提交第一个spark作业到集群运行
写在前面
接触spark有一段时间了,但是一直都没有真正意义上的在集群上面跑自己编写的代码。今天在本地使用scala编写一个简单的WordCount程序。然后,打包提交到集群上面跑一下…
在本地使用idea开发,由于这个程序比较简单,我这里就直接给出代码。
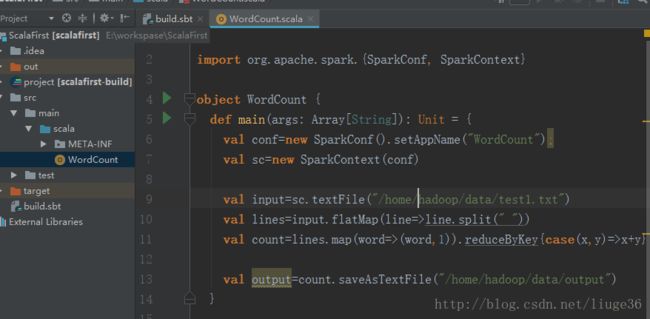
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("WordCount");
val sc=new SparkContext(conf)
val input=sc.textFile("/home/hadoop/data/test1.txt")
val lines=input.flatMap(line=>line.split(" "))
val count=lines.map(word=>(word,1)).reduceByKey{case(x,y)=>x+y}
val output=count.saveAsTextFile("/home/hadoop/data/output")
}
}
代码,写完之后,就是打包成一个jar文件
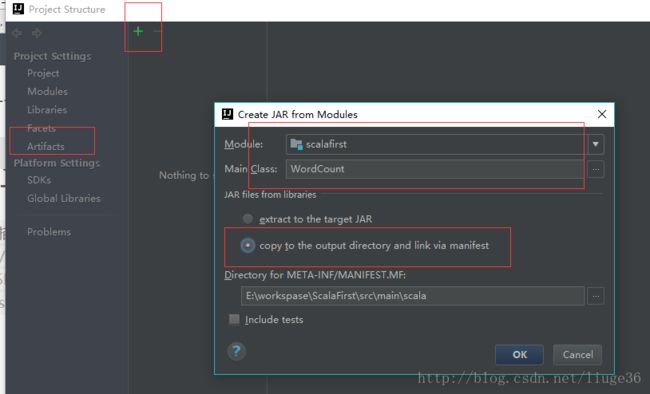
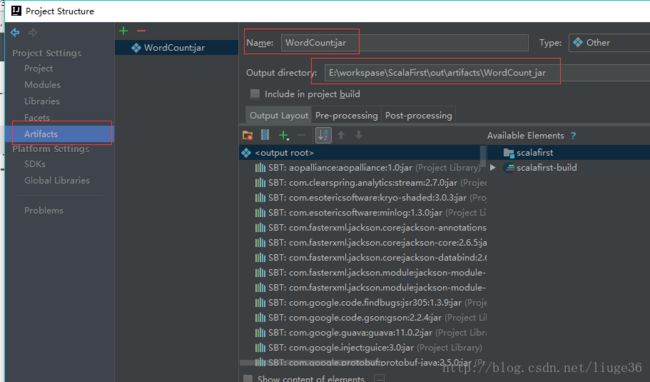
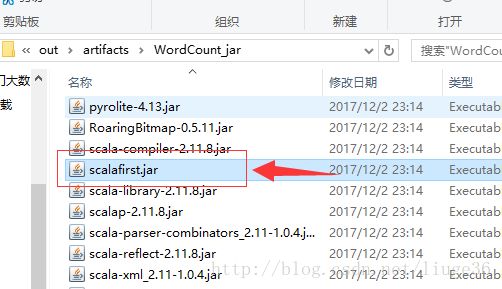
接着,上传生成的架包到集群
[hadoop@hadoop000 jars]$ rz
[hadoop@hadoop000 jars]$ ls
scalafirst.jar
[hadoop@hadoop000 jars]$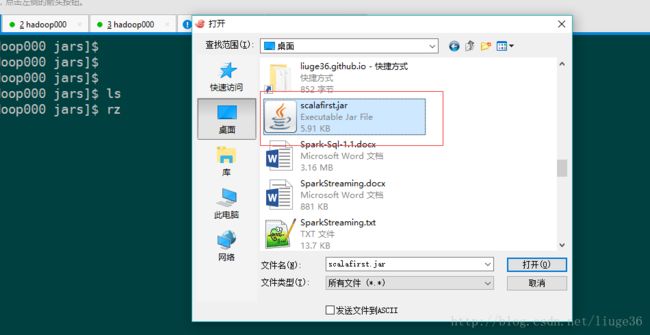
我们的架包上传好了之后,我们就可以启动spark集群了
在开始之前,先来查看一下需要统计的文件:

启动master
[hadoop@hadoop000 sbin]$ pwd
/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/sbin
[hadoop@hadoop000 sbin]$ ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-hadoop000.out
[hadoop@hadoop000 sbin]$
查看结果:
[hadoop@hadoop000 sbin]$ jps
25266 Master
25336 Jps
22815 SparkSubmit
[hadoop@hadoop000 sbin]$ 可以看见master启动成功
启动worker
[hadoop@hadoop000 spark-2.2.0-bin-2.6.0-cdh5.7.0]$ ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://hadoop000:7077查看结果:
[hadoop@hadoop000 ~]$ jps
25266 Master
25356 Worker
25421 Jps
22815 SparkSubmit
[hadoop@hadoop000 ~]$ 上面的worker也是成功启动了
提交作业,计算结果
[hadoop@hadoop000 spark-2.2.0-bin-2.6.0-cdh5.7.0]$ ./bin/spark-submit --master spark://hadoop000:7077 --class WordCount /home/hadoop/jars/scalafirst.jar
17/12/02 23:05:23 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/02 23:05:25 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
[Stage 0:> (0 + 0) / 2[Stage 0:> (0 + 1) / 2[Stage 0:> (0 + 2) / 2[Stage 0:=============================> (1 + 1) / 2[Stage 1:> (0 + 0) / 2[Stage 1:> (0 + 1) / 2[Stage 1:=============================> (1 + 1) / 2 [hadoop@hadoop000 spark-2.2.0-bin-2.6.0-cdh5.7.0]$
查看结果:
[hadoop@hadoop000 data]$ pwd
/home/hadoop/data
[hadoop@hadoop000 data]$ cd output/
[hadoop@hadoop000 output]$ ls
part-00000 part-00001 _SUCCESS
[hadoop@hadoop000 output]$ cat part-00000
(hive,1)
(,1)
(hello,5)
(kafka,1)
(sqoop,1)
[hadoop@hadoop000 output]$ cat part-00001
(spark,1)
(hadoop,1)
(flume,1)
(hbase,1)
[hadoop@hadoop000 output]$
可以参照之前的:
好的,到这里,我们的统计就已经完成了,可以看见结果也是没有问题的。就这样简单的三个步骤我们就在集群上面跑了我们的第一个程序。如果,你是初学者,不妨一试哟。。