Spring Batch 测试以及问题记录
研究Spring Batch,期间的问题在此记录
工具以及环境:
Eclipse neon
JDK1.8
Spring boot 1.5.3.RELEASE
Spring
Spring Batch
Oracle 11g
图表工具:Echarts 3
1、初始化脚本
之前搭建了一个使用hibernate和JPA的版本,项目启动的时候会自动创建batch相关的表,一共是5张。之后又搭建了一个去掉hibernate和JPA的版本,这个版本不会自动创建表,需要配置一下。
在datasource.properties中添加配置项:
batch.schema.script=classpath:/org/springframework/batch/core/schema-oracle10g.sql
当然,也可以自己写sql脚本,将这个路径换成自定义脚本的位置即可。
1.使用XML方式
如果是用XML的方式配置,按照如下办法:
a、在batch的配置文件中添加JDBC的namespace
b、添加如下配置:
data-source:
A reference to a data source that should be initialized. Defaults to "dataSource".
需要初始化的DataSource的引用,默认值为“dataSource”
ignore-failures:
Should failed SQL statements be ignored during execution?
执行期间执行失败的sql是否需要被忽略?默认值:NONE。可选值:NONE , DROPS , ALL
enabled:
Is this bean "enabled", meaning the scripts will be executed? Defaults to true but can be used to switch on and off script execution depending on the environment.
这个bean是否可用?意思就是这个脚本是否会被执行?默认为 true ,但可以根据环境切换脚本是否执行。
这里说明一下:因为我创建datasource的时候使用的DataSourceFactory是需要通过传入Properties文件才能创建DataSource,而并不是直接创建的DataSource,所以这里引入Properties文件并不是通过placeholder方式,而是
2.使用JAVA CONFIG方式
1.在batch的config类中添加注解,引入Priperties文件,
2.引入脚本
3.定义DataSourceInitializer的bean
@PropertySource("classpath:datasource.properties")
public class AppConfig {
@Value("${batch.schema.script}")
private Resource schemaScript;
@Bean
public DataSourceInitializer dataSourceInitializer(final DataSource dataSource) {
final DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(databasePopulator());
return initializer;
}
private DatabasePopulator databasePopulator() {
final ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(schemaScript);
return populator;
}
}2、ORA-08177
在启动的时候项目报ORA-08177,无法连续访问此事物处理。看了一下日志,发现是操作batch的相关表的时候出现的,查询资料说是事物的默认级别引起的。根据spring的官方文档4.3.1章节: Transaction Configuration for the JobRepository
The default isolation level for that method is SERIALIZABLE, which is quite aggressive: READ_COMMITTED would work just as well; READ_UNCOMMITTED would be fine if two processes are not likely to collide in this way. However, since a call to the create* method is quite short, it is unlikely that the SERIALIZED will cause problems, as long as the database platform supports it. However, this can be overridden:
需要将ORACLE默认级别改为READ_COMMITED。
a.使用XML方式
1.定义TransactionManager,
2.配置jobRepository,并修改事物级别
3.配置jobLauncher
b.使用JAVA CONFIG方式
使用这种方式需要多配置一个JobOperator,和xml一样,也是在配置JobRepository的时候修改事物的级别。
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource){
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "jobRepository")
public JobRepository getJobRepository() {
JobRepositoryFactoryBean factoryBean = new JobRepositoryFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setTransactionManager(txManager);
factoryBean.setIsolationLevelForCreate("ISOLATION_READ_COMMITTED");
factoryBean.setTablePrefix("BATCH_");
try {
factoryBean.afterPropertiesSet();
return factoryBean.getObject();
} catch (Exception e) {
logger.error("JobRepository bean could not be initialized");
throw new BatchConfigurationException(e);
}
}
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor = new JobRegistryBeanPostProcessor();
jobRegistryBeanPostProcessor.setJobRegistry(jobRegistry);
return jobRegistryBeanPostProcessor;
}
@Bean
public JobLauncher jobLauncher(JobRepository jobRepository) {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
return jobLauncher;
}
@Bean
public JobOperator jobOperator(JobExplorer jobExplorer,JobLauncher jobLauncher,ListableJobLocator jobRegistry,JobRepository jobRepository) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobLauncher(jobLauncher);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobRepository(jobRepository);
return jobOperator;
}参考链接: Spring Batch - ORA-08177
3、Schedule 不执行
因为是测试性能,所以多定义了一个schedule来定时输出一些监控的数据,使用xml配置的时候没有问题,但是写成javaconfig里总是监控的那个schedule不执行,只是很偶尔才会执行一次,也没有任何报错。xml方式配置如下:
那个pool-size引起了我的注意。
难道是因为线程池的原因?找到一篇资料,上面说schedule是单线程,而我配置的schedule,batch的是
@Scheduled(fixedRate = 1)@Scheduled(fixedRate = 200)
于是按照资料上添加了配置,果然奏效。
添加了一个类:
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.SchedulingConfigurer;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
import org.springframework.scheduling.config.ScheduledTaskRegistrar;
@Configuration
public class SchedulingConfigurerConfiguration implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(100);
taskScheduler.initialize();
taskRegistrar.setTaskScheduler(taskScheduler);
}
}然后再次运行,果然没问题了。
参考链接: What is the default scheduler pool size in spring-boot?
