用户画像——ID-Mapping
讲解ID-Mapping算法之前,先说几个重要概念:
- MAC(Media Access Control),MAC位址,为网卡的标识,唯一标识网络设备。
- IMEI(International Mobile Equipment Identity),通常说的手机序列号、手机“串号”,在移动电话网络中识别每一部独立的手机等行动通讯装置;序列号共有15位数字,前6位(TAC)是型号核准号码,代表手机类型。接着2位(FAC)是最后装配号,代表产地。后6位(SNR)是串号,代表生产顺序号。最后1位(SP)一般为0,是检验码,备用。
- IMSI(International Mobile SubscriberIdentification Number),储存在SIM卡中,区别移动用户的有效信息;其总长度不超过15位,同样使用0~9的数字。其中MCC是移动用户所属国家代号,占3位数字,中国的MCC规定为460;MNC是移动网号码,最多由两位数字组成,用于识别移动用户所归属的移动通信网;MSIN是移动用户识别码,用以识别某一移动通信网中的移动用户。
- Android ID是系统随机生成的设备ID 为一串64位的编码(十六进制的字符串),通过它可以知道设备的寿命(在设备恢复出厂设置或刷机后,该值可能会改变)。
- UDID (Unique Device Identifier),苹果IOS设备的唯一识别码,它由40个字符的字母和数字组成,为了保护用户隐私苹果已经禁止读取这个标识了。
- UUID(Universally Unique IDentifier),是基于iOS设备上面某个单个的应用程序,只要用户没有完全删除应用程序,则这个 UUID 在用户使用该应用程序的时候一直保持不变。如果用户删除了这个应用程序,然后再重新安装,那么这个 UUID 已经发生了改变。缺点是用户删除了你开发的程序后,基本上无法获取关联之前的数据。
- OpenUDID,不是苹果官方的,是一个替代 UDID 的第三发解决方案, 缺点是如果你完全删除全部带有OpenUDID SDK 包的App(比如恢复系统等),那么OpenUDID 会重新生成,而且和之前的值会不同。
- IDFA (广告标示符),苹果禁用UDID后想出了折中办法,就是提供另外一套和硬件无关的标识符,用于给商家监测广告效果,这就是IDFA。用户可以在手机设置里改变这串字符,会导致商家没有办法长期跟踪用户行为。
- telphone(手机号)。 手机号也可以唯一的标识用户。因为两个人的手机号在同一时间内不会一样。
上面给出的这几个信息都可以唯一标识一位用户,可以作为用户ID号。
假设有一位用户张三,在第一个手机上使用百度地图, 在ipad上观看百度爱奇艺视频,在第二个手机上使用手机百度app, 在pc电脑上使用百度搜索,如何将同一个用户在这些不同端的用户信息聚合起来呢?
ID-Mapping主要解决这个问题,用来关联ID信息。
算法思路
我们把用户在各个端的信息收集起来,假设输入两条日志的id信息为:
line1: < mac1,mac2> < imei1> < tel1>
line2: < mac1> < imei2> < tel1,tel2>
上下是两条用户行为日志,看到他们都有mac1,两条数据应该是同一个用户。
使用多轮map-reduce的聚合方法,map做数据分块,reduce做归并
第一轮,以mac1和 mac2为key字段来map和reduce
Map 输出:
mac1 line1 < mac1,mac2 > < imei1> < tel1>
mac2 line1 < mac1,mac2> < imei1> < tel1>
mac1 line2 < mac1> < imei2> < tel1,tel2>
Reduce 输出:
line1 < mac1,mac2> < imei1,imei2> < tel1,tel2>
line1 < mac1,mac2> < imei1> < tel1>
line2 < mac1,mac2> < imei2,imei1> < tel1,tel2>
第二轮, 以line1和 line2为key字段来map和reduce
Map 输出:
line1 < mac1,mac2> < imei1,imei2> < tel1,tel2>
line1 < mac1,mac2> < imei1> < tel1>
line2 < mac1,mac2> < imei2,imei1> < tel1,tel2>
Reduce 输出:
line1 < mac1,mac2> < imei1,imei2> < tel1,tel2>
line2 < mac1,mac2> < imei1,imei2> < tel1,tel2>
第三轮, 以< mac1,mac2>为key字段来map和reduce
Map输出:
< mac1,mac2> < imei1,imei2> < tel1,tel2>
< mac1,mac2> < imei1,imei2> < tel1,tel2>
Reduce输出:
< mac1, mac2> < imei1,imei2> < tel1,tel2>
依次指定< id >重复上述过程,直到无法归并
数据和索引设计
数据库表的设计,设置global-id作为主key,(类似身份证号的作用),其他的字段都可以有多个(map< string,int>),这些用来表示一个用户的多个身份标识。
//数据表
global_id string,
imei map<string,int>
mac map<string,int>
imsi map<string,int>
phone_number map<string,int>
idfa map<string,int>
openudid map<string,int>
uid map<string,int>
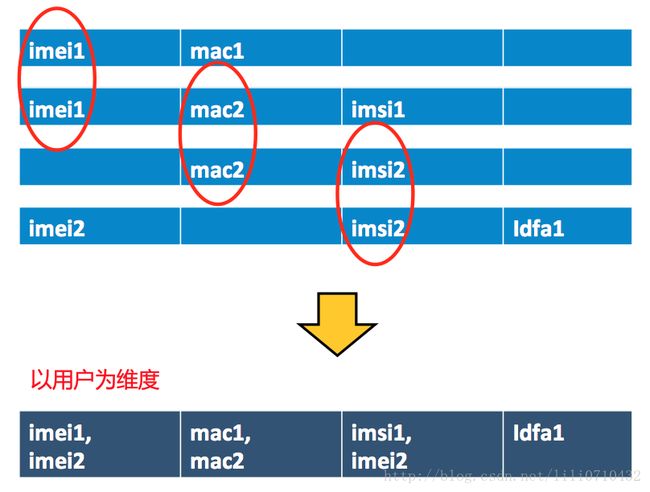
did map<string,int> 例如这四条记录可以看到其实是一个用户,存储的时候就把它们存为一个用户,用global_id作为key。
由此得到
global_id <=> imei,mac,imsi,phone_number,idfa,openudid,uid,did的相互映射关系。
//索引表
id string
global_id string
线上查询的时候,假设获取了mac1类型ID, 根据mac的索引表获取global_id,然后根据global_id数据表获取用户imei、phone_number等其他ID信息。
ID过期问题
对于僵尸用户,或者长期不用的用户,保存数据没有意义,浪费资源而且数据长期不更新后可能数据不准确。
可以对每个ID加入活跃度参数,一方面代表用户的活跃程度,一方面可以对ID的存储做控制。
- 用户行为数据:代表了用户的活跃度,数据入表活跃度设置为0
- ID Mapping历史数据:按周更新,代表上周用户的数据,迭代计算时,活跃度+1
- 全量用户信息数据:代表全量用户,数据引入时,设置活跃度参数为一个合理值。(eg: 60)