真小白如何学会(?)用python爬取中国大学排名
即使现在是寒冬腊月也冷却不了我热爱敲代码的心,作为一只真小白,从零基础学习python,首先肯定是安装python,说好了是真小白,那就从安装开始讲起,这里有一个小姐姐写得十分详细的安装过程,请点击传送门 真小白入门:python的安装
学习python的第一个晚上安装python成功!
- 从IDLE启动python
首先什么是IDLE呢,它是一个python shell,shell 的意思就是“外壳”,基本上来说,就是一个通过键入文本与程序交互的途径!我们看到>>>这个提示符,它的含义是告诉你,python 已经准备好了,在等着你键入python指令呢。好了我们先来试试看吧。
最先的肯定是大家最熟悉的hello world啦!!!
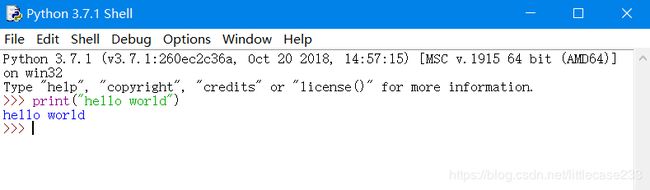
真小白的我看的是廖雪峰的python入门课程 传送门在此Python入门课程当然也可以选择去找其他资源,比如小甲鱼(个人觉得还行,不喜勿喷) - 学习了一定的语法之后呢,我们开始讲爬虫。
什么是爬虫呢
爬虫就是 一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。如果把整个互联网想象成一个蜘蛛网的构造,每个网站都是一个节点,每个域名都是一个节点,那么我们这只蜘蛛在上面爬来爬去爬来爬去爬来爬去,顺便获得我们想要的资源,抓取最有用滴。我们之所以可以通过百度或者谷歌这样的搜索引擎检索到网页靠的就是他们每天派出大量的蜘蛛在互联网上爬来爬去,对网页中的每个关键词进行建立索引数据库通过复杂的排序算法之后按照搜索关键词的相关度的高低展现在我们面前。让我们编写一个搜索引擎估计是十分苦难的事情但是我们从一个小爬虫开始。 - python如何访问互联网???
先说python 的urlib
urlib=URL+lib
lib就是library
ULR:即统一资源定位符,也就是我们说的网址。
URL的一般格式为(带方括号【】为可选项)
protocol://hostname[:port]/path/[;parameters][?parameters][?query]#fragment
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。http、https、ftp、ftp等
②第二部分是存有该资源的主机IP地址或者该资源服务器的域名系统(有时也包括端口号,HTTP的默认端口为80)。
③第三部分是主机资源的具体地址,如目录和文件名等。
我们先来尝尝爬虫的滋味:我首先爬的是这个网站http://dasai.lanqiao.cn/pages/dasai/index.html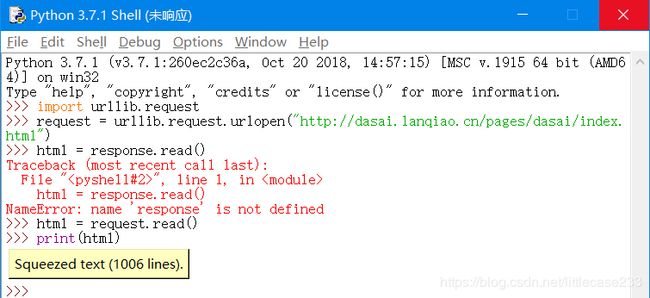
urllib事实上是一个包而不是一个模块,有问题找文档(打开shell按f1):
