循环神经网络
今天突然发现百度词条对循环神经网络的解释全面的令人感动,尤其是提到了ESN和LSM这类水库计算模型
链接:https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/23199490?fr=aladdin
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network) [1] 。
对循环神经网络的研究始于二十世纪80-90年代,并在二十一世纪初发展为重要的深度学习(deep learning)算法 [2] ,其中双向循环神经网络(Bidirectional RNN, Bi-RNN)和长短期记忆网络(Long Short-Term Memory networks,LSTM)是常见的的循环神经网络 [3] 。
循环神经网络具有记忆性、参数共享并且图灵完备(Turing completeness),因此能以很高的效率对序列的非线性特征进行学习 [4] 。循环神经网络在自然语言处理(Natural Language Processing, NLP),例如语音识别、语言建模、机器翻译等领域有重要应用,也被用于各类时间序列预报或与卷积神经网络(Convoutional Neural Network,CNN)相结合处理计算机视觉问题。
中文名
循环神经网络
外文名
Recurrent Neural Network, RNN
类 型
机器学习算法,神经网络算法
提出者
M. I. Jordan,Jeffrey Elman
提出时间
1986-1990年
学 科
人工智能
应 用
自然语言处理,计算机视觉
目录
- 1 历史
- 2 结构
- ▪ 循环单元
- ▪ 输出模式
- 3 理论
- ▪ 学习范式
- ▪ 优化
- 4 算法
- ▪ 简单循环网络
- ▪ 门控算法
- ▪ 深度算法
- ▪ 拓展算法
- 5 性质
- 6 应用
- ▪ 自然语言处理
- ▪ 计算机视觉
- ▪ 其它
历史
编辑
1933年,西班牙神经生物学家Rafael Lorente de Nó发现大脑皮层(cerebral cortex)的解剖结构允许刺激在神经回路中循环传递,并由此提出反响回路假设(reverberating circuit hypothesis) [5] 。该假说在同时期的一系列研究中得到认可,被认为是生物拥有短期记忆的重要原因 [6-7] 。随后神经生物学的进一步研究发现,反响回路的兴奋和抑制受大脑阿尔法节律(α-rhythm)调控,并在α-运动神经(α-motoneurones )中形成循环反馈系统(recurrent feedback system) [8-9] 。在二十世纪70-80年代,为模拟循环反馈系统而建立的各类数学模型为循环神经网络的发展奠定了基础 [10-12] 。
1982年,美国学者John Hopfield基于Little (1974) [12] 的神经数学模型使用二元节点建立了具有结合存储(content-addressable memory)能力的神经网络,即Hopfield神经网络 [13] 。Hopfield网络是一个包含外部记忆(external memory)的循环神经网络,其内部所有节点都相互连接,并使用能量函数进行学习 [14] 。由于Hopfield (1982) 使用二元节点,因此在推广至序列数据时受到了限制,但其工作受到了学界的广泛关注,并启发了其后的循环神经网络研究 [15-16] 。
1986年,Michael I. Jordan基于Hopfield网络的结合存储概念,在分布式并行处理(parallel distributed processing)理论下建立了新的循环神经网络,即Jordan网络 [16] 。Jordan网络的每个隐含层节点都与一个“状态单元(state units)”相连以实现延时输入,并使用logistic函数(logistic function)作为激励函数 [16] 。Jordan网络使用反向传播算法(Back-Probagation, BP)进行学习,并在测试中成功提取了给定音节的语音学特征 [16] 。之后在1990年,Jeffrey Elman提出了第一个全连接的循环神经网络,Elman网络 [17] 。Jordan网络和Elman网络是最早出现的面向序列数据的循环神经网络,由于二者都从单层前馈神经网络出发构建递归连接,因此也被称为简单循环网络(Simple Recurrent Network, SRN) [4] 。
在SRN出现的同一时期,循环神经网络的学习理论也得到发展。在反向传播算法的研究受到关注后 [18] ,学界开始尝试在BP框架下对循环神经网络进行训练 [16] [2] [19] 。1989年,Ronald Williams和David Zipser提出了循环神经网络的实时循环学习(Real-Time Recurrent Learning, RTRL) [20] 。随后Paul Werbos在1990年提出了循环神经网络的随时间反向传播(BP Through Time,BPTT) [21] ,RTRL和BPTT被沿用至今,是循环神经网络进行学习的主要方法 [4] 。
