SpringBoot集成jsoup多线程爬取美剧天堂全部电影资源
SpringBoot集成jsoup爬取美剧天堂全部美剧资源
-
准备工作
这次我的目的是获取这个网站的所有美剧的信息和迅雷的BT地址,我们需要获取的信息都在上万个类似于下面个页面结构的页面上
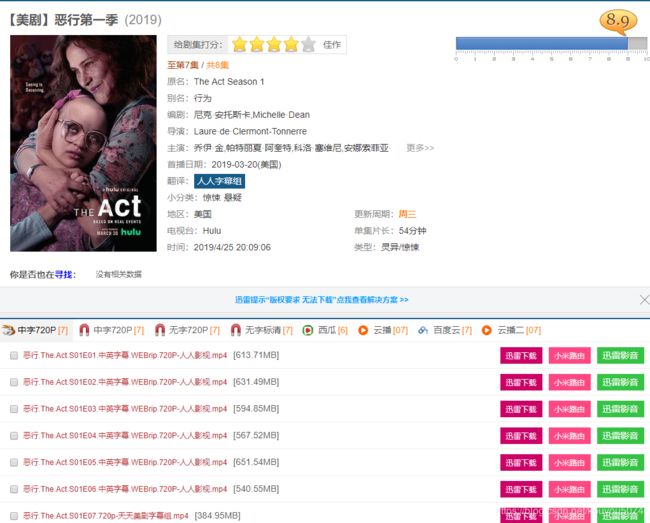
确定了目标,那就开工!
首先导入JSOUP的maven依赖,jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。org.jsoup jsoup 1.10.2 首先,爬虫最基础也是最重要的就是观察网页结构,一个好的入口url能让你事半功倍,
我们先看美剧天堂的所有资源的页面
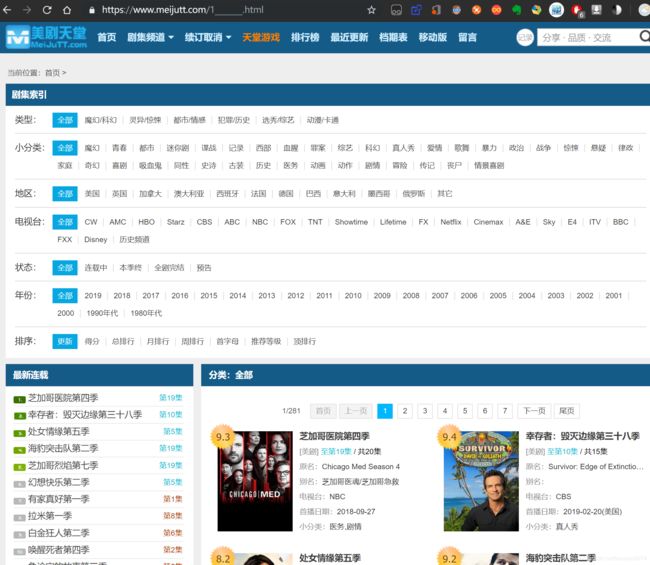
然后我们点击第二页

然后我们发现了规律,第一页和第二页以此类推都是在https://www.meijutt.com/(这里填页码)_______.html这种规律的URL,
至此我们就可以写出第一个方法,首先我们看到页面上面的 2/281 表示这个网页一共有281页,我们首先就要获取到这个最大的页码数,然后从1开始递增到最大页码数并拼在url后便能够获取到全部的这种格式的网页URL,如何从页面中获取元素呢,在这里我们就要用到jsoup包下的select方法,用一种类似于jquery的方式获取到页面的元素,在这里我们在网页上对着页码虽在的位置右键检查便能直接定位到当前元素在html文件中的位置

在这里我们发现这个元素是在 class为page的div下的span中,我们知道这一点之后便可以通过jsoup选择器定位到这里然后稍加处理便能获取到最大页码,关于jsoup选择器的使用可以看这篇文章 https://www.open-open.com/jsoup/selector-syntax.htm
下面上代码
//初始的URL入口
private static String url = "https://www.meijutt.com/1_______.html";
public String getPageNum() throws IOException {
String number ="";
try{
//使用JSOUP获取连接
Connection conn = Jsoup.connect(url).timeout(5000);
//设置请求头,模拟浏览器登陆,绕过简单的反爬虫机制
conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
conn.header("Accept-Encoding", "gzip, deflate, sdch");
conn.header("Accept-Language", "zh-CN,zh;q=0.8");
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
//从url中获取流并解析为Document对象
Document doc = conn.get();
//使用JSOUP的css选择器获取指定的Document页面元素
Elements select = doc.select(".page span");
//对获得的元素进行处理,获取页面上的页码
number = select.get(0).text().substring(select.get(0).text().indexOf("/")+1);
}catch (Exception e){
e.printStackTrace();
}
return number;
}
获取到最大页码后就可以拼接出所有的URL了
public List<String> getUrl() throws IOException {
List<String> list = new ArrayList<>(3000);
try{
String number = getPageNum();
String url = "https://www.meijutt.com/";
for(int i = 1;i<=Integer.parseInt(number);i++){
list.add(url+i+"_______.html");
}
}catch (Exception e){
e.printStackTrace();
}
return list;
}
下面回到原来的页面,确定第二个目标:
我们需要获取到每个列表页面的所有美剧单独信息的URL地址

最后我们需要做的就是爬取单独美剧页面

下面是获取所有单独美剧页面超链接的代码
//@Async通过线程池异步获取,可以不带参,使用默认的线程池
@Async("asyncPromiseExecutor")
public void getAndInsertData(String currentUrl) throws IOException {
//List allUrl = getAllUrl();
//List allUrl = new ArrayList<>();
// BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(new File("C:/lastUrl.txt")),
// "UTF-8"));
// String line = null;
// while((line=br.readLine())!=null){
// log.info(line);
// allUrl.add(line);
// }
// br.close();
// String fileName="D:"+ File.separator+"download.txt";
// File f = new File(fileName);
//OutputStream out = new FileOutputStream(f,true);//true表示追加模式,否则为覆盖
//for(String currentUrl:allUrl){
try{
Document document = Jsoup.connect(currentUrl).timeout(5000).header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("Accept-Language", "zh-CN,zh;q=0.8")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
.get();
Media m = new Media();
m.setMediaName(document.select(".info-title span").text()+document.select(".info-title h1").text());
// if(!"".equals(document.select(".info-title span").text()+document.select(".info-title h1").text())){
// int countByMediaName = mediaDAO.getCountByMediaName(document.select(".info-title span").text() + document.select(".info-title h1").text());
// if(countByMediaName>=1){
// return; //重复数据不爬取
// }
// }else {
// return;
// }
m.setPrimitiveName(document.select(".o_r_contact ul li").get(1).text().substring(document.select(".o_r_contact ul li").get(1).text().indexOf(":")+1));