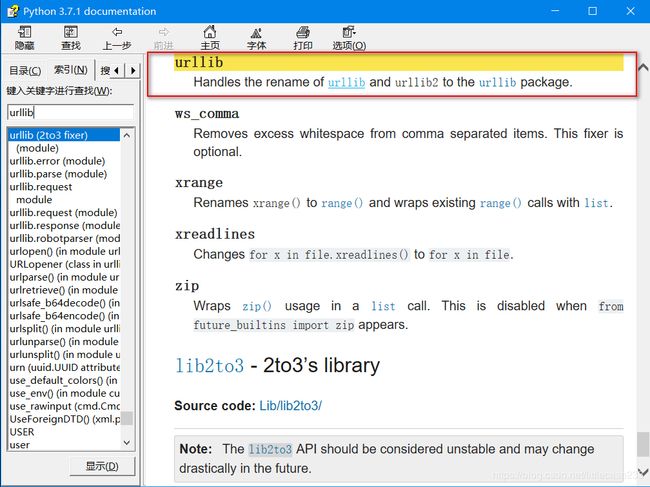
在Python 3以后的版本中,urllib2这个模块已经不单独存在(也就是说当你import urllib2时,系统提示你没这个模块),urllib2被合并到了urllib中,叫做urllib.request 和 urllib.error 。
urllib整个模块分为urllib.request, urllib.parse, urllib.error。
例:
其中urllib2.urlopen()变成了urllib.request.urlopen()
urllib2.Request()变成了urllib.request.Request()
复制里面的text:
这里的b是二进制的意思,我们再往下看:
可以看到这里有我们熟悉的身影,这不就是< head>标签吗,在往下看,有< div>耶,这不就是html的标签吗,如果大家对这些标签不是很熟悉,我建议到菜鸟教程看看 传送门在此 菜鸟教程 ,但是这和我们在网页上按f12看到的不太一样,我们可以把它变得一样:输入:print(html.decode("utf-8"))
回车之后: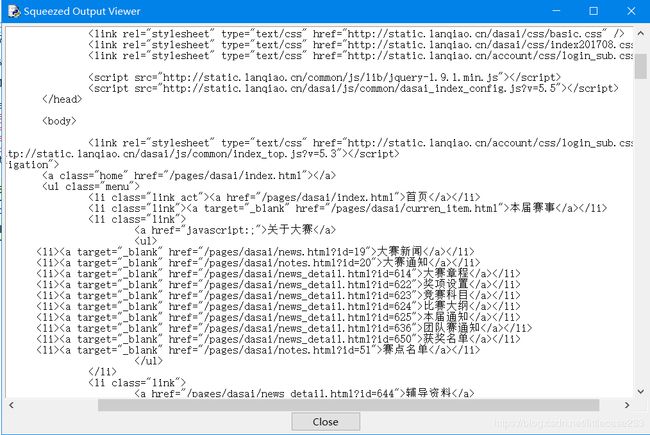
接下来,通过实战来试验一下:
爬谷歌翻译没想到
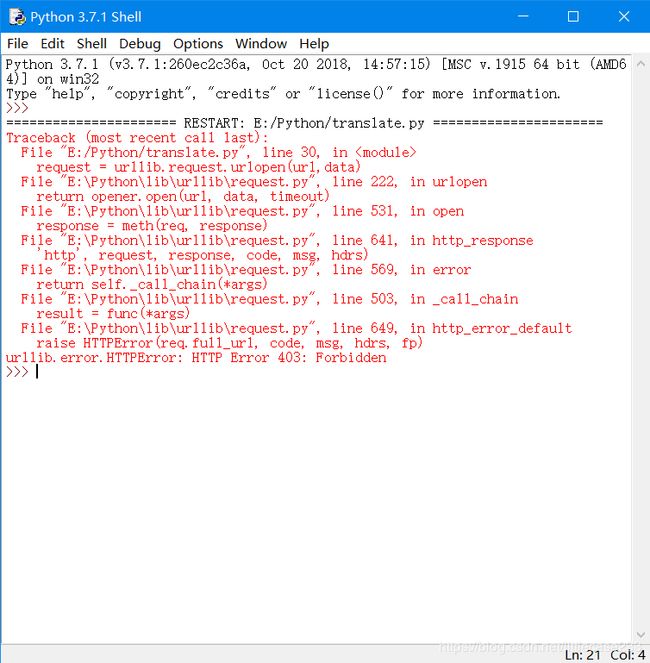
之所以出现上面的异常,是因为如果用 urllib.request.urlopen 方式打开一个URL,服务器端只会收到一个单纯的对于该页面访问的请求,但是服务器并不知道发送这个请求使用的浏览器,操作系统,硬件平台等信息,而缺失这些信息的请求往往都是非正常的访问,例如爬虫.有些网站为了防止这种非正常的访问,会验证请求信息中的UserAgent(它的信息包括硬件平台、系统软件、应用软件和用户个人偏好),如果UserAgent存在异常或者是不存在,那么这次请求将会被拒绝(如上错误信息所示)
没事,我们换一个,但是想爬的话还是可以爬的,网上的博客也有教程。
那我们就爬有道:
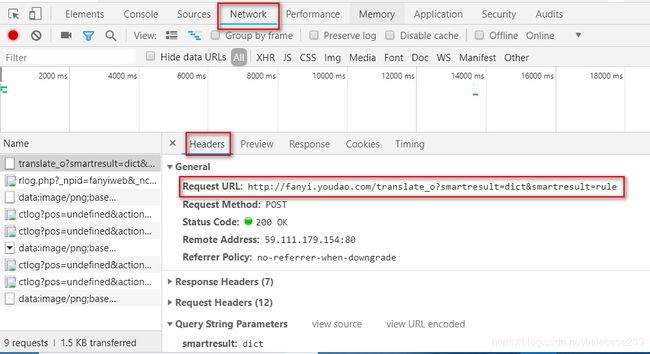
打开有道翻译的网站,按f12,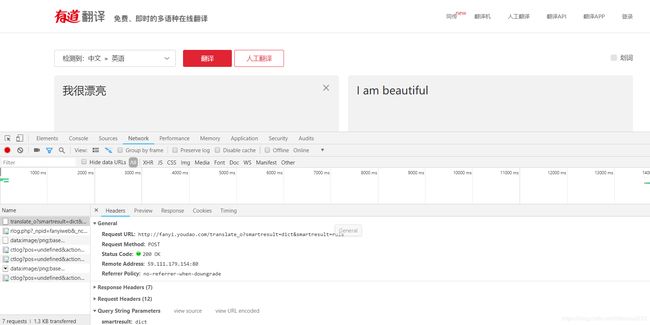
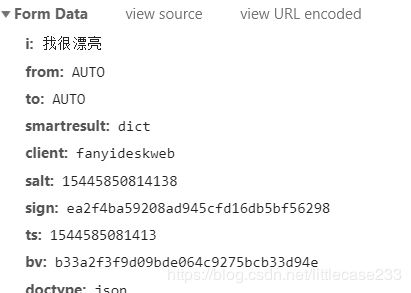
import urllib.request
import urllib.parse
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data={}
data['i']= "我很漂亮"
data['from']= 'AUTO'
data['to']= 'AUTO'
data['smartresult']= 'dict'
data['client']= 'fanyideskweb'
data['salt']= '15445850814138'
