hadoop完全分布式环境搭建,整合zookeeper,hbase,spark,hive,hue
前期准备工作
1、由于测试环境的所有服务器只在内网访问,所以全部关闭防火墙,省去配置访问规则时间。
service iptables stop
2、集群中包括4个节点:1个master,3个salve,所以节点均安装好jdk,节点之间局域网连接,可以相互ping通。节点IP地址分布如下:
IP 机器名
192.168.2.221 dhadoop01(master)
192.168.2.222 dhadoop01(slave1)
192.168.2.223 dhadoop01(slave2)
192.168.2.224 dhadoop01(slave3)
将以上的ip:主机名映射关系都添加至每台服务器的/etc/hosts

3、下载所需的软件包
hadoop-2.6.0.tar.gz
spark-1.6.2-bin-hadoop2.6.tgz
scala-2.11.8.tgz
zookeeper-3.4.6.tar.gz
hbase-1.2.5-bin.tar.gz
apache-hive-1.2.1-bin.tar.gz
livy-server-0.3.0.zip
hue-3.12.0.tgz
4、每台服务器上都创建hadoop组和hadoop用户
创建hadoop用户组:
groupadd hadoop
创建hadoop用户:
useradd –g hadoop hadoop
为hadoop用户添加密码:
passwd hadoop
使得hadoop用户获得sudo权限。
vi /etc/sudoers
我们这里设置hadoop的密码都是hadoop

编辑好,退出时,wq!(加叹号)
一、hadoop安装
1、切换至hadoop用户
将上面的安装安装包都上传到master主机的hadoop用户目录/home/hadoop上,并解压

mv hadoop hadoop-2.6.0 hadoop
2、配置环境变量
sudo vi /etc/profile
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=...:$HAOOP_HOME/bin
source /etc/profile使配置生效
3、ssh无验证登录配置
在master进行以下操作
ssh-keygen -t rsa -P ''
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600~/.ssh/authorized_keys
用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容
vi /etc/ssh/sshd_config

service sshd restart
切换为hadoop用户
操作以上步骤,在其他3台节点服务器做相同的操作。
使用scp ~/.ssh/id_rsa.pub hadoop@hostname:~/将公钥复制到其他机器
在其他机器cat ~/id_rsa.pub>> ~/.ssh/authorized_keys将公钥添加到授权密钥文件
复制完删除~/id_rsa.pub
四台机器都必须完成这些操作,一台完成后再配置另一台,最后用ssh测试每台机是不是都可以免密码互相登录
4、开始安装配置hadoop集群
先在master机器上安装配置,作为namenode节点,再复制到其他三台slave节点上
进入hadoop安装目录
cd /home/hadoop/hadoop
新建目录,tmp,hdfs/data,hdfs/name
mkdir tmp
mkdir -p hdfs/data
mkdir -p hdfs/name
配置以下hadoop文件
/home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
/home/hadoop/hadoop/etc/hadoop/yarn-env.sh
/home/hadoop/hadoop/etc/hadoop/slaves
/home/hadoop/hadoop/etc/hadoop/core-site.xml
/home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
/home/hadoop/hadoop/etc/hadoop/mapred-site.xml
/home/hadoop/hadoop/etc/hadoop/yarn-site.xml
cd /home/hadoop/hadoop/etc/hadoop/ 进入配置文件目录,由于时间关系,而且是测试环境,只修改最基本的配置,优化相关的配置,后续再修改
hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk7
保存退出!
yarn-env.sh
vi yarn-env.sh
export JAVA_HOME=/usr/local/java/jdk7
slaves,配置datanode节点地址
vi slaves
dhadoop02
dhadoop03
dhadoop04
core-site.xml
fs.default.name
hdfs://dhadoop01:9000
true
hadoop.tmp.dir
/home/hadoop/hadoop/tmp/hadoop-${user.name}
//这里配置允许代理访问用户,后面hue配置需要
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
hdfs-site.xml
dfs.namenode.secondary.http-address
dhadoop01:9001
dfs.name.dir
/home/hadoop/hadoop/hdfs/name
dfs.data.dir
/home/hadoop/hadoop/hdfs/data
dfs.replication
4
dfs.permissions
false
dfs.datanode.max.xcievers
4096
dfs.client.block.write.replace-datanode-on-failure.enable
true
dfs.client.block.write.replace-datanode-on-failure.policy
NEVER
//hue配置需要
dfs.webhdfs.enabled
true
mapred-site.xml
mapreduce.framework.name
yarn
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8099
yarn.resourcemanager.scheduler.address
dhadoop01:8030
yarn.resourcemanager.address
dhadoop01:8032
yarn.resourcemanager.resource-tracker.address
dhadoop01:8031
yarn.resourcemanager.admin.address
dhadoop01:8033
将master上配置好的hadoop scp复制到其他slave节点节约时间
scp -r hadoop hadoop@主机名:/home/hadoop/
格式化namenode
hdfs namenode –format
或者
hadoop namenode –format
注意命令中的-是中文字符,执行过程中输入的英文字符,导致一直格式化失败
启动hadoop集群并验证是否成功
cd /home/hadoop/hadoop/sbin
./start-all.sh
master主机 jps一下