4、关于Druid和Tomcat自带连接池的性能
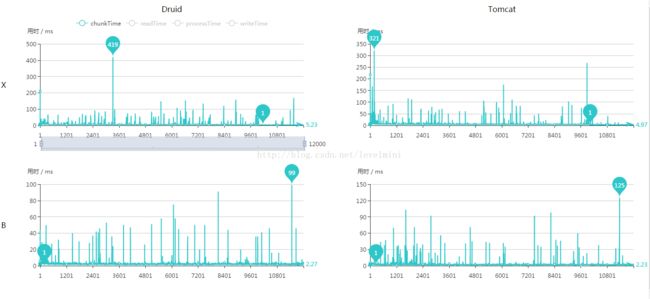
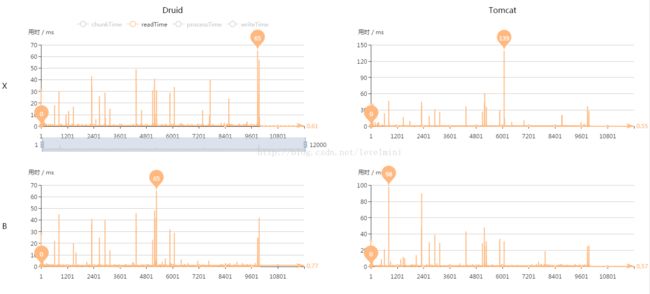
项目需求,读数和取数都需要使用存储过程,测试使用1W条数据,读取出来之后转换成另外一个bean再存入数据库另外一个表中。之前使用带hibernate和JPA版本的batch,测试发现,相同配置下,使用druid速度比tomcat自带pool快近一倍。不知道是什么原因引起的。现在使用了不带hibernate和JPA的版本,测试发现其实二者并没有显著区别。
测试结果如图:
说明:Druid列表示此列为Druid连接池测试结果。Tomcat列表示此列为Tomcat自带连接池测试结果。X行表示此行使用XML配置,B行表示此行使用JAVA CONFIG方式配置。
1.性能总图:

2.单次处理-chunkTime
3.单次处理-readTime
 ‘’
‘’
4.单次处理-processTime

5.单次处理-writeTime
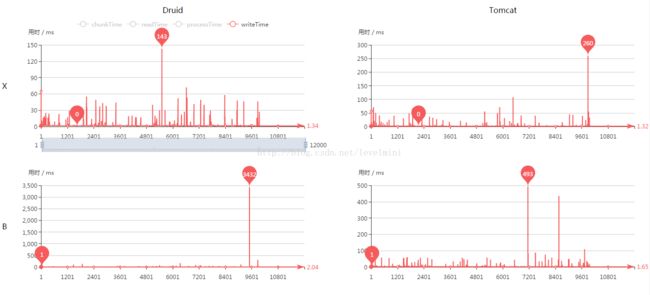
从上面几张图看出,druid和tomcat自带连接池不分伯仲。几乎同时完成了测试。在6分钟之内完成了读库-处理-写库的操作。并且完成时间相差不到5秒。至于为什么上一个版本相差很多,还有待研究。
不定期更新中。。。