机器学习:Python实现聚类算法(一)之K-Means
转自
机器学习:Python实现聚类算法(一)之K-Means - lc19861217 - 博客园
1. 简介
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
2. 算法大致流程为:
1)随机选取k个点作为种子点(这k个点不一定属于数据集)
2)分别计算每个数据点到k个种子点的距离,离哪个种子点最近,就属于哪类
3)重新计算k个种子点的坐标(简单常用的方法是求坐标值的平均值作为新的坐标值)
4)重复2、3步,直到种子点坐标不变或者循环次数完成
3.完整计算过程
1)设置实验数据
运行之后,效果如下图所示:

在图中,ABCDE五个点是待分类点,k1、k2是两个种子点。
2)计算ABCDE五个点到k1、k2的距离,离哪个点近,就属于哪个点,进行初步分类。
结果如图:

A、B属于k1,C、D、E属于k2
3)重新计算k1、k2的坐标。这里使用简单的坐标的平均值,使用其他算法也可以(例如以下三个公式)
PS:公式的图片莫名其妙被屏蔽了,由于没有留备份,找不到原来的图片了。所以这里只写个名字,方便大家做个了解或者搜索的关键字。
a)Minkowski Distance公式—— λ λ λ可以随意取值,可以是负数,也可以是正数,或是无穷大。
b)Euclidean Distance公式——也就是第一个公式 λ = 2 λ=2 λ=2的情况
c)CityBlock Distance公式——也就是第一个公式 λ = 1 λ=1 λ=1的情况
采用坐标平均值算法的结果如图:
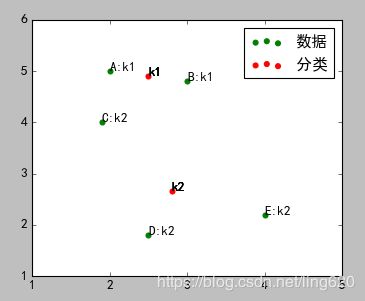
4)重复2、3步,直到最终分类完毕。
下面是完整的示例代码:
import numpy as np
import matplotlib.pyplot as plt
##样本数据(Xi,Yi),需要转换成数组(列表)形式
Xn=np.array([2,3,1.9,2.5,4])
Yn=np.array([5,4.8,4,1.8,2.2])
#标识符号
sign_n = ['A','B','C','D','E']
sign_k = ['k1','k2']
def start_class(Xk,Yk):
##数据点分类
cls_dict = {}
##离哪个分类点最近,属于哪个分类
for i in range(len(Xn)):
temp = []
for j in range(len(Xk)):
d1 = np.sqrt((Xn[i]-Xk[j])*(Xn[i]-Xk[j])+(Yn[i]-Yk[j])*(Yn[i]-Yk[j]))
temp.append(d1)
min_dis=np.min(temp)
min_inx = temp.index(min_dis)
cls_dict[sign_n[i]]=sign_k[min_inx]
#print(cls_dict)
return cls_dict
##重新计算分类的坐标点
def recal_class_point(Xk,Yk,cls_dict):
num_k1 = 0 #属于k1的数据点的个数
num_k2 = 0 #属于k2的数据点的个数
x1 =0 #属于k1的x坐标和
y1 =0 #属于k1的y坐标和
x2 =0 #属于k2的x坐标和
y2 =0 #属于k2的y坐标和
##循环读取已经分类的数据
for d in cls_dict:
##读取d的类别
kk = cls_dict[d]
if kk == 'k1':
#读取d在数据集中的索引
idx = sign_n.index(d)
##累加x值
x1 += Xn[idx]
##累加y值
y1 += Yn[idx]
##累加分类个数
num_k1 += 1
else :
#读取d在数据集中的索引
idx = sign_n.index(d)
##累加x值
x2 += Xn[idx]
##累加y值
y2 += Yn[idx]
##累加分类个数
num_k2 += 1
##求平均值获取新的分类坐标点
k1_new_x = x1/num_k1 #新的k1的x坐标
k1_new_y = y1/num_k1 #新的k1的y坐标
k2_new_x = x2/num_k2 #新的k2的x坐标
k2_new_y = y2/num_k2 #新的k2的y坐标
##新的分类数组
Xk=np.array([k1_new_x,k2_new_x])
Yk=np.array([k1_new_y,k2_new_y])
return Xk,Yk
def draw_point(Xk,Yk,cls_dict):
#画样本点
plt.figure(figsize=(5,4))
plt.scatter(Xn,Yn,color="green",label="数据",linewidth=1)
plt.scatter(Xk,Yk,color="red",label="分类",linewidth=1)
plt.xticks(range(1,6))
plt.xlim([1,5])
plt.ylim([1,6])
plt.legend()
for i in range(len(Xn)):
plt.text(Xn[i],Yn[i],sign_n[i]+":"+cls_dict[sign_n[i]])
for i in range(len(Xk)):
plt.text(Xk[i],Yk[i],sign_k[i])
plt.show()
if __name__ == "__main__":
##种子
Xk=np.array([3.3,3.0])
Yk=np.array([5.7,3.2])
for i in range(3):
cls_dict =start_class(Xk,Yk)
Xk_new,Yk_new =recal_class_point(Xk,Yk,cls_dict)
Xk=Xk_new
Yk=Yk_new
draw_point(Xk,Yk,cls_dict)
最终分类结果:

由上图可以看出,C点最终是属于k1类,而不是开始的k2.