其他slave

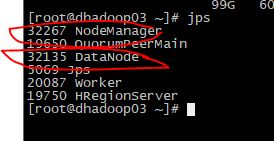

浏览器访问http://192.168.2.221:8099/cluster进入hadoop web后台
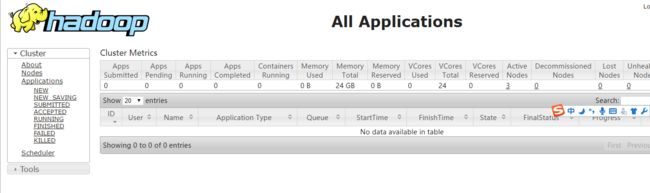
hadoop集群部署成功
二、zookeeper集群安装
在master,slave1,slave2上安装
hadoop用户进入master
cd /home/hadoop
tar -zxvf zookeeper-3.4.6.tar.gz
sudo vi /etc/profile
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.6
export PATH=....:$ZOOKEEPER_HOME/bin
:wq
cd zookeeper-3.4.6/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
# The number of milliseconds of each tick
tickTime=20000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/zookeeper-3.4.6/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=dhadoop01:2888:3888
server.2=dhadoop02:2888:3888
server.3=dhadoop03:2888:3888
保存退出
cd /home/hadoop/zookeeper-3.4.6/data
修改myid为1
保存退出
cd /home/hadoop
scp -r zookeeper-3.4.6 hadoop@dhadoop02:/home/hadoop
进入dhadoop02
cd /home/hadoop/zookeeper-3.4.6/data
修改myid为2
scp -r zookeeper-3.4.6 hadoop@dhadoop03:/home/hadoop
进入dhadoop03
cd /home/hadoop/zookeeper-3.4.6/data
修改myid为3
dhadoop01(master)>dhadoop02(slave1)>dhadoop03(slave2)
依次执行
zkServer.sh start
验证