data['sign']= 'ea2f4ba59208ad945cfd16db5bf56298'
data['ts']= '1544585081413'
data['bv']= 'b33a2f3f9d09bde064c9275bcb33d94e'
data['doctype']= 'json'
data['version']= '2.1'
data['keyfrom']= 'fanyi.web'
data['action']=' FY_BY_REALTIME'
data['typoResult']= 'false'
data=urllib.parse.urlencode(data).encode('utf-8')
request=urllib.request.urlopen(url,data)
html=request.read().decode('utf-8')
#print(data)
这里的JSON:JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。 这些特性使JSON成为理想的数据交换语言。(来自这里 传送门:介绍JSON)

可以看到这个是字典,然后我们需要获取‘i am beautiful’,然后一层一层地获取,最后的结果对应的key是这个:
target[ 'translateResult'][0][0]['tgt']
再修改一下我们的代码,把formdata里面我们当时输入的文字替换content,
import urllib.request
import urllib.parse
import json
content=input("请输入翻译内容:")
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data={}
data['i']= content
data['from']= 'AUTO'
data['to']= 'AUTO'
data['smartresult']= 'dict'
data['client']= 'fanyideskweb'
data['salt']= '15445850814138'
data['sign']= 'ea2f4ba59208ad945cfd16db5bf56298'
data['ts']= '1544585081413'
data['bv']= 'b33a2f3f9d09bde064c9275bcb33d94e'
data['doctype']= 'json'
data['version']= '2.1'
data['keyfrom']= 'fanyi.web'
data['action']=' FY_BY_REALTIME'
data['typoResult']= 'false'
data=urllib.parse.urlencode(data).encode('utf-8')
