redis的冷热数据处理
参考:https://blog.csdn.net/rlnLo2pNEfx9c/article/details/81091547
阿里云提供redis混合存储产品,链接:
当前KV数据库从存储介质可以分为两种模式,一种是以内存为主持久化为辅,如memcache(无持久化)、redis等;一种是以持久化为主内存为辅,如ssdb(基于leveldb/rocksdb存储引擎)。这两种模式代表了两种不同的选择策略和哲学,适应不同的业务场景。简单地说,以内存为主的模式侧重高性能,信奉“内存是新的硬盘”的哲学;以持久化为主的模式则侧重大容量,兼顾性能。
对于以持久化为主的模式,因其天然支持大容量数据的快速读写,实现冷热数据分离是相对比较容易的,当前用到的数据就认为是热数据,只要把热数据保留于指定大小的内存即可。而对于以内存为主的模式,即使有持久化,也只是顺序写的持久化,在需要读硬盘时不能做到快速读取。因此这种模式要实现冷热分离,需要准确区分冷热数据、精心设计落地策略并保证可以快速读取。
这里冷热分离方案主要基于redis或者基于redis协议及命令实现。
二、方案汇总
2.1 方案一 改造redis,使之支持冷热分离
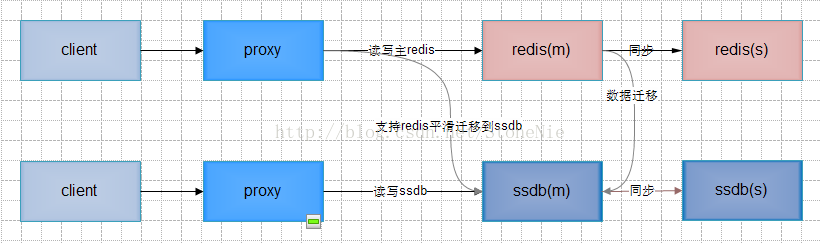
l 实现描述:
ü 可以使用开源的rocksdb或lmdb引擎读写落地数据;
ü 写操作全部记录在内存,不同步写磁盘;
ü 常驻写子进程定时将内存中的数据写到磁盘;
ü 内存中标记不存在的key,如果一个key在磁盘上不存在,则在标记之后不用再去磁盘查看这个值是否存在;
ü 读操作先读内存,如内存中不存在且key未被标识磁盘不存在,则由读子进程从磁盘读并写回到redis(key不存在才写回)。之后子进程通知主进程再次读取,此过程会阻塞主进程上单个连接的处理。
l 优点:真正意义上实现单机redis的冷热分离。Redis和落地数据在同一台机器,容易保证数据一致性。
l 缺点:实现较复杂。因为是基于redis做二次开发,后续不方便升级redis,不过单机redis已经非常稳定,后续升级可能性较小。
l 分析:
redis定位是内存KV数据库,只支持所有数据存放在内存,持久化只是数据安全性的一种保障方式。基于redis做冷热分离的例子有两个,一个是v2.0-2.4版的原生redis,一个是jimdb S,这两个做得都不成功。
redis 2.0版加入支持VM机制,VM机制即虚拟内存机制,参考操作系统的虚拟内存机制实现,暂时把不经常访问的数据从内存交换到磁盘中,需要时再从磁盘交换回内存,可以实现冷热数据分离。但由于VM机制在某些情况下会导致redis重启、保存和同步数据等太慢及代码复杂,所以2.4版后就不再支持了。
Jimdb S是京东云平台基于redis2.8实现的KV数据库,用SSD持久化数据。使用Jimdb S可以保存全量数据,把缓存+数据库的两层架构用一层架构取代。写操作时先写内存,再异步写cycledb。读操作如数据不在内存,则创建后台任务读cycledb。这个后台任务的作用是预热,读到数据后并不把结果载入内存,执行完成后由前台主线程再次读取,这次在内存中读不到则直接读取cycledb并载入内存。目前了解到的情况是使用不广泛,而且即将下线。主要原因是性能不如纯内存的redis,但不知道是否还有其它缺陷。
