[深度学习]RCNNs系列(2)RCNN介绍
RCNN是整个RCNN系列的开端,也是使用卷积神经网络进行目标检测的一类重要方法的开端,下面我们来看一下RCNN算法。
RCNN是rbg大神在2013年发表的《Rich feature hierarchies for accurate object detection and semantic segmentation》一文中提出的算法,其实算法的思想在现在来看非常的简单,而且也很容易想到,然而这个算法一出却极大的提升了检测的效果。
1. RCNN的检测流程
RCNN主要分为3个大部分,第一部分产生候选区域,第二部分对每个候选区域使用CNN提取长度固定的特征;第三个部分使用一系列的SVM进行分类。
下面就是RCNN的整体检测流程:
![[深度学习]RCNNs系列(2)RCNN介绍_第1张图片](http://img.e-com-net.com/image/info8/70965f325fb14352ac7f6ab885936feb.jpg)
(1)首先输入一张自然图像;
(2)使用Selective Search提取大约2000个候选区域(proposal);
(3)对每个候选区域的图像进行拉伸形变,使之成为固定大小的正方形图像,并将该图像输入到CNN中提取特征;
(4)使用线性的SVM对提取的特征进行分类
下面我们来分布介绍这几个步骤。
1.1 候选区域的产生
这里介绍的比较简单,RCNN使用Selective Search算法提取图像中的候选区域(因为我关注RCNN系列比较晚,直接应用的Faster RCNN,就没有关注Selective Search算法,这里也就不介绍了)
1.2 CNN特征提取
作者使用AlexNet对得到的候选区域的图像进行特征提取,最终生成的是一个4096维的特征向量。注意AlexNet输入的是227x227大小的图像,因此在输入到AlexNet之前,作者把候选区域的图像首先进行了一小部分的边缘扩展(16像素),然后进行了拉伸操作,使得输入的候选区域图像满足AlexNet的输入要求(即227x227)。
作者在这里其实进行了一部分实验,考虑怎样使候选区域图像满足AlexNet的输入要求,在文章的附录A中进行了介绍,以下是附录A中实验的三种方法:
![[深度学习]RCNNs系列(2)RCNN介绍_第2张图片](http://img.e-com-net.com/image/info8/e6e1e295a948460e8f4106ac4fd38f15.jpg)
最终作者选择的是D中的直接拉伸的方法。
1.3 SVM特征分类
好吧,作者论文里并没有介绍怎么进行SVM的特征分类,不过要注意的是作者为每个类都训练了一个SVM分类器,在训练/检测的过程中使用这些分类器为每一类进行分类。
2. 训练与测试阶段
2.1 应用测试阶段
在测试阶段,首先使用selective search提取测试图像的2000个proposals,然后将所有proposal图像拉伸到合适的大小并用CNN进行特征提取,得到固定长度的特征向量。最终对于每个类别,使用为该类别训练的SVM分类器对得到的所有特征向量(对应每个proposal图像)进行打分(代表的是这个proposal是该类的概率)。
注意到这里作者应用了一次NMS(非最大值抑制),具体来说就是对每一类而言,若一个proposal与一个分值比它大的proposal相交,且IoU(intersection over union,即相交面积比这两个proposal的并集面积之比)大于一定阈值的情况下,则抛弃该proposal。
作者对测试阶段的时间进行了分析,认为RCNN的优势在于:(1)CNN中共享网络参数(CNN本身特性);(2)CNN提取后的特征维度较低(相比之前的方法),计算更快。
2.2 训练阶段
2.2.1 ImageNet预训练阶段
作者首先在ImageNet上进行了CNN的预训练,由于VOC 2012中训练数据较少(相对而言),所以使用ImageNet预训练然后再fine tune效果会更好。
2.2.2 Fine-tuning(微调)阶段
在微调阶段,作者把ImageNet上预训练的网络从1000个输出改为21个输出(VOC的20类+1类background),然后将所有与groundtruth的包围框的IoU>= 0.5的proposal看作正类(20类之一),其他的全部看作背景类。在训练时使用随机梯度下降(SGD),学习率为0.001,在训练的过程中随机选取32个postive样本和96个negative样本,这样选择是因为在提取的proposal中background样本要远远多于postive样本。
2.2.3 SVM分类器训练阶段
在训练SVMs的过程中,作者把IoU低于0.3的proposal设置为negative样本,对于postive则是groundtruth的包围盒图像。作者对每个类别都训练了一个线性的SVM分类器,由于训练图像过多,同时为了保证训练的效果,所以作者在训练的过程中采用了hard negative mining方法(hard negative mining训练方法在我看来就是通过训练挑出训练集中那些总是被识别错误的负样本作为训练集)。
作者的文章的附录B中讨论了两个问题,这里我也简单介绍一下:
(1)为什么fine-tuning时采用的IoU阈值和SVM训练时采用的阈值不同呢?
