不同Graph Embedding表示方法的区别和效果
不同embedding表示方法的区别与效果
转载自:https://zhuanlan.zhihu.com/p/26222107
0) 引言
在自然语言处理、文本挖掘中,常常使用词向量作为单词(Word)内在含义的表达,从传统的向量表达到近几年的词嵌入(Word Embedding)表达,词向量已经作为一种文本的常用特征得到广泛应用。类似的,一些研究者希望通过网络结构中的连接关系,得到网络中顶点(vertex)的向量表示,作为基本特征应用到聚类、分类等任务上。最近在研究图片搜索中关于query和site的关系时,希望能通过它们的连接关系得到embedding向量作为特征。
本文总结了5种近几年常用的将网络结构中节点转化为节点向量的方法,不同研究者对这一问题的命名有出入,如node2vector,graph representation,network embedding等,但实质上是同一个问题。接下来本文对deepwalk、line、DNGR、SDNE、node2vector五种方法分别做介绍。
1) Deepwalk
Deepwalk来源于《DeepWalk: Online Learning of Social Representations》这篇论文,它的思想非常简单,主要借鉴了word2vec,将网络结构通过Random walk的方式,转换为类似“sentence”的节点序列的形式。Word2Vec是Mikolov带领Google研发的用来产生词嵌入表达的模型,其中又包括skip-grams 或continuous-bag-of-words(CBOW)两种方式。Word2Vec相关介绍很多,本文不再赘述。
在deepwalk的这篇论文中,为了说明网络结构中的节点和文本中的词具有可比性,作者根据对社交网络的图和Wikipedia中的文本进行分别统计,发现都遵循zipf's定律,说明词和经过Random walk后图的节点,具有相似的特性。如下图所示:
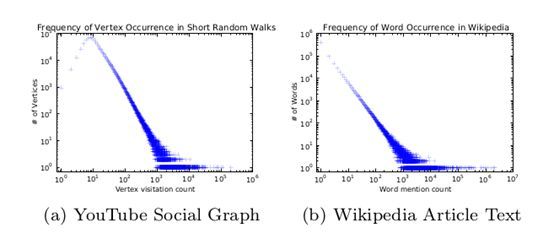
将网络结构转化为“sentence”序列后,以通过word2vec中的Skip-gram模型或者CBOW模型,训练得到每个节点的向量表示形式,进而可以用余弦距离或者欧式距离来求得两个节点之间的相似度。这篇论文采用了Skip-gram模型。
Deepwalk算法描述,见下图。对图G,随机采样1个节点v,然后以此为起点连续采样,直到达到最大路径长度t,再通过Skip-gram来更新参数。

Deepwalk实现很简单,在网络结构上主要考虑节点间是否存在连接的边,但是效果稳定,在评测数据上取得了很不错的效果,且代码健壮。在应用上deepwalk支持directed/undirected网络,原始代码不支持带权重的网络结构。
Deepwalk工具包地址:deepwalk
2) LINE
LINE模型源于论文《LINE: Large-scale Information Network Embedding》,这篇文章提出了两个规则(order),我们通过文中的示例来具体理解这两种规则。如下图所示网络:
这个网络结构中,对5、6、7三个节点而言,根据first-order来说6、7节点更相似,因为它们有一条直接相连的边;根据second-order来说5、6节点更相似,因为它们有四个公共邻居节点。根据这两种计算相似性的规则,论文作者相应的提出了两种训练节点向量的算法。
