Hierarchical softmax 和 negative sampling:值得一讲的短文
我决定,利用一些时间,做一些无用的功——翻译一篇博客,说不定自己会对Hierarchical softmax and negative sampling有更深的了解,不然闲着也是闲着。
严格的说,它是前一篇文章的延续,因为在这一篇文章中,会讨论到更多方法上的细节,这些细节有助于完成词嵌入,例如用softmax函数计算激活层。我们将使用通过softmax得到的输出向量作为单词的向量表示,那为什么需要新的训练方法输出我们的单词向量?它们有什么好处呢?它们表现的很好吗?它们与原来的不同吗?接下来我将会解释它,我相信通过接下来的解释,一切都会变得很清楚。
直觉和先决条件(softmax)
正如前面提到的,softmax(正则的指数函数)是输出层函数,他可以用于计算至少两种不同类型的常见词嵌入:word2vec, FastText。另外,它与sigmoid和tanh函数都是许多种类型的神经网络架构的激活步骤,softmax的公式如下:
p ( w j ∣ w I ) = y j = e x p ( u j ) ∑ j ′ = 1 V e x p ( u j ′ ) p(w_{j}|w_{I}) = y_{j} = \frac{exp(u_{j})}{\sum_{j'=1}^{V}exp(u_{j'})} p(wj∣wI)=yj=∑j′=1Vexp(uj′)exp(uj)
激活了的输出向量中的每一个元素都是这个单词在给定输入单词I的情况下,等于单词表中第j个单词的概率,其中,输出向量的元素总和是1,并且每一个元素都在[0,1]之间(这段话暂且保留,我知道作者的意思,但是我举不出来例子,后面有机会我想看看有什么简单的例子,便于理解)。
这个算法的复杂性就直接是我们单词表的大小O(V)。事实表明,我们使用二叉树的结构可以简化这个复杂性,那为什么不呢?这就引出了分层(hierarchical) softmax。
Hierarchical softmax
使用分层softmax可以使时间复杂度变为 l o g 2 V log_{2}V log2V,而不是 V V V。这在计算算法的复杂性和算法步骤的数量时,是一个巨大的改变。我们使用二叉树来达到这个目的,其中,叶子节点表示单词的概率,第 j j j个叶子节点是第 j j j个单词的概率,并且在输出的softmax向量中的位置也是 j j j。
我们可以根据从根节点经由内部节点得到的路径表示每一个单词,沿着那条路可以得到概率质量(离散变量的概率)。这些值可以产生于简单sigmoid函数,只要我们计算的路径仅仅是由下面公式定义的概率质量函数的乘积(没大懂)。
σ ( x ) = 1 1 + e x p ( − x ) \sigma (x) = \frac{1}{1+exp(-x)} σ(x)=1+exp(−x)1
那在我们的应用中, x x x是什么呢?它是输入和输出的单词表示向量的点积:
x = u n ( w , j ) = v n ( w , j ) ′ T v w I x = u_{n(w,j)} = v'^{T}_{n(w,j)} v_{w_{I}} x=un(w,j)=vn(w,j)′TvwI
其中 n ( w , j ) n(w,j) n(w,j)是属于第 j j j个单词的路径里,从根节点开始,到我们要计算概率质量的 w w w。(我也没看懂,作者说在她的上一篇文章中有更详细的解释)
事实上我们可以以概率来替换sigmoid符号;在二叉树中,对每一个内部节点,任意选择它的一个孩子节点(左孩子或右孩子),给他们分配正的sigmoid函数值(通常是左孩子)。通过保留这些约束,第n个节点的左孩子的sigmoid函数可以改为如下的形式:
p ( n , l e f t ) = σ ( v n ′ T h ) = σ ( v n ′ T v w I ) p(n,left) = \sigma(v'^{T}_{n}h) = \sigma(v'^{T}_{n}v_{w_{I}}) p(n,left)=σ(vn′Th)=σ(vn′TvwI)
同理,第n个节点的右孩子的sigmoid函数可以改为如下的形式:
p ( n , r i g h t ) = σ ( − v n ′ T h ) = σ ( − v n ′ T v w I ) p(n,right) = \sigma(-v'^{T}_{n}h) = \sigma(-v'^{T}_{n}v_{w_{I}}) p(n,right)=σ(−vn′Th)=σ(−vn′TvwI)
通过前面的工作,我们已经收集了最终函数计算的所有部分,包括前面的所有步骤以及使用我们选择的任一节点进行布尔检验:
p ( w ∣ w I ) = ∏ j = 1 L ( w ) − 1 σ ( < n ( w , j + 1 ) = c h ( n ( w , j ) ) > v n ′ T v w I ) p(w|w_{I}) = \prod\limits^{L(w)-1}_{j=1}\sigma(<n(w,j+1) = ch(n(w,j))>v^{'T}_{n}v_{w_{I}}) p(w∣wI)=j=1∏L(w)−1σ(<n(w,j+1)=ch(n(w,j))>vn′TvwI)
其中角括号表示布尔检验,也就是判断这个实例是真的还是假的; L ( w ) L(w) L(w)是树的高度, c h ( n ) ch(n) ch(n)是节点 n n n的孩子节点。
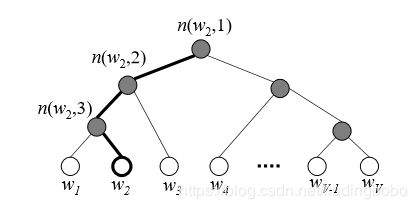
如果树有根节点,有两个内部节点,和叶子节点,那么显然我们的计算是分三步的,这样,就简化了问题的复杂度。
负样例
负样例的思想基于噪声对比评估的观念(如:生成对抗网络),也就是说,一个好的模型,应该通过逻辑回归的方法区分真假信号。同时,负样例的目标与随机梯度下降的目标相似:通过每次改变K个观察值的权重,而不是所有观察值的权重,以大限度的增加计算的效率。
一个观察值的负样例目标如下:
log p ( w ∣ w I ) = log σ ( v w ′ T v w I ) + ∑ i = k K E w i ∼ p n ( w ) [ log σ ( − v w ′ T v w I ) ] \log p(w|w_{I}) = \log \sigma(v^{'T}_{w} v_{w_{I}}) + \sum\limits_{i=k}^{K}E_{w_{i}\sim p_{n(w)}}[\log \sigma(-v^{'T}_{w} v_{w_{I}})] logp(w∣wI)=logσ(vw′TvwI)+i=k∑KEwi∼pn(w)[logσ(−vw′TvwI)]
正如我们所看到的,与随机梯度下降法的区别在于,我们不仅考虑了一个观测结果,而是同时考虑了其中的K个。
我们使用的概率分布是噪声分布,使用噪声分布的原因是由于需要从假数据中辨别真数据。
合适的噪声分布是unigram分布:
P ( w i ) = f ( w i ) 3 / 4 ∑ j = 0 n ( f ( w j ) 3 / 4 ) P(w_{i} ) = \frac{f(w_{i})^{3/4}}{\sum_{j = 0}^{n}(f(w_{j})^{3/4})} P(wi)=∑j=0n(f(wj)3/4)f(wi)3/4
其中,3/4是通过实验得到的合适的值; f ( w ) f(w) f(w)是单词在语料库中出现的频率。
如果我们使用word2vec理论中得到的skim-gram模型,那么负样例是单词,而不是文本;正样例是文本。
总结
原文链接:
https://towardsdatascience.com/hierarchical-softmax-and-negative-sampling-short-notes-worth-telling-2672010dbe08