hive学习笔记之-数据操作
1. 导入数据到管理表
因为Hive不支持事务,所以没有行级别的insert,update,delete操作,仅支持使用加载的方式把数据导入到表中。
--加载数据到分区表的例子
LOAD DATA LOCAL INPATH '${env:HOME}/california-employees'
OVERWRITE INTOTABLE employees
PARTITION(country = 'US', state = 'CA');
上面是上一节创建的表语句,如果没分区目录不存在,则建表时会创建../US/CA目录。
如果不是分区表,则可忽略PARTITION子句。
--创建分区管理表
CREATE TABLE IF NOT EXISTS logmsgs1 (
hms INT,
severity STRING,
server STRING,
process_id INT,
message STRING)
PARTITIONED BY (year INT, month INT, day INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
[licz@nticket1 data]$ ls log20
log20140120 log20140120_1
--导入目录下所有文件数据
hive (mydb)>load data local inpath '/app/hadoop/data/log20'
> overwrite into table logmsgs1partition (year = 2014,month = 1,day = 20);
INPATH子句后可以是目录,也可以是单个文件,如果是目录则是导入目录下所有文件的数据。
2. 从查询语句中插入数据
--插入单个分区
--示例1
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'OR')
SELECT * FROM staged_employees se
WHERE se.cnty ='US' AND se.st = 'OR';
--示例2
INSERT OVERWRITE TABLE logmsgs1
PARTITION (year= 2014,month = 1,day = 22)
SELECT hms,severity,server,process_id,message
FROM logmsgs WHERE year = 2014 and month = 1and day=22;
--插入多个分区
--示例1
FROM staged_employees se
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'OR')
SELECT * WHERE se.cnty = 'US' AND se.st = 'OR'
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'CA')
SELECT * WHERE se.cnty = 'US' AND se.st = 'CA'
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'IL')
SELECT * WHERE se.cnty = 'US' AND se.st = 'IL';
--示例2
FROM logmsgs
INSERT OVERWRITETABLE logmsgs1
PARTITION (year= 2014,month = 1,day = 20)
SELECThms,severity,server,process_id,message WHERE day=20
INSERT OVERWRITETABLE logmsgs1
PARTITION (year= 2014,month = 1,day = 21)
SELECThms,severity,server,process_id,message WHERE day=21;
3. 动态分区插入
如果表中有许多分区各方面,按上面插入语句会要写很多的SQL,而且查询语句要对应上不同的分区,这样就插入语句用起来就会很繁琐。
Hive中有这样的支持动态分区插入的功能,它能跟分区字段的内容自动创建分区,并在每个分区插入相应的内容。
SELECT语句中要包含分区字段,如下所示:
INSERT OVERWRITE TABLE employees
PARTITION(country, state)
SELECT ..., se.cnty, se.st
FROM staged_employees se;
示例
--删除原来的分区
hive (mydb)>alter table logmsgs1 drop partition (year=2014,month=1,day=20);
Dropping the partition year=2014/month=1/day=20
hive (mydb)>alter table logmsgs1 drop partition (year=2014,month=1,day=22);
Dropping thepartition year=2014/month=1/day=22
hive (mydb)>show partitions logmsgs1;
year=2014/month=1/day=21
--要动态插入分区必需设置hive.exec.dynamic.partition.mode=nonstrict
hive (mydb)>FROM logmsgs
> INSERT OVERWRITE TABLE logmsgs1
> PARTITION (year, month , day )
> SELECThms,severity,server,process_id,message,year,month,day;
FAILED: SemanticException [Error 10096]:Dynamic partition strict mode requires at least one static partition column. Toturn this off set hive.exec.dynamic.partition.mode=nonstrict
hive (mydb)>set hive.exec.dynamic.partition.mode;
hive.exec.dynamic.partition.mode=strict
hive (mydb)> set hive.exec.dynamic.partition.mode=nonstrict;
--动态插入分区
hive (mydb)>FROM logmsgs
> INSERT OVERWRITE TABLE logmsgs1
> PARTITION (year, month , day )
> SELECT hms,severity,server,process_id,message,year,month,day;
--分区会自动创建