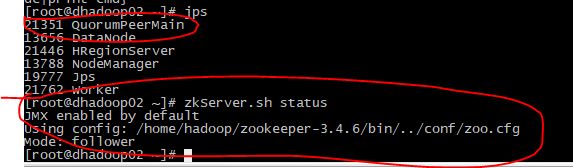

安装部署成功
三、hbase完全分布式集群安装
集群机器:
dhadoop01(namenode)
dhadoop02(datanode)
dhadoop03(datanode)
hadoop用户进入dhadoop01
cd /home/hadoop
tar -zxvf hbase-1.2.5-bin.tar.gz
mv hbase-1.2.5-bin hbase
sudo vi /etc/profile
export HBASE_HOME=/home/hadoop/hbase
export PATH=...:$HBASE_HOME/bin
:wq
配置hbase文件
cd /home/hadoop/hbase/conf
hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk7
export HBASE_LOG_DIR=/home/hadoop/hbase/logs
export HBASE_MANAGES_ZK=false//使用自己安装的zookeeper,需要配置为false,默认为true使用自带的zookeeper
hbase-site.xml
hbase.rootdir
hdfs://dhadoop01:9000/hbase
hbase.cluster.distributed
true
hbase.master
hdfs://dhadoop01:60000
hbase.zookeeper.quorum
dhadoop01,dhadoop02,dhadoop03
regionservers
dhadoop01
dhadoop02
dhadoop03
scp -r hadoop /home/hadoop/hbase hadoop@dhadoop02:/home/hadoop
scp -r hadoop /home/hadoop/hbase hadoop@dhadoop03:/home/hadoop
/home/hadoop/hbase/bin/start-hbase.sh启动hbase集群
验证
dhadoop01
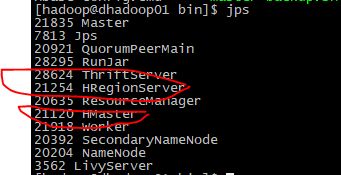
dhadoop02

dhadoop03
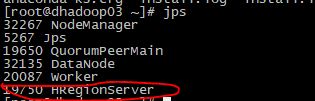
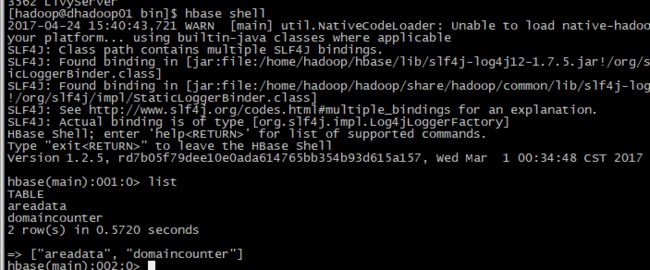
进入hbase shell
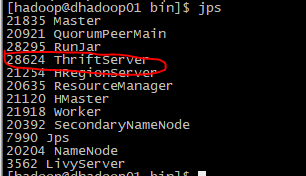
/home/hadoop/hbase/bin/hbase-deamon.sh start thrift 启动thrift服务,hue需要
特别说明:hadoop重新格式化后,原来的表不见了,重新建表的时候一直出现表已存在的错误,但是表已经删除了的,最后发现是原来的表信息被zookeeper保存,所以得进入zookeeper控制台将表信息删除
zkCli.sh

四、spark分布式集群安装
集群机器:
dhadoop01(master)
dhadoop02(slave1)
dhadoop03 (slave2)
dhadoop04(slave3)
cd /home/hadoop
tar -zxvf scala-2.11.8.tgz
mv scala-2.11.8 scala
tar -zxvf spark-1.6.2-bin-hadoop2.6.tgz
mv spark-1.6.2-bin-hadoop2.6 spark
sudo vi /etc/profile
export SCALA_HOME=/home/hadoop/scala
export SPARK_HOME=/home/hadoop/sparkexport PATH=...:$SCALA_HOME/bin:$SPARK_HOME/bin
:wq
source /etc/profile
cd /home/hadoop/spark/conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
spark-env.sh
export SCALA_HOME=/home/hadoop/scala
export JAVA_HOME=/usr/local/java/jdk7
export SPARK_MASTER_IP=192.168.2.221
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoopslaves
dhadoop01
dhadoop02
dhadoop03
dhadoop04将spark目录scp复制到其他slave节点
scp -r hadoop /home/hadoop/spark hadoop@节点名:/home/hadoop/
/home/hadoop/spark/sbin/start-all.sh 启动spark集群
验证
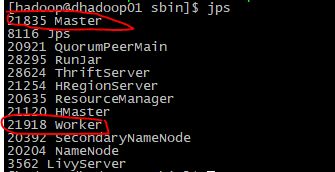
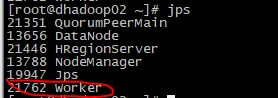