从以上redis删除VM机制和jimdb S的实践情况看,直接改造redis做冷热分离可能并不是一个很好的发展方向,即使做出来也很可能是一个平庸的产品。最根本的原因是纯内存的redis性能更好,而用户对性能的期望是没有最好,只有更好。随着内存越来越大、越来越便宜,更多的数据可以直接放到内存,会进一步导致冷热分离成为一个鸡肋功能。另外一个原因是实现冷热分离会导致redis代码复杂性增加不少,不利于后续的维护。
方案二 改造备redis和proxy,备redis落地数据

l 实现描述:
ü 写操作时proxy正常写主redis,由改造备redis写rocksdb;
ü 读操作时proxy先正常读主redis,如无数据,则读改造备redis;改造备redis在内存中读不到数据则读rocksdb,proxy从改造备redis读到数据再写主redis。
l 优点:写操作和当前流程完全一样;读操作和当前迁移流程中rrw流程基本一致,可以复用。不影响纯内存的原生redis使用,风险可控。
l 缺点:proxy和redis均需修改。在原有一主一备redis基础上需要增加改造备redis部署。
l 分析:
最大特点是不影响纯内存的原生redis使用,且proxy改动较小。
可以视情况选择部署一个或两个改造备redis。只部署一个改造备redis时落地数据是单点,可用于数据丢失不重要或后端另存有全量数据的场景。部署两个改造备redis可以避免单点,因为是链式同步,对主redis几乎无影响。
方案三 改造proxy,使用ssdb落地数据
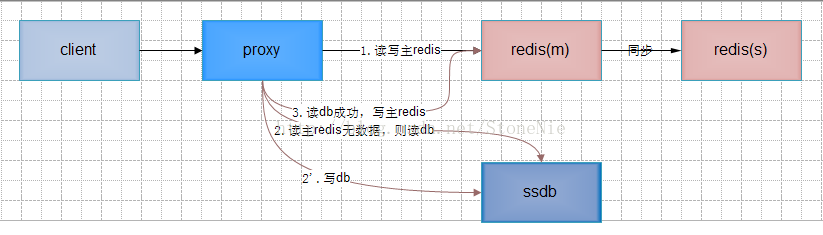
l 实现描述:
ü 写操作时proxy先正常写主redis,再同步或异步写ssdb;
ü 读操作时proxy先正常读redis,如redis无数据,则读ssdb;读ssdb成功,再写主redis。
l 优点:只改proxy,redis无须改动。
l 缺点:proxy实现较复杂,redis和ssdb的数据一致性不好保证。因为ssdb基于leveldb/rocksdb实现,在读操作且redis中无数据且ssdb内存中无数据时,可能极大影响性能。
方案四 提供ssdb,业务选择接入redis或ssdb

实现描述:redis和ssdb独立两套系统,类似之前腾讯提供CMEM和TSSD两套系统。业务开发根据业务特点决定使用哪一套系统。client,proxy可以复用,等同可以选择使用redis存储引擎或leveldb/rocksdb存储引擎。
优点:无须开发,只需引入ssdb系统即可
缺点:业务开发可能没办法一开始确定使用哪一套系统。需要维护和运维两套系统
方案五 提供ssdb,业务初始化接入redis,可选择平滑迁入ssdb
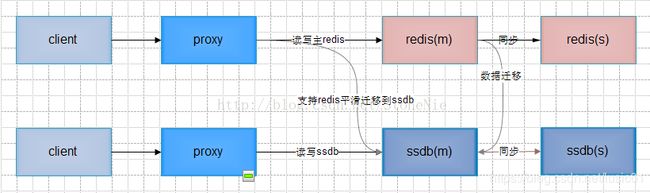
实现描述:类似方案四,但可选择从redis平滑迁入ssdb
优点:只需开发proxy支持迁入ssdb系统即可
缺点:需要维护和运维两套系统
三:通用问题
1,读操作且redis中无数据的性能问题