1991年,Sepp Hochreiter发现了循环神经网络的长期依赖问题(long-term dependencies problem),即在对序列进行学习时,循环神经网络会出现梯度消失(gradient vanishing)和梯度爆炸(gradient explosion)现象,无法掌握长时间跨度的非线性关系 [22-23] 。为解决长期依赖问题,大量优化理论得到引入并衍生出许多改进算法,包括神经历史压缩器(Neural History Compressor, NHC) [24] 、长短期记忆网络(Long Short-Term Memory networks, LSTM) [25] 、门控循环单元网络(Gated Recurrent Unit networks, GRU) [26] 、回声状态网络(echo state network)、独立循环神经网络(Independent RNN) [27] 等。
在应用方面,SRN自诞生之初就被应用于语音识别任务,但表现并不理想 [28] ,因此在二十世纪90年代早期,有研究尝试将SRN与其它概率模型,例如隐马尔可夫模型(Hidden Markov Model, HMM)相结合以提升其可用性 [29-30] 。双向循环神经网络(Bidirectional RNN, Bi-RNN)和双向LSTM的出现提升了循环神经网络对自然语言处理的能力 [31] [32] ,但在二十世纪90年代,基于循环神经网络的有关应用没有得到大规模推广。二十一世纪后,随着深度学习方法的成熟,数值计算能力的提升以及各类特征学习(feature learning)技术的出现,拥有复杂构筑的深度循环神经网络(Deep RNN, DRNN)开始在自然语言处理问题中展现出优势,并成为语音识别、语言建模等应用的重要算法 [33] [34] 。
结构
编辑
循环单元
内部计算
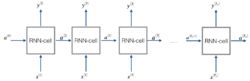 全连接的循环单元 [3]
全连接的循环单元 [3]
循环神经网络的核心部分是一个有向图(directed graph)。有向图展开中以链式相连的元素被称为循环单元(RNN cell) [1] [3] 。通常地,循环单元构成的链式连接可类比前馈神经网络中的隐含层(hidden layer),但在不同的论述中,循环神经网络的“层”可能指单个时间步的循环单元或所有的循环单元,因此作为一般性介绍,这里避免引入“隐含层”的概念。给定按序列输入的学习数据
![]()
,循环神经网络的展开长度为
![]()
。待处理的序列通常为时间序列,此时序列的演进方向被称为“时间步(time-step)”。对时间步
![]()
,循环神经网络的循环单元有如下表示 [1] :
![]()
式中
![]()
称为循环神经网络的系统状态(system status),在动力系统的观点下,系统状态描述了一个给定空间中所有点随时间步的变化 [1] 。
![]()
是内部状态(internal status),与系统状态有关
![]()
。由于求解当前的系统状态需要使用前一个时间步的内部状态,因此循环单元的计算包含递归(recursion)。在树结构的观点下,所有先前时间步的循环单元都是当前时间步循环单元的父节点。式中
![]()
是激励函数或一个封装的前馈神经网络,前者对应简单循环网络(SRN),后者对应门控算法和一些深度算法 [1] 。常见的激励函数选择包括logistic函数和双曲正切函数(hyperbolic tangent function)。
![]()
是循环单元内部的权重系数,与时间步无关,即对一组学习样本,循环神经网络使用共享的权重计算所有时间步的输出 [1] 。
仅由循环单元构成的循环神经网络在理论上是可行的,但循环神经网络通常另有输出节点,其定义为一个线性函数 [1] :
![]()
式中
![]()
是权重系数。根据循环神经网络结构的不同,一个或多个输出节点的计算结果在通过对应的输出函数后可得到输出值
![]()
。例如对分类问题,输出函数可以是归一化指数函数(softmax function)或其它机器学习算法建立的分类器 [1] [4] 。
连接性
1. 循环单元-循环单元连接:也被称为“隐含-隐含连接(hidden-hidden connection)”或全连接,此时每个循环单元当前时间步的状态由该时间步的输入和上一个时间步的状态决定:
![]()
,
![]()
是循环节点的权重,前者称为状态-状态权重,后者称为状态-输入权重 [4] 。循环单元-循环单元连接可以是双向的,对应双向循环神经网络 [1] 。
2. 输出节点-循环单元连接:该连接方式下循环单元的状态由该时间步的输入和上一个时间步的输出(而不是状态)决定:
![]()
。由于潜在假设了前一个时间步的输出节点能够表征先前所有时间步的状态,输出节点-循环单元连接的循环神经网络不具有图灵完备性,学习能力也低于全连接网络。但其优势是可以使用Teacher Forcing进行快速学习 [1] 。
3. 基于上下文的连接:因为在图网络的观点下呈现闭环结构,该连接方式也被称为闭环连接(closed-loop connection),其中循环单元的系统状态引入了其上一个时间步的真实值
![]()
。使用基于上下文连接的循环神经网络由于训练时将学习样本的真实值作为输入,因此是一个可以逼近学习目标概率分布的生成模型(generative model)。基于上下文的连接有多种形式,其中常见的一类使用了该时刻的输入、上一时刻的状态和真实值:
![]()
。其它的类型可能使用固定长度的输入,使用上一时刻的输出代替真实值,或不使用该时刻的输入 [1] 。
输出模式
通过建立输出节点,循环神经网络可以有多种输出模式,包括序列-分类器(单输出)、序列-序列(同步多输出)、编码器-解码器(异步多输出)等 [4] 。
序列-分类器
序列-分类器的输出模式适用于序列输入和单一输出的机器学习问题,例如文本分类(sentiment classification)。给定学习数据和分类标签:
![]()
