python网络爬虫学习(六)利用Pyspider+Phantomjs爬取淘宝模特图片
本篇博文在编写时参考了http://cuiqingcai.com/2652.html,向作者表示感谢
一.新的问题与工具
平时在淘宝上剁手的时候,总是会看到各种各样的模特。由于自己就读于一所男女比例三比一的工科院校……写代码之余看看美女也是极好的放松方式。但一张一张点右键–另存为又显得太过麻烦而且不切实际,毕竟图片太多了。于是,我开始考虑用万能的python来解决问题。
我们先看看淘女郎页面的URL,https://mm.taobao.com/json/request_top_list.htm?page=1
page后面的数字代表页码,那么有多少页呢?反正我试着写了个10000发现依然有页面存在。由此可见,右键另存为极不现实。
要用爬虫去爬,就得先分析页面,我们打开第一个淘女郎的页面,如图
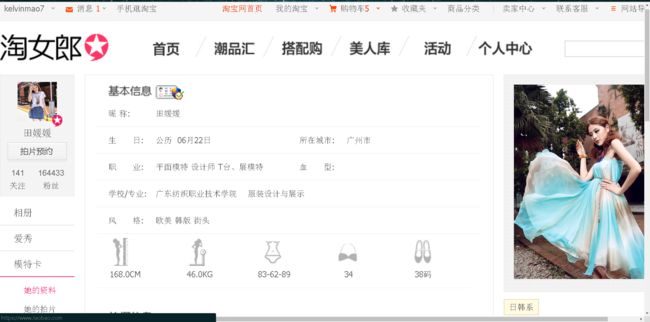
看起来好像和我们之前爬过的站没什么不同嘛,直接上urllib和urllib2不就好了?不过,当我打开页面源码时,发现并非如此,源码如图
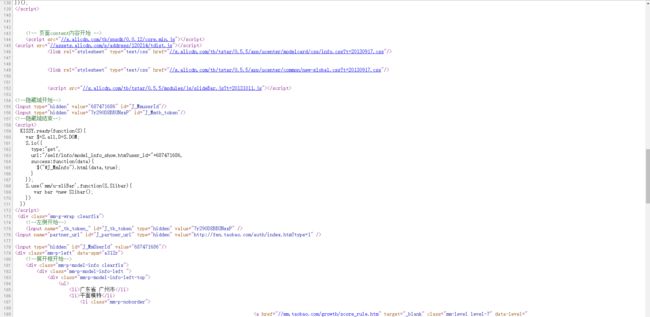
这个页面的很多内容并没有出现在源码中,很明显,使用js加载出来的。那么,我们常用的urllib2库也就起不了什么作用了,因为这个库只能获取到HTML中的内容。于是,在经过查找资料后, 我找到了另外两个好用的工具:Pyspider和Phantomjs
Pyspider是一个爬虫框架,具有webUI,CSS选择器等实用的功能,支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等等的功能,使用非常人性化。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它全面支持web而不需浏览器支持,其快速、原生支持各种Web标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可以用于页面自动化、网络监测、网页截屏以及无界面测试等。
在介绍完我们的主角之后,我会对我配置开发环境的过程中遇到的问题进行记录。
二.开发环境的配置
系统环境:Ubuntu 14.04 -i386(注意一定要使用32位的Ubuntu,因为经过我的实际测试phantomjs无法在64位系统上运行,另外,也无法再16.04版本的Ubuntu上运行,建议系统环境与我保持一致)
step 1:安装pip
sudo apt-get install python-pipstep 2:安装Phantomjs
sudo apt-get install phantomjsstep 3:安装Pyspider
根据官方文档,在在安装pyspider之前,你需要安装以下类库
sudo apt-get install python python-dev python-distribute python-pip libcurl4-openssl-dev libxml2-dev libxslt1-dev python-lxml安装过程完成之后,运行
sudo pyspider all不报错即为安装成功,如果有错误,请善用google和baidu,都可以找到答案。
之后进入图形界面,打开浏览器在地址栏中输入localhost:5000即可

下面记录一个似乎是只有我遇到的问题,在使用ubuntu自带的firefox时,在之后的一步操作中会出现问题,至于问题是什么待会儿陈述,强烈建议各位使用应用商店中别的浏览器。
之后打开目标网站https://mm.taobao.com/json/request_top_list.htm?page=1
打开第一位模特的页面,如图

注意到个性域名了吗?进去看看~
原来模特的图片都在这里,这样我们大致确定了爬取思路:
1.在某一页中先爬取每位模特的详情页
2.在详情页中取出我们需要的个性域名的url
3.从个性域名中筛选出图片并保存。
三.开始爬取
(1)创建项目
