Docker学习笔记 — Swarm搭建Docker集群
http://www.cnblogs.com/rio2607/p/4445968.html#undefined
Swarm介绍
Swarm是Docker公司在2014年12月初发布的一套较为简单的工具,用来管理Docker集群,它将一群Docker宿主机变成一个单一的,虚拟的主机。Swarm使用标准的Docker API接口作为其前端访问入口,换言之,各种形式的Docker Client(docker client in Go, docker_py, docker等)均可以直接与Swarm通信。Swarm几乎全部用Go语言来完成开发,上周五,4月17号,Swarm0.2发布,相比0.1版本,0.2版本增加了一个新的策略来调度集群中的容器,使得在可用的节点上传播它们,以及支持更多的Docker命令以及集群驱动。
Swarm deamon只是一个调度器(Scheduler)加路由器(router),Swarm自己不运行容器,它只是接受docker客户端发送过来的请求,调度适合的节点来运行容器,这意味着,即使Swarm由于某些原因挂掉了,集群中的节点也会照常运行,当Swarm重新恢复运行之后,它会收集重建集群信息。下面是Swarm的结构图:
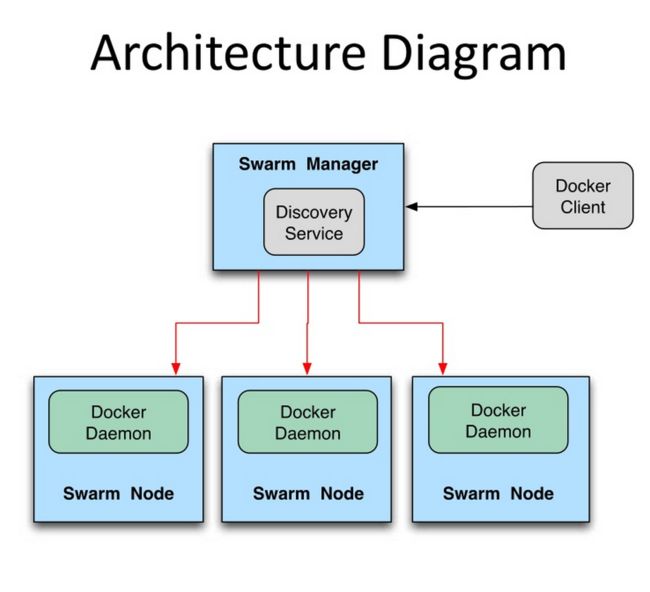

如何使用Swarm
有3台机器:
sclu083:10.13.181.83
sclu084:10.13.181.84
atsg124:10.32.105.124
利用这三台机器创建一个Docker集群,其中sclu083同时充当swarm manager管理集群。
Swarm安装
最简单的安装Swarm的方式就是用Docker官方提供的Swarm镜像:
$ sudo docker pull swarm
Docker集群管理需要服务发现(Discovery service backend)功能。Swarm支持以下几种discovery service backend:Docker Hub上面内置的服务发现功能,本地的静态文件描述集群(static file describing the cluster),etcd(顺带说一句,etcd这玩意貌似很火很有前途,有时间研究下),consul,zookeeper和一些静态的ip列表(a static list of ips)。本文会详细介绍前面两种方法backend的使用。
在使用Swarm进行集群管理之前,需要先把准备加入集群的所有的节点的docker deamon的监听端口修改为0.0.0.0:2375,可以直接使用sudo docker –H tcp://0.0.0.0:2375 &命令,也可以在配置文件中修改
$ sudo vim /etc/default/docker
在文件的最后面添加下面这句
D0OCKER_OPTS="-H 0.0.0.0:2375 –H unix:///var/run/docker.sock"
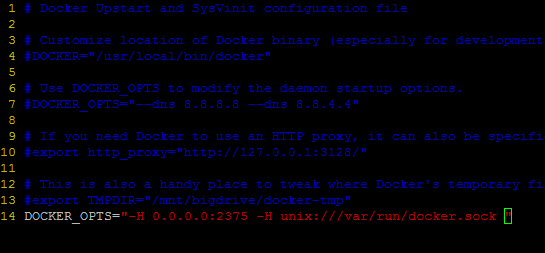
注意:一定是要在所有的节点上进行修改,修改之后要重启docker deamon
$ sudo service docker restart
第一种方法:使用Docker Hub上面内置的服务发现功能
第一步
在任何一个节点上面执行swarm create命令来创建一个集群标志。这条命令执行完毕之后,swarm会前往Docker Hub上内建的发现服务中获取一个全球唯一的token,用以唯一的标识swarm管理的Docker集群。
$ sudo docker run --rm swarm create
我们在sclu084 这台机器上执行上面的命令

返回的token是d947b55aa8fb9198b5d13ad81f61ac4d,这个token一定要记住,因为接下来的操作都会用到这一个token。
第二步
在所有的要加入集群的机器上面执行swarm join命令,把机器加入集群。
本次试验就是要在所有的三台机器上执行命令。
$ sudo docker run –-rm swarm join –addr=ip_address:2375 token://d947b55aa8fb9198b5d13ad81f61ac4d
在IP地址为10.13.181.84机器上面执行

执行这条命令后不会立即返回 ,我们手动通过Ctrl+C返回。
第三步
启动swarm manager。
因为我们要让sclu083充当Swarm管理节点,所以我们要在这台机器上面执行swarm manage命令
$ sudo docker run –d –p 2376:2375 swarm manage token:// d947b55aa8fb9198b5d13ad81f61ac4d
重点内容需要注意的是:在这条命令中,第一:要以daemon的形式运行swarm;第二:端口映射:2376可以更换成任何一个本机没有占用的端口,一定不能是2375,否则就会出问题。
执行结果如下如所示:
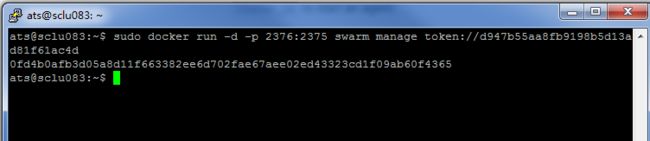
执行完这个命令之后,整个集群已经启动起来了。
现在可以在任何一个节点上查看集群上的所有节点了。