First-order:这种方法主要考虑两个节点间的没有方向(undirected)的边,用表示节点向量,那么可以用下面的式子计算节点和的联合概率:

根据经验,在网络结构中和联合分布的经验概率可以表示为,其中,模型的目标函数就是希望优化两种联合概率的距离
![]()
其中函数表示两种分布的“距离”,论文中选用了KL散度来衡量。此时,目标函数转化为
![]() Second-order:由于第二规则着重考虑邻居节点对中心节点的表达,类似于文本中上下文对中心词的表达,上下文一致时两个中心词就极有可能相似,因此在第二规则中对有向(directed)边,定义了节点间的生成概率:
Second-order:由于第二规则着重考虑邻居节点对中心节点的表达,类似于文本中上下文对中心词的表达,上下文一致时两个中心词就极有可能相似,因此在第二规则中对有向(directed)边,定义了节点间的生成概率:
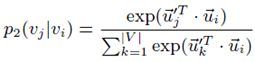 根据经验,我们可以知道节点生成节点的概率为,其中表示节点指向所有边的权重和。那么模型的目标函数如下:
根据经验,我们可以知道节点生成节点的概率为,其中表示节点指向所有边的权重和。那么模型的目标函数如下:
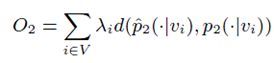
同样适用KL散度定义距离,且使,消去常数项,可以使目标函数转化为:
在Second-order的目标生成概率函数中可以发现,当需要计算节点i到节点j的转移概率时,需要计算所有和节点i相邻节点的内积,这样明显会极大增加求解过程中的计算量。论文作者采用负采样(negative sampling)的方法对生成概率进行替换,如下面式子所示:

其中是sigmoid函数,是负采样的样本个数。是一个表示负样本分布的参数,具体可参看论文。
发散思考:
本文作者在这两种方法的基础上,提出了一些具体问题上进行讨论。
第一个问题是网络节点中低维度节点应该怎样训练?低维度节点指的是某些节点的“邻居节点”太少,这样可供其采集的样本就很少。在这些节点上学习到的特征就很弱。为了增加其信息的丰富性,作者尝试使用构建邻接边的方式丰富网络结构,主要思想是假如存在临边 、,那么就可以确定出的权重。公式如下:
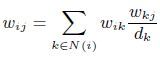
第二个问题是针对一个网络结构训练完毕后,如何添加入新的节点?
这是一个应用性很强的问题,其本质是要考虑如何不重新整合全局信息而得到新加入节点在这个空间维度的向量表达。在Word2Vec中就可以实现在训练结果的基础上,加入新的语料继续优化。在这里,作者提出了一个简单的优化目标,在不改变原始网络中节点向量的基础上,根据新节点的连接关系对新节点进行优化。两种规则的优化目标函数如下:

两个目标函数较易理解,不再赘述。
除了以上两个问题,作者还对这两种向量的结合问题做了思考。毕竟这两种方法都挺不错,如果能结合起来学出来一套综合的向量按理说效果应该更好啊。不过很遗憾的是由于这两个方法的出发点不一样,很难把两种算法结合起来学习。但是却有一种简单粗暴的方法,就是使用两种规则分别训练,最后直接把两个向量拼接起来。效果在具体任务上见仁见智吧,我在自己的任务上试验过,反而比单独的效果还差一点,也是很不解。有兴趣的童鞋可以再研究研究,没准就能搞一篇不错的论文出来。
LINE工具包:LINE
3) Node2Vector
Node2Vector算法源于论文《node2vec: Scalable Feature Learning for Networks》,这篇论文可以看作是deepwalk的升级版。