hive (mydb)>show partitions logmsgs1;
year=2014/month=1/day=20
year=2014/month=1/day=21
year=2014/month=1/day=22
同样的,也可以混合dynamic和static分区使用
INSERT OVERWRITE ABLE employees
PARTITION (country = 'US', state)
SELECT ...,se.cnty, se.st
FROM staged_employees se
WHERE se.cnty ='US';
hive (mydb)>FROM logmsgs
> INSERT OVERWRITE TABLE logmsgs1
> PARTITION (year=2014, month=1 ,day )
> SELECT hms,severity,server,process_id,message,day
> WHERE year=2014 and month=1;
Total MapReduce jobs = 3
Launching Job 1 out of 3
…
OK
Time taken: 8.146 seconds
动态插入参数说明:
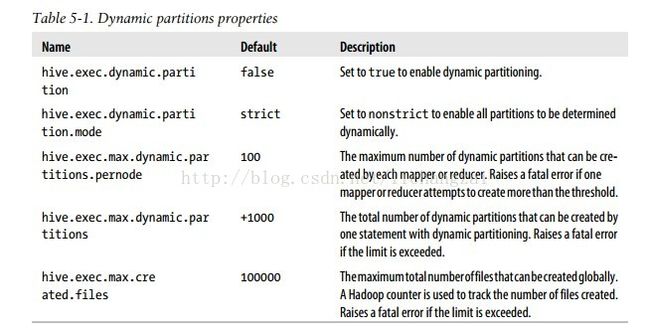
要设置动态插入操作,可能需要以下的参数设置:
hive> sethive.exec.dynamic.partition=true;
hive> sethive.exec.dynamic.partition.mode=nonstrict;
hive> sethive.exec.max.dynamic.partitions.pernode=1000;
hive> INSERTOVERWRITE TABLE employees
> PARTITION (country, state)
> SELECT ..., se.cty, se.st
> FROM staged_employees se;
4.用create as创建表
--创建表并加载查询内容
CREATE TABLE ca_employees
AS SELECT name,salary, address
FROM employees
WHERE sstate ='CA';
可以看到用法和SQL是一样的。这个特性不能用于创建外部表,但可以从外表里读取数据来创建管理表。
5. 导出数据
如果数据文件已经是被格式化的,只要简单copy目录就可以了
hadoop fs -cpsource_path target_pat
否则要INSERT …DIRECTORY …,语句进行导出,如下:
hive (mydb)>INSERT OVERWRITE LOCAL DIRECTORY '/tmp/logmsgs1'
> SELECT hms,server,process_id
> FROM logmsgs1
> WHERE year = 2014 and month = 1and day in(20,21);
注意:加LOCAL子句是导到文件系统,不加LOCAL子句是导入到HDFS
hive (mydb)>!ls /tmp/logmsgs1;
000000_0
hive (mydb)>dfs -cat /tmp/logmsgs1/000000_0;
62410.1.5.17465768
11162410.1.5.17465769
11162410.1.5.17465770
11162510.1.5.17465771
可以看到字段之间的是连接在一起的,没有了限定符。因为^A和^B分隔符不能被显示(rendered.)
--导出表中的数据到多个目录
FROM staged_employees se
INSERT OVERWRITEDIRECTORY '/tmp/or_employees'
SELECT * WHERE se.cty = 'US' and se.st = 'OR'
INSERT OVERWRITEDIRECTORY '/tmp/ca_employees'
SELECT * WHERE se.cty = 'US' and se.st = 'CA'
INSERT OVERWRITEDIRECTORY '/tmp/il_employees'
SELECT * WHEREse.cty = 'US' and se.st = 'IL';
如果像上面导出结果一样没有限定符的话,我们可能导出的数据可能就是一个问题,无法使用。所以我们需要先对查询数据做处理,或是导入到一个临时表里(Hive没有关系数据库的临时表,只能先生成一个表后再用完再删除),或是在导出时直接格式化如下所示
hive (mydb)>INSERT OVERWRITE DIRECTORY '/tmp/logmsgs2'
> SELECT hms,',',server,',',process_id
> FROM logmsgs1
> WHERE year = 2014 and month = 1and day in(20,21);
hive (mydb)>dfs -cat /tmp/logmsgs2/000000_0;
111624,10.1.5.17,465769
111624,10.1.5.17,465770
111625,10.1.5.17,465771
111625,10.1.5.105,465772
111625,10.1.5.17,465773
另一种有用的方法:
替换hive导出文件字段默认分隔符
Hive建表的时候虽然可以指定字段分隔符,不过用insert overwrite local directory这种方式导出文件时,字段的分割符会被默认置为\001,一般都需要将字段分隔符转换为其它字符,可以使用下面的命令:
sed -e 's/\x01/|/g' file
可以将|替换成自己需要的分隔符,file为hive导出的文件。
例如 ,
--替换分隔符为tab键后,输入到t1.txt文件中
sed -e 's/\x01/\t/g' 000000_01 > t1.txt
[licz@nticket1 bill]$ vi t1.txt
27.0 1327661724-15677344 -1.0
27.0 1327661560-15807853 1.0
27.0 1327661560-15807853 2.0
27.0 1327661560-15807853 -1.0
27.0 1327661041-16002756 1.0
27.0 1327661041-16002756 2.0
27.0 1327661041-16002756 -1.0
27.0 1327661347-16462474 -1.0
27.0 1327661397-16003897 1.0
--导出文件
sftp> get t1.txt
Downloading t1.txt from /tmp/bill/t1.txt
100% 294 bytes 294 bytes/s 00:00:00
/tmp/bill/t1.txt: 294 bytes transferred in 0 seconds (294 bytes/s)