【Spark内核源码】SparkContext一些方法的解读
目录
创建SchedulerBackend的TaskScheduler方法
设置并启动事件总线
发布环境更新的方法
发布应用程序系统的方法
在【Spark内核源码】SparkContext中的组件和初始化 已经介绍了Spark初始化时是如何执行的,都创建了哪些组件。这些组件具体技术细节后面会慢慢的说,而针对SparkContext,里面还有一些方法,值得大家品一品。
创建SchedulerBackend的TaskScheduler方法
在SparkContext初始化中有这么一段代码执行了SparkContext.createTaskScheduler方法,用于创建SchedulerBackend和TaskScheduler。TaskScheduler是Spark的重要组成部分,其进行两级调度,第一级调度是负责向集群管理器发送请求给应用程序分配并运行Executor,第二级调度是给具体任务分配Executor并执行相关任务。

createTaskScheduler方法有点长,需要慢慢分析。
首先createTaskScheduler方法需要传入三个参数,SparkContext,master和deployMode,从调用createTaskScheduler方法时可以看出,SparkContext就是使用的本身,"sc = this",master是配置文件中key=“spark.master”所对应的值,deployMode是配置文件中key=“spark.submit.deployMode”所对应的值。返回值类型是Tuple,第一个元素是SchedulerBackend,第二个元素是TaskScheduler。

接着就是对master进行模式匹配
如果master与local匹配:
分别创建TaskSchedulerImpl和LocalSchedulerBackend,然后初始化TaskSchedulerImpl,最后返回SchedulerBackend和TaskScheduler。其实后面的几个模式匹配都是这个模式,只是根据匹配的不同内容做了前置调整。
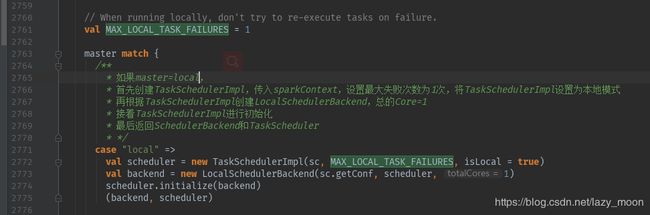
这里很值得注意的就是scheduler.initialize(backend)方法,initialize的主要作用就是依据不同的优先策略建立调度池,Spark中的调度模式主要有两种:FIFO和FAIR。通过配置文件的spark.scheduler.mode进行设置,默认情况下Spark的调度模式是FIFO(先进先出),谁先提交谁先执行,后面的任务需要等待前面的任务执行。而FAIR(公平调度)模式支持在调度池中为任务进行分组,不同的调度池权重不同,任务可以按照权重来决定执行顺序。代码如下:

如果master与LOCAL_N_REGEX(threads)匹配:
表示通过"local[]"这是使用本地的线程数量,如果“[]”中是“*”就采用java虚拟机可用的处理器数量,如果是具体数字就使用具体个数的处理器个数。然后和local模式一样,分别创建TaskSchedulerImpl和LocalSchedulerBackend,然后初始化TaskSchedulerImpl,最后返回SchedulerBackend和TaskScheduler。
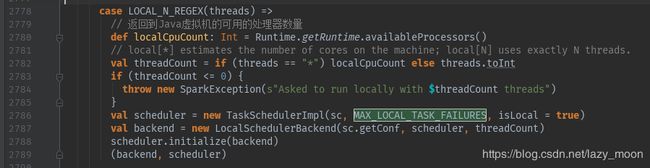
如果master与LOCAL_N_FAILURES_REGEX(threads)匹配:
与LOCAL_N_REGEX(threads)类似,只不过增加了最大失败次数的设置

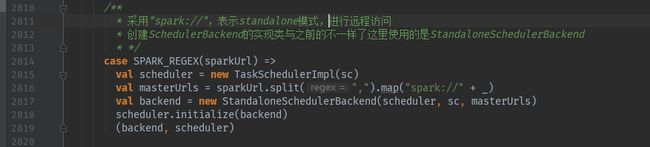
如果master与SPARK_REGEX(threads)匹配:
采用"spark://",表示standalone模式,进行远程访问,创建SchedulerBackend的实现类与之前的不一样了这里使用的是StandaloneSchedulerBackend。
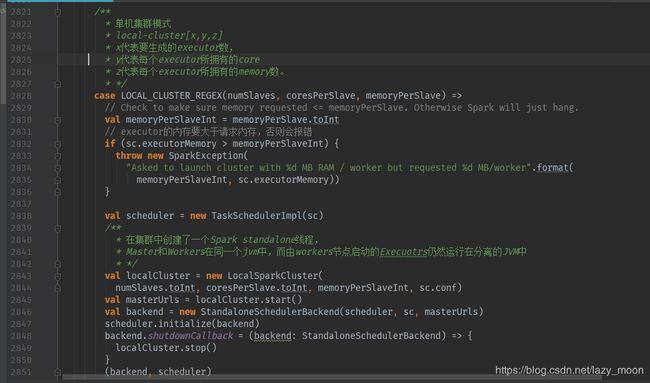
如果master与LOCAL_CLUSTER_REGEX(threads)匹配:
这是单机集群模式,通过“local-cluster[x,y,z]”进行设置,x代表executor数量,y代表executor的core的个数,z代表executor拥有的memory,这个memory值不能大于sparkContext设置的executorMemory的值,否则会报错。
如果master与masterURL匹配:
这里就指的是yarn模式,yarn-cluster还是yarn-client模式,都是走的这里。

设置并启动事件总线

设置并启动时间总线是在SparkContext初始化接近尾声时进行的,该方法通过配置文件中key=“spark.extraListeners”获取所有额外的监听器的类名,然后通过反射机制,显示加载这些监听器,并把每个监听器加载到事件总线中,最后启动事件总线ListenerBus。

发布环境更新的方法
这个方法张这样:
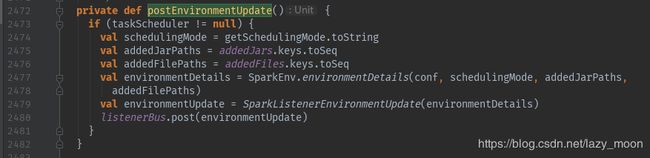
根据当前调度模式和增加的依赖、文件的路径,制定环境更新详情,并通过事件总线发送跟新信息。发布环境更新的方法,在SparkContext中出现了三次,分别在SparkContext初始化接近尾声时、增加依赖后(addJar方法)和增加文件后(addFile方法)执行的,也就是说,系统中的资源和依赖发生变化时,都会通过事件总线将资源和依赖的变化告诉各个组件。
发布应用程序系统的方法

事件总线发布Spark应用程序启动事件,SparkListenerApplicationStart继承自SparkListenerEvent,是Spark应用程序启动时的时间,需要设置应用程序的名称,ID,开始时间,用户信息,当且应用程序尝试的ID以及驱动程序日志的url。因为applicationId和applicationAttempId都是通过taskScheduler生成的,因此,postAppliactionStart方法一定是在创建TaskScheduler之后执行的。postAppliactionStart方法确定的执行位置是在SparkContext初始化时postEnvironmentUpdate方法之后执行。启动总线、发布更新事件、发布启动应用程序时间按照顺序依次执行。

还有一些组件启动的详细过程涉及到对应的组件程序,需要对这些组件进行深入的研究。后面会一点一点研究他们。前面的路还很长,这只是一个开始。