【编者按】6月24日,由香港主办、开源社群主导的国际技术会议,香港开源年会2016 (HKOSCon)在港召开。PingCAP 联合创始人兼CEO刘奇应邀出席,与大家分享了《How to Build a NewSQL Database》的英文主题演讲。
以下为他的演讲实录:
大家好,我是PingCAP CEO刘奇。今天我将和大家分享一下如何构建一个NewSQL数据库。
首先,来介绍下我自己。和你们当中很多人一样,我是一名开源Hacker,一名架构工程师,并长期致力于创建新一代数据库。我曾投身于以下几个开源项目的工作,包括TiKV、TiDB 和Codis,这些项目都已在Github上发布。今天,我的演讲将涉及下列话题:
- 简要介绍NewSQL;
- 如何建立一个NewSQL数据库;
- 以及roadmap。
▌为什么我们需要一个新的数据库?
在正式开始前,我先问一个问题:你们熟悉数据库吗?熟悉的朋友请举手。谢谢!
另外,有谁知道MySQL吗?谢谢,比我预期的人数要少一些。
那么,现有数据库存在哪些问题呢?
-
像MySQL、Oracle、PostgreSQL这样的关系数据库,它们的问题是很难扩展。尽管我们有分片技术,还有youtube/vitess和MySQL proxy等,但它们都不支持分布式事务以及cross-node join连接。
-
像HBase、MongoDB以及Redis这样的NoSQL数据库:它们可扩展,但不支持SQL,同时也舍弃了事务的一致性。
因此,新一代数据库将会是怎样的?在我看来,其主要特征应该是:
- 支持SQL;
- 具有可扩展性;
- 支持事务执行四要素/ACID Transaction;
- 高可用。
首先,它必须支持SQL,因为这数十年来我们一直在使用SQL,而且许多应用程序都使用SQL,故而不能轻易将其舍弃。
第二,必须有良好的扩展性,也就是说只需通过接入更多的机器就可以扩展其容量或使之实现负载均衡。
第三,必须支持事务的ACID属性,这一点也恰恰是关系数据库的主要特征之一。有了强大的一致性作保障,开发者便可以用较短的代码编写出正确的程序。
最后,即使是在计算机陷入故障,甚至是整个数据中心瘫痪的情况下,它也应该能够保持其较高的可用性。同时,它还应当可以自动修复。
总之,新一代数据库应该既有很好的可扩展性,又能保留关系数据库的主要特征。
▌NewSQL是什么?
你可能会好奇,这样的数据库真的存在吗?它听起来似乎太过完美和理想化了。这个问题的答案是肯定的,这样的数据库的确存在,它就是NewSQL。那什么是NewSQL数据库?先来看一看维基百科给出的解释:
NewSQL是指这样一类新式的关系型数据库管理系统,它针对OLTP实现读-写工作负载,追求提供和NoSQL系统相同的扩展性能,且仍然保持传统数据库支持的ACID特性。
从上述定义来看,我们不难发现NewSQL的扩展性与NoSQL相当,并同时保留了ACID特性。而这恰恰是我们需要的。
▌建立一个NewSQL数据库
今天我将向大家展示如何建立一个这样的数据库。我们受到全球最大数据库Google Spanner 和 F1 的启发,将其分为两个层级:
- KV层:这一层属于底层存储系统,负责提供跨数据中心的同步以及强一致性事务。
- SQL层:这一层使能够满足我们对传统SQL数据库可用性以及功能性的支持。
▌建立NewSQL数据库