m.setAlias(document.select(".o_r_contact ul li").get(2).text().substring(document.select(".o_r_contact ul li").get(2).text().indexOf(":")+1));
m.setScriptWriterName(document.select(".o_r_contact ul li").get(3).text().substring(document.select(".o_r_contact ul li").get(3).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(3).text().indexOf("更多")));
m.setDirectorName(document.select(".o_r_contact ul li").get(4).text().substring(document.select(".o_r_contact ul li").get(4).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(4).text().indexOf("更多")));
m.setActors(document.select(".o_r_contact ul li").get(5).text().substring(document.select(".o_r_contact ul li").get(5).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(5).text().indexOf("更多")));
String Date = document.select(".o_r_contact ul li").get(6).text().substring(document.select(".o_r_contact ul li").get(6).text().indexOf(":") + 1);
// SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
// Date premiereDate = df.parse(Date);
m.setBigMediaKind(document.select(".o_r_contact ul li").get(8).text().substring(document.select(".o_r_contact ul li").get(8).text().indexOf(":")+1));
m.setLocation(document.select(".o_r_contact ul li").get(9).select("label").text().substring(document.select(".o_r_contact ul li").get(9).select("label").text().indexOf(":")+1));
m.setTvStation(document.select(".o_r_contact ul li").get(10).select("label").text().substring(document.select(".o_r_contact ul li").get(10).select("label").text().indexOf(":")+1));
String secondDate = document.select(".o_r_contact ul li").get(11).select("label").text().substring(document.select(".o_r_contact ul li").get(11).select("label").text().indexOf(":")+1);
// SimpleDateFormat dff = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
// Date timeSchadule = dff.parse(secondDate);
m.setTimeSchadule(secondDate);
m.setPremiereDate(Date);
m.setMediaKind( document.select(".o_r_contact ul li").get(11).select("span").text().substring(document.select(".o_r_contact ul li").get(11).select("span").text().indexOf(":")+1));
//log.info(document.select("#score-stars").toString());
//m.setGrade(document.select("#schedule-score").attr("style"));
String params = "id="+currentUrl.substring(currentUrl.lastIndexOf("meiju")+5,currentUrl.lastIndexOf("."))+"&action=newstarscorevideo";
//log.info(params);
Thread.sleep(1000);
String s = HttpRequest.sendGet("https://www.meijutt.com/inc/ajax.asp", params);
//log.info(s);
String substring = s.substring(s.indexOf("[") + 1, s.indexOf("]"));
String[] split = substring.split(",");
double v = Double.parseDouble(split[0]);
double v0 = Double.parseDouble(split[1]);
double v1 = Double.parseDouble(split[2]);
double v2 = Double.parseDouble(split[3]);
double v3 = Double.parseDouble(split[4]);
Double grade =(v*2+v0*4+v1*6+v2*8+v3*10)/(v+v0+v1+v2+v3);
DecimalFormat df3 = new DecimalFormat("#.00");
String str = df3.format(grade);
m.setGrade(str);
String imgUrl = document.select(".o_big_img_bg_b img").attr("src");
String imgName = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date())+String.valueOf(new Random().nextInt(10000));
DownloadUtil.downloadImage(imgUrl,imgName);
m.setImage(imgName);
log.info(m.toString());
//mediaDAO.insert(m);
//已经插入的url写入文件以下次断点续爬
// byte[] b = currentUrl.getBytes();
// out.write(b);
Thread.sleep(100);
//Integer id = m.getId();
//m1.setUrlName(document.select(".down_list").select(".max-height").select("li"));
try{
Elements li = document.select(".down_list").get(0).select("ul li");
if(li.size()!=0){
for(int i=0;i<li.size();i++){
Thread.sleep(100);