request=urllib.request.urlopen(url,data)
html=request.read().decode('utf-8')
target=json.loads(html)
print("翻译结果%s"%(target[ 'translateResult'][0][0]['tgt']))

哒啦,成功!这样我们就可以不用在浏览器查找翻译了。
我试过其他的翻译网站,有些网站并不是很友好,爬有道翻译的话吧url里面的“_o”去掉就好了,当然想爬其他网站的方法还是有的。不过还是建议大家选择到他们的API查找翻译。
好嘞,经过一轮热身之后,就进入真正的实战
想爬哪个网页,想了很久很久很久,于是决定做中国最好大学省份分布情况。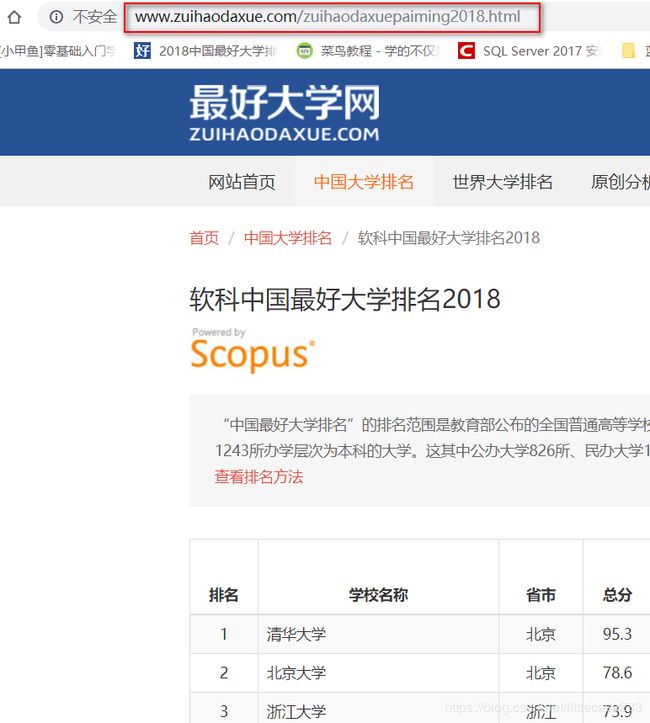
找到中国最好大学的排名的网站 这里有个传送门
上面使我们所需要的URL
在此之前我们需要懂得正则表达式,正则表达式比较难,可以参考菜鸟课程或者其他博客,我之前学习制作前端页面的时候稍微了解正则表达式,感觉原理应该是差不多,大概就是匹配查找字符。
好嘞,接下来我们先获取他的标题,这里每个页面只有一个title标签,所以不用筛选:
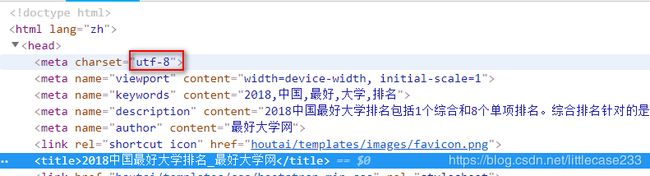
用python中的try-except来捕获相应的异常,代码如下:
这里的response对象了。它有多个方法,这里要讲的是主要是read这个方法,显而易见,就是读取文件内容,然后返回HTML字符串类型。为了防止卡住,建议最好设置timeout参数。
里面还有一个decode() 方法,它是以 encoding 指定的编码格式解码字符串。默认编码为字符串编码。为了防止获得的信息与网页的编码不同,所以我们调用一下它,将获得的文件内容指定为utf-8编码,就不会出现奇怪的东西。
import urllib.request
import re
request=urllib.request.Request('http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html')
try:
response = urllib.request.urlopen(request, timeout=20) # 指定超时秒数,在规定时间内不返回结果,直接raise timeout
content=response.read().decode('utf-8')
except urllib.request.HTTPError as e:
print(e)
except urllib.request.URLError as e:
print (e)
#标题
title=re.compile(r'(.*?) ').findall(content)
print('+++++++++++++++++++'+title[0]+'+++++++++++++++++++')