这就是我们在PingCAP所从事的工作,当然是开源的。其中,我们的数据库分为两层,即KV层和SQL层。就KV层来看,我们有TiKV;对于SQL层,则有TiDB。而我将在稍后介绍其中的关键技术。这里的Ti是Titanium(钛)的缩写,我们都知道钛作为一种抗腐蚀性的化学元素,被广泛应用于高端科技当中。
■TiKV的特性
-
异地备份:我们利用Raft来支持异地备份。Raft是一种一致性算法,它在容错性和性能方面相当于Paxos算法。我们的实现参考应用广泛的etcd,它已经通过了广泛测试并具有较高的稳定性。
-
水平扩展性:由于Raft支持 membership 变更,我们利用其这一特性来实现水平扩展。
-
一致性的分布式事务:这种事务模型的创建是受到了 Google Percolator(来自一篇2006发表的论文)的启发,主要是一个优化的两阶段提交协议。该模型借助一个时间戳分配器来给各项事务分配单调递增的时间戳,因此可检测到冲突。
-
协处理器支持:与 HBase 类似,我们运用协处理器架构执行服务器代码来进行分布式计算。
-
追求更高的性能和更低的延迟,用编程语言 Rust 进行了编写。你们当中有谁知道 Rust 吗?很不错。你们应该尝试一下,它真的相当有趣。
✦TiKV架构
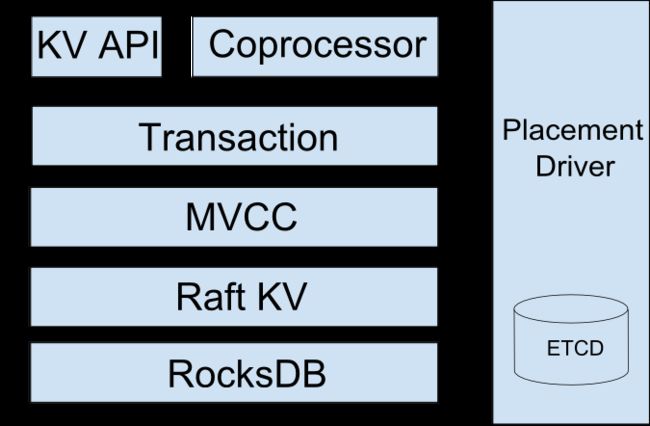
从上图中可以看出,它经过了高度分层。
从底层往上看。底层是RocksDB,它是一个持久的内嵌式KV存储引擎。RocksDB的最初设计重点在于其极高的性能,可以轻松对读放大、写放大以及空间放大进行优化。
上面一层是Raft KV,这一层用来实现分布式。
再往上是MVCC,即多版本并发控制(Multi-version concurrency control)。我相信你们当中很多人对此都很熟悉。TiKV是一个多版本数据库,而MVCC则支持我们的无锁读以及事务的ACID属性。
接下来的事务(Transaction)层,我之前已经介绍过了。
然后是KV API,这是一组程序接口,它允许开发者对数据的输入和输出。
同样,协处理器(Coprocesser)在前面也提过了。
最后是Placement Driver,这是一个尤为重要的部分,因为它可协助进行异地备份,水平扩展以及一致性的分布式事务。稍后我将对其细节进行进一步补充。
✦TiKV 软件栈
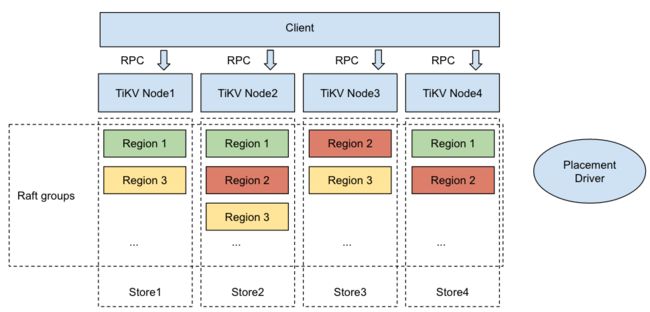
让我们来看一下软件栈。首先,我们会发现客户端与TiKV相连。同时我们还能看见几个Node。而在每个Node当中都有Store,每一个物理磁盘存一个store。在每个 Store 当中,我们又划出许多Region。而Region是数据迁移的基本单位,并且经由Raft备份。每个Region都被同步到多个节点。一个 Raft group 由一个 Region 的数个备份组成。如你所见,每个 Region 在三个不同的节点上有三个备份。
✦驱动程序配置
PD,又称 placement driver,这一名称来源自Spanner的原文。它是集群管理器,提供了该集群的上帝视角。它由两个部分构成:rebalancer和timestamp allocator。PD对Region副本进行周期性检测,平衡负载,并自动处理数据迁移。当它检测到负载过高时,将会重新平衡数据。
■TiDB
- 以TiKV为基础的NewSQL:它将TiKV转变成了一个NewSQL数据库。