Element element = li.get(i);
//log.info(element.toString());
LinkMedia m1 = new LinkMedia();
m1.setUrlName(element.select(".down_part_name").select("a").text());
m1.setSize(element.select("em").text());
//m1.setLinkId(id);
m1.setUrlAddress(element.select(".down_part_name").select("a").attr("href").replaceAll("请输入ED2K://开头的","").replaceAll("地址",""));
//log.info( element.select("em").text());
// log.info(m1.toString());
//linkMediaDAO.insert(m1);
log.info(m1.toString());
}
}
}catch (Exception e){
e.printStackTrace();
log.info(currentUrl);
return;
}
//log.info(li.toString());
//log.info(Integer.valueOf(li.size()).toString());
}catch (Exception e){
e.printStackTrace();
log.info(currentUrl);
}
//
//}
//out.close();
}
下面上爬虫源码以及相关实体类代码和工具类代码
import com.linkjb.servicebase.dao.LinkMediaMapper;
import com.linkjb.servicebase.dao.MediaMapper;
import com.linkjb.servicebase.pojo.LinkMedia;
import com.linkjb.servicebase.pojo.Media;
import com.linkjb.servicebase.service.SpiderService;
import com.linkjb.servicebase.utils.DownloadUtil;
import com.linkjb.servicebase.utils.HttpRequest;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.io.*;
import java.text.DecimalFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.regex.Pattern;
/**
* @author sharkshen
* @data 2019/3/22 13:52
* @Useage
*/
@Service
public class SpiderServiceImp {
// @Resource
// MediaMapper mediaDAO;
// @Resource
// LinkMediaMapper linkMediaDAO;
//log4j日志
private static final Logger log = LoggerFactory.getLogger(SpiderServiceImp.class);
//初始的URL入口
private static String url = "https://www.meijutt.com/1_______.html";
public String getPageNum() throws IOException {
String number ="";
try{
//使用JSOUP获取连接
Connection conn = Jsoup.connect(url).timeout(5000);
//设置请求头,模拟浏览器登陆,绕过简单的反爬虫机制
conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
conn.header("Accept-Encoding", "gzip, deflate, sdch");
conn.header("Accept-Language", "zh-CN,zh;q=0.8");
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
//从url中获取流并解析为Document对象
Document doc = conn.get();
//使用JSOUP的css选择器获取指定的Document页面元素,在这里我们选择获取页码
Elements select = doc.select(".page span");
//对获得的元素进行处理
number = select.get(0).text().substring(select.get(0).text().indexOf("/")+1);
}catch (Exception e){
e.printStackTrace();
}
return number;
}
public List<String> getUrl() throws IOException {
List<String> list = new ArrayList<>(3000);
try{
String number = getPageNum();
String url = "https://www.meijutt.com/";
for(int i = 1;i<=Integer.parseInt(number);i++){
list.add(url+i+"_______.html");
}
}catch (Exception e){
e.printStackTrace();
}
return list;
}
public List<String> getAllUrl(){
List<String> list = new ArrayList<>(5000);
try{
List<String> Allurl = getUrl();
for (String url:Allurl){
Document document = Jsoup.connect(url).timeout(5000).header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("Accept-Language", "zh-CN,zh;q=0.8")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
.get();
//获取当前页面的所有href标签,也就是当前列表页面的所有单独连接URL地址
Elements select = document.select(".cn_box2 .bor_img3_right a");
// String fileName="D:"+ File.separator+"allUrl.txt";
// File f = new File(fileName);
// OutputStream out = new FileOutputStream(f,true);//true表示追加模式,否则为覆盖
for(Element currentEle:select){
// String href = "https://www.meijutt.com"+currentEle.attr("href")+"\r\n";
log.info("https://www.meijutt.com"+currentEle.attr("href"));
// byte[] b = href.getBytes();
// out.write(b);
list.add("https://www.meijutt.com"+currentEle.attr("href"));
}
//out.close();
}
}catch(Exception e){