成功的第一步也算是成功了一大半啦
继续看我们的网页代码,可以看到这个表格几乎都是td标签,所以不能像标题一样直接用标签来提取,所以我们要找到一个特殊的值。又因为,这里头的td标签几乎都一模一样,没有class或者id,各种特殊性都没有,这样很难去获取想要的标签
于是我就想,把省市这个属性作为我们想要提取的信息的索引,也就是,输入省市的名称就返回学校的排名、名称总分,把省市作为突破点,将设置一个变量用来接受这个输入值,然后把这个变量放入正则表达式中,让它变得“特殊”起来。
import urllib.request
import re
request=urllib.request.Request('http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html')
try:
response = urllib.request.urlopen(request, timeout=20) # 指定超时秒数,在规定时间内不返回结果,直接raise timeout
content=response.read().decode('utf-8')
except urllib.request.HTTPError as e:
print(e)
except urllib.request.URLError as e:
print (e)
#标题
title=re.compile(r'(.*?) ').findall(content)
print('+++++++++++++++++++'+title[0]+'+++++++++++++++++++')
#输入省市 查找学校
shengshi_input=input("请输入省市:")
shengshi= re.compile(shengshi_input,re.S)
shengshiming = shengshi.findall(content)
print(shengshiming)
运行一下:

又成功了一大半了!
说话上面用到的RE,我们import了一个re模块,这个模块提供了与 Perl 相似l的正则表达式匹配操作。Unicode字符串也同样适用,这里简单的说一下
1.martch和search的区别
Python提供了两种不同的原始操作:match和search。match是从字符串的起点开始做匹配,而search(perl默认)是从字符串做任意匹配。
注意:当正则表达式是’ ^ '开头时,match与search是相同的。match只有当且仅当被匹配的字符串开头就能匹配 或 从pos参数的位置开始就能匹配 时才会成功。
2.模块内容
re.compile(pattern, flags=0)
编译正则表达式,返回RegexObject对象,然后可以通过RegexObject对象调用match()和search()方法。
re.match(pattern, string, flags=0)
