redis可用性提升(哨兵sentinel)配置示例
redis提供了sentinel(哨兵)机制,通过sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决
每个sentinel会向其它sentinal、master、slave定时发送消息,以确认对方是否“活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的“主观认为宕机” Subjective Down,简称SDOWN)。
若“哨兵群”中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective Down,简称ODOWN),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
最小化的sentinel配置文件为:
1 port 7031 2 3 dir /opt/app/redis/redis-2.8.17/tmp 4 5 sentinel monitor mymaster 10.6.144.155 7030 1 6 sentinel down-after-milliseconds mymaster 5000 7 sentinel parallel-syncs mymaster 1 8 sentinel failover-timeout mymaster 15000
第1行,指定sentinel使用的端口,不能与redis-server运行实例的端口冲突
第3行,指定工作目录
第5行,显示监控master节点10.6.144.155,master节点使用端口7030,最后一个数字表示投票需要的"最少法定人数",比如有10个sentinal哨兵都在监控某一个master节点,如果需要至少6个哨兵发现master挂掉后,才认为master真正down掉,那么这里就配置为6,最小配置1台master,1台slave,在二个机器上都启动sentinal的情况下,哨兵数只有2个,如果一台机器物理挂掉,只剩一个sentinal能发现该问题,所以这里配置成1,至于mymaster只是一个名字,可以随便起,但要保证5-8行都使用同一个名字
第6行,表示如果5s内mymaster没响应,就认为SDOWN
第8行,表示如果15秒后,mysater仍没活过来,则启动failover,从剩下的slave中选一个升级为master
第7行,表示如果master重新选出来后,其它slave节点能同时并行从新master同步缓存的台数有多少个,显然该值越大,所有slave节点完成同步切换的整体速度越快,但如果此时正好有人在访问这些slave,可能造成读取失败,影响面会更广。最保定的设置为1,只同一时间,只能有一台干这件事,这样其它slave还能继续服务,但是所有slave全部完成缓存更新同步的进程将变慢。
另:一个sentinal可同时监控多个master,只要把5-8行重复多段,加以修改即可。
具体使用步骤:(约定7030是redis-server端口,7031是redis-sentinel端口,且master、slave上的redis-server均已正常启动)
1、先在redis根目录下创建conf子目录,新建配置文件sentinel.conf,内容参考前面的内容(master和slave上都做相同的配置)
2、./redis-sentinel ../conf/sentinel.conf 即可(master和slave上都启用sentinel,即最终有二个哨兵)
3、./redis-cli -p 7031 sentinel masters 可通过该命令查看当前的master节点情况(注,这里一定要带sentinel的端口)
4、在master上,./redis-cli -p 7030 shutdown ,手动把master停掉,观察sentinel的输出
[17569] 21 Nov 11:06:56.277 # +odown master mymaster 10.6.144.155 7030 #quorum 1/1
[17569] 21 Nov 11:06:56.277 # Next failover delay: I will not start a failover before Fri Nov 21 11:07:26 2014
[17569] 21 Nov 11:06:57.389 # +config-update-from sentinel 10.6.144.156:7031 10.6.144.156 7031 @ mymaster 10.6.144.155 7030
[17569] 21 Nov 11:06:57.389 # +switch-master mymaster 10.6.144.155 7030 10.6.144.156 7030
[17569] 21 Nov 11:06:57.389 * +slave slave 10.6.53.131:7030 10.6.53.131 7030 @ mymaster 10.6.144.156 7030
从红线部分可以看出,master发生了迁移,等刚才停掉的master再重启后,可以观察到它将被当作slave加入,类似以下输出:
[36444] 21 Nov 11:11:14.540 * +convert-to-slave slave 10.6.144.155:7030 10.6.144.155 7030 @ mymaster 10.6.144.156 7030
注意事项:发生master迁移后,如果遇到运维需要,想重启所有redis,必须最先重启“新的”master节点,否则sentinel会一直找不到master。
最后,如果想停止sentinel,可输入命令./redis-cli -p 7031 shutdown
客户端的使用:
一、Jedis
1 @Test 2 public void testJedis() throws InterruptedException { 3 4 Setsentinels = new HashSet (); 5 sentinels.add("10.6.144.155:7031"); 6 sentinels.add("10.6.144.156:7031"); 7 8 JedisSentinelPool sentinelPool = new JedisSentinelPool("mymaster", 9 sentinels); 10 11 Jedis jedis = sentinelPool.getResource(); 12 13 System.out.println("current Host:" 14 + sentinelPool.getCurrentHostMaster()); 15 16 String key = "a"; 17 18 String cacheData = jedis.get(key); 19 20 if (cacheData == null) { 21 jedis.del(key); 22 } 23 24 jedis.set(key, "aaa");// 写入 25 26 System.out.println(jedis.get(key));// 读取 27 28 System.out.println("current Host:" 29 + sentinelPool.getCurrentHostMaster());// down掉master,观察slave是否被提升为master 30 31 jedis.set(key, "bbb");// 测试新master的写入 32 33 System.out.println(jedis.get(key));// 观察读取是否正常 34 35 sentinelPool.close(); 36 jedis.close(); 37 38 }
4-6行是关键,这里指定了sentinel节点信息。但这段代码在运行时发现一个问题:对于1主1从的最小化配置,如果连续发生两次写操作,第1次set成功后,如果断点停在这里,down掉master,这时剩下的slave会提升为master,但是第2次set时,会抛异常,类似:连接已断开。(注:通过Spring-Data-Redis整合Jedis与redis时,利用RedisTemplate调用不会有这个问题,看来Spring-Data-Redis针对这个问题做过优化,所以建议正式项目中,通过Spring-Data-Redis整合Redis来调用相关功能,而不是自己直接引用Jedis的jar包来使用)
二、Redisson
同样做类似的测试,二次写,二次读,如果第1次写后,人工down掉master,剩下的slave会提升成master,第二次写ok,但此时redis节点中,只剩master,没有slave了,从测试结果上看,第二次get还是尝试去找slave节点,但是此时已经不存在了,所以一直在等候,导致后面的的处理被阻塞。
这不是redis的问题,而是Redisson客户端设计不够智能。
鉴于这种现状,如果要使用Redisson,最好做成1主2从的部署结构:(sentinel.conf中的“法定人数”,建议调整成2)
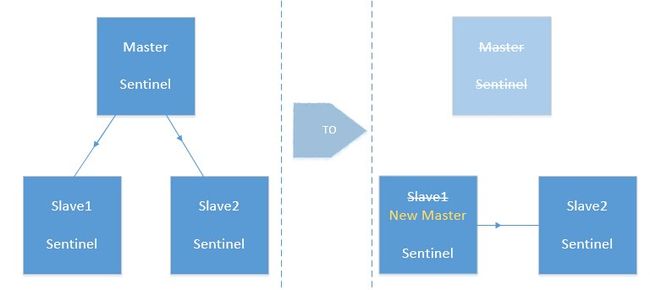
这样的好处是,1个master挂掉后,剩下的2台slave中,会有1台提升为master,整体仍然保证有1个master和1个slave,读写均不受影响。
关于Sentinel的更多细节,可参考官网文档:http://www.redis.io/topics/sentinel
出处: http://yjmyzz.cnblogs.com