go爬虫爬取boss直聘岗位信息
主要是通过goquery三方包发送请求,然后解析返回的数据,再用excelize三方包写入excel文件。
说明:
1、代码中给定的的查询条件为C++,展示结果也是过滤C++后相关的岗位,请求第一页的url格式为:https://www.zhipin.com/c101280600-p100102/?query=C%2B%2B&page=1&ka=page-1,
只需将改动最后的page=1&ka=page-1变成page=2&ka=page-2,即url变为:https://www.zhipin.com/c101280600-p100102/?query=C%2B%2B&page=2&ka=page-2
就是请求过滤条件为C++的第二页的岗位信息。
2、对于网站返回的结果,我们只需要提取部分有用的信息即可,每一页的每一个岗位信息在一个li标签里面,如下:
 郭先生招聘者
郭先生招聘者像class=“job-title"标签下的岗位名称就是我们需要的,通过selection.Find(”.job-title").Text()提取即可,其他字段也是类似。
3、目前代码中在发送请求时使用了随机User-Agent的方式,但是对boss直聘没有作用,需要使用代理ip才能解决访问过于频繁而被禁止访问的问题,本利中的代码一般运行一两次就会提示2小时内禁止访问。本例子纯属于练手,就没有纠结这一块了,不过使用免费的ip代理,确实有一定的作用但不稳定。
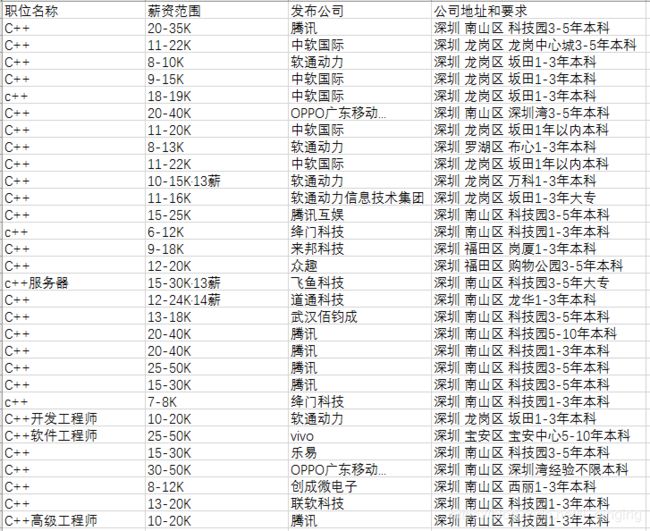
4、目前只展示了部分信息,列入职位详细的信息可以根据a标签下的job_detail部分拼接完整的url在请求,然后在解析数据就能拿到职位详细信息。这里不做演示。完整代码以及爬取结果如下:
package main
import (
"fmt"
"github.com/excelize" //读写excel文件
"goquery"
"math/rand"
"net/http"
"os"
"strconv"
)
func WriteData2Excel(filename string, sheet string, data map[string]string){
file, err := excelize.OpenFile(filename)
if err != nil{
fmt.Println("OpenFile ",filename, " error:",err)
}
for k,v := range data{
file.SetCellValue(sheet, k ,v)
}
err2 := file.SaveAs("./"+filename)
if err2 != nil {
fmt.Printf("f.SaveAs err:%s",err2)
}
}
func InitExcel(filename string, sheet string, header map[string]string){
file := excelize.NewFile()
index := file.NewSheet("Sheet1")
file.SetColWidth(sheet, "A", "D", 20)
file.SetColWidth(sheet, "D", "D", 30)
for k,v := range header{
file.SetCellValue(sheet, k, v)
}
file.SetActiveSheet(index)
err := file.SaveAs("./"+filename)
if err != nil {
fmt.Printf("f.SaveAs err:%s",err)
}
}
func Write2Excel(filename string, sheet string, httpurl string, i int, page chan<- int){
fmt.Printf("正在爬取第%d页,url=%s\n", i, httpurl)
my_headers := []string{"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "}
request,_ := http.NewRequest("GET", httpurl, nil)
request.Header.Set("Content-Type", "application/json")
request.Header.Set("User-Agent", my_headers[rand.Intn(12)])
request.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
request.Header.Set("Connection", "keep-alive")
doc, err4 := goquery.NewDocument(httpurl)
if (err4 != nil){
fmt.Println(err4)
}
doc.Find("div[class=job-list]").Find("ul").Find("li").Each(func(j int, selection * goquery.Selection){
jobTitle := selection.Find(".job-title").Text()
jobSalary := selection.Find(".red").Text()
jobCompany := selection.Find(".company-text").Find("h3").Find("a").Text()
jobCompanyAddr := selection.Find(".info-primary").Find("p").Text()
dataIndex := strconv.Itoa(j+2)
data := map[string]string{"A"+dataIndex:jobTitle,"B"+dataIndex:jobSalary,"C"+dataIndex:jobCompany,"D"+dataIndex:jobCompanyAddr}
WriteData2Excel(filename, sheet, data)
})
page <- i
}
func doWork(httpurl string, start int, end int){
//创建一个通道用于同步
page := make(chan int) //无缓冲
fmt.Printf("开始爬取第%d页到第%d页的数据。。。。\n", start, end)
//创建结果文件夹
err := os.Mkdir("Result", os.ModeDir)
if err != nil {
fmt.Println("os.Mkdir err=",err)
}
//修改工作目录
err2 := os.Chdir("Result")
if err2 != nil {
fmt.Println("os.Chdir err2=",err2)
return
}
header := map[string]string{"A1":"职位名称","B1":"薪资范围","C1":"发布公司","D1":"公司地址和要求"}
for i := start; i <= end; i++ {
httpurl := httpurl + strconv.Itoa(i) + "&ka=page-" + strconv.Itoa(i)
filename := "jd"+strconv.Itoa(i)+".xlsx"
sheet := "Sheet1"
InitExcel(filename, sheet, header)
go Write2Excel(filename, sheet, httpurl, i, page)
}
for j := start; j <= end; j++ {
fmt.Printf("第%d页爬取完成!\n", <-page)
}
}
func test1(){
var start int = 1
var end int = 20
var httpurl string = ""
httpurl = "https://www.zhipin.com/c101280600-p100102/?query=C%2B%2B&page="
doWork(httpurl, start, end)
}
func main(){
test1()
}

郑重声明:本文示例纯做学习,不可用作任何商业用途。