整体上来看,Node2Vector在deepwalk的基础上改变了节点游走的方式,考虑了更多的信息,deepwalk在下一个节点的选择上只是对当前节点的所有邻居节点中random选择一个,而本文方法就更复杂些,在一些评测上也取得了更好的效果。下面就具体看一下Node2Vec的实现方法。
论文作者首先提出了网络节点间游走(采样)的两种方式:Breadth-first Sampling(BFS)和Depth-first Sampling(DFS),其实有点类似常说的广搜和深搜。我们用论文中的一张图来说明这两种采样方式:
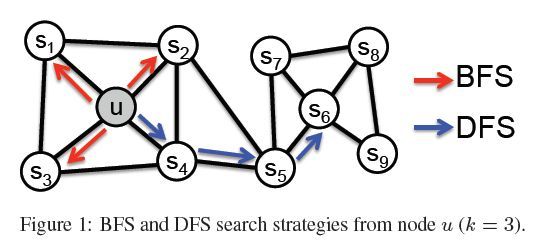
相信上面这张图已经直观的解释了BFS和DFS,不再细说。这两种采样方式风格不同,但各有千秋,都挺符合我们的认知,论文作者觉得应该把两种采样方式结合起来啊,这样岂不是很牛逼?但是怎样结合是一个大问题。
不着急,我们先来看下面这个图,这是作者论文中的一张图:
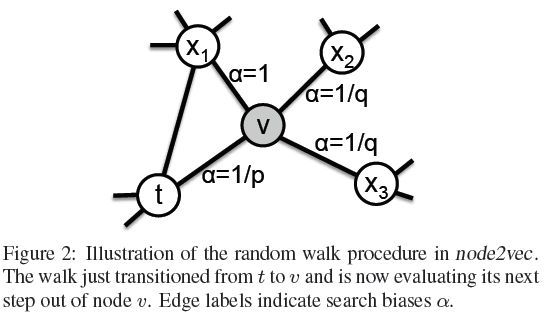
这种图充分说明论文作者如何将两种游走方式结合起来的。在deepwalk中,一条walk序列从节点走到节点,接下来往哪里走呢?就是从随机选一个,然后依次类推的往下走。但在Node2Vector中作者将四个节点共分为3类,对当前节点(cur_node)来说,节点的上一个节点(pre_node),是cur_node和pre_node同时连接的节点,是其他邻居节点。我们还可以将这三类节点按照DFS和BFS的理论去分析,比如再往想//走就是DFS,往/走就是BFS,总而言之这些都可以算是物理意义上的解释吧。
为了实现这种结合的游走方式,作者定义了、两个参数,将这三类节点的概率值分别定义为、、,参数、是作为参数传入的。根据网络结构的不同特点,可以调整、来实现对不同采样方式的偏爱。如下图所示:
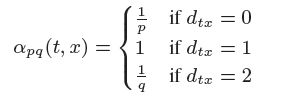
到这里,针对节点t能来说,我们得到了能转移到不同类别节点的概率,常规做法是归一化之后按照概率随机选取,但这篇论文并没有直接这样做,而是选用了Alias算法进行抽样。Alias算法相比较于直接抽样方法效率上要高一些,效果上见仁见智,这里不再具体介绍。
此时,我们就可以得到节点序列,已经完成了整个算法的核心部分,因为接下来就是直接用word2vec对节点序列进行训练(对,就是这么任性)就好了。
另外,值得一提的是,由于在next_node的选择上需要
当然,也由于这种游走方式的复杂性,在网络节点的个数较少时,node2vec的效果整体上要优于deepwalk,但在节点多到可能影响空间限制时,deepwalk效果更优。
Node2vec源码:node2vec
4) SDNE
SNDE方法源于论文《Structural Deep Network Embedding》,这篇论文从Auto-encoder方法上进行改进,从而实现对网络节点的embedding。
Auto-encoder方法,简单来说可以算是一种降维的方法,在图片应用上比较多,将原始的高维向量在尽可能避免信息丢失的情况下降维得到目标维度的向量。Auto-encoder的网络结构大致如下:
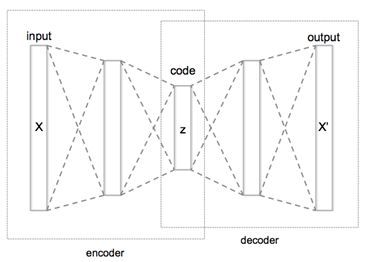
Auto-encoder算法主要达到的是一个“降维”的目的,并不能学习出表示节点关系的embedding表达。在这篇论文中,作者通过在训练过程中加入节点信息使得学习出的向量能过表示出节点的内在关系。