,序列-分类器中循环单元的输出节点会直接通过分类器,常见的选择是使用最后一个时间步的输出节点
![]()
,或递归计算中所有系统状态的均值
![]()
[4] 。常见的序列-分类器使用全连接结构。
序列-序列
序列-序列的输出模式中,序列的每个时间步对应一个输出,即输入和输出的长度相同 [4] 。给定学习目标
![]()
,序列-序列的输出模式在每个时间步都输出结果
![]()
。循环单元-循环单元连接、输出节点-循环单元连接和基于上下文的连接都支持序列-序列输出,其中前两者常见于词性标注(part-of-speech tagging)问题,后者可被应用于文本生成(text generation)和音乐合成(music composition)。
编码器-解码器(encoder-decoder)
在输入数据和学习目标都为序列且长度可变时,可以使用两个相耦合的基于上下文连接的循环神经网络,即编码器-解码器进行建模,编码器-解码器常被用于机器翻译(Machine Translation, MT)问题,这里以此为例进行说明。给定嵌入的原始文本和翻译文本:
![]()
,编码器在工作时对原始文本进行处理,并输出
![]()
或
![]()
到解码器,解码器根据编码器的输出生成新序列。编码器-解码器结构的循环神经网络以最大化
![]()
为目标更新权重系数 [1] 。
理论
编辑
学习范式
监督学习(supervised learning)
1. Teacher Forcing
Teacher Forcing是一种在序列-序列输出模式下对循环神经网络进行快速训练的方法,其理念是在每一个时间步的训练中引入上一个时间步的学习目标(真实值)从而解耦误差的反向传播。具体地,Teacher Forcing是一种极大似然估计(Maximum Likelihood Estimation, MLE)方法,例如对序列的前两个时间步,序列的对数似然有如下表示 [1] :
![]()
此时MLE将时间步
![]()
的学习转化为求解权重系数
![]()
使
![]()
的似然取极大值的优化问题,因此不需要将神经网络的误差函数反向传播至该时间步。
上述方法被称为“严格的”Teacher Forcing,适用于输出节点-循环单元连接的循环神经网络,对循环单元-循环单元连接的循环神经网络,只要输出节点-循环单元可以连接,则Teacher Forcing可以和随时间反向传播(BPTT)一起使用 [1] 。
严格的Teacher Forcing不适用于闭环连接的循环神经网络,因为该连接方式在测试时会将前一个时间步的输出作为当前时间步的输入,而Teacher Forcing在学习时使用的真实值
![]()
和测试时神经网络自身的输出
![]()
往往有显著差别。一个改进是对部分样本进行自由学习,即使用神经网络自身的输出代替真实的学习目标加入Teacher Forcing中 [1] 。此外也可在Teacher Forcing的所有学习样本中随机混入
![]()
,并随着学习过程不断增加混入
![]()
的比例 [35] 。
2. 随时间反向传播(BP Through Time, BPTT)
参见:反向传播算法
BPTT是反向传播算法(BP)由前馈神经网络向循环神经网络的推广 [1] ,BPTT将循环神经网络的链式连接展开,其中每个循环单元对应一个“层”,每个层都按前馈神经网络的BP框架进行计算 [4] 。考虑循环神经网络的参数共享性质,权重的梯度是所有层的梯度之和:
![]()
式中
![]()
为损失函数。这里以循环单元-循环单元连接的多输出网络为例介绍BPTT的计算步骤。首先给定如下的更新方程 [1] :
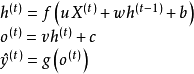
式中需要求解的权重为
![]()
。对最末端的时间步
![]()
和其余的时间步
![]()
,求解总损失函数对循环单元状态的偏导数是一组递归计算:
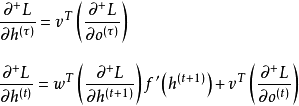
由于循环神经网络参数共享,因此在计算当前时间步的梯度时需要将共享的参数对其它时间步的损失函数的变化“固定”,这里使用“
![]()
”表示该关系,在一些文献中,该符号被称为“实时导数(intermediate derivative)” [4] [36] 。式中
![]()
为激励函数的导数,
![]()
与输出函数
![]()
有关。按上式对所有时间步反向传播后,循环神经网络的权重梯度更新按如下方式给出:
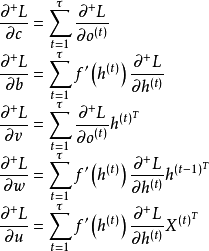
上述步骤为BPTT的标准求解框架,在理论上可以处理所有类型的循环神经网络 [3] 。在实际应用中,由于损失函数对状态的偏导数
![]()
需要被完整地保存直到该样本的所有参数更新完毕,因此在学习长序列样本时,BPTT的空间复杂度显著增加 [4] 。对BPTT按固定长度截断,即截断的BPTT(truncated BPTT)可解决上述问题 [37] 。
3. 实时循环学习(Real-Time Recurrent Learning, RTRL)
RTRL通过前向传播的方式来计算梯度,在得到每个时间步的损失函数后直接更新所有权重系数至下一个时间步,类似于自动微分的前向连锁(forward accumulation)模式。这里以BPTT中的状态-状态权重
![]()
为例做简单介绍。在时间步
![]()
,损失函数
![]()
对权重中元素
![]()
的实时更新规则如下:
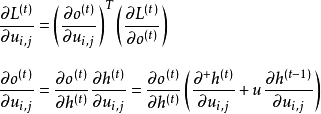
