区块链相关论文研读3- 关于超级账本Hyperledger Fabric的性能优化
这是2019年6月发表在顶会Sigmod上面的论文,论文题目为《Blurring the Lines between Blockchains and Database Systems: the Case of Hyperledger Fabric》,第一作者为Ankur Sharma。
本人这段时间要大量阅读顶刊顶会论文,在阅读论文的同时跟大家分享所提炼出来的论文内容,达到加深理解以及共同探讨研究和学习的目的。关注本人的知乎或者专栏可以获得最新的更新通知哦 =-=
论文的问题描述
- 总体上来讲,这篇论文是针对Hyperledger Fabric的吞吐量的优化。超级账本的客户端所发起的所有的交易中,无有效/无有意义的交易的所占的比例很大。很多种情况会使一个交易无效,比如恶意篡改,脏数据读取(如果正常提交的交易在这个过程中涉及的数据发生了变化)。下图所示,客户端发送空白交易成功的比例是100%,而非空白的交易中,很大一部分是无效的,最总能够写入账单中的交易只占其中的一部分(这里使用空白交易实验对比)。

上面是论文所解决问题的总体方向,但是,具体所要解决的问题是什么呢?先得了解Hyperledger交易的处理流程了。下面给以简单介绍:
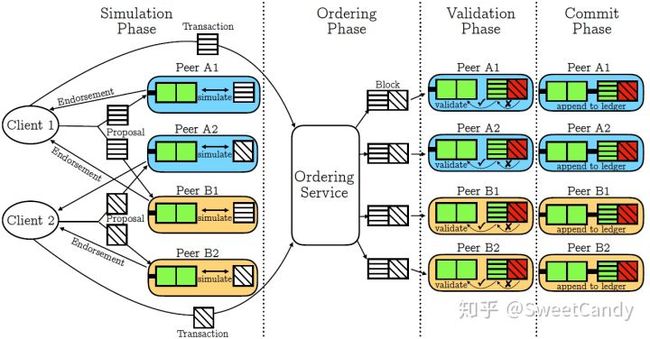
在超级账本中,一个交易从被发起到最终写入账本中需要经历四个阶段,分别是模拟背书,排序,验证和提交。在模拟阶段,客户端产生交易,并发给多个peers节点,每一个peer节点进行模拟背书操作之后,都向客户端返回一个读写集合以及自己的签名,客户端把所收到的数据发给排序服务Ordering Service,进入排序阶段。排序服务不会读取交易中的内容,只是将所收到的交易数据按照接收顺序排序和打包,然后发给各个peer,进入验证阶段。各个peer节点验证各个交易数据是否有效。在目前版本的实现中,无效交易也会保留在区块中,可以通过区块记录的元数据确定哪些是无效交易。无效交易的读写集不会提交到状态数据库中,不会导致状态数据库发生变化,只是会占用区块的大小,占用记账节点的硬盘空间。后续的版本会实现账本的精简,过滤掉无效交易。
了解了超级账本的交易流程之后,我们发现一个问题,那就是交易的有效性是在第三阶段检查的。如果无效交易比较多,就会影响系统的吞吐量。就比如排了半天的队,快要轮到你的时候才跟你说要打烊了,是不是觉得很恼火,为什么不早点告诉我呢?如果我们在第一和第二阶段也进行针对无效交易的检查,也就是把部分检查提前,而不需要等到交易跑了大半个流程之后才将其标定为无效的,就可以在一定程度上提高系统的吞吐量了。那么,具体如何将无效交易的检查提前呢?这也就是这篇论文主要解决的具体问题了。
