大数据-Hadoop集群搭建(配置免密登录及配置环境)
目录
安装Hadoop
集群布局
克隆
配置免密登录
集群配置
验证集群
总结
安装Hadoop
上传压缩包。
在hadoop用户下,新建一个apps目录,进入该目录。可以通过文件的属性中的安全选项卡找到完整路径,并复制,和安装jdk时一样,使用SecureCRT的sftp上传即可。
 文件路径
文件路径
解压在该目录下即可。
 解压
解压
可以看到hadoop里面的内容,在sbin目录下有一些脚本,以后会用到。
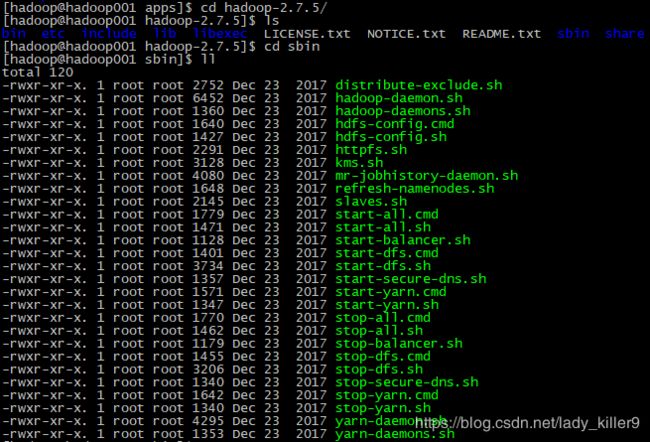 hadoop的内容
hadoop的内容
- vim ~/.bashrc
- 在最后面加入以下语句:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin - source ~/.bashrc(使新配置的环境变量生效)
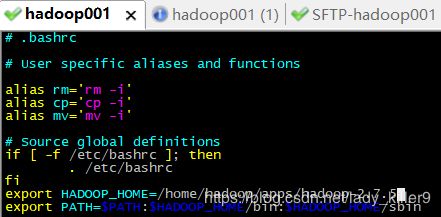 配置hadoop
配置hadoop
至此,母版虚拟机已经设置完毕,接下来将进行克隆与整体布局。
集群布局
| 虚拟机名 | h1 | h2 | h3 |
|---|---|---|---|
| HostName | hadoop1 | hadoop2 | hadoop3 |
| ip | 192.168.74.121 | 192.168.74.122 | 192.168.74.123 |
| NameNode | √ | × | × |
| SecondryNameNode | × | √ | × |
| ResourceManager | × | × | √ |
| DataNode | √ | √ | √ |
| NodeManager | √ | √ | √ |
克隆
运行内存有限,建议3~4台,这里克隆三台。关闭母版虚拟机,以第一台为例,母版虚拟机上右键,选择管理,然后选择克隆。
 克隆第一台
克隆第一台
依次克隆另外两台,分别命名为h2、h3。
网络连接
vi /etc/udev/rules.d/70-persistent-net.rules,以h1为例,将eth0所在行注释或删除,将eth1改为eth0,其他两台一样。
 h1修改前
h1修改前
 h1修改后
h1修改后
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0,将HWADDR和UUID所在行删除或注释掉,修改IPADDR。
 h1静态ip修改
h1静态ip修改
sudo vi /etc/sysconfig/network,修改hostname,SecureCRT下方右键,可以对多个会话一起发命令,比较方便,三台虚拟机一起修改。
 修改hostname
修改hostname
sudo vi /etc/hosts,修改主机映射,保存后,使用init 6命令重启网卡。
 标题更改主机映射
标题更改主机映射
也可以添加本机的主机映射,在SecureCRT和浏览器地址用主机名代替,更加方便。
 本机主机映射
本机主机映射
配置免密登录
为什么要配置免密登录?