4.K-Means的不足
K-Means算法的不足,都是由初始值引起的:
1)初始分类数目k值很难估计,不确定应该分成多少类才最合适(ISODATA算法通过类的自动合并和分裂,得到较为合理的类型数目k。这里不讲这个算法)
2)不同的随机种子会得到完全不同的结果(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
5.K-Means++算法
算法流程如下:
1)在数据集中随机挑选1个点作为种子点
##随机挑选一个数据点作为种子点
def select_seed(Xn):
idx = np.random.choice(range(len(Xn)))
return idx
2)计算剩数据点到这个点的距离 d ( x ) d(x) d(x),并且加入到列表
##计算数据点到种子点的距离
def cal_dis(Xn,Yn,idx):
dis_list = []
for i in range(len(Xn)):
d = np.sqrt((Xn[i]-Xn[idx])**2+(Yn[i]-Yn[idx])**2)
dis_list.append(d)
return dis_list
3)再取一个随机值。这次的选择思路是:先取一个能落在上步计算的距离列表求和后(sum(dis_list))的随机值rom,然后用 r o m − = d ( x ) rom -= d(x) rom−=d(x),直到 r o m < = 0 rom<=0 rom<=0,此时的点就是下一个“种子点”
##随机挑选另外的种子点
def select_seed_other(Xn,Yn,dis_list):
d_sum = sum(dis_list)
rom = d_sum * np.random.random()
idx = 0
for i in range(len(Xn)):
rom -= dis_list[i]
if rom > 0 :
continue
else :
idx = i
return idx
4)重复第2步和第3步,直到选出k个种子
5)进行标准的K-Means算法。下面完整代码
import numpy as np
import matplotlib.pyplot as plt
##样本数据(Xi,Yi),需要转换成数组(列表)形式
Xn=np.array([2,3,1.9,2.5,4])
Yn=np.array([5,4.8,4,1.8,2.2])
#标识符号
sign_n = ['A','B','C','D','E']
sign_k = ['k1','k2']
##随机挑选一个数据点作为种子点
def select_seed(Xn):
idx = np.random.choice(range(len(Xn)))
return idx
##计算数据点到种子点的距离
def cal_dis(Xn,Yn,idx):
dis_list = []
for i in range(len(Xn)):
d = np.sqrt((Xn[i]-Xn[idx])**2+(Yn[i]-Yn[idx])**2)
dis_list.append(d)
return dis_list
##随机挑选另外的种子点
def select_seed_other(Xn,Yn,dis_list):
d_sum = sum(dis_list)
rom = d_sum * np.random.random()
idx = 0
for i in range(len(Xn)):
rom -= dis_list[i]
if rom > 0 :
continue
else :
idx = i
return idx
##选取所有种子点
def select_seed_all(seed_count):
##种子点
Xk = [] ##种子点x轴列表
Yk = [] ##种子点y轴列表
idx = 0 ##选取的种子点的索引
dis_list = [] ##距离列表
##选取种子点
#因为实验数据少,有一定的几率选到同一个数据,所以加一个判断
idx_list = []
flag = True
for i in range(seed_count):
if i == 0:
idx = select_seed(Xn)
dis_list = cal_dis(Xn,Yn,idx)
Xk.append(Xn[idx])
Yk.append(Yn[idx])
idx_list.append(idx)
else :
while flag:
idx = select_seed_other(Xn,Yn,dis_list)
if idx not in idx_list:
flag = False
else :
continue
dis_list = cal_dis(Xn,Yn,idx)
Xk.append(Xn[idx])
Yk.append(Yn[idx])
idx_list.append(idx)
##列表转成数组
Xk=np.array(Xk)
Yk=np.array(Yk)
return Xk,Yk
def start_class(Xk,Yk):
##数据点分类
cls_dict = {}
##离哪个分类点最近,属于哪个分类
for i in range(len(Xn)):
temp = []
for j in range(len(Xk)):
d1 = np.sqrt((Xn[i]-Xk[j])*(Xn[i]-Xk[j])+(Yn[i]-Yk[j])*(Yn[i]-Yk[j]))
temp.append(d1)
min_dis=np.min(temp)
min_inx = temp.index(min_dis)