字符串的开头是否能匹配正则表达式。返回_sre.SRE_Match对象,如果不能匹配返回None。
re.findall(pattern, string, flags=0)
找到 RE 匹配的所有子串,并把它们作为一个列表返回。这个匹配是从左到右有序地返回。如果无匹配,返回空列表。
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
这里主要用到的是re.S
使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。由于td标签在HTML中是过行的,而且,还有缩进,所以和中间要加上一个.*?或者.s+,前者如果导入re模块再添加上re.S,就几乎可以匹配所有字符串了。包括换行,空格字符等
我们需要获取信息是学校排名、学校名称、总分: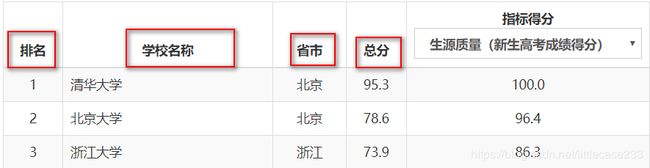
先获取它的总分:
import urllib.request
import re
request=urllib.request.Request('http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html')
try:
response = urllib.request.urlopen(request, timeout=20) # 指定超时秒数,在规定时间内不返回结果,直接raise timeout
content=response.read().decode('utf-8')
except urllib.request.HTTPError as e:
print(e)
except urllib.request.URLError as e:
print (e)
#标题
title=re.compile(r'(.*?) ').findall(content)
print('+++++++++++++++++++'+title[0]+'+++++++++++++++++++')
#输入省市 查找学校
shengshi_input=input("请输入省市:")
shengshi= re.compile(shengshi_input,re.S)
shengshiming = shengshi.findall(content)
#总分
zongfen=re.compile(r''+shengshi_input+' .*?(\d+\.\d) ',re.S)
zongfen_a=zongfen.findall(content)
print(zongfen_a) #先把他打印出来看看
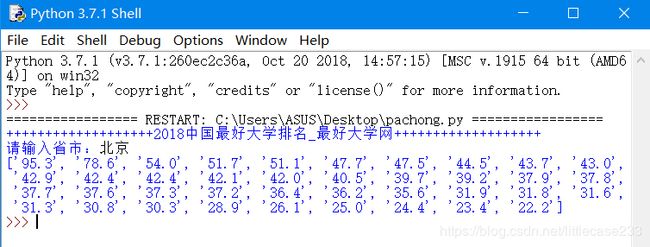
OK 又可以了。接下来获取他的学校名称: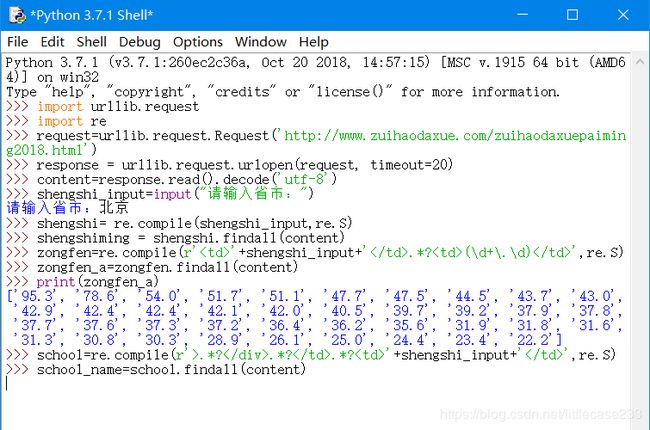
哦豁,完蛋了,学校名称查找不到!!难道是因为我的正则表达式写错了???