首先作者承认,在实验开始他们并没有fine-tuning的过程,而最开始使用SVM训练时阈值就是0.3,在后面的实验中加入finetuing以后,采用相同的阈值发现效果比使用现在的0.5阈值要差很多。作者的猜想是阈值的设置并不是很重要,而是微调时数据量的问题,在微调时采用0.5阈值的话会出现很多所谓的“抖动”的样本,这些样本于groundtruth的IoU在0.5到1之间,采用0.5的阈值以后正样本增加了30倍,所以fine-tuning时训练数据增多,效果会更好。
(2)为什么不直接使用CNN的分类结果,而还要继续训练若干个SVM分类器呢?
作者也直接使用CNN分类结果进行了实验,发现效果相比SVM有所降低,他发现使用CNN直接分类结果并不注重于精确定位(我觉得这个情况很合理,因为CNN识别能力非常强大,非常的鲁棒,所以不是那么精确的定位也可以得到比较好的结果,所以不注重精确定位)第二个原因在于SVM训练时采用的hard negative mining选择的样本比CNN中随机选择的样本要好,所以结果会更好。作者也提出,可能通过更改fine-tuning的一些细节可以提升效果(他们也是这么做的,Fast RCNN中他们改变了loss函数)。
3. Bounding-box回归
这里需要重点提一下的是,作者在完成了前面提到的“生成候选区域——CNN提取特征——SVM进行分类”以后,为了进一步的提高定位效果,在文章的附录C中介绍了Bounding-box Regression的处理。
Bounding-box Regression训练的过程中,输入数据为N个训练对
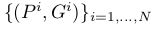 ,其中
,其中
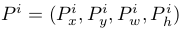 为proposal的位置,前两个坐标表示proposal的中心坐标,后面两个坐标分别表示proposal的width和height,而
为proposal的位置,前两个坐标表示proposal的中心坐标,后面两个坐标分别表示proposal的width和height,而
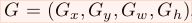 表示groundtruth的位置,regression的目标就是学会一种映射将P转换为G。
表示groundtruth的位置,regression的目标就是学会一种映射将P转换为G。
作者设计了四种坐标映射方法
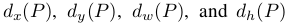 ,其中前两个表示对proposal中心坐标的尺度不变的平移变换,后面两个则是对proposal的width和height的对数空间的变换,文章中的映射方式为:
,其中前两个表示对proposal中心坐标的尺度不变的平移变换,后面两个则是对proposal的width和height的对数空间的变换,文章中的映射方式为:
![[深度学习]RCNNs系列(2)RCNN介绍_第3张图片](http://img.e-com-net.com/image/info8/1b6993003ab44cbf986caae1c7523d20.jpg)
其中
 表示对该proposal的Pool5层提取的特征
表示对该proposal的Pool5层提取的特征
 进行线性变化操作,即
进行线性变化操作,即
 ,最终的优化方法为:
,最终的优化方法为:
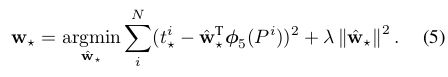
其中
![[深度学习]RCNNs系列(2)RCNN介绍_第4张图片](http://img.e-com-net.com/image/info8/46310787ca174b1097fa83197cf22804.jpg)
这是一个典型的最小二乘问题。
最终在进行实验时,lambda = 1000,同时作者发现同一对中P和G相距过远时通过上面的变换是不能完成的,而相距过远实际上也基本不会是同一物体,因此作者在进行实验室,对于pair(P,G)的选择是选择离P较近的G进行配对,这里表示较近的方法是需要P和一个G的最大的IoU要大于0.6,否则则抛弃该P。
其实现在RCNN应用已经非常少了,我这里重点介绍回归的原因就是以后的RCNN系列将这个回归的过程作为一个loss函数加入到了卷积神经网络中,他们的做法与这里的非常相似。