在浏览器中输入 http://localhost:5000,可以看到 PySpider 的主界面,点击的 Create,命名为 taobaomm,名称你可以随意取,点击 Create。
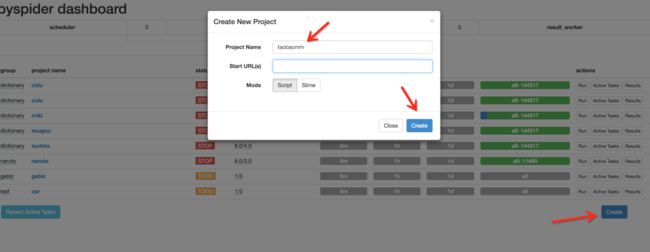
之后进入到一个爬取操作的页面。
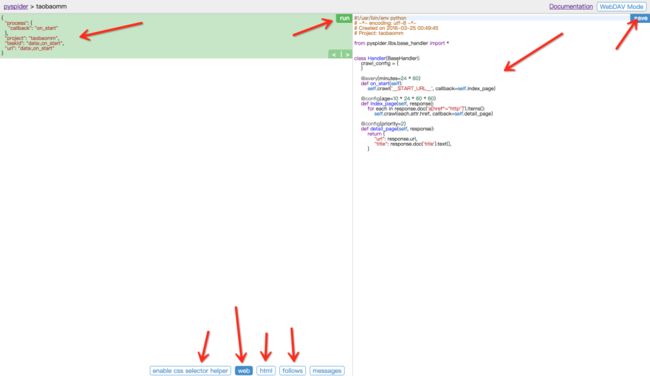
我们看到页面被分为两栏,左边是爬取页面预览区域,右边是代码编写区域。
左侧绿色区域:这个请求对应的 JSON 变量,在 PySpider 中,其实每个请求都有与之对应的 JSON 变量,包括回调函数,方法名,请求链接,请求数据等等。
绿色区域右上角Run:点击右上角的 run 按钮,就会执行这个请求,可以在左边的白色区域出现请求的结果。
左侧 enable css selector helper: 抓取页面之后,点击此按钮,可以方便地获取页面中某个元素的 CSS 选择器。
左侧 web: 即抓取的页面的实时预览图。
左侧 html: 抓取页面的 HTML 代码。
左侧 follows: 如果当前抓取方法中又新建了爬取请求,那么接下来的请求就会出现在 follows 里。
左侧 messages: 爬取过程中输出的一些信息。
右侧代码区域: 你可以在右侧区域书写代码,并点击右上角的 Save 按钮保存。
右侧 WebDAV Mode: 打开调试模式,左侧最大化,便于观察调试。
(2)进行简单的爬取操作
我们先对https://mm.taobao.com/json/request_top_list.htm?page=1这个页面进行爬取,我们在’init’ 方法中定义基地址,页码,最大页码。代码如下:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url = 'https://mm.taobao.com/json/request_top_list.htm?page='
self.page_num = 1
self.total_num = 30
@every(minutes=24 * 60)
def on_start(self):
while self.page_num <= self.total_num:
url = self.base_url + str(self.page_num)
print url
self.crawl(url, callback=self.index_page)
self.page_num += 1
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}其实只是在原先的代码中加入了一个初始化的方法,没有做其他改变,保存后运行,我们看到

我们看到控制台中给出了30个url,同时看到follow上的数字为30,这表示之后有30个请求,我们点击某一个URL右侧的绿色三角,继续爬取该页面。
我们点击左下角的web按钮,就可以预览到网页的内容,网页内容被回调给index.page方法处理,由于此时还没有编写index.page的具体方法,所以只是继续构建了链接请求。

(2)获取模特个性域名
在上一步中,我们已经看到了模特的列表,但是该如何进入详情页呢?老方法,分析页面源码

注意高亮部分,模特的详情页的URL是在一个class为”lady-name”的a标签中。那么我们就要对index.page方法加以修改如下:
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page)其中的response就是指刚才的模特列表页,调用doc函数其实是用CSS选择器得到每个模特的链接,然后用self.crawl方法继续发起请求。回调函数是 detail_page,爬取的结果会作为 response 变量传过去。detail_page 接到这个变量继续下面的分析。
继续点击小三角爬取下一个页面,得到的页面如下

似乎和我们在浏览器中看到的有点不一样,图片没有被加载出来。什么原因呢?因为这个页面比较特殊,它是用JS动态加载出来的,所以我们看不到任何内容。怎么办呢?我们就要使用神器Phantomjs
了。我们对index.page方法作出如下的修改:
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')只需要在self.crawl方法中加上 fetch=’js’即可,这表示使用phantomjs来加载页面。
请各位注意,在文章开始时,我提到过我遇到一个难以解决的问题,当我使用firefox浏览器打开pyspider的webUI时,这一步即使我加上 fetch=’js’依然没有加载出页面,直到后来我换用了chromeium浏览器才解决这个问题,请各位注意!!我在这个问题上浪费了两天时间,希望各位不要在这个问题上耽误太多时间
现在点击向左的箭头返回到上一页,重新爬取模特的详情页,页面被成功加载,phantomjs名不虚传
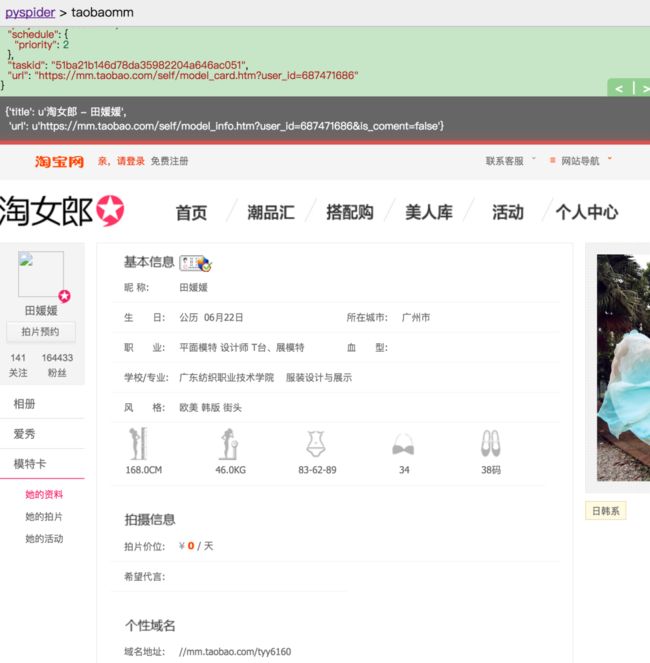
看到个性域名了吗?我们离成功只差一步,下面我们解决如何从详情页中获取到模特的个性域名。
老规矩,F12打开chrome的开发者模式,搜索个性域名的URL,找到其所在的标签。

找到后,增加一个domain_page方法用来处理个性域名,并修改detail_page方法如下:
def detail_page(self, response):
domain = 'https:' + response.doc('.mm-p-domain-info li > span').text()
print domain
self.crawl(domain, callback=self.domain_page)
def domain_page(self, response):
passmm-p-domain-info li > span指的是从域名所在的div标签到span标签的路径上的所有祖先节点。再加上”https:”就组成了个性域名的URL。之后使用self.crawl来继续对domain这个页面进行爬取。
再次点击run按钮,我们就可以看到模特的主页了
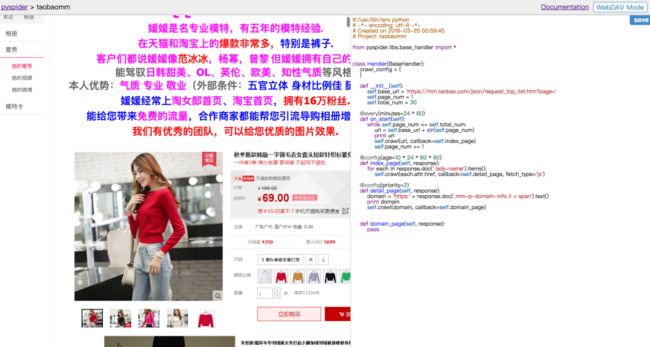
接下来该怎么办?你懂得~~~~
(3)保存照片和简介
进入了模特的个人页面,我们再次分析源码,寻找简介和照片的位置。

找到模特姓名所在的标签,那么要使用CSS选择器进行解析的话,路径应该是这样的: .mm-p-model-info-left-top dd > a
同样的方法找到简介为: .mm-aixiu-content
图片为: .mm-aixiu-content img
这样我们就定位了我们所需要的信息在页面上的位置。
之后我们完善domain_page方法如下:
def domain_page(self, response):
name=response.doc('.mm-p-model-info-left-top dd > a').text()
dir_path=self.deal.mkDIR(name)
brief=response.doc('.mm-aixiu-content').text()
if dir_path:
imgs=response.doc('.mm-aixiu-content img').items()
count=1
self.deal.save_brief(brief,name,dir_path)
for img in imgs:
url = img.attr.src
if url:
extension=self.deal.getextension(url)
file_name=name+str(count)+'.'+extension
#self.deal.save_Img(img.attr.src,file_name)
count += 1
self.crawl(img.attr.src, callback=self.save_img, save={'save_path':dir_path,'file_name':file_name})
def save_img(self,response):
content=response.content
dir_path=response.save['save_path']
file_name=response.save['file_name']
file_path=dir_path+'/'+file_name