e.printStackTrace();
}
return list;
}
//通过@Async注解表明该方法是一个异步方法,如果注解在类级别,表明该类下所有方法都是异步方法,
// 而这里的方法自动被注入使用ThreadPoolTaskExecutor 作为 TaskExecutor
//@Async通过线程池异步获取,可以不带参,使用默认的线程池
@Async("asyncPromiseExecutor")
public void getAndInsertData(String currentUrl) throws IOException {
//List allUrl = getAllUrl();
//List allUrl = new ArrayList<>();
// BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(new File("C:/lastUrl.txt")),
// "UTF-8"));
// String line = null;
// while((line=br.readLine())!=null){
// log.info(line);
// allUrl.add(line);
// }
// br.close();
// String fileName="D:"+ File.separator+"download.txt";
// File f = new File(fileName);
//OutputStream out = new FileOutputStream(f,true);//true表示追加模式,否则为覆盖
//for(String currentUrl:allUrl){
try{
Document document = Jsoup.connect(currentUrl).timeout(5000).header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate, sdch")
.header("Accept-Language", "zh-CN,zh;q=0.8")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
.get();
Media m = new Media();
m.setMediaName(document.select(".info-title span").text()+document.select(".info-title h1").text());
// if(!"".equals(document.select(".info-title span").text()+document.select(".info-title h1").text())){
// int countByMediaName = mediaDAO.getCountByMediaName(document.select(".info-title span").text() + document.select(".info-title h1").text());
// if(countByMediaName>=1){
// return; //重复数据不爬取
// }
// }else {
// return;
// }
m.setPrimitiveName(document.select(".o_r_contact ul li").get(1).text().substring(document.select(".o_r_contact ul li").get(1).text().indexOf(":")+1));
m.setAlias(document.select(".o_r_contact ul li").get(2).text().substring(document.select(".o_r_contact ul li").get(2).text().indexOf(":")+1));
m.setScriptWriterName(document.select(".o_r_contact ul li").get(3).text().substring(document.select(".o_r_contact ul li").get(3).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(3).text().indexOf("更多")));
m.setDirectorName(document.select(".o_r_contact ul li").get(4).text().substring(document.select(".o_r_contact ul li").get(4).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(4).text().indexOf("更多")));
m.setActors(document.select(".o_r_contact ul li").get(5).text().substring(document.select(".o_r_contact ul li").get(5).text().indexOf(":")+1,document.select(".o_r_contact ul li").get(5).text().indexOf("更多")));
String Date = document.select(".o_r_contact ul li").get(6).text().substring(document.select(".o_r_contact ul li").get(6).text().indexOf(":") + 1);
// SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
// Date premiereDate = df.parse(Date);
m.setBigMediaKind(document.select(".o_r_contact ul li").get(8).text().substring(document.select(".o_r_contact ul li").get(8).text().indexOf(":")+1));
m.setLocation(document.select(".o_r_contact ul li").get(9).select("label").text().substring(document.select(".o_r_contact ul li").get(9).select("label").text().indexOf(":")+1));
m.setTvStation(document.select(".o_r_contact ul li").get(10).select("label").text().substring(document.select(".o_r_contact ul li").get(10).select("label").text().indexOf(":")+1));
String secondDate = document.select(".o_r_contact ul li").get(11).select("label").text().substring(document.select(".o_r_contact ul li").get(11).select("label").text().indexOf(":")+1);
// SimpleDateFormat dff = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
// Date timeSchadule = dff.parse(secondDate);
m.setTimeSchadule(secondDate);
m.setPremiereDate(Date);