哦豁,不是我的正则表达式错了: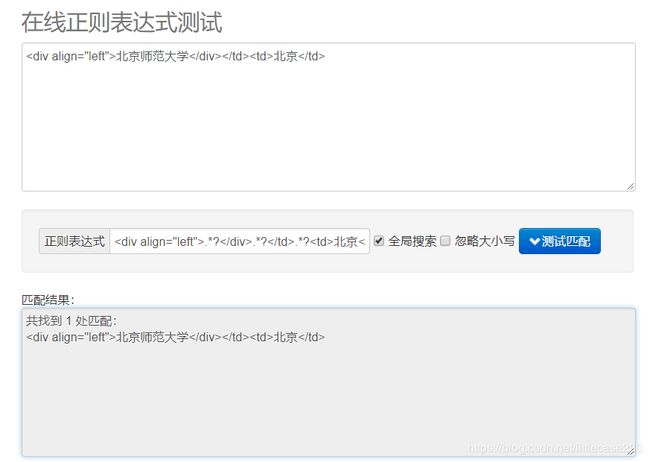
经过两天的排查,原来还是我的正则表达式写得不好,因为我写的正则表达式是贪婪的,所以它把一些不相关的东西也会包含进来 比如说,两个北京之间的东西都包含进来了,
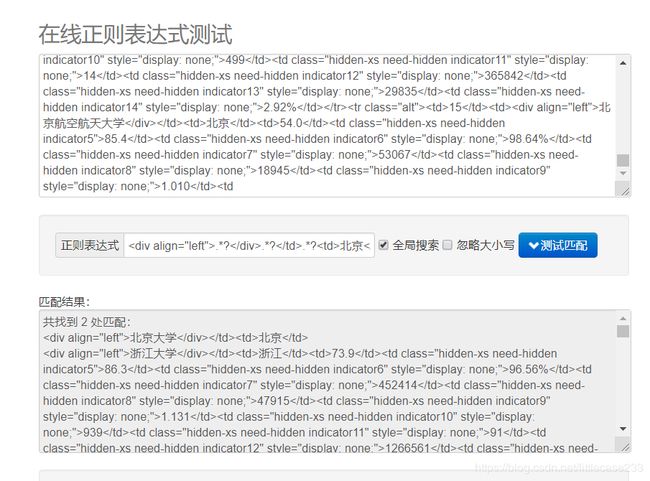
OK ,fine~,挣扎了两天,我选择用BeautifulSoup o(╥﹏╥)o
BeautifulSoup的语法不难,看看文档,很快能够上手,传送门在此
如果看不懂的话可以看嵩老湿的视频传送门在此
from bs4 import BeautifulSoup
import urllib.request
request = urllib.request.Request('http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html')
response = urllib.request.urlopen(request)
content=response.read().decode('utf-8')
soup = BeautifulSoup(content,"html.parser")
print("++++++++++++++++++++++",soup.title.string,"++++++++++++++++++++++")
shengshi_input=input("请输入省市:")
#+++++++++++我是分割线+++++++++++++++++
# tr_list = content.find_all(lambda e: e.name == 'tr' and shengshi_input in e.text) 这里美中不足的地方
#是标签的名字是tr并且标签里面有你输入的地名都会被获取,比如说,学校名有北京两个字,但是不是在北京也会被获取
tr_list = soup.find_all('tr',{'class':'alt'})
for i in tr_list: #遍历tr列表
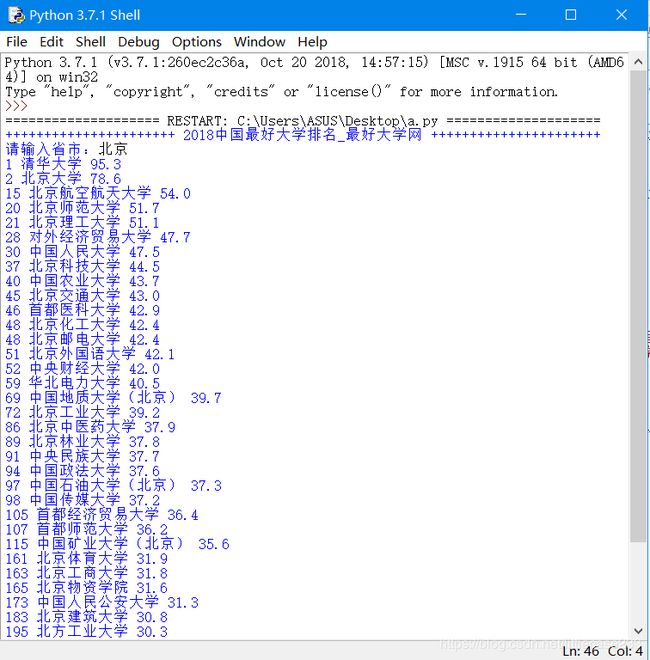
if i.find_all('td')[2].text==shengshi_input: #如果tr里面第二个td的内容文字是你输入的内容文字一样,则输出对应的排名,学校名称,总分
print(i.find_all('td')[0].text,i.find_all('td')[1].text,i.find_all('td')[3].text)
前面的东西没怎么改,主要是改后面如何获取标签内的内容的方法:主要思路是先获取首先得到类名为alt的所有tr标签,然后进行判断即第二个td的内容是否与输入的内容一样,如果真,就把当前tr里面想要的td里面的内容找出来,然后打印。