其它权重的更新可以按相近的方式导出。相比于BPTT,RTRL的计算量更大,但因为无需存储反向传播的误差梯度,RTRL的内存开销更小,更适用于在线学习或使用长序列学习样本的问题 [4] 。
非监督学习(unsupervised learning)
使用编码器-解码器结构的循环神经网络能够以自编码器(Auto-Encoders, AE)的形式,即循环自编码器(Recurrent AE)进行非监督学习 [38] 。RAE是对序列数据进行特征学习(feature learning)的方法之一 [39] ,其工作方式与编码器-解码器相近。具体地,RAE输入端的编码器会处理序列并将最后一个时间步的状态传递至解码器,解码器使用编码器的输出重构序列。RAE以最小化原始序列和重构序列的差异为目标进行学习 [38] 。不同于一般的编码器-解码器结构,在学习完毕后,RAE只有编码器部分会被取出使用,对输入序列进行编码 [38] 。
非监督学习也可被应用于堆叠循环神经网络,其中最早被提出的方法是神经历史压缩器(Neural History Compressor, NHC) [24] [2] 。NHC是一个自组织阶层系统(self-organized hierarchical system),在学习过程中,NHC内的每个循环神经网络都以先前时间步的输入
![]()
学习下一个时间步的输入
![]()
,学习误差(通常由长距离依赖产生)会输入到更高阶层的循环神经网络中,在更长时间尺度下进行学习以 [24] 。最终输入数据会在NHC的各个阶层得到完整的表征,上述过程在研究中被描述为“压缩(compression)”或“蒸馏(distillation)” [24] [40] 。NHC在本质上是阶层结构的AE,对输入数据进行压缩即是其特征学习的过程 [2] 。由于可以在多时间尺度上学习长距离依赖,因此NHC也被用于循环神经网络在监督学习问题中的预学习(pre-training) [2] 。
除上述方法外,循环神经网络有其它适用于特定问题的非监督学习方法。在对序列数据进行聚类(clustering)时,循环神经网络可以使用BINGO(Binary Information Gain Optimization)算法 [41-42] 。对非参数学习问题,循环神经网络可以使用NEO(Non-parametric Entropy Optimization)算法 [42-43] 。上述两种算法使用较少,这里不做赘述。
优化
循环神经网络在误差梯度在经过多个时间步的反向传播后容易导致极端的非线性行为,包括梯度消失(gradient vanishing)和梯度爆炸(gradient explosion)。不同于前馈神经网络,梯度消失和梯度爆炸仅发生在深度结构中,且可以通过设计梯度比例得到缓解,对循环神经网络,只要序列长度足够,上述现象就可能发生 [1] 。在理解上,循环神经网络的递归计算类似于连续的矩阵乘法,例如
![]()
可视为一个不考虑激励函数的循环神经网络,而该式实际等价于
![]()
。由于循环神经网络使用固定的权重处理所有时间步,因此随着时间步的推移,权重系数必然出现指数增长或衰减,引发梯度的显著变化 [1] [4] 。
在实践中,梯度爆炸虽然对学习有显著影响,但较少出现,使用梯度截断可以解决 [1] 。梯度消失是更常见的问题且不易察觉,发生梯度消失时,循环神经网络在多个时间步后的输出几乎不与序列的初始值有关,例如先前式中的
![]()
,因此无法模拟序列的长距离依赖(long-term dependency) [1] 。在数值试验中,SRN对时间步跨度超过20的长距离依赖进行成功学习的概率接近于0 [44] 。恰当的权重初始化(weight initialization),或使用非监督学习策略例如神经历史压缩器(NHC)可提升循环神经网络学习长距离依赖的能力 [45] ,但对更一般的情形,循环神经网络发展了一系列优化策略,其中有很多涉及网络结构的改变和算法的改进。
梯度截断
梯度截断是处理循环神经网络梯度爆炸现象的有效方法,具体分为两种,一是设定阈值并逐个元素筛查,若梯度超过阈值则截断至阈值 [46] ;二是在参数更新前,若误差对参数的梯度超过阈值,则按范数(norm)截断 [47] :
![]()
式中
![]()
为梯度的阈值。比较可知,按范数截断保持了截断前后梯度的方向不变,因此逻辑上更合理,但试验表明,两种方法效果相当。事实上作为经验方法,只要梯度截断将权重系数带离数值不稳定区域,就能很好地应对梯度爆炸现象 [1] 。
正则化(regularization)
循环神经网络的正则化是应对其长距离依赖问题的方法之一,其理念是控制循环节点末端状态对初始状态导数,即雅可比矩阵的范数以提升循环神经网络对长距离误差的敏感性 [36] 。在误差反向传播至第
![]()
个时间步时,其对应的正则化项有如下表示[36] :
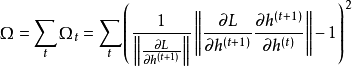
在BP中加入上述正则化项会显著提升计算复杂度,此时可将包含损失函数的项近似为常数,并引导雅可比矩阵的范数向1靠近 [36] 。研究表明,正则化和梯度截断结合使用可以增加循环神经网络学习长距离依赖的能力,但相比于门控单元,正则化没有减少模型的冗余 [1] [36] 。
在前馈神经网络中被广泛使用的随机失活(dropout)策略也可用于循环神经网络。在输入序列的维度大于1时,循环神经网络在每个时间步的输入和状态的矩阵元素都可以被随机归零 [48] [49] :
![]()
式中
![]()