论文的贡献点
本片论文的贡献点主要有两个:(1)transaction reordering (2)early transaction abort. 也就是交易重排序和提前中断交易。
下面分别对这两个贡献点进行分析
贡献点一:交易重排序
问题描述:
一个交易包含读集和写集,都是以键值对的方式出现,读集表示需要读取的数据的键和值,比如交易T2的需要读取的数据为(k1,v1)和(k2,v1); 写集表示需要写入或者更新账本的集合,比如交易T2需要将键为k2的值从v1改为v2。
下表中,因为第一个交易T1已经把键为k1的值从v1改为v2,而交易T2,T3和T4读取的却是k1对应的老数据(脏数据)(从Read Set中看出),所以,这后面到来的三个交易都是无效的。这里使用 表示它们的顺序关系。
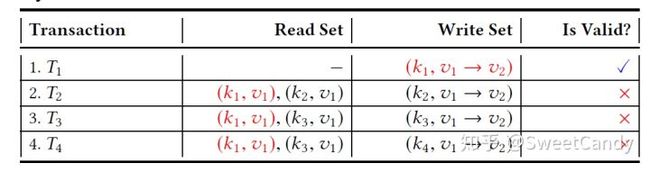
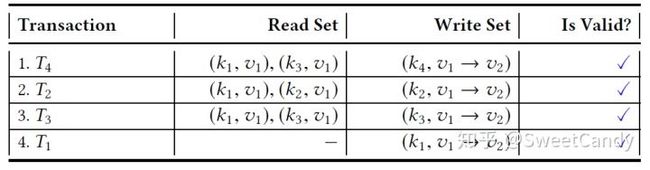
而如果交易产生的顺序为 ,就不会有这个读脏数据的问题。这时候,四个交易都是有效的。所以,交易的顺序很重要。
因此,首先需要分析同一个区块中的交易数据,找出相互冲突的交易,比如交易之间形成了环,然后进行有效性排序来避免冲突,减少无效交易。如下图,一个区块中的交易很可能存在这样读写冲突的情况。

怎么解决这些冲突呢?算法为:
(1)对这个区块中的所有交易建立一个冲突图。
(2)找到这个图中所有的环。
(3)标记每一个交易在这些环中出现的次数
(4)从出现次数最多的交易开始,增量地中断该交易,直到所有的环都解除了。
(5)构建合理的交易顺序。
下面结合具体的例子讲解上面的算法:
下面的两个表格分别是一个区块中所有交易的读集和写集。值为1表示对相应键为Ki的值进行了读或者写。
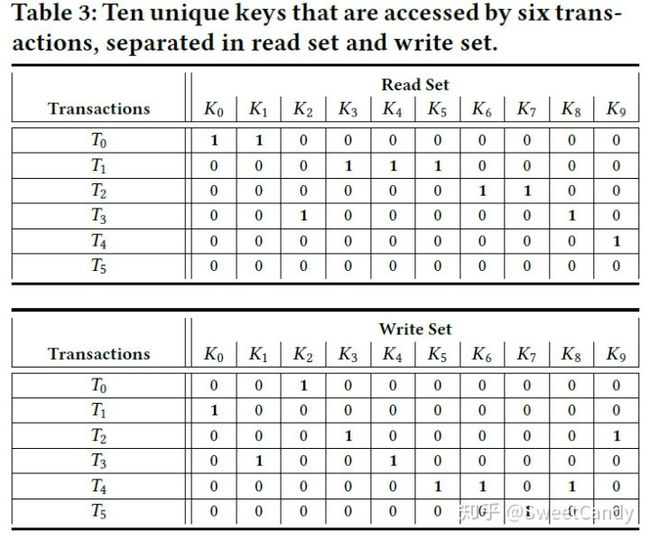
根据上面两个表格,我们做二进制与&的操作,很容易得到下面冲突图
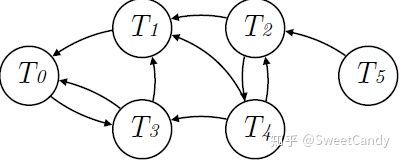
- 利用算法Tarjan's algorithm可以将上面的冲突图分解成多个强连通图。强连通图是指其中的每一个节点都可以到达其它节点的图。
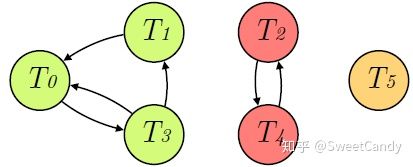
- 使用Johnsons算法从强连通图中得到所有的环。分别为:
- 对上面这三个环,我们可以建立下面这个表格,用于标记每一个交易出现的总次数
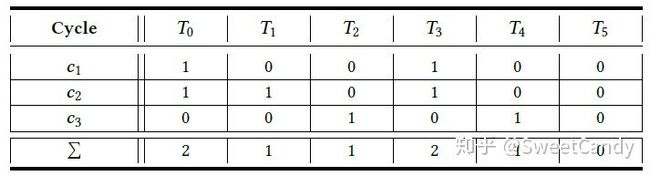