之后可以在任何一台安装了docker的机器上面通过命令(命令中要指明swarm maneger 机器的IP地址和端口)在这个集群上面运行Dcoker容器操作。
现在在10.13.181.85这台机器上面查看集群的节点的信息。info命令可以换成任何一个Swarm支持的docker命令,这些命令可以查看官方文档
$ sudo docker –H 10.13.181.83:2376 info
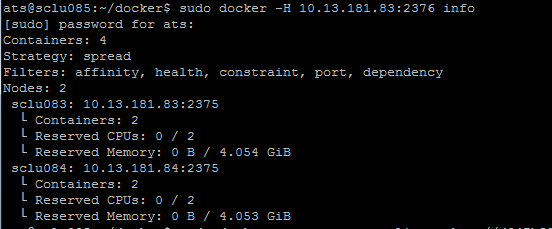
由上图的结果,我们可以发现一个问题:明明这个小集群中是有3个节点的,但是info命令只显示了2个节点。还缺少节点10.32.105.124。为什么会出现这个情况呢?
因为10.32.105.124这台机器没有设置上面的docker daemon监听0.0.0.0:2375这个端口,所以Swarm没办法吧这个节点加入集群中来。
在使用Docker Hub内置的发现服务时,会出现一个问题,就是使用swarm create时会出现
time="2015-04-21T08:56:25Z" level=fatal msg="Get https://discovery-stage.hub.docker.com/v1/clusters/d947b55aa8fb9198b5d13ad81f61ac4d: dial tcp: i/o timeout"
类似于这样的错误,不知道是什么原因,有待解决。(可能是防火墙的问题)
当使用Docker Hub内置的服务发现功能出现问题时,可以使用下面的第二种方法。
第二种方法:使用文件
第二种方法相对而言比第一种方法要简单,也更不容易出现timeout的问题。
第一步
在sclu083这台机器上新建一个文件,把要加入集群的机器的IP地址写进去
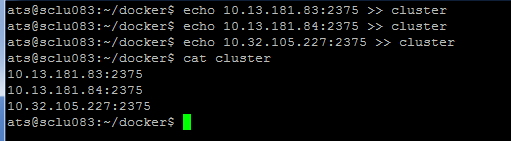
第二步
在sclu083这台机器上面执行swarm manage命令:
$ sudo docker run –d –p 2376:2375 –v $(pwd)/cluster:/tmp/cluster swarm manage file:///tmp/cluster

注意:这里一定要使用-v命令,因为cluster文件是在本机上面,启动的容器默认是访问不到的,所以要通过-v命令共享。还有,file:///千万不能忘记了。
可以看到,swarm已经运行起来了。现在可以查看下集群节点信息了,使用命令:
$ sudo docker run –rm –v $(pwd)/cluster:/tmp/cluster swarm list file:///tmp/cluster

(在使用文件作为服务发现的时候,貌似manage list命令只能在swarm manage节点上使用,在其他节点上好像是用不了)
好了,现在集群也已经运行起来了,可以跟第一种方法一样在其他机器上使用集群了。同样在sclu085 机器上做测试:

可以看到,成功访问并且节点信息是正确的。接下来可以把上面的info命令替换成其他docker可执行命令来使用这个晓得Docker集群了。
Swarm调度策略
Swarm在schedule节点运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random.
Random顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点的可用的CPU, RAM以及正在运行的容器的数量来计算应该运行容器的节点。
在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点(The binpack strategy causes Swarm to optimize for the Container which is most packed.)。
使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在一个节点上面。
过滤器
Constraint Filter
通过label来在指定的节点上面运行容器。这些label是在启动docker daemon时指定的,也可以写在/etc/default/docker这个配置文件里面。
$ sudo docker run –H 10.13.181.83:2376 –name redis_083 –d –e constraint:label==083 redis
Affinity Filter
使用-e affinity:container==container_name / container_id –-name container_1可以让容器container_1紧挨着容器container_name / container_id执行,也就是说两个容器在一个node上面执行(You can schedule 2 containers and make the container #2 next to the container #1.)
先在一台机器上启动一个容器
$ sudo docker -H 10.13.181.83:2376 run --name redis_085 -d -e constraint:label==085 redis
接下来启动容器redis_085_1,让redis_085_1紧挨着redis_085容器运行,也就是在一个节点上运行
$ sudo docker –H 10.13.181.83:2376 run –d –name redis_085_1 –e affinity:container==redis_085 redis
通过-e affinity:image=image_name命令可以指定只有已经下载了image_name的机器才运行容器(You can schedule a container only on nodes where the images are already pulled)
下面命令在只有Redis镜像的节点上面启动redis容器:
$ sudo docker –H 100.13.181.83:2376 run –name redis1 –d –e affinity:image==redis redis
下面这条命令达到的效果是:在有redis镜像的节点上面启动一个名字叫做redis的容器,如果每个节点上面都没有redis容器,就按照默认的策略启动redis容器。
$ sudo docker -H 10.13.181.83:2376 run -d --name redis -e affinity:image==~redis redis
Port filter
Port也会被认为是一个唯一的资源
$ sudo docker -H 10.13.181.83:2376 run -d -p 80:80 nginx
执行完这条命令,任何使用80端口的容器都是启动失败。