自定义Druid的拦截器
自定义Druid的拦截器
Druid是一个JDBC组件,它包括三部分:
- DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。
- DruidDataSource 高效可管理的数据库连接池。
- SQLParser
Druid可以做什么?
1) 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
2) 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
3) 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
4) SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
-------------------------------------分割线--------------------------------------------
怎么使用Druid提供的Filter-Chain机制,方便编写JDBC层的扩展插件呢?
这才是本篇文章重点要描述的。
https://github.com/alibaba/druid/wiki/%E9%A6%96%E9%A1%B5 druid官方里面好像没找到。
(代码里面的注释真的少得可怜。。。)
不过用过druid的知道里面内置了一些filter
例如在配置
附内置filter的别名
| Filter类名 | 别名 |
| default | com.alibaba.druid.filter.stat.StatFilter |
| stat | com.alibaba.druid.filter.stat.StatFilter |
| mergeStat | com.alibaba.druid.filter.stat.MergeStatFilter |
| encoding | com.alibaba.druid.filter.encoding.EncodingConvertFilter |
| log4j | com.alibaba.druid.filter.logging.Log4jFilter |
| log4j2 | com.alibaba.druid.filter.logging.Log4j2Filter |
| slf4j | com.alibaba.druid.filter.logging.Slf4jLogFilter |
| commonlogging | com.alibaba.druid.filter.logging.CommonsLogFilter |
这些Filter都实现了com.alibaba.druid.filter.Filter 这个接口,里面的函数太多。。
从哪里开始?
其实最简单的方法就是仿照已有的Filter来写,例如Log4jFilter,
Log4jFilter 继承 LogFilter,从上面看出,Druid日志插件还支持Slf4jLog,CommonsLog。这里面其实就是根据不同情况打印不同的日志。
LogFilter又继承于FilterEventAdapter这个类,这个类好像很熟悉,貌似Spring里面经常会有xxxAdapter来帮我们对一些接口实现一些默认的方法,而我们只需要继承这个类, 重写里面需要重写方法就可以了。
里面最重要的方法就是
@Override
public boolean preparedStatement_execute(FilterChain chain, PreparedStatementProxy statement) throws SQLException {
try {
//抽象方法
statementExecuteBefore(statement, statement.getSql());
boolean firstResult = chain.preparedStatement_execute(statement);
//抽象方法,后面我们会重写这个方法
this.statementExecuteAfter(statement, statement.getSql(), firstResult);
return firstResult;
} catch (SQLException error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
} catch (RuntimeException error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
} catch (Error error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
}
}
好吧,这个方法就是实行FilterChain的preparedStatement_execute方法。这里就是filter的执行链上的一个node把。
依葫芦画瓢
1. 创建一个Filter
/**
* Created by hzlizhou on 2017/2/5.
*/
public class TestFilter extends FilterEventAdapter{
@Override
protected void statementExecuteAfter(StatementProxy statement, String sql, boolean result) {
System.out.println("haha");
super.statementExecuteAfter(statement, sql, result);
}
}
我们自己写一个TestFilter, 继承FilterEventAdapter,重写statementExecuteAfter方法(在SQL语句执行成功以后会执行)
2. 加入到执行链(ChainFilter)
仔细看DruidDataSource,他的父类,里面有个
protected Listfilters = new CopyOnWriteArrayList ();
public void setFilters(String filters) throws SQLException {
if (filters != null && filters.startsWith("!")) {
filters = filters.substring(1);
this.clearFilters();
}
this.addFilters(filters);
}
还有一个set方法是直接加入filters
public void setProxyFilters(Listfilters) { if (filters != null) { this.filters.addAll(filters); } }
因此,我们在datasource配置中增加
以及对应的bean
运行程序,发现每次成功访问数据库都会打印"haha",看来这样做的是对的。这样,我们就可以按照自己的需求自定义一些操作啦(我的目的其实就是数据库同步,把增、删、改的sql语句加入队列中)
原理解析
简单分析下Druid的Filter吧。其实和一般的Filter一样的(Spring Security,Servlet),功能就是在执行真正的业务代码之前和之后增加一些自定义的功能。
顺着刚才的思路往上找,刚才分析到了
@Override
public boolean preparedStatement_execute(FilterChain chain, PreparedStatementProxy statement) throws SQLException {
try {
//抽象方法
statementExecuteBefore(statement, statement.getSql());
//重点是这里!!!!
boolean firstResult = chain.preparedStatement_execute(statement);
//抽象方法,后面我们会重写这个方法
this.statementExecuteAfter(statement, statement.getSql(), firstResult);
return firstResult;
} catch (SQLException error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
} catch (RuntimeException error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
} catch (Error error) {
//抽象方法
statement_executeErrorAfter(statement, statement.getSql(), error);
throw error;
}
}先来看一下FilterChain ,他只有一个实现类FilterChainImpl,有3个成员变量,终于看到了DataSourceProxy(看名字也知道其实就是对DruidDataSource的代理类)
protected int pos = 0; private final DataSourceProxy dataSource; private final int filterSize;
preparedStatement_executeQuery的方法如下。这样在调用前会把所有的Filter都执行一次其中的preparedStatement_execute。
@Override
public boolean preparedStatement_execute(PreparedStatementProxy statement) throws SQLException {
if (this.pos < filterSize) {
return nextFilter().preparedStatement_execute(this, statement);
}
return statement.getRawObject().execute();
}
preparedStatement_execute在哪里被执行的呢?PreparedStatementProxyImpl#execute()
PreparedStatementProxyImpl#execute()在哪里被执行的呢? DruidPooledPreparedStatement#execute()
(好吧,我承认我是debug看调用栈的。。DruidPooledPreparedStatement#execute()就是iBatis中的调用的了!)
调用的时序大概如下面
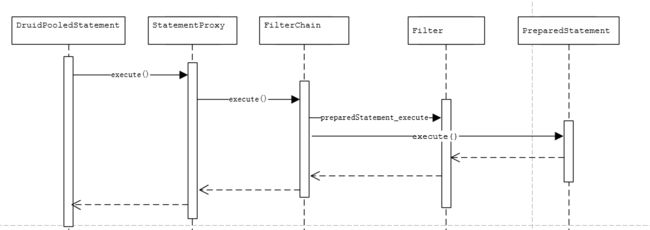
DruidPooledPreparedStatement除了execute(),还有executeUpdate(),executeQuery()。但是如果是基于ibatis的sql语句都是使用execute()。