接下来我们来详细介绍下SDNE,先给出下面这幅图,描述了整个SDNE的网络结构:
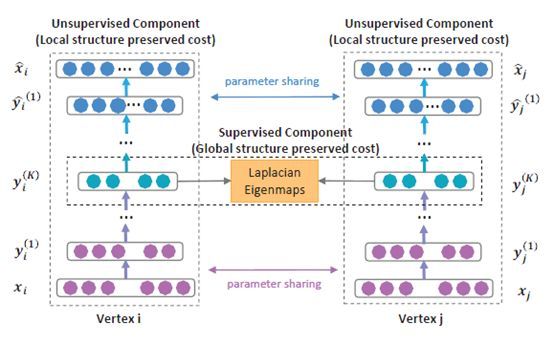
第一步,我们来了解下Auto-encoder,就是上图中的左边部分,给定一个原始的出入向量,可以得到:
通过decoder的过程,我们可以得到最终输出,目标函数是最小化输入和输出的误差:
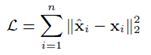
第二步,对Auto-encoder算法加入惩罚因子。在图片的自编码中,由于原始输入的每一维度都不为0,但是在网络结构中,我们将节点和其他节点的关系(0、1关系/权重关系)作为该节点的原始输入。对一些节点多、连接少的网络结构而言,原始输入十分稀疏,这会导致encode/decode后的向量更趋向零向量。因此将目标函数改为如下:
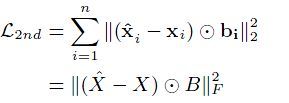
其中,表示Hadamard乘法,,如果,则,否则。
第三步,学习节点间的关系信息。这是这篇论文在Auto-encoder较大的改进应用。作者认为两个节点直接相连的时候,那么最终的短处向量y就应该更相似。基于这个目标,能够得到如下loss函数:
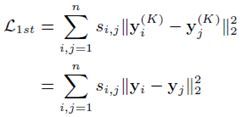
其中就是我们需要的固定维度的最终向量。
最终,基于以上这些,作者给出了最终的目标函数:
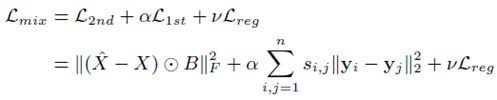
前两项在在上面已经解释过,最后一项是个正则化项防止过拟合,定义如下:
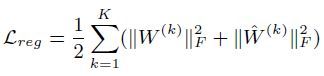
关于求解过程不再具体阐述。以上就是SDNE的模型框架。
5) DNGR
NDGR算法来源于论文《Deep Neural Networks for Learning Graph Representations》,这篇论文和SDNE算法有异曲同工之妙,都应用了auto-encoder,但在如何学习节点间连接信息的方法上却另辟蹊径。
SDNE为了学习到邻接节点的相似信息,在目标函数中加入中间结果的loss函数(具体见上文),而本文则根据邻接信息改变每个节点的原始表达,作为自编码模型的输入。由于输入向量本身就含有网络连接信息,因此经过“压缩”后的向量也能表达节点关系。具体我们一步步来介绍。
第一步,通过random surfing模型得到概率共现矩阵。作者认为将网络节点转化为序列可能存在一些问题,比如序列长度,采样次数,这些都不好确定。根据PageRank算法的启发,作者希望通过概率转移矩阵/邻接矩阵A学习到网络结构信息。由于步骤较为简单且便于理解,此处直接通过matlab代码来说明:

其中A是原始邻接/概率转移矩阵,alpha是平滑参数,决定节点是否需要转移。P0和M矩阵初始分别是单位矩阵和全0矩阵,M是最终产出结果。ScaleSimMat是对矩阵进行主对角线置0后,对每列进行归一化。
第二步是得到PPMI矩阵,对上步得到的矩阵进行处理。其中PMI(pointwise mutual information,点互信息)定义如下:

在PMI的基础上,对值为负的元素,全部置为0,得到PPMI矩阵。