 未配置免密登录前
未配置免密登录前
未配置免密登录前,在hadoop1登录hadoop2需要输入密码,这对以后的工作会产生很多麻烦。
在 hadoop 用户下,输入命令 ssh-keygen ,连按 3 次回车,之后你会发现,在/home/hadoop/.ssh 目录下生成了一对密钥。每台虚拟就都需要,使用发送所有对话框,输入一次就好,比较方便。
 生成密钥
生成密钥
再分别输入ssh-copy-id hadoop1、ssh-copy-id hadoop2、ssh-copy-id hadoop3。每次需要输入yes及密码。这样就会在每台虚拟机的.ssh/authorized_keys中存在三台虚拟机的密钥。
 复制密钥
复制密钥
 复制密钥成功
复制密钥成功
可以在任一台虚拟机,使用ssh 主机名的方式登录其他虚拟机,使用exit退出。
集群配置前先同步时间
- date(查看时间)
- sudo ntpdate ntp1.aliyun.com(与阿里云的同步)
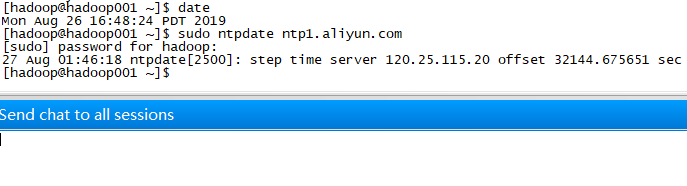 同步时间
同步时间
集群配置
需要配置的文件,如图中的画红勾的那些。你可以照着Hadoop官网所给提示来敲,也可以从我的百度网盘下载,直接上传覆盖(上传前记得修改文件为自己的路径、用户名等)。
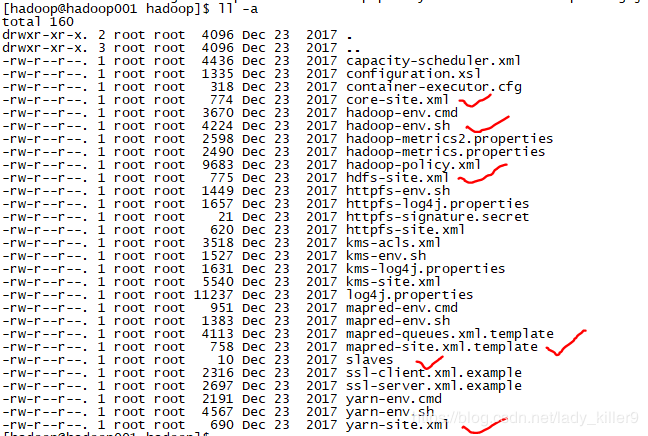 hadoop的配置文件
hadoop的配置文件
core-site.xml的配置
指定了工作目录等,读者根据自己的用户名等进行修改。
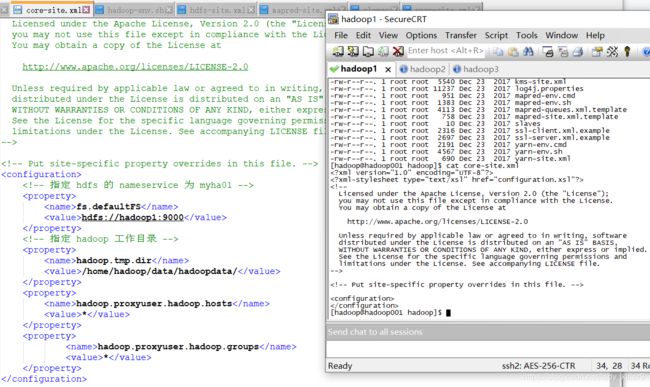 core-site.xml的配置
core-site.xml的配置
hadoop-env.sh的配置
指定了jdk路径,读者根据自己的进行修改。
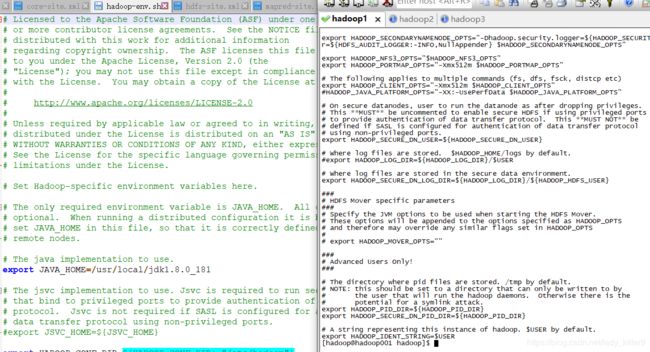 hadoop-env.sh的配置
hadoop-env.sh的配置
hdf-site.xml的配置
指令了一些数据目录等,读者根据自己的进行修改。
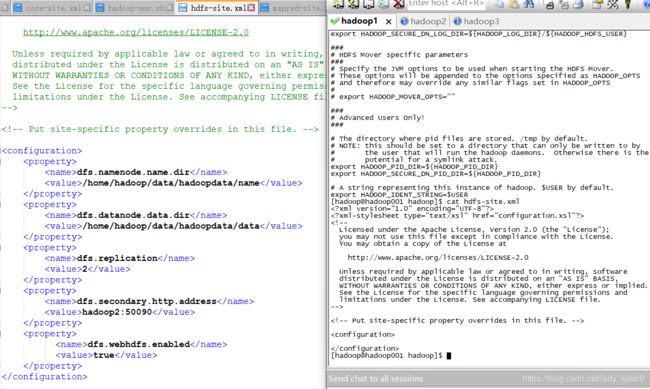 hdf-site.xml的配置
hdf-site.xml的配置
mapred-site.xml的配置
hadoop自带的是.template结尾的,如果你不是上传的我的文件,是自己在vi/vim编辑器下编辑的,记得改后缀。
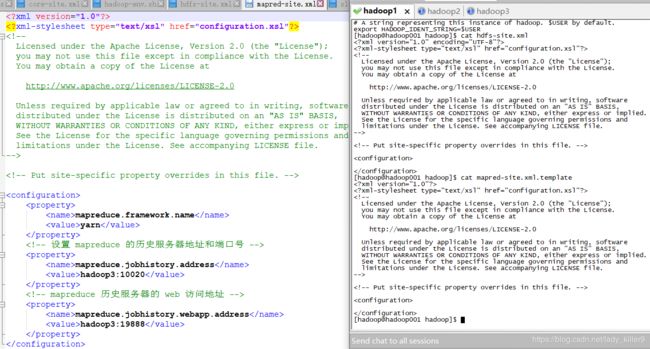 标题
标题
slaves的配置
