机器学习笔记(2)——使用朴素贝叶斯算法过滤(中英文)垃圾邮件
在上一篇文章《使用朴素贝叶斯算法对文档分类详解》中,我们实现了用朴素贝叶斯算法对简单文档的分类,今天我们将利用此分类器来过滤垃圾邮件。
1. 准备数据——文本切分
之前算法中输入的文档格式为单词向量,例如['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],而实际情况中通常要处理的是文本(例如邮件),那么就要先将文本转换为词向量,在bayes.py中加入代码:
# 文件解析为向量
def textParse(bigString):
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]上面3行代码包含了很多内容,它的输入参数是字符串,返回字符串列表。
- 因为要使用正则表达式切分文本,首先引用了re模块。
- 调用re.split方法切分文本,正则表达式‘\W*’代表以单词和数字外的任意长度字符作为分隔符,前面的r表示原生字符,用于声明\不作为转义字符而是与W一起作为正则表达式。
- listOfTokens是被切分后的词列表, 但其中包含了空字符串,解析文本中的url产生的无含义的短字符串等。代码最后一行负责生成并返回一个列表, 列表的内容为listOfTokens中长度大于2的单词,并统一转为小写。
2. 测试算法——过滤垃圾邮件
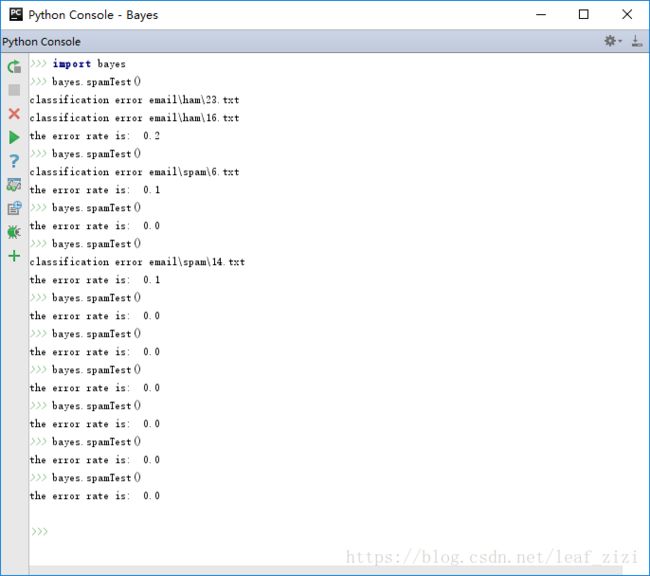
现在有50封电子邮件,垃圾邮件和正常邮件各25个,随机选取10个作为测试集,剩余的40个作为训练集。测试过程可以分解为3部分:
- 读取文本文件,并将其转换为词向量列表
- 构建训练集和测试集,利用训练集构建分类器
- 对测试集样本分类,输出分类错误的文本和错误率
# 垃圾邮件测试函数
def spamTest():
docList = []
classList = []
fileList = []
for i in range(1, 26):
wordList = textParse(
open(r'email\spam\%d.txt' % i).read()) # 将垃圾邮件内容转换为词向量
docList.append(wordList) # 添加到邮件列表
classList.append(1) # 添加到类别列表
fileList.append(r'email\spam\%d.txt' % i)
wordList = textParse(
open(r'email\ham\%d.txt' % i).read()) # 将正常邮件内容转换为词向量
docList.append(wordList)
classList.append(0)
fileList.append(r'email\ham\%d.txt' % i)
vocabList = createVocabList(docList) # 生成词条列表
trainingSet = list(range(50)) # 创建一个长度为50的训练集索引列表
testSet = []
for i in range(10): # 随机选择10个作为测试样本,并将其从训练集中删除
randomIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randomIndex])
del (trainingSet[randomIndex])
trainMat = []
trainClasses = []
for docIndex in trainingSet: # 生成训练样本的矩阵
trainMat.append(bagOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0v, p1v, pSpam = trainNB0(array(trainMat), array(trainClasses)) # 构建分类器
errorCount = 0
for docIndex in testSet: # 对测试集分类
wordVector = bagOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(array(wordVector), p0v, p1v, pSpam) != classList[
docIndex]: # 如果分类错误,打印错误信息
errorCount += 1
print('classification error', fileList[docIndex])
print('the error rate is: ', float(errorCount) / len(testSet)) # 输出错误率下面测试一下分类的效果,因为测试集是随机选取的,每次测试的结果可能不同,可以多次运行测试函数求平均错误率,以此来评估算法。我运行了10次,平均错误率是4%。
3. 中文邮件怎么处理
上面处理的邮件是全英文的,可是中文邮件怎么办呢?如果按上述方法按标点符号来切分的话,中文的一整句话会被当做一个词条,这显然不行,好在Python有个强大的中文处理模块 jieba(结巴),它不仅能对中文文本切词,如果碰到英文单词,也会以英文的默认形式切分。
# 文件解析函数,可处理中文和英文
def textParse1(bigString):
import re
import jieba
listOfTokens = jieba.lcut(bigString) # 使用jieba切分文本
newList = [re.sub(r'\W*', '', s) for s in listOfTokens] # 去掉标点符号
return [tok.lower() for tok in newList if len(tok) > 0] # 删除长度为0的空值这里需要注意的是,如果邮件内容包含中文,是否删除短字符串就要谨慎了,因为中文的一两个字对于分类也是有意义的。我们来试一下效果:
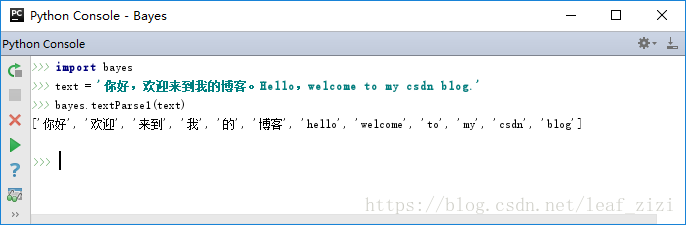
不错,现在对中文邮件也可以轻松过滤了。
说明:文中的测试样本和部分代码来自《机器学习实战》,但书中的代码适合Python 2.7版本, 我将代码做了调整使其能够在Python 3.6下运行,并添加了详细的中文注释。
如果需要测试样本文件,可到我的资源下载:https://download.csdn.net/download/leaf_zizi/10716544。
jieba的下载地址和安装方法:https://pypi.org/project/jieba/