m.setMediaKind( document.select(".o_r_contact ul li").get(11).select("span").text().substring(document.select(".o_r_contact ul li").get(11).select("span").text().indexOf(":")+1));
//log.info(document.select("#score-stars").toString());
//m.setGrade(document.select("#schedule-score").attr("style"));
String params = "id="+currentUrl.substring(currentUrl.lastIndexOf("meiju")+5,currentUrl.lastIndexOf("."))+"&action=newstarscorevideo";
//log.info(params);
Thread.sleep(1000);
String s = HttpRequest.sendGet("https://www.meijutt.com/inc/ajax.asp", params);
//log.info(s);
String substring = s.substring(s.indexOf("[") + 1, s.indexOf("]"));
String[] split = substring.split(",");
double v = Double.parseDouble(split[0]);
double v0 = Double.parseDouble(split[1]);
double v1 = Double.parseDouble(split[2]);
double v2 = Double.parseDouble(split[3]);
double v3 = Double.parseDouble(split[4]);
Double grade =(v*2+v0*4+v1*6+v2*8+v3*10)/(v+v0+v1+v2+v3);
DecimalFormat df3 = new DecimalFormat("#.00");
String str = df3.format(grade);
m.setGrade(str);
String imgUrl = document.select(".o_big_img_bg_b img").attr("src");
String imgName = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date())+String.valueOf(new Random().nextInt(10000));
DownloadUtil.downloadImage(imgUrl,imgName);
m.setImage(imgName);
log.info(m.toString());
//mediaDAO.insert(m);
//已经插入的url写入文件以下次断点续爬
// byte[] b = currentUrl.getBytes();
// out.write(b);
Thread.sleep(100);
//Integer id = m.getId();
//m1.setUrlName(document.select(".down_list").select(".max-height").select("li"));
try{
Elements li = document.select(".down_list").get(0).select("ul li");
if(li.size()!=0){
for(int i=0;i<li.size();i++){
Thread.sleep(100);
Element element = li.get(i);
//log.info(element.toString());
LinkMedia m1 = new LinkMedia();
m1.setUrlName(element.select(".down_part_name").select("a").text());
m1.setSize(element.select("em").text());
//m1.setLinkId(id);
m1.setUrlAddress(element.select(".down_part_name").select("a").attr("href").replaceAll("请输入ED2K://开头的","").replaceAll("地址",""));
//log.info( element.select("em").text());
// log.info(m1.toString());
//linkMediaDAO.insert(m1);
log.info(m1.toString());
}
}
}catch (Exception e){
e.printStackTrace();
log.info(currentUrl);
return;
}
//log.info(li.toString());
//log.info(Integer.valueOf(li.size()).toString());
}catch (Exception e){
e.printStackTrace();
log.info(currentUrl);
}
//
//}
//out.close();
}
public static void main(String[] args){
SpiderServiceImp sp =new SpiderServiceImp();
List<String> allList = sp.getAllUrl();
allList.forEach(i-> {
try {
sp.getAndInsertData(i);
} catch (IOException e) {
e.printStackTrace();
return;
}
});
}
}
import java.io.Serializable;
import java.util.Date;
public class Media implements Serializable {
private Integer id;
private String mediaName;
private String primitiveName;
private String alias;
private String scriptWriterName;
private String directorName;
private String actors;
private String premiereDate;
private String bigMediaKind;
private String mediaKind;
private String location;
private String tvStation;
private String timeSchadule;
private String grade;
private String image;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getMediaName() {
return mediaName;
}
public void setMediaName(String mediaName) {
this.mediaName = mediaName == null ? null : mediaName.trim();
}
public String getPrimitiveName() {
return primitiveName;
}
public void setPrimitiveName(String primitiveName) {
this.primitiveName = primitiveName == null ? null : primitiveName.trim();
}
