jvm
网上看到了很多大神写的jvm的文章,有很深的感触,所以这里总结一下,写的不好的请大家指出。
jdk/bin目录下有个工具 jvisualvm.exe,我们使用它会更直观的了解jvm。废话不多说,打开它。
点击工具插件安装插件 Visual GC,打开它你会看到下面的界面,它就是jvm的内部结构。
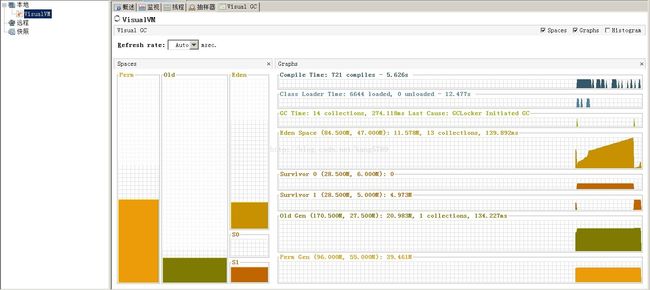
如上图所示,jvm可以分为以下几个部分
Eden:年轻代,用来存放JVM刚分配的Java对象
Survivor0(S0),Survivor1(S1):两个Survivor空间一样大,当Eden满了的时候会进行一次普通GC(垃圾回收),没有被回收掉时对象会复制到Survivor任意一个,当这个Survivor也满了的时候会在两个Survivor之间来回Copy,当满足某个条件,比如Copy次数,就会被Copy到Old。显然,Survivor只是增加了对象在年轻代中的逗留时间,增加了被垃圾回收的可能性。
Old:年老代,用来存放一些存活时间较长的Java对象
Perm:永久代,存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间。
垃圾回收算法
垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
- Serial算法(单线程)
- 并行算法
- 并发算法
JVM会根据机器的硬件配置对每个内存代选择适合的回收算法,比如,如果机器多于1个核,会对年轻代选择并行算法,关于选择细节请参考JVM调优文档。
稍微解释下的是,并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行,而并发算法,也是多线程回收,但期间不停止应用执行。所以,并发算法适用于交互性高的一些程序。经过观察,并发算法会减少年轻代的大小,其实就是使用了一个大的年老代,这反过来跟并行算法相比吞吐量相对较低。
还有一个问题是,垃圾回收动作何时执行?
- 当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
- 当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
- 当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
另一个问题是,何时会抛出OutOfMemoryException,并不是内存被耗空的时候才抛出
- JVM98%的时间都花费在内存回收
- 每次回收的内存小于2%
满足这两个条件将触发OutOfMemoryException,这将会留给系统一个微小的间隙以做一些Down之前的操作,比如手动打印Heap Dump。
系统崩溃前的一些现象:
- 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
- FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
- 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
Q:为什么崩溃前垃圾回收的时间越来越长?
A:根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
Q:为什么Full GC的次数越来越多?
A:因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
Q:为什么年老代占用的内存越来越大?
A:因为年轻代的内存无法被回收,越来越多地被Copy到年老代
在JVM启动参数中,可以设置跟内存、垃圾回收相关的一些参数设置,默认情况不做任何设置JVM会工作的很好,但对一些配置很好的Server和具体的应用必须仔细调优才能获得最佳性能。通过设置我们希望达到一些目标:
- GC的时间足够的小
- GC的次数足够的少
- 发生Full GC的周期足够的长
前两个目前是相悖的,要想GC时间小必须要一个更小的堆,要保证GC次数足够少,必须保证一个更大的堆,我们只能取其平衡。
(1)针对JVM堆的设置一般,可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值
(2)年轻代和年老代将根据默认的比例(1:2)分配堆内存,可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代,比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小
(3)年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。我们观察一下二者大小变化有哪些影响
- 更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
- 更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
- 如何选择应该依赖应用程序对象生命周期的分布情况:如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性,在抉择时应该根据以下两点:(A)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 (B)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间
(4)在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC ,默认为Serial收集
(5)线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
(4)可以通过下面的参数打Heap Dump信息
- -XX:HeapDumpPath
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:/usr/aaa/dump/heap_trace.txt
通过下面参数可以控制OutOfMemoryError时打印堆的信息
- -XX:+HeapDumpOnOutOfMemoryError
请看一下一个时间的Java参数配置:(服务器:Linux 64Bit,8Core×16G)
JAVA_OPTS="$JAVA_OPTS -server -Xms3G -Xmx3G -Xss256k -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseParallelOldGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/aaa/dump -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/aaa/dump/heap_trace.txt -XX:NewSize=1G -XX:MaxNewSize=1G"
经过观察该配置非常稳定,每次普通GC的时间在10ms左右,Full GC基本不发生,或隔很长很长的时间才发生一次
通过分析dump文件可以发现,每个1小时都会发生一次Full GC,经过多方求证,只要在JVM中开启了JMX服务,JMX将会1小时执行一次Full GC以清除引用
引用: http://blog.csdn.net/lifuxiangcaohui/article/details/37992725