得到类名为alt的所有tr标签,抽取所有的tr,打印一下tr_list,得出的结果是:![]()
bs4.element.ResultSet 其实是一个list,list中的每个元素还是bs4.element.Tag,然后我们遍历这个list进行判断,第二个td里面的文字与输入的文字进行判断,是真的话打印第0、1、3个td
最后用format()美化一下,让文字居中,看起来好看一些,献上最后的代码:
from bs4 import BeautifulSoup
import urllib.request
request = urllib.request.Request('http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html')
response = urllib.request.urlopen(request)
content=response.read().decode('utf-8')
soup = BeautifulSoup(content,"html.parser")
print(soup.title.string.center(65,'+'))
shengshi_input=input("请输入省市名:")
# tr_list = content.find_all(lambda e: e.name == 'tr' and shengshi_input in e.text) 这里美中不足的地方
#是标签的名字是tr并且标签里面有你输入的地名都会被获取,比如说,学校名有北京两个字,但是不是在北京也会被获取
format_a = '{0:^10}\t{1:{3}^10}\t{2:^10}'
# 定义输出模板为变量format,\t为横向制表符,^为居中对齐,10为每列的宽度
print(format_a.format("排名","学校名称","总分",chr(12288)))
print(" ")
tr_list = soup.find_all('tr',{'class':'alt'})
for i in tr_list:#遍历tr列表
if i.find_all('td')[2].text==shengshi_input:#如果tr里面第二个td的内容文字是你输入的内容文字一样,
#则输出对应的排名,学校名称,总分
print(format_a.format(i.find_all('td')[0].text,i.find_all('td')[1].text,i.find_all('td')[3].text,chr(12288)))
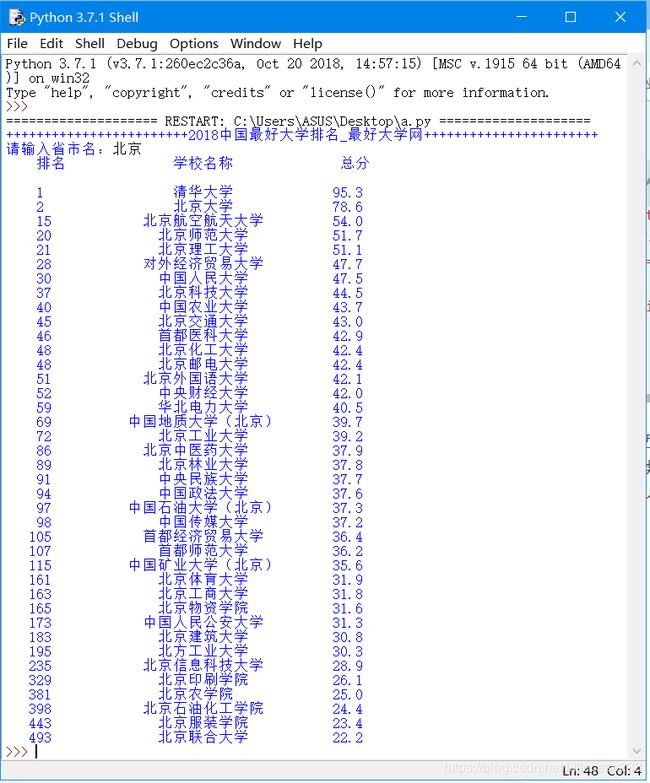
ok 完美。