为(0,1)-矩阵,也被称为maxout矩阵(maxout array)随机决定需要失活的连接。maxout矩阵可以对一组学习样本的所有时间步保持不变,其中与系统状态相乘的maxout矩阵也可随时间步变化 [48] [49] 。在长序列的学习中,不断生成随机数进行随机失活会降低算法的运行效率,一个可能的改进是假设距离过长的元素影响很小,并只对与当前时间步相隔一定范围的循环单元连接使用随机失活 [48] 。
层归一化(Layer Normalization, LN)
应用于循环神经网络时,LN将循环神经网络的每个循环单元视为一个层进行归一化。对时间步
![]()
,包含LN的循环节点的内部计算如下表示 [50] :
![]()
式中
![]()
和
![]()
为代表缩放和平移的参数,随BP算法进行更新 [50] 。在循环神经网络中,循环节点的均值和标准差会发生改变,产生协变漂移(covariate shift)现象,该现象会导致梯度爆炸和梯度消失,因此LN是缓解长距离依赖问题的方法之一 [51] 。
储层计算(reservoir computing)
储层计算将循环神经网络中链式连接转变为一个“储层(reservoir)”,储层内循环单元的状态在每个时间步更新。储层与输出层相连,其对应的输出权重由学习数据求解 [1] [52] :
![]()
式中
![]()
为储层的输入权重,在计算中随机初始化并且固定,
![]()
为输出权重,按线性参数模型的计算方法求解。注意到上式中
![]()
向
![]()
的递归是随机的,因此储层计算的构筑本身缓解了循环神经网络的长距离依赖问题。同时,为确保储层不发生梯度爆炸,其输出权重有两个重要设定:使用稀疏矩阵和特征值的最大绝对值小于谱半径(spectural radius)。谱半径是一个超参数,用于控制
![]()
随时间步的指数增长 [1] [53] 。稀疏矩阵控制储层与输出层间的松散连接,此时储层中的信息只能在有限的输出中“回声”,不会扩散至网络的所有输出中 [52] 。
储层计算可以被视为循环神经网络的学习理论或对循环神经网络的结构优化 [52] [54] 。使用储层计算的循环神经网络包括回声状态网络(Echo State Network, ESN)和流体状态机(liquid state machine),二者的不同点是流体状态机的储层单元是二元节点 [1] 。储层计算中随机初始化并固定隐含层输入权重的方法接近于极限学习机(Extreme Learning Machine, ELM),但后者基于前馈神经网络构建,其隐含层节点不是循环单元,不具有记忆性 [55] 。
跳跃连接(skip connection)
梯度消失是时间步的函数,因此可以通过使用跳跃连接提高循环神经网络学习长距离依赖的能力。跳跃连接是跨多个时间步的长距离连接,引入跳跃连接后,长时间尺度的状态能够更好地在神经网络中传递,缓解梯度消失现象 [1] 。有研究在使用跳跃连接的同时直接删除循环单元-循环单元连接,强迫循环神经网络以阶层结构在长时间尺度上运行 [56] 。
渗漏单元(leaky unit)和门控单元(gated unit)
渗漏单元也被称为线性自连接单元(linear self-connection unit)是在循环单元间模拟滑动平均(moving average)以保持循环神经网络中长距离依赖的方法 [1] :
![]()
式中的权重
![]()
是预先给定的。由上式容易发现,渗漏单元会在迭代中优先记忆系统先前的状态 ,因此提升了循环神经网络建立长期依赖的能力 [1] 。研究表明ESN可以引入渗漏单元进行优化以提升其学习效果 [53] 。
渗漏单元在应用中有两个不足,一是人为给定的权重不是记忆系统状态的最优方式,二是渗漏单元没有遗忘功能,容易出现信息过载,在过去的状态被循环单元充分使用后,将其遗忘可能是有利的 [1] 。 以此出发,门控单元是渗漏单元的推广,门控单元的类型包括输入门(input gate)、输出门(output gate)和遗忘门(forget gate)。每个门都是一个封装的神经网络,其计算方式可参见算法部分。总体而言,门控单元是减少学习误差的长距离依赖的有效方法,使用门控单元的算法,包括长短期记忆网络(Long Short-Term Memory networks, LSTM)和门控循环单元网络(Gated Recurrent Unit networks, GRU)被证实在各类问题中有显著优于SRN的表现 [1] 。
算法
编辑
简单循环网络
简单循环网络(Simple Recurrent Network, SRN)是仅包含一组链式连接(单隐含层)的循环神经网络,其中循环单元-循环单元连接的为Elman网络,闭环连接的为Jordan网络。对应的递归方式如下 [16] [17] :
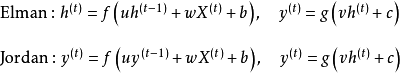
式中
![]()
和
![]()
为激励函数,例如逻辑斯蒂函数或双曲正切函数。SRN在提出时使用BPTT进行监督学习,但不包含任何优化理论,因此无法学习长距离依赖 [44] ,在现代的机器学习问题中很少直接使用。
门控算法
门控算法是循环神经网络应对长距离依赖的重要方法,其思想是使用门控单元赋予循环神经网络控制其内部信息积累的能力,在学习时既能掌握长距离依赖又能选择性地遗忘信息防止过载 [1] 。门控算法使用BPTT和RTRL进行学习,其计算复杂度和学习表现均高于SRN [25] [1] 。
长短期记忆网络(Long Short-Term Memory networks, LSTM)
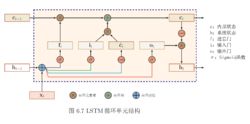 LSTM单元的内部结构
LSTM单元的内部结构