填入主机名即可,读者根据自己的进行修改。
 slaves的配置
slaves的配置
yarn-site.xml的配置
添加了yarn结点的主机名等,读者根据自己的进行修改。
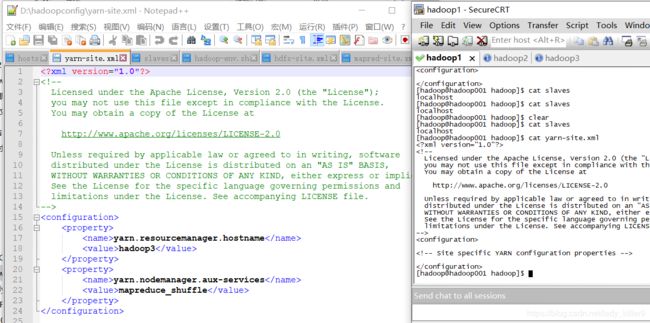 yarn-site.xml的配置
yarn-site.xml的配置
- cd ~/apps/hadoop-2.7.5/etc/hadoop/
- put D:\hadoopconfig\* (\*是上传所有文件,这样就会覆盖掉了)
使用hadoop namenode -format,初始化namenode。
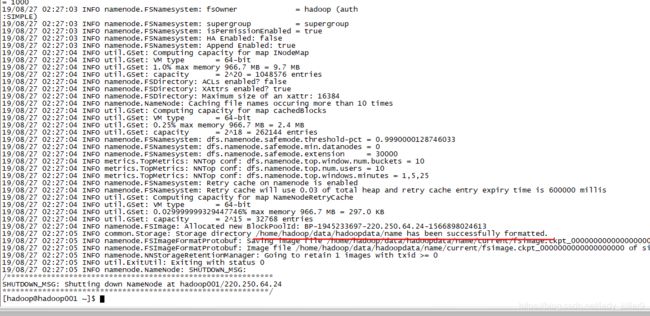 初始化
初始化
start-dfs.sh(任意结点启动dfs均可)、使用stop-dfs.sh关闭。
 启动dfs
启动dfs
start-yarn.sh(只能在YARN的主节点启动,否则ResourceManager进程无法启动,YARN主节点设置的为hadoop3 )、使用stop-yarn.sh关闭。
 启动yar成功
启动yar成功
验证集群
1、使用jps
dfs启动后
 dfs启动后的hadoop1
dfs启动后的hadoop1
 dfs启动后的hadoop2
dfs启动后的hadoop2
yarn启动后
 yarn启动后的h1
yarn启动后的h1
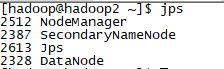 yarn启动后的h2
yarn启动后的h2
 yarn启动后的h3
yarn启动后的h3
可以看到,每台虚拟机作为什么结点,如同规划的一样。
2、web验证
可以在本机的hosts里面也添加映射,如同上篇文章的hadoop001一样,这样在SecureCRT以及浏览器地址栏用主机名代替ip即可,比较方便。输入hadoop1:50070,即可打开如下界面,可以看到激活了。
 namenode查看
namenode查看
输入hadoop3:8088即可查看到如下界面。
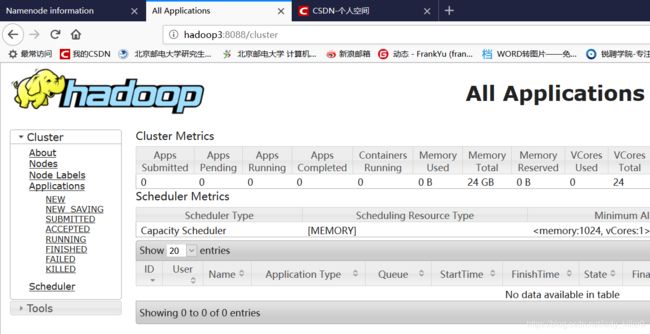 yarn结点查看
yarn结点查看
总结
今天主要学习了以下内容
安装hadoop并配置
克隆虚拟机,搭建集群
配置免密登录
配置集群
网盘链接:
链接:https://pan.baidu.com/s/1yIHOlRPpcGYkKTYM4-64bA
提取码:ims7
更多大数据知识请查看:大数据自学目录
有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!如有侵权,请及时联系。