不管是直接基于leveldb/rocksdb做数据落地,还是使用ssdb,都会碰到读操作且redis中无数据的性能问题,因此此时需要先读取redis,redis中读不到再一个level一个level去读磁盘文件,这种情况的性能可想而知不会太好
2,redis的淘汰
redis区分冷热数据都是设定redis的maxmemory,然后进行lru淘汰使内存中只保留热数据,而redis的lru淘汰只是从随机选的一些key选出最符合lru规则的一个key进行淘汰,即只是一种近似淘汰,所以不能很好地区分冷热数据。因此有可能出现被lru淘汰的key实际并不是冷数据,这样下次读取时会因为redis中已无数据而去磁盘读,出现一些性能问题。
3,写操作先写内存还是先写磁盘
先写内存,此时如果系统奔溃,内存中的数据还没来得及dump到磁盘,会丢失数据。先写磁盘,再写内存,则即使系统崩溃,不会造成数据的丢失,但可能导致磁盘和内存数据的不一致,为了避免这种不一致,又得先删除内存中的key,再写磁盘,再写内存,影响性能。总的来说,对于以内存为主的KV数据库,优先选择先写内存。
SSD应用风险
为了提高读写磁盘的性能,需要使用SSD。而SSD本身存在一些问题:
毛刺问题:同时读写SSD盘时,读SSD盘有可能会耗时数秒。被挂住的几率为万分之一;
坏盘问题:SSD坏盘几率比普通sas硬盘要高
坏块问题:SSD盘中可能存在某个块可以写入,但是读不出来,此时这个块的数据将会丢失
(
毛刺问题:
最近收到一封邮件,对于线上磁盘使用出现毛刺的分析。
话说某天,磁盘使用的监控出现多个毛刺,每秒读的大小为20M/S,造成的影响就是响应时间慢,用户体验不好。于是开始了分析的过程,通过查看毛刺出现点的web server日志,发现这个时候多是在处理查询的请求,于是开始进一步探索这个时候的查询都分别是对哪些表,什么动作行为的查询?查看得知,此时最多的查询请求是对我们item表--记录当前资源信息的表的查询,于是,想到,对表的查询,速度慢,原因是啥呢?索引?数据量大?分区,分表不合理?于是,对该表的信息进行查询,发现该表当前存在13W条左右的数据,占据的磁盘大小为4G+,相当于每一条数据占据的大小为32K,那么做一次全表扫描(全表扫描是数据库服务器用来搜寻表的每一条记录的过程,直到所有符合给定条件的记录返回为止。),,,,,,,这个动作造成的磁盘的IO的确很惊人。通过对DB此时查询执行的sql语句进行分析,进行查询的条件多没建索引,于是尝试建立索引(考虑了该类索引对应的字段内容是不是会经常进行修改,字段类型是不是适合建立索引等)。这些动作做完之后,回归该问题,发现比之前有所改进,但是毛刺还是不理想,于是开始分析,发现我们的环境里面还存在一个情况,就是虽然我们做了上面的操作:合理的建立了索引、将查询的数据分批次执行(不将13w的数据一次性全表扫描),但是环境里面出现多次对item表操作的动作,为什么呢?还是查看日志,发现我们环境里有一台机器不知道为什么,每半分钟就从item表里面拉5次数据,之前这个机器是用来做缓存的,可能当时没有考虑到这样频繁拉到带来的影响,现在已经有了新的替代方案,做了nginx的代理缓存和web缓存,这一层对于db数据的缓存也用了相应的技术解决,于是申请停掉该机器的服务,再次回归,问题回归合理值。读从20M/s回归到0.2M/S。
)