cls_dict[sign_n[i]]=sign_k[min_inx]
#print(cls_dict)
return cls_dict
##重新计算分类的坐标点
def recal_class_point(Xk,Yk,cls_dict):
num_k1 = 0 #属于k1的数据点的个数
num_k2 = 0 #属于k2的数据点的个数
x1 =0 #属于k1的x坐标和
y1 =0 #属于k1的y坐标和
x2 =0 #属于k2的x坐标和
y2 =0 #属于k2的y坐标和
##循环读取已经分类的数据
for d in cls_dict:
##读取d的类别
kk = cls_dict[d]
if kk == 'k1':
#读取d在数据集中的索引
idx = sign_n.index(d)
##累加x值
x1 += Xn[idx]
##累加y值
y1 += Yn[idx]
##累加分类个数
num_k1 += 1
else :
#读取d在数据集中的索引
idx = sign_n.index(d)
##累加x值
x2 += Xn[idx]
##累加y值
y2 += Yn[idx]
##累加分类个数
num_k2 += 1
##求平均值获取新的分类坐标点
k1_new_x = x1/num_k1 #新的k1的x坐标
k1_new_y = y1/num_k1 #新的k1的y坐标
k2_new_x = x2/num_k2 #新的k2的x坐标
k2_new_y = y2/num_k2 #新的k2的y坐标
##新的分类数组
Xk=np.array([k1_new_x,k2_new_x])
Yk=np.array([k1_new_y,k2_new_y])
return Xk,Yk
def draw_point(Xk,Yk,cls_dict):
#画样本点
plt.figure(figsize=(5,4))
plt.scatter(Xn,Yn,color="green",label="数据",linewidth=1)
plt.scatter(Xk,Yk,color="red",label="分类",linewidth=1)
plt.xticks(range(1,6))
plt.xlim([1,5])
plt.ylim([1,6])
plt.legend()
for i in range(len(Xn)):
plt.text(Xn[i],Yn[i],sign_n[i]+":"+cls_dict[sign_n[i]])
for i in range(len(Xk)):
plt.text(Xk[i],Yk[i],sign_k[i])
plt.show()
def draw_point_all_seed(Xk,Yk):
#画样本点
plt.figure(figsize=(5,4))
plt.scatter(Xn,Yn,color="green",label="数据",linewidth=1)
plt.scatter(Xk,Yk,color="red",label="分类",linewidth=1)
plt.xticks(range(1,6))
plt.xlim([1,5])
plt.ylim([1,6])
plt.legend()
for i in range(len(Xn)):
plt.text(Xn[i],Yn[i],sign_n[i])
plt.show()
if __name__ == "__main__":
##选取2个种子点
Xk,Yk = select_seed_all(2)
##查看种子点
draw_point_all_seed(Xk,Yk)
##循环三次进行分类
for i in range(3):
cls_dict =start_class(Xk,Yk)
Xk_new,Yk_new =recal_class_point(Xk,Yk,cls_dict)
Xk=Xk_new
Yk=Yk_new
draw_point(Xk,Yk,cls_dict)
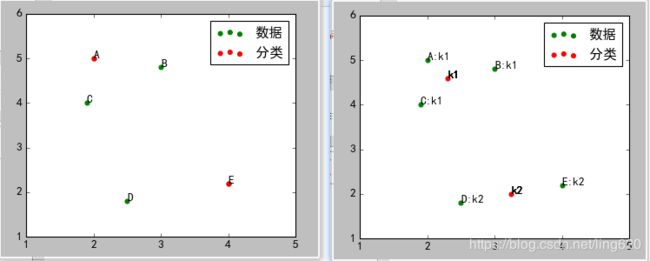
如图所示,选择了A、E两点作为种子点。右图是最终的结果。
补充说明:因为数据量太少,在选取所有种子函数的while阶段有可能陷入死循环,所以需要关闭代码重新运行才可以出结果。
6.sklearn包中的K-Means算法
1)函数:sklearn.cluster.KMeans
2)主要参数
n_clusters:要进行的分类的个数,即上文中k值,默认是8
max_iter :最大迭代次数。默认300
min_iter :最小迭代次数,默认10
init:有三个可选项
'k-means ++':使用k-means++算法,默认选项
'random':从初始质心数据中随机选择k个观察值
第三个是数组形式的参数
n_jobs: 设置并行量 (-1表示使用所有CPU)
3)主要属性:
cluster_centers_ :集群中心的坐标
labels_ : 每个点的标签
4)官网示例:
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [4, 2], [4, 4], [4, 0]])
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
>>> kmeans.labels_
array([0, 0, 0, 1, 1, 1], dtype=int32)
>>> kmeans.predict([[0, 0], [4, 4]])
array([0, 1], dtype=int32)
>>> kmeans.cluster_centers_
array([[ 1., 2.],
[ 4., 2.]])