- 异步schema改变:你可以在不停止也不影响正在进行的操作的前提下,添加新的列以及索引。本质上看,它是一个多阶段协议。
与MySQL协议兼容:TiDB服务器遵从MySQL协议,并且遵循其SQL语法。换句话说就是在大多情况下,你能够在不更改任何一行代码的同时,通过用TiDB替换MySQL来增强你的应用。TiDB适用于MySQL应用和管理工具,比phpMyAdmin、Navicat以及WordPress。同时,很多ORM也可以在TiDB上很好的工作,例如Hibernate、GORM、ActiveRecord、SQLAlchemy等。
✦TiDB的架构
让我们来看一下TiDB的架构:
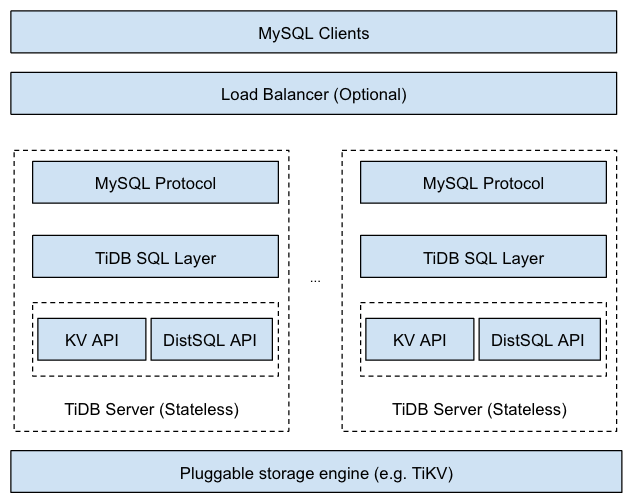
MySQL客户端:顶层是一组MySQL客户端,这些客户端向下一层发送请求。在这里你仍然可以使用你所熟悉的MySQL驱动程序。
负载平衡器:这一层属于可选层,例如HAProxy 以及 LVS。
TiDB服务器:它是无状态的,一个客户端可以同任何一个TiDB服务器相连接。在TiDB服务器内部,最顶层提供MySQL协议支持;下一层是SQL Plan层,往往被用以将MySQL请求转换成TiDB SQL Plan;底层则是KV API以及分布式SQL API。如果较底层的存储引擎支持协处理器,TiDB SQL层将会使用比KV API更为高效的DistSQL API。TiDB支持插件式存储引擎,早期支持HBase。同时作为试验性存储引擎,我们还支持CockroachDB。但我们推荐TiKV为默认存储引擎。
✦TiDB如何使SQL与KV相匹配
让我们用一个例子来展示一个SQL 表是如何映射成KV对的。
假设我们的数据库里有一张简单的用户表。它有一行三列:nickname、email和age。此处的nickname类型是字符串,且nickname是主键。
| nickname | age | |
|---|---|---|
| bob | [email protected] | 30 |
如果我们映射这张表到KV对,Key就分成了三个部分:table、row key、column。而这时的KV对排列如下:
| Key (table/row key/column) | Value |
|---|---|
| user/bob/nickname | nil |
| user/bob/email | [email protected] |
| user/bob/age | 30 |
现在,我们得到了一个典型的SQL statement:按用户名bob筛选email和age;如果映射为KV操作的话,则表达如下:
- email = kv.Get( ” user/bob/email ” )
- age = kv.Get( ” user/bob/age ” )
这就是在一个使用字符串的通用KV数据库中的存储方式。在TiDB内部,每个表,每一列都有一个唯一的ID。所以TiDB使用表ID以及列ID来取代字符串。因此在TiDB中,表id是1,nickname列id为2,email列id为3,age列id则为4,而这一TiDB表显示如下:
| Key (table id/row id/column id) | Value |
|---|---|
| 1/bob/2 | nil |
| 1/bob/3 | [email protected] |
| 1/bob/4 | 30 |
以上就是我今天演讲的全部内容。谢谢大家。