第三步是进行自编码,论文作者使用了SDAE(stacked denoising autoencoders)编码。SDAE和AE的差距不大,主要区别是在训练之前对input向量进行了容错处理,具体做法是按照一定的方式对input向量中的少部分元素置0,这样可以在某种程度上对输入向量的依赖程度,提高整体的学习效果。具体encode/decode的过程和AE基本一致,可以在SDNE方法中看到。
DNGR方法在编码之前,通过转移矩阵学习到节点间的连接信息,和SDNE有共通之处。但在实际应用过程中却会遇到很多问题,可以在上列步骤中看到需要进行矩阵运算,当网络节点很多时,就要面临大型矩阵的运算问题,需要单独将矩阵运算部分拿出来,利用Hadoop等方式运算(主要是大型矩阵的存储)。笔者尝试一般超过5W节点后基本单机是难以直接实现的,因此在工业实现上还需要具体改进算法。
DNGR工具包:DNGR(matlab) DNGR-Keras(python)
6) 实践
在实际工作中,考虑到效率和性能,我们一般会选择最简单的模型进行尝试,因此我们选用Deepwalk作为我们探索query和site相关性的首选模型。
- 数据来源:从User搜索日志中,随机选择60W query,打压至搜狗图片搜索,爬取首页结果。可以得到大约60w * 24 对query和site的关系(图片结果页首页有24张)。
- 数据生成:通过query和site的链接关系,生成基于query-site的二部图,再通过邻接表的形式,将二部图表示出来。如下如所示:
 向量生成:将这个处理后的文件作为Deepwalk的输入,之后就可以通过类似word2vec的方式显示效果了。
向量生成:将这个处理后的文件作为Deepwalk的输入,之后就可以通过类似word2vec的方式显示效果了。-
未登录query处理:可能你已经发现,上面生成的向量,只包含选取的那些query和site,大约21Wquery和40Wsite,针对未登录的site,我们认为很可能站点太小或者有是垃圾站点,对整体效果影响不大,因此忽略不计。这里主要针对未登录的query进行处理。
最直接的想法,当一个新的query到来时,是否可以从已知query中找到一个语义最相近的query来表示这个未登录query呢?然而,这个方法局限性也很大,很难保证已知query的语义都能覆盖到。那么进一步地思考,是否我们可以通过query作为桥梁,学习site空间和文本空间的一个映射关系呢?有了这个关系,我们就可以将文本空间的query映射到site空间,进而可以和site计算相似度了。这里我们采用了 DSSM (Deep Structured Semantic Model)来学习不同语义空间的关系。这样,对于任意一个query,我们都可以获取与其相关的site信息了。
- Demo展示:为了方便观察,我们搭建了一个Demo观察效果。
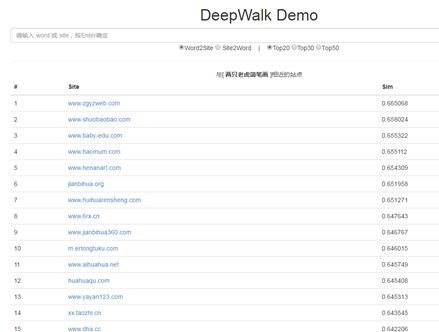

可以看到,有明显图片意图的query或者垂直类站点效果都不错,但是比如 http://nipic.com这种综合类的站点,对应的query种类也比较多,效果并不理想。
7) 小结:
以上五种方法中,整体来说deepwalk和node2vector一脉相承,DNGR和SDNE异曲同工,LINE在没有直接借助现成工具,但思想上和前面两种方法更接近。
从效果上来说,deepwalk在大型网络上比小网络上效果要好,源于其完全随机的游走方式需要大数据位基础,在小型网络上 node2vector 比 deepwalk 效果整体好一些。在具体应用上, deepwalk 和 LINE 对大数据的适应性更好,其余三种方法原始代码对大型网络(节点>5W)难以实现,需要通过其他方式改进。