self.deal.save_Img(content,file_path)上述代码首先用save_brief方法保存页面所有文字,之后遍历模特所有图片,用save_Img方法保存所有照片,并使用一个自增变量+模特姓名来构造文件名。
(3)保存照片至本地
下面定义文件处理类
class Deal:
def __init__(self):
self.dir_path=DIR_PATH
if not self.dir_path.endswith('/'):
self.dir_path=self.dir_path+'/'
if not os.path.exists(self.dir_path):
os.makedirs(self.dir_path)
def mkDIR(self,name):
name=name.strip()
#dir_name=self.dir_path+'/'+name
dir_name=self.dir_path+name
exists=os.path.exists(dir_name)
if not exists:
os.makedirs(dir_name)
return dir_name
else:
return dir_name
def save_Img(self,content,file_name):
file=open(file_name,'wb')#这个地方将图片以二进制流写入文件
file.write(content)
file.close()
def save_brief(self,brief,name,path):
file_name=path+'/'+name+'.txt'
file=open(file_name,'w+')
file.write(brief.encode('utf-8'))
file.close()
def getextension(self,url):
extension=url.split('.')[-1]
return extension文件处理类主要使用os模块的一些方法,都是基础内容,没什么好说的,有不懂的地方请使用搜索引擎或者翻阅python教程。
三.大功告成
到这里,我们就完成了基本的功能,下面贴出完整代码,version 1.0.0就算基本完成。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-06-15 10:48:25
# Project: taobaomm_v1
# Version:1.0.0
# Function:保存模特照片至本地,以模特姓名建立文件夹来分类存储
from pyspider.libs.base_handler import *
import os
PAGE_NUM=1#起始页码
MAX_PAGE=30#终止页码
DIR_PATH='/home/kelvinmao/Music/'#定义保存位置(这三个变量都可以自己填)
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url='https://mm.taobao.com/json/request_top_list.htm?page='
self.page_num=PAGE_NUM
self.max_page=MAX_PAGE
self.deal=Deal()
@every(minutes=24 * 60)
def on_start(self):
while self.page_num<=self.max_page:
url=self.base_url+str(self.page_num)
print url
self.crawl(url, callback=self.index_page)
self.page_num+=1
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
@config(priority=2)
def detail_page(self, response):
domain = response.doc('.mm-p-domain-info li > span').text()
if domain:
domain_name = 'https:' + domain
self.crawl(domain_name, callback=self.domain_page)
def domain_page(self, response):
name=response.doc('.mm-p-model-info-left-top dd > a').text()
dir_path=self.deal.mkDIR(name)
brief=response.doc('.mm-aixiu-content').text()
if dir_path:
imgs=response.doc('.mm-aixiu-content img').items()
count=1
self.deal.save_brief(brief,name,dir_path)
for img in imgs:
url = img.attr.src
if url:
extension=self.deal.getextension(url)
file_name=name+str(count)+'.'+extension
#self.deal.save_Img(img.attr.src,file_name)
count += 1
self.crawl(img.attr.src, callback=self.save_img, save={'save_path':dir_path,'file_name':file_name})
def save_img(self,response):
content=response.content
dir_path=response.save['save_path']
file_name=response.save['file_name']
file_path=dir_path+'/'+file_name
self.deal.save_Img(content,file_path)
class Deal:
def __init__(self):
self.dir_path=DIR_PATH
if not self.dir_path.endswith('/'):
self.dir_path=self.dir_path+'/'
if not os.path.exists(self.dir_path):
os.makedirs(self.dir_path)
def mkDIR(self,name):
name=name.strip()
#dir_name=self.dir_path+'/'+name
dir_name=self.dir_path+name
exists=os.path.exists(dir_name)
if not exists:
os.makedirs(dir_name)
return dir_name
else:
return dir_name
def save_Img(self,content,file_name):
file=open(file_name,'wb')
file.write(content)
file.close()
def save_brief(self,brief,name,path):
file_name=path+'/'+name+'.txt'
file=open(file_name,'w+')
file.write(brief.encode('utf-8'))
file.close()
def getextension(self,url):
extension=url.split('.')[-1]
return extension粘贴这些代码到你的pyspider中,保存
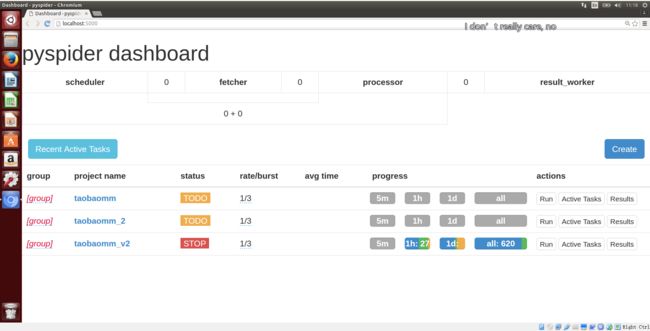
点击STOP或者TODO状态,将其切换为RUNNING,点击右侧的run按钮,就可以看到海量的照片奔向你的电脑了。
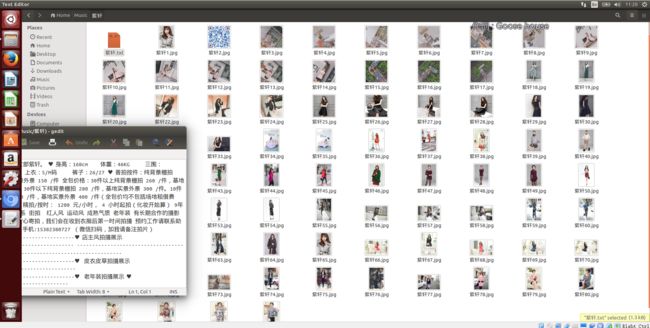
四.后续
随着学习的深入,打算增添一些更有趣的功能,比如将模特的三围,居住地,身高体重或者风格等数据建立数据库,便于检索,甚至可以建立一个网站。不过一切都依赖于我的继续学习。