从出现次数最大的交易开始,将该交易从区块中移除,将包含该交易的所有环从上面表格中移除,同时对于出现在该环上面的交易,相应的减少它们的出现次数。重复上面过程直到上面表格为空。上面T0和T3的次数都是2,这里选择交易下标编号较小的一个,首先选择T0。将第一个和第二个环从表格中移除,移除交易T0,相应的,T3的次数也相应减少为0。现在上面表格只剩下环c3,将环3移除,移除交易T2。此时表格中没有环了,算法结束。
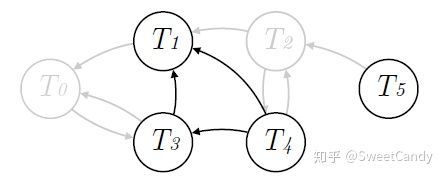
- 我们得到下面没有环的图。接下来就是构建交易顺序了。合理的交易顺序应该是无读写冲突的,为 。T0和T2被当作无效的交易已经被移除出区块了。
这就是交易重排序的算法了。
在Hyperledger Fabric的重排序阶段,接收多少个交易之后才能打包成一个区块呢?在Fabric中,如果满足下面三个条件之一,就将所接收到的所有交易进行打包。
- 达到一定数量的交易。
- 达到了一定的数据大小。
- 从接收到这些交易的第一个交易开始,已经过去了一定的时间。
结合上面的算法,为了避免上面表格Table3中的不同key的数量太多,影响算法性能,论文提出增加一个打包条件:
- 所接收到的所有交易中的不同key集合达到一定的数量。
论文贡献点2:提前中断交易
在传统数据库系统中,当要修改一个数据的时候,可以通过加同步锁的方式,这样其它客户端就不会读取到脏数据了。而在Hyperledger Fabric中,可以通过版本号来实现同步,避免使用同步锁。一个版本号包含一个进行更新操作的交易ID和区块的Id。如果一个操作要把一个数据更新,它需要更新该数据的版本号。另一个操作读取该数据,在模拟阶段会检查该数据是不是被更新过,如果被更新过,就能够知道该交易是无效的。
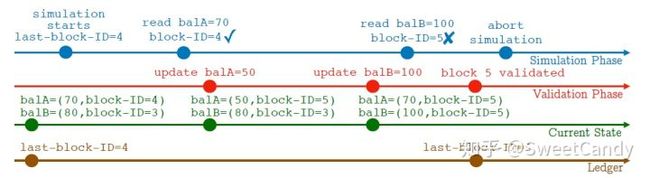
论文举了一个例子,如上图所示,看上面两条线,它们分别表示并行的两个阶段,模拟阶段和验证阶段。一开始的时候,最新的block id是last-block-id = 4,表示最新被验证通过的区块。第一个在模拟阶段的读操作读取balA=70成功。接下来在验证阶段将balA修改为50,同时将balB修改为100。如果这时候在模拟阶段要读取balB的值,那么对应的交易将是无效的,因为此时last-block-id是4,而更新block-id为5, 4 < 5。意思是在区块id为5的区块中的交易将这个值修改了,但是该区块还没验证通过。当该区块验证通过,那么last block id将变为5.
总结:本论文通过交易重排序和提前中断交易两种方式来提高Hyperledger Fabric的吞吐量。论文给出了详细且准确算法描述。18页的论文通篇读下来,感觉自己又长见识了!
谢谢!
都读到这里了,给一个赞呗 = =