Linux IO : 阻塞、非阻塞、同步、异步
在学习Linux网络IO时,同步(synchronous)和异步(asynchronous),阻塞(blocking)和非阻塞(non-blocking)这几个概念一直都频繁出现,且很容易混淆不清。经过几番查阅之后略有思路,整理于此。
注:由于不同的系统环境和知识背景下对这几个概念的理解都会有所出入,此处主要以Steven先生的《Unix网络编程:卷一》为基础,在Linux环境中以个人愚见来浅析以上四个概念。
在《Unix网络编程:卷一》一书的第六章中,提及了5种类Unix下的IO模型:
- 阻塞式IO
- 非阻塞IO
- IO复用(I/O multiplexing)
- 信号驱动式IO(SIGIO)
- 异步IO
其中的信号驱动式IO在实际中很少见,所以避而不谈。对于这几种IO模型而言,一个输入操作通常包括两个阶段:
1.等待数据准备好
2.从内核拷贝数据到用户空间
可见,这两个阶段中包含了两个系统对象,一个是IO的调用者(用户的应用进程或线程),另外一个便是系统内核。不同的IO模型的区别也主要表现在这两个对象在IO的两个阶段中操作的差异。
阻塞式 IO
默认情况下所有的套接字都是被设置为阻塞的,下图以read调用为例给出了传统的也是最为常见的阻塞IO模型:

在此模型中,应用进程执行一个系统调用(read),此时进程会阻塞并对内核进行上下文切换,当内核缓冲区数据准备就绪(如UDP收到了一个完整包)并拷贝至用户空间后,进程解除阻塞并返回。
非阻塞IO
进程把一个套接字设置成非阻塞是在通知内核,当所请求的I/O操作非得把本进程投入睡眠才能完成时,不要把进程投入睡眠,而是返回一个错误。
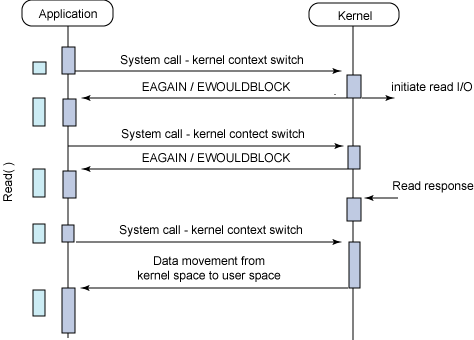
图中可见,当应用进程执行read调用时,如果内核中数据未准备就绪,则立马返回一个错误(EAGAIN / EWOULDBLOCK),而不是将进程阻塞。从应用进程角度来看,每次的调用会立刻得到结果,如果返回的是错误则可知内核数据尚未就绪,可以执行某些延迟重新调用等策略。从内核角度来看,如果数据准备就绪,且又收到应用进程的系统调用,则会将数据拷贝至用户空间,并返回。
该模型的效率并不高,因为应用进程需要轮询内核直到内核数据就绪,而这样往往也会耗费大量CPU时间,如引用延时IO操作则会降低整体数据吞吐量。
IO复用
IO复用(IO multiplexing)是一种将阻塞从IO系统调用(read,recv等)转移到select、poll、epoll这样的系统调用上的模型,有时又被称为事件驱动IO(event driven IO),其优势在于单个进程可以通过IO复用来同时处理多路IO。在实际的IO复用模型中,套接字一般被设置为非阻塞,但是应用进程实质上是一直被阻塞的,只不过其阻塞在select/epoll上,而不是套接字IO调用上。

当应用进程调用select (或poll、epoll)后,整个进程便会被阻塞住,此时内核会统一等待所有select中所包含的套接字,一旦有套接字数据准备就绪,select便会返回,此时用户进程再进行IO操作将数据从内核拷贝至用户进程(对于epoll而言,当epoll通知应用进程时数据已经在用户空间中了)。
IO复用既可以理解为阻塞,也可以理解为非阻塞。 所谓非阻塞是因为无需等到所有套接字数据全部到达后再做处理,而阻塞是因为内核在等待数据时还是处于阻塞状态。
异步IO
理想的异步IO模型是:应用进程进行IO系统调用后不等待结果继续执行,内核接收到异步操作请求后立刻返回(这样便不会阻塞应用进程),然后内核等待数据准备完成并将数据拷贝至用户空间后,产生一个信号或执行回调函数来完成这次IO处理过程。

阻塞与非阻塞
这四种模型介绍完后,阻塞与非阻塞的区别就很明显了:阻塞调用是指在调用结果返回前,当前进程被挂起,直到得到结果后才返回,而非阻塞调用是指在不能立刻得到调用结果前,该调用不会挂起该进程,而是返回错误,阻塞与非阻塞关注点都在于应用进程在等待调用结果时的状态。
补充:Linux中非阻塞模型看似比阻塞要好,实际上CPU很大几率会因为没有socket数据而空转,造成机器效率低下。
同步与异步
同步和异步的关注点在于消息通信机制:对于同步而言,是调用者主动等待调用结果,不得到结果不返回。而对于异步,调用在发出后不等结果便返回了,而后被调用者通过状态、通知来告知调用者,或通过回调函数进行处理。
《Unix网络编程:卷一》6.2.7节中如此描述同步和异步IO:
- 同步I/O操作 (synchronous I/O operation) :导致请求进程阻塞,直到I/O操作完成;
- 异步I/O操作 (asynchronous I/O operation):不导致请求进程阻塞。
根据这个定义,阻塞式IO,非阻塞IO和IO复用这三个模型均属于同步IO,因为在内核数据准备好时,进程调用的IO操作(read、recv)会将数据拷贝至用户空间,此时应用进程将被阻塞。而对比此时的异步IO,当进程发起IO操作调用后直接返回,直到1.数据准备就绪 2.数据由内核拷贝至用户空间 这两个操作完成后被告知IO操作已经完成,在此过程中应用进程完全没有被阻塞。所以,阻塞和非阻塞是针对同步IO而言,对于异步IO而言没有所谓阻塞和非阻塞之分。
总的而言,在处理IO操作时,阻塞和非阻塞都是同步IO,只有使用特殊 API 时才属于异步IO。

补充:对于IO复用模型中的epoll调用,因为epoll函数采用 mmap的机制, 使得内核的套接字缓冲区和用户空间中的缓冲区共享了,从而省去了将数据拷贝至用户空间这一步骤,这也意味着, 当epoll回调上层的回调函数来处理套接字数据时, 数据已经从内核层 “自动” 到了用户空间,所以epoll通知应用进程时,数据已经到达了用户空间,这时的read/recv等调用只用读取用户空间中的缓冲区了,而不用进行拷贝操作了。所以epoll这个调用很多时候会被误理解为异步IO,但是epoll在告知应用进程前还是被阻塞了,只不过将阻塞点由IO系统调用转移到了epoll这个系统调用上,所以IO复用模型中的epoll虽然在业务逻辑上有异步,但是从IO操作层面上而言还是属于同步IO的。
参考资料:
[思考]也谈同步异步I/O
IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
boost application performance using asynchronous I/O(希望辩证看待这篇文章)