LSTM是最早被提出的循环神经网络门控算法,其对应的循环单元,LSTM单元包含3个门控:输入门、遗忘门和输出门。相对于循环神经网络对系统状态建立的递归计算,3个门控对LSTM单元的内部状态建立了自循环(self-loop) [1] 。具体地,输入门决定当前时间步的输入和前一个时间步的系统状态对内部状态的更新;遗忘门决定前一个时间步内部状态对当前时间步内部状态的更新;输出门决定内部状态对系统状态的更新。LSTM单元的更新方式如下 [1] :
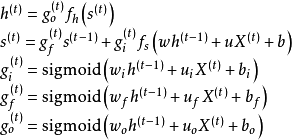
式中
![]()
为系统状态和内部状态的激励函数,通常为双曲正切函数,
![]()
为随时间步更新的门控,本质上是以Sigmoid函数为激励函数的前馈神经网络,使用Sigmoid函数的原因是其输出在
![]()
区间,等效于一组权重。式中脚标
![]()
表示输入门、遗忘门和输出门。除上述更新规则外,LSTM也可进一步引入内部状态更新门控,使用该策略的算法被称“peephole LSTM” [4] [57] :
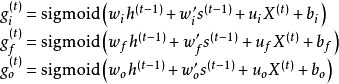
最初版本的LSTM没有遗忘门,以全连接的方式进行序列-序列输出 [25] ,但本质上LSTM单元可以被引入其它各类循环神经网络构筑中,例如LSTM自编码器(LSTM Autoencoder) [58] 、堆叠LSTM(stacked LSTM) [59] 等。
对LSTM进行权重初始化时,需要为遗忘门设定较大的初始值,例如设定
![]()
。过小的值会使得遗忘门在学习中快速遗忘先前时间步的信息,不利于神经网络学习长距离依赖, 并可能导致梯度消失 [60] 。
门控循环单元网络(Gated Recurrent Unit networks, GRU)
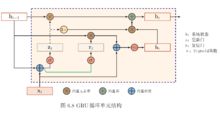 GRU的内部结构
GRU的内部结构
由于LSTM中3个门控对提升其学习能力的贡献不同,因此略去贡献小的门控和其对应的权重,可以简化神经网络结构并提升其学习效率 [1] 。GRU即是根据以上观念提出的算法,其对应的循环单元仅包含2个门控:更新门和复位门,其中复位门的功能与LSTM单元的输入门相近,更新门则同时实现了遗忘门和输出门的功能 [1] [26] 。GRU的更新方式如下 [26] :
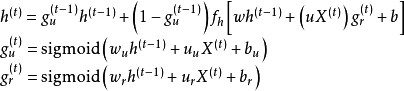
式中符号含义参考LSTM,脚标
![]()
表示更新门和复位门。对比LSTM与GRU的更新规则可以发现,GRU的参数总量更小,且参数更新顺序与LSTM不同,GRU先更新状态再更新门控,因此当前时间步的状态使用前一个时间步的门控参数,LSTM先更新门控,并使用当前时间步的门控参数更新状态。GRU的2个门控不形成自循环,而是直接在系统状态间递归,因此其更新方程也不包含内部状态
![]()
。
LSTM和GRU有很多变体,包括在循环单元间共享更新门和复位门参数,以及对整个链式连接使用全局门控,但研究表明这些改进版本相比于标准算法未体现出明显优势,其可能原因是门控算法的表现主要取决于遗忘门,而上述变体和标准算法使用了的遗忘门机制相近 [61] 。
深度算法
循环神经网络的“深度”包含两个层面,即序列演进方向的深度和每个时间步上输入与输出间的深度。对前者,循环神经网络的深度取决于其输入序列的长度,因此在处理长序列时可以被认为是直接的深度网络;对后者,循环神经网络的深度取决于其链式连接的数量,单链的循环神经网络可以被认为是“单层”的 [4] 。
循环神经网络能够以多种方式由单层加深至多层 [62] ,其中最常见的策略是使用堆叠的循环单元 [33] 。由于在序列演进方向已经存在复杂结构,因此不同于深度的前馈神经网络,深度循环神经网络在输入和输出间不会堆叠太多层次,一个3层的深度循环神经网络已经具有很大规模 [3] 。
堆叠循环神经网络(Stacked Recurrent Neural Network, SRNN)
SRNN是在全连接的单层循环神经网络的基础上堆叠形成的深度算法。SRNN内循环单元的状态更新使用了其前一层相同时间步的状态和当前层前一时间步的状态 [4] [33] :
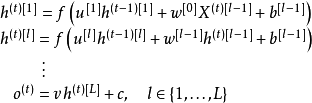
式中符号含义参见循环单元部分,上标
![]()
分别表示时间步和层数。参与构建SRNN的循环神经网络可以是简单循环网络(SRN)或门控算法。使用SRN构建的SRNN也被称为循环多层感知器(Recurrent Multi-Layer Perceptron,RMLP),是1991年被提出的深度循环神经网络 [63] 。
双向循环神经网络(bidirectional recurrent neural network, Bi-RNN)
Bi-RNN是两层的深度循环神经网络,被应用于学习目标与完整(而不是截止至当前时间步)输入序列相关的场合。例如在语音识别中,当前语音对应的词汇可能与其后出现的词汇有对应关系,因此需要以完整的语音作为输入 [1] 。Bi-RNN的两个链式连接按相反的方向递归,输出的状态会进行矩阵拼接并通过输出节点,其更新规则如下 [31] [4] :
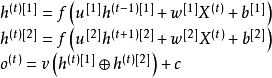
式中符号含义参见循环单元部分,
![]()
表示矩阵拼接。和SRNN类似,Bi-RNN也可以由各种类型的循环单元构成,例如由LSTM构成的版本被称为双向LSTM [32] 。
拓展算法
外部记忆