安装 livy-server,livy-server是spark的一个restful服务插件,为spark提供restful接口,需手动安装,后面hue配置也需要用到
unzip livy-server-0.3.0.zip
cd /home/hadoop/livy-server-0.3.0/conf
vi livy.conf
//默认使用hiveContext
livy.repl.enableHiveContext = true
//开启用户代理
livy.impersonation.enabled = true
//设置session空闲过期时间
livy.server.session.timeout = 1hvi livy-env.sh
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop/conf
export SPARK_HOME=/home/hadoop/sparkvi spark-blacklist.conf
注释spark.master
# spark.mastercd ../
mkdir logs
cd bin
nohup sudo -u hadoop ./livy-server >/dev/null 2>&1 & //启动livy server

spark-submit提交任务到yarn


五、hive安装
1) 在mysql里创建hive用户,并赋予其足够权限
[root@node01 mysql]# mysql -u root -p
Enter password:
mysql> create user 'hive' identified by 'hive';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to 'hive' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
cd /home/hadoop
tar -zxvf apache-hive-1.2.1-bin.tar.gz
mv apache-hive-1.2.1-bin hive
sudo vi /etc/profile
export HIVE_HOME=/home/hadoop/hive
export PATH=...:$HIVE_HOME/bin
:wq
cd /home/hadoop/hive/
mkdir iotmp
cd conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
exportHIVE_HOME=/home/hadoop/hive
export PATH=$HIVE_HOME/bin:$PATH
export HIVE_AUX_JARS_PATH=$HIVE_HOME/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HADOOP_USER_CLASSPATH_FIRST=true
cp hive-default.xml.template hive-site.xml
vi hive-site.xml
修改以下几个地方
将所有 ${system:Java.io.tmpdir}替换成/home/hadoop/hive/iotmp
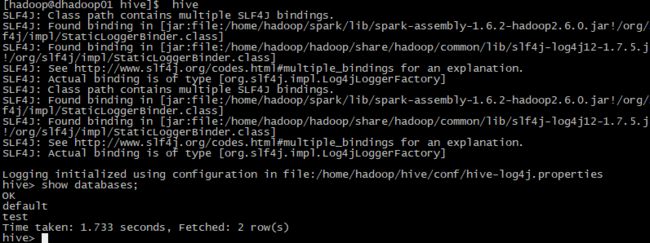
nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 &
//启动hiveserver2,hue需要
六、hue安装
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以使用wen ui控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,操作hbase表,执行hive 的sql处理数据,运行MapReduce Job等等。官网给出的特性,通过翻译原文简单了解一下Hue所支持的功能特性集合:
- 默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
- 基于文件浏览器(File Browser)访问HDFS
- 基于Hive编辑器来开发和运行Hive查询
- 支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
- 支持基于Impala的应用进行交互式查询
- 支持Spark编辑器和仪表板(Dashboard)
- 支持Pig编辑器,并能够提交脚本任务
- 支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
- 支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
- 支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
- 支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
- 支持Job设计器,能够创建MapReduce/Streaming/Java Job
- 支持Sqoop 2编辑器和仪表板(Dashboard)
- 支持ZooKeeper浏览器和编辑器
- 支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
下面,通过实际安装来验证Hue的一些功能,此次主要配置hadoop yarn,hdfs,hive,hbase,spark,zookeeper使用
到hue官网下载hue安装包,放到dhadoop02的/home/hadoop上,官网建议放在master主机上,由于上面已经安装太多东西有点重,所以放在dhadoop02子节点机器上。
yum install 安装hue依赖的组件(以下是centos系统所需的,不同系统部分不同,具体看hue github介绍https://github.com/cloudera/hue)
- ant
- asciidoc
- cyrus-sasl-devel
- cyrus-sasl-gssapi
- cyrus-sasl-plain
- gcc
- gcc-c++
