码:zkpk
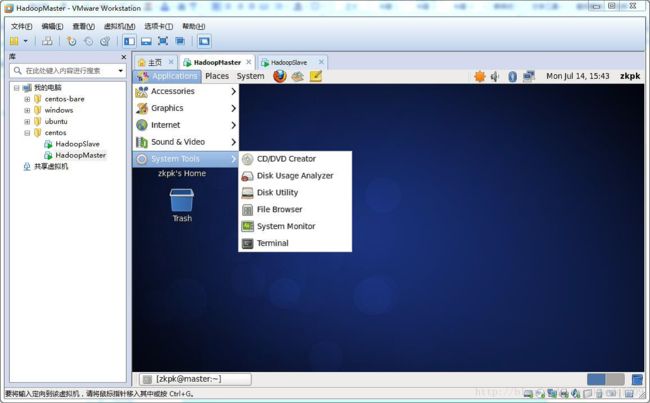
本节所有的命令都在终端环境,打开终端的过程如下,或者使用xshell
3.2.1 软件包和数据包说明
将完整的软件包“/home/zkpk/resources”下的software是相关的安装软件包。
3.2.2配置主机名
1、HadoopMaster节点
使用vim编辑主机名
[root@master zkpk]$ vi /etc/sysconfig/network
或者使用gedit命令直接编辑。
配置信息如下:
NETWORKING=yes #启动网络
HOSTNAME=master #主机名
确定修改生效命令:
[root@master zkpk]$ hostname master
检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,打开新的终端:
[root@master zkpk]$ hostname
执行完命令,会看到如下的打印输出:

2、HadoopSlave节点
使用gedit编辑主机名:
[root@slave zkpk]$ gedit /etc/sysconfig/network
配置信息如下:
NETWORKING=yes #启动网络
HOSTNAME=slave #主机名
确定修改生效命令:
[root@slave zkpk]$ hostname slave
检测主机名是否修改如前面所示。
3.2.3使用setup 命令配置网络环境
以下操作也需要在slave阶段进行
在终端执行命令:
[zkpk@master ~]$ ifconfig
如果看到如下,即存在内网ip、广播地址、子网掩码,说明不需要配置网络

3.2.4 关闭防火墙
以下操作也需要在slave阶段进行
输入如下命令:
开启: chkconfig iptables on
关闭: chkconfig iptables off
3.2.5 配置host列表
以下操作也需要在slave阶段进行
需要在root用户下,编辑主机名列表的命令:
[root@master zkpk]$ gedit /etc/hosts
将下面两行添加到/etc/hosts文件中:
192.168.1.100 master
192.168.1.101 slave
注意:这里master节点的ip地址是192.168.1.100,slave对应的ip是192.168.1.101,而自己在做配置时,需要将两个ip地址改为你的master和slave对应的ip地址。
验证是否配置成功命令如下:
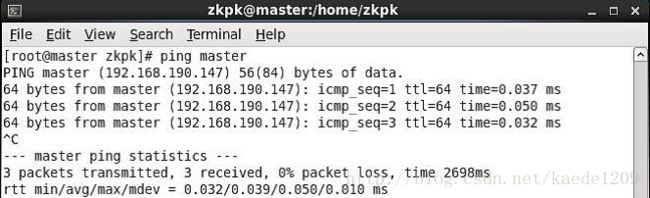
[zkpk@master ~]$ ping master
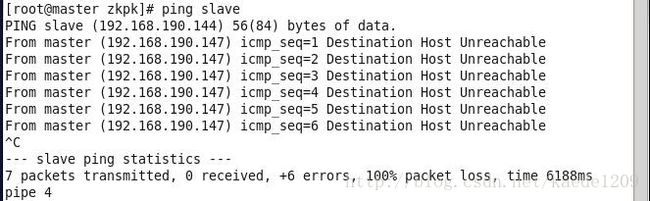
[zkpk@master ~]$ ping slave
ping通则表示配置成功如下:
如下则表示配置失败:
3.2.6安装JDK
以下操作也需要在slave阶段进行
将JDK文件解压,放到/user/java目录下
[zkpk@master ~]$ cd /home/zkpk/resources/software/jdk
[zkpk@master jdk]$ mkdir /usr/java
[zkpk@master jdk]$ cd /usr/java
[zkpk@master java]$ tar -xvf /usr/java/jdk-7u71-linux-x64.gz
使用gedit配置环境变量
[zkpk@master java]$ gedit /home/zkpk/.bash_profile
复制粘贴以下内容添加到上面gedit打开的文件中:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export PATH=$JAVA_HOME/bin:$PATH
使改动生效命令:
[zkpk@master java]$ source /home/zkpk/.bash_profile
测试配置:
[zkpk@master ~]$ java -version
出现如下表示jdk安装成功:

3.2.7免密钥登录配置
以下需要在普通用户下完成
1、HadoopMaster节点
在终端生成密钥,命令如下:
[zkpk@master ~]$ ssh-keygen -t rsa
生成的密钥在.ssh目录下如下图所示:
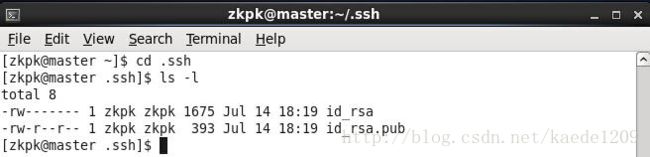
复制公钥文件
[zkpk@master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
执行ll命令可以看到如下图所示

修改authorized_keys文件的权限,命令如下:
[zkpk@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
修改完权限,查看文件列表如下:

将authorized_keys文件复制到slave节点,命令如下:
[zkpk@master .ssh]$ scp ~/.ssh/authorized_keys zkpk@slave:~/
如果有提示yes/no时,输入yes,回车。
2、HadoopSlave节点
在终端生成密钥,命令如下(一直点击回车生成密钥)
[zkpk@slave ~]$ ssh-keygen -t rsa
将authorized_keys文件移动到.ssh目录
[zkpk@slave ~]$ mv authorized_keys ~/.ssh/
修改authorized_keys文件的权限,命令如下:
[zkpk@slave ~]$ cd ~/.ssh
[zkpk@slave .ssh]$ chmod 600 authorized_keys
3、验证免密钥登陆
在HadoopMaster机器上执行下面的命令:
[zkpk@master ~]$ ssh slave
如果出现如下则表示成功:

3.3Hadoop配置部署
每个节点上的Hadoop配置基本相同,在HadoopMaster节点操作,然后完成复制到另一个节点。将Hadoop的安装包放到Linux环境下
3.3.1 Hadoop安装包解压
进入Hadoop软件包,命令如下:
[zkpk@master ~]$ cd /home/zkpk/resources/software/hadoop/apache
复制并解压Hadoop安装包命令如下:
[zkpk@master apache]$ cp ~//resources/software/hadoop/apache/hadoop-2.5.2.tar.gz ~/
[zkpk@master apache]$ cd
[zkpk@master ~]$ tar -xvf ~/hadoop-2.5.2.tar.gz
[zkpk@master ~]$ cd ~/hadoop-2.5.2
ls -查看如下内容,表示解压成功
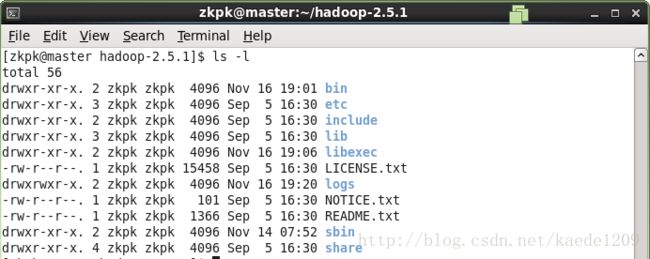
3.3.2配置环境变量hadoop-env.sh
环境变量文件中,只需要配置JDK的路径
[zkpk@master hadoop-2.5.2]$ gedit /home/zkpk/hadoop-2.5.2/etc/hadoop/hadoop-env.sh
在文件的靠前的部分找到下面的一行代码:
export JAVA_HOME=${JAVA_HOME}
将这行代码修改为下面的代码:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.3.3配置环境变量yarn-env.sh
环境变量文件中,只需要配置jdk的路径。
[zkpk@master hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/yarn-env.sh
在文件的靠前的部分找到下面的一行代码:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
将这行代码修改为下面的代码:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.3.4配置核心组件core-site.xml
使用gedit编辑:
[zkpk@master hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/core-site.xml
用下面的代码替换core-site.xml中的内容:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/home/zkpk/hadoopdata
3.3.5配置文件系统hdfs-site.xml
使用gedit编辑:
[zkpk@master hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/hdfs-site.xml
用下面的代码替换:
dfs.replication
1
3.3.6配置文件系统yarn-site.xml
使用gedit编辑:
[zkpk@master hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/yarn-site.xml
用一下内容替换:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.resourcemanager.webapp.address
master:18088
3.3.7配置计算框架mapred-site.xml
将/mapred-site.xml.template文件改名为/mapred-site.xml
[zkpk@master ~]$mv /mapred-site.xml.template /mapred-site.xml
用以下内容代替:
mapreduce.framework.name
yarn
3.3.8 在master节点配置slaves文件
使用gedit命令:
[zkpk@master hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/slaves
用如下内容代替:
slave
3.3.9 复制到从节点
使用以下命令将已经配置完成的Hadoop复制到从节点HadoopSlave上:
[zkpk@master hadoop-2.5.2]$ cd
[zkpk@master ~]$ scp -r hadoop-2.5.2 zkpk@slave:~/
注意:因为之前配置了免密钥登录,所以可以直接远程复制。
3.4 启动Hadoop集群
3.4.1 配置Hadoop启动的系统环境变量
需要同时在两个节点上进行操作,命令如下:
[zkpk@master hadoop-2.5.2]$ cd
[zkpk@master ~]$ gedit ~/.bash_profile
在末尾添加如下内容:
#HADOOP
export HADOOP_HOME=/home/zkpk/hadoop-2.5.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行命令:
[zkpk@master ~]$ source ~/.bash_profile
3.4.2启动Hadoop集群
1、格式化文件系统
在HadoopMaster节点上操作:
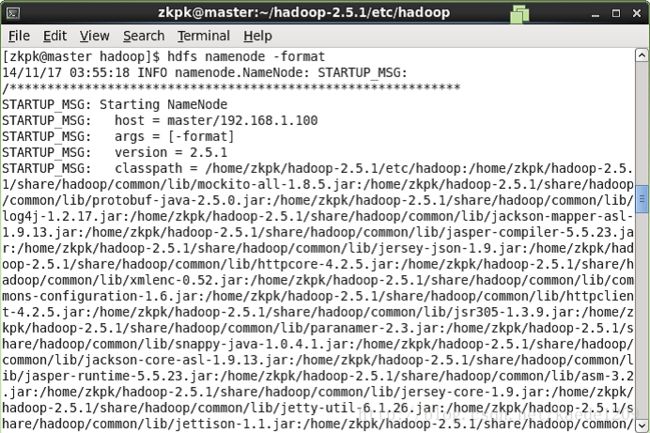
[zkpk@master ~]$ hdfs namenode -format
如下图表示成功:
2、启动Hadoop
使用如下命令启动Hadoop
[zkpk@master ~]$ cd ~/hadoop-2.5.2
[zkpk@master hadoop-2.5.2]$ sbin/start-all.sh
此命令显示已经过时,也可用其他方式启动Hadoop
3、查看进程是否启动
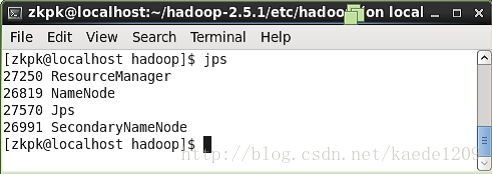
在HadoopMaster上面执行命令jps会看到四个进程如下图:
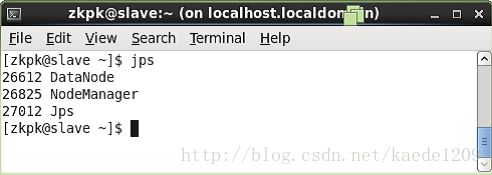
在HadoopSlave节点上执行jps会看到上三个进程如下:
4、Web UI查看集群是否成功启动
打开浏览器,输入网址http://master:50070/ 进入如下页面

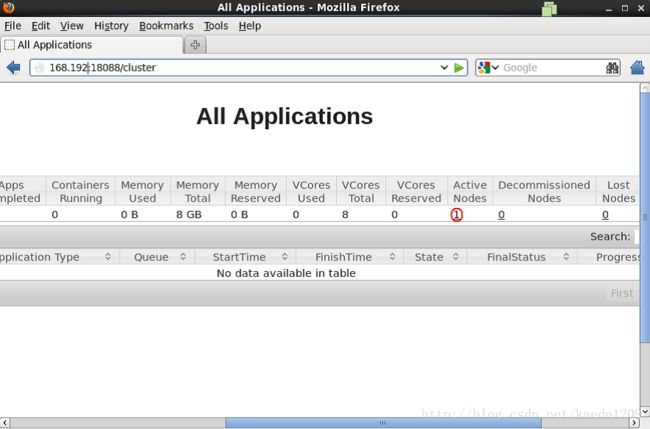
输入网址http://master:18088/ ,检查yarn是否正常,以及MapReduce程序运行情况等,页面如下:
5、运行PI实例检查集群是否成功
进入Hadoop安装的目录,以下命令:
[zkpk@master ~]$ cd ~/hadoop-2.5.2/share/hadoop/mapreduce/
会看到如下结果:

最后输出:
Estimated value of pi is 3.20000000000000
说明集群正常启动
Hadoop安装完成