public String getAlias() {
return alias;
}
public void setAlias(String alias) {
this.alias = alias == null ? null : alias.trim();
}
public String getScriptWriterName() {
return scriptWriterName;
}
public void setScriptWriterName(String scriptWriterName) {
this.scriptWriterName = scriptWriterName == null ? null : scriptWriterName.trim();
}
public String getDirectorName() {
return directorName;
}
public void setDirectorName(String directorName) {
this.directorName = directorName == null ? null : directorName.trim();
}
public String getActors() {
return actors;
}
public void setActors(String actors) {
this.actors = actors == null ? null : actors.trim();
}
public String getBigMediaKind() {
return bigMediaKind;
}
public void setBigMediaKind(String bigMediaKind) {
this.bigMediaKind = bigMediaKind == null ? null : bigMediaKind.trim();
}
public String getMediaKind() {
return mediaKind;
}
public void setMediaKind(String mediaKind) {
this.mediaKind = mediaKind == null ? null : mediaKind.trim();
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location == null ? null : location.trim();
}
public String getTvStation() {
return tvStation;
}
public void setTvStation(String tvStation) {
this.tvStation = tvStation == null ? null : tvStation.trim();
}
public String getGrade() {
return grade;
}
public void setGrade(String grade) {
this.grade = grade == null ? null : grade.trim();
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image == null ? null : image.trim();
}
public String getPremiereDate() {
return premiereDate;
}
public void setPremiereDate(String premiereDate) {
this.premiereDate = premiereDate;
}
public String getTimeSchadule() {
return timeSchadule;
}
public void setTimeSchadule(String timeSchadule) {
this.timeSchadule = timeSchadule;
}
}
public class LinkMedia {
private Integer id;
private Integer linkId;
private String urlName;
private String urlAddress;
private String size;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getLinkId() {
return linkId;
}
public void setLinkId(Integer linkId) {
this.linkId = linkId;
}
public String getUrlName() {
return urlName;
}
public void setUrlName(String urlName) {
this.urlName = urlName == null ? null : urlName.trim();
}
public String getUrlAddress() {
return urlAddress;
}
public void setUrlAddress(String urlAddress) {
this.urlAddress = urlAddress == null ? null : urlAddress.trim();
}
public String getSize() {
return size;
}
public void setSize(String size) {
this.size = size;
}
@Override
public String toString() {
return "LinkMedia{" +
"id=" + id +
", linkId=" + linkId +
", urlName='" + urlName + '\'' +
", urlAddress='" + urlAddress + '\'' +
", size='" + size + '\'' +
'}';
}
}
// An highlighted block
/**
* @author sharkshen
* @data 2019/3/24 0:37
* @Useage
*/
public class DownloadUtil {
public static void downloadImage(String Imageurl,String filename) throws IOException {
// System.getProperties().setProperty("http.proxyHost", "IP");//设置代理
// System.getProperties().setProperty("http.proxyPort", "Port");
URL url = new URL(Imageurl);
//打开网络输入流
DataInputStream dis = new DataInputStream(url.openStream());
File f = new File("D://tmp");
if(!f.exists()){
f.mkdirs();
}
String newImageName="D://tmp//"+filename+".jpg";
//建立一个新的文件
FileOutputStream fos = new FileOutputStream(new File(newImageName));
byte[] buffer = new byte[1024];
int length;
//开始填充数据
while((length = dis.read(buffer))>0){
fos.write(buffer,0,length);
}
dis.close();
fos.close();
}
}



第一次在CSDN上写博客,写的很粗糙,献丑了
源码项目地址
https://github.com/linkshark/LinkCloudDisk