- krb5-devel
- libffi-devel
- libtidy (for unit tests only)
- libxml2-devel
- libxslt-devel
- make
- mvn (from
apache-mavenpackage or maven3 tarball) - mysql
- mysql-devel
- openldap-devel
- python-devel
- sqlite-devel
- openssl-devel (for version 7+)
- gmp-devel
tar -zxvf hue-3.12.0.tgz
cd hue-3.12.0
make apps
cd /home/hadoop/hue-3.12.0/desktop/conf
vi hue.ini
[desktop]
# Set this to a random string, the longer the better.
# This is used for secure hashing in the session store.
secret_key=
# Execute this script to produce the Django secret key. This will be used when
# 'secret_key' is not set.
## secret_key_script=
# Webserver listens on this address and port
http_host=192.168.2.222
http_port=8888
# Time zone name
time_zone=Asia/Shanghai
# Webserver runs as this user
server_user=hadoop
server_group=hadoop
# This should be the Hue admin and proxy user
default_user=hadoop
# This should be the hadoop cluster admin
default_hdfs_superuser=hadoop
=================================================
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://dhadoop01:9000
# NameNode logical name.
## logical_name=
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://192.168.2.221:50070/webhdfs/v1
# Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True
# Directory of the Hadoop configuration
hadoop_conf_dir=/home/hadoop/hadoop/etc/hadoop
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=dhadoop01
# The port where the ResourceManager IPC listens on
#resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://dhadoop01:8099
# URL of the ProxyServer API
proxy_api_url=http://dhadoop01:8099
# URL of the HistoryServer API
history_server_api_url=http://dhadoop01:19888
=================================================
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=dhadoop01
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10001
=================================================
[spark]
# Host address of the Livy Server.
livy_server_host=dhadoop01
# Port of the Livy Server.
livy_server_port=8999
=================================================
[hbase]
# Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
# Use full hostname with security.
# If using Kerberos we assume GSSAPI SASL, not PLAIN.
hbase_clusters=(Cluster|dhadoop01:9090)
# HBase configuration directory, where hbase-site.xml is located.
hbase_conf_dir=/home/hadoop/hbase/conf
=================================================
[zookeeper]
[[clusters]]
[[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
host_ports=dhadoop01:2181,dhadoop02:2181,dhadoop03:2181
对应配置项配置就行了
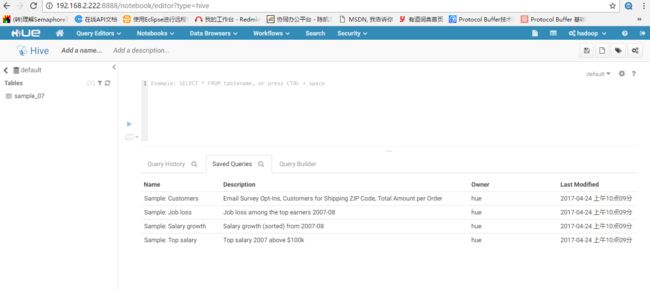
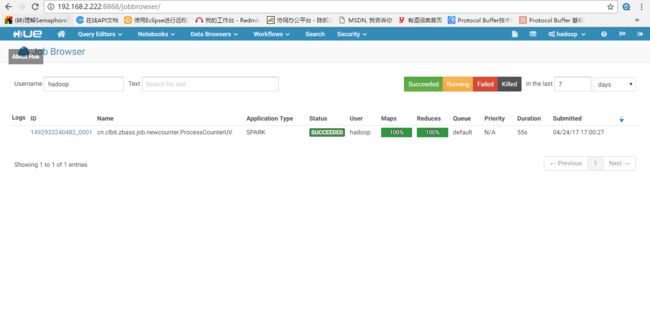
nohup /home/hadoop/hue-3.12.0/build/env/bin/supervisor & //启动hue



原著作权归作者所有,转载请注明出处