循环神经网络在处理长序列时有信息过载的问题,例如对编码器-解码器结构,编码器末端的输出可能无法包含序列的全部有效信息 [1] 。门控算法的遗忘门/更新门可以有选择地丢弃信息,减缓循环单元的饱和速度,但更进一步地,有研究通过将信息保存在外部记忆(external memory)中,并在需要时再进行读取,以提高循环神经网络的网络容量(network capacity) [1] [14] 。使用外部记忆的循环神经网络包括神经图灵机(Neural Turing Machine, NTM) [64] 、Hopfield神经网络等 [14] 。
与卷积神经网络相结合
参见:卷积神经网络
循环神经网络与卷积神经网络相结合的常见例子是循环卷积神经网络(Recurrent CNN, RCNN)。RCNN将卷积神经网络的卷积层替换为内部具有递归结构的循环卷积层(Recurrent Convolutional Layer, RCL),并按前馈连接建立深度结构 [65] 。
除RCNN外,循环神经网络和卷积神经网络还可以通过其它方式相结合,例如使用卷积神经网络对序列化的格点输入进行特征学习,并将结果按输入循环神经网络 [66] 。
递归神经网络和图网络
主条目:递归神经网络,图网络
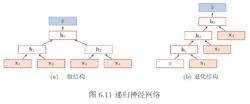 一般的递归神经网络(左),结构退化后的循环神经网络(右) [4]
一般的递归神经网络(左),结构退化后的循环神经网络(右) [4]
循环神经网络按序列演进方向的递归可以被扩展到树(tree)结构和图(graph)结构中,得到递归神经网络(recursive neural network)和图网络(Graph Network, GN)。
递归神经网络是循环神经网络由链式结构向树状结构的推广 [67] 。不同于循环神经网络的链式连接,递归神经网络的每个子节点都可以和多个父节点相连并传递状态。当其所有子节点都仅与一个父节点相连时,递归神经网络退化为循环神经网络 [4] 。递归神经网络的节点可加入门控机制,例如通过LSTM门控得到树状长短期记忆网络(tree-structured LSTM) [68] 。图网络是循环神经网络和递归神经网络的进一步推广,或者说后两者是图网络在特定结构下的神经网络实现 [69] 。在图网络观点下,全连接的循环神经网络是一个有向无环图,而上下文连接的循环神经网络是一个有向环图。递归神经网络和图网络通常被用于学习数据具有结构关系的场合,例如语言模型中的语法结构 [70] 。
性质
编辑
权重共享:循环神经网络的权重系数是共享的,即在一次迭代中,循环节点使用相同的权重系数处理所有的时间步。相比于前馈神经网络,权重共享显著降低了循环神经网络的总参数量,增强了网络的泛化能力。同时,权重共享也意为着循环神经网络可以提取序列中随时间变化的动力特征,因此其在学习和测试序列具有不同长度时也可以有稳定的表现 [3] 。
计算能力:可以证明,一个循环单元间完全连接的循环神经网络满足通用近似定理,即全联接循环神经网可以按任意精度逼近任意非线性系统,且对状态空间的紧致性没有限制,只要其拥有足够多的非线性节点。在此基础上,任何图灵可计算函数(Turing computable function)都可以由有限维的全联接循环神经网络计算,因此循环神经网络是图灵完备(Turing completeness)的 [4] 。
作为时间序列模型的性质:在时间序列建模的观点下,循环神经网络是一个无限冲激响应滤波器(Infinite Impulse Response filter, IIR) [71] 。这将循环神经网络与其它应用于序列数据的权重共享模型,例如一维的卷积神经网络相区分,后者以时间延迟网络为代表,是有限冲激响应滤波器(Finite Impulse Response filter, FIR) [71] 。
应用
编辑
自然语言处理
自然语言数据是典型的序列数据,因此处理序列数据具有内在优势的循环神经网络是各类NLP问题的重要算法。在语音识别(speech recognition)中,循环神经网络被广泛应用于端到端(end-to-end)建模,例如有研究使用LSTM单元构建的双向深度循环神经网络成功进行了英语文集TIMIT的语音识别,其识别准确率超过了同等条件的隐马尔可夫模型(Hidden Markov Model, HMM)和深度前馈神经网络 [33] 。
循环神经网络是机器翻译(Machine Translation, MT)的主流算法之一 [3] ,并形成了区别于“统计机器翻译”的“神经机器翻译(neural machine translation)”方法 [72] 。有研究使用端到端学习的LSTM成功对法语-英语文本进行了翻译 [73] ,也有研究将卷积n元模型(convolutional n-gram model)与循环神经网络相结合进行机器翻译 [74] 。有研究认为,按编码器-解码器形式组织的LSTM能够在翻译中考虑语法结构 [75] 。
基于上下文连接的循环神经网络,被大量用语言建模(language modeling)问题 [3] [34] [76] 。有研究在字符层面(character level)的语言建模中,将循环神经网络与卷积神经网络相结合并取得了良好的学习效果 [66] 。循环神经网络也是语义分析( sentiment analysis)的工具之一,被应用于文本分类 [77] 、社交网站数据挖掘 [78-79] 等场合。
在语音合成(speech synthesis)领域,有研究将多个双向LSTM相组合建立了低延迟的语音合成系统,成功将英语文本转化为接近真实的语音输出 [80] 。循环神经网络也被用于端到端文本-语音(Text-To-Speech, TTS)合成工具的开发,例子包括Tacotron [81] 、Merlin [82] 等。
计算机视觉
