Apriori算法
学习Apriori算法首先要了解几个概念:项集、支持度、置信度、最小支持度、最小置信度、频繁项集。
项集:顾名思义,即项的集合。eg:牛奶、面包组成一个集合{牛奶、面包},其中牛奶和面包为项,{牛奶、面包}为项集,称之为2项集。(说白了,其实就是集合)
支持度:项集A、B同时发生的概率称之为关联规则的支持度。
置信度:项集A发生的情况下,则项集B发生的概率为关联规则的置信度。
支持度与置信度的概念有些抽象,具体可以看下面的例子:
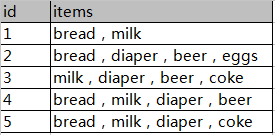
如图数据为顾客购物情况,每一个id对应的items都是一个项集,现在需要对{milk,diaper}与{beer}关联性进行研究,计算支持度与置信度。
计算如下:
计算支持度:计算{milk,diaper}{beer}同时发生的概率就相当于计算{milk,diaper,beer}出现的次数所占数据条的比重,即2/5.
计算置信度:计算{milk,diaper}发生的情况下,则{beer}发生的概率就相当于计算{milk,diaper,beer}出现的次数所占{milk,diaper}发生次数的比重,即2/3.
最小支持度:最小支持度就是人为按照实际意义规定的阈值,表示项集在统计意义上的最低重要性。
最小置信度:最小置信度也是人为按照实际意义规定的阈值,表示关联规则最低可靠性。
如果支持度与置信度同时达到最小支持度与最小置信度,则此关联规则为强规则。
频繁项集:满足最小支持度的所有项集,称作频繁项集。
(频繁项集性质:1、频繁项集的所有非空子集也为频繁项集;2、若A项集不是频繁项集,则其他项集或事务与A项集的并集也不是频繁项集)
了解了以上定义,那么如何从大量的数据中找出不同项的关联规则呢?下面具体看Apriori算法实现过程。
Apriori实现过程:首先,找出所有的频繁项集,再从频繁项集中找出符合最小置信度的项集,最终便得到有强规则的项集(即我们所需的项的关联性)。
例如:
数据如下
算法过程如下
首先计算出所有的频繁项集,这里最小支持度为0.2
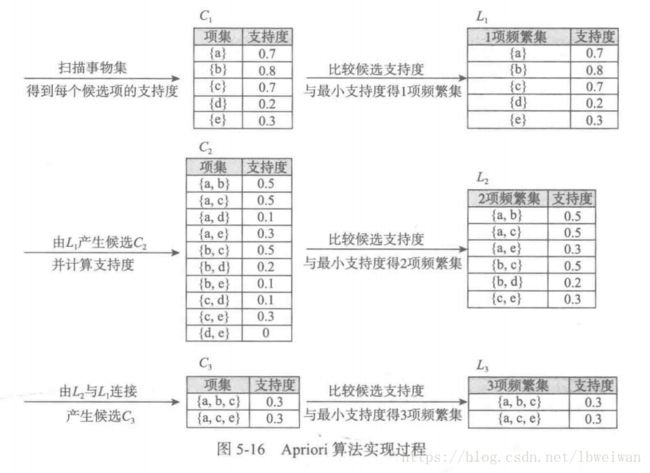
得出L1、L2、L3的各个项集均为频繁项集,再进行计算每个频繁项集的置信度,其中L1不必计算。计算结果如下

(如果想了解寻找频繁项集的详细过程,可以研读张良均等著《python数据分析与挖掘实战》,里面有详细过程)
至此就完成了Apriori算法的全部过程。
接下来python实现Apriori算法
#-*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return resultApriori算法调用,进行关联性分析
数据如下
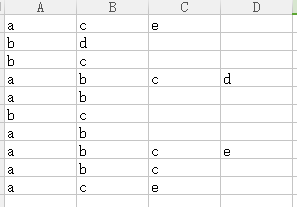
代码如下
#-*- coding: utf-8 -*-
#使用Apriori算法挖掘菜品订单关联规则
from __future__ import print_function
import pandas as pd
from apriori import * #导入自行编写的apriori函数
inputfile = '../data/menu_orders.xls'
outputfile = '../tmp/apriori_rules.xls' #结果文件
data = pd.read_excel(inputfile, header = None)
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行
data = pd.DataFrame(list(b)).fillna(0) #实现矩阵转换,空值用0填充
print(u'\n转换完毕。')
del b #删除中间变量b,节省内存
support = 0.2 #最小支持度
confidence = 0.5 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data, support, confidence, ms).to_excel(outputfile) #保存结果结果如下
support confidence
e—a 0.3 1.000000
e—c 0.3 1.000000
c—e—a 0.3 1.000000
a—e—c 0.3 1.000000
c—a 0.5 0.714286
a—c 0.5 0.714286
a—b 0.5 0.714286
c—b 0.5 0.714286
b—a 0.5 0.625000
b—c 0.5 0.625000
a—c—e 0.3 0.600000
b—c—a 0.3 0.600000
a—c—b 0.3 0.600000
a—b—c 0.3 0.600000
本文主要参考书籍张良均等著《python数据分析与挖掘实战》
本文主要参考博客https://blog.csdn.net/baimafujinji/article/details/53456931