循环神经网络与卷积神经网络向结合的系统在计算机视觉问题中有一定应用,例如在字符识别(text recognition)中,有研究使用卷积神经网络对包含字符的图像进行特征提取,并将特征输入LSTM进行序列标注 [83] 。对基于视频的计算机视觉问题,例如行为认知(action recognition)中,循环神经网络可以使用卷积神经网络逐帧提取的图像特征进行学习 [84] 。
其它
在计算生物学(computational biology)领域,深度循环神经网络被用于分析各类包含生物信息的序列数据,有关主题包括在DNA序列中识别分割外显子(exon)和内含子(intron)的断裂基因(split gene) [85] 、通过RNA序列识别小分子RNA(microRNA) [86] 、使用蛋白质序列进行蛋白质亚细胞定位(subcellular location of proteins)预测 [87] 等。
在地球科学(earth science)领域,循环神经网络被用于时间序列变量的建模和预测。使用LSTM建立的水文模型(hydrological model)对土壤湿度的模拟效果与陆面模式相当 [88] 。而基于LSTM的降水-径流模式(rainfall-runoff model)所输出的径流量与美国各流域的观测结果十分接近 [89] 。在预报方面,有研究将地面遥感数据作为输入,使用循环卷积神经网络进行单点降水的临近预报(nowcast) [90] 。
包含循环神经网络的编程模块
现代主流的机器学习库和界面,包括TensorFlow、Keras、Thenao、Microsoft-CNTK等都支持运行循环神经网络。此外有基于特定数据的循环神经网络构建工具,例如面向音频数据开发的auDeep [91] 等。
词条图册更多图册
词条图片(5)
参考资料
- 1. Goodfellow, I., Bengio, Y., Courville, A..Deep learning (Vol. 1):Cambridge:MIT Press,2016:367-415
- 2. Schmidhuber, J., 2015. Deep learning in neural networks: An overview. Neural networks, 61, pp.85-117.
- 3. Ng, A., Kian, K. and Younes, B., Sequence Models, Deep learning. .Coursera and deeplearning.ai.2018[引用日期2018-11-29]
- 4. 邱锡鹏 著,神经网络与深度学习,第六章 循环神经网络 .Github Inc..2018-3-12[引用日期2018-11-28]
- 5. Lorente de Nó, R., 1933. Studies on the structure of the cerebral cortex. I: the area entorhinalis. Journal für Psychologie und Neurologie, 45, pp.381-438.
- 6. Mackay, R.P., 1953. Memory as a biological function. American Journal of Psychiatry, 109(10), pp.721-728.
- 7. Gerard, R. W., 1963. The material basis of memory. Journal of verbal learning and verbal behavior, 2, pp.22-33.
- 8. Cullheim, S., Kellerth, J.O. and Conradi, S., 1977. Evidence for direct synaptic interconnections between cat spinal α-motoneurons via the recurrent axon collaterals: a morphological study using intracellular injection of horseradish peroxidase. Brain research, 132(1), pp.1-10.
- 9. Windhorst, U., 1996. On the role of recurrent inhibitory feedback in motor control. Progress in neurobiology, 49(6), pp.517-587.
- 10. Windhorst, U., 1979. Auxiliary spinal networks for signal focussing in the segmental stretch reflex system. Biological Cybernetics, 34(3), pp.125-135.
展开全部
学术论文
内容来自 
- 朱小燕,王昱,徐伟. 基于循环神经网络的语音识别模型. 《 计算机学报 》 , 2001
- 王科俊,李国斌. DRNN神经网络用于船舶横摇运动的时间序列预报. 《 哈尔滨工程大学学报 》 , 1997
- 古勇,苏宏业. 循环神经网络建模在非线性预测控制中的应用. 《 控制与决策 》 , 2000
- 夏国清等. 基于DRNN神经网络的PD混合控制技术在船舶动力定位系统中的应用. 《 中国造船 》 , 2006
- 张剑,屈丹,李真. 基于词向量特征的循环神经网络语言模型. 《 模式识别与人工智能 》 , 2015
查看全部