64位系统能使用多少内存
疑问
我们知道32位win7一般只能使用4GB内存,原因是如果按照地址宽度是32bit(其实并不是)来算的话系统最多只能管理 232 字节的内存(通过补丁的方式可以使32位win7突破4GB的限制,关键词:ReadyFor4GB,后面我会讲下对其实现原理的猜测)。
那么照这么算,64位系统应该能使用 264 字节的内存,也就是16EB(1EB = 1024PB, 1PB = 1024TB),这也太夸张了吧,谨慎的我还百度了下,结果发现说法不一,有说是192GB的,有说是128GB的,那么到底是多少,又为什么没有直接飙到16EB呢?
于是带着疑问我开始从文档和 Linux 源码中探索这个问题的答案,但本文不涉及内核源码,只是因为操作系统可能会在软件层面对内存做进一步的限制,所以会提到到其中的内存布局,而大部分信息是直接从文档中得出的。
我研究的是 x86_64 的CPU,文档是《64-ia-32-architectures-software-developer-manual-325462_NoRestriction》,可以从这里下载到。文档分3卷(volume):
- 卷1:基础的一些概念,比较无聊,我没有细看
- 卷2:主要讲x86指令集,汇编中用到的那些指令都在这里(有建立每个指令的书签)
- 卷3:操作系统开发者指南(内存管理、中断、异常、进程管理…都在这里了)
卷下面又分了章节,所以后面用 v3:4.1 表示卷3第4章第1节这样子。
Linux 源码看的是 Ubuntu 16.04 内核版本是 4.4.0-31,可以从这里获得Ubuntu Kernel(是从主线 Linux fork 出来并做了改动)的下载方法、编译方法。
四种寻址模式
文档(v3:4.1 Paging Modes and Control Bits)中讲到:x86_64 CPU(是指支持64位寻址的 x86 指令集的CPU,据说64位CPU从2005年下半年开始普及,所以除了古董级的CPU,否则都是支持64位的)可工作在4种内存寻址模式下(不考虑8086模式——只能寻址1MB内存):
- 不分页模式(没有魔法,只支持4GB)
- 32位分页模式(有魔法,能超过4GB)
- PAE分页模式(32位地址+64位的页表项,这个应该属于过渡阶段)
- IA-32e分页模式(也就是目前的”64位模式”)
按照该章节的描述,后三种模式都必须启动分页管理,关闭分页就会回到第一种模式。
第一种模式是最简单的,程序中使用的32位的虚拟地址(有的地方也称之为逻辑地址或相对地址)+段的32位起始地址(x86 CPU总是分段管理内存的,分页是可选的)得出一个线性地址,这个线性地址直接当成物理地址来用。但是基本没有操作系统启动完毕后是这样使用内存的,因为分页管理的好处太多了,不开启简直就是犯罪啊:
- 交换内存(虚拟内存),x86 默认是 4KB 分页,操作系统可以将一些长久没有使用的内存页交换到外存上(一页只有4KB,写盘是非常快的),然后这些页就可以分配到别的地方使用,这样可以使得”内存容量”大增,而调度得好的话在性能上影响不大。
- 延迟装载,现在一个游戏安装程序动辄上G,如果一次性装载完再执行,那等个几分钟才出安装界面也是正常的,实际上各种操作系统都用CPU的分页机制实现了延迟装载:装载程序时会在进程中建立内存页到可执行文件的映射,并将相应的页表项初始化为不可用状态,等执行到这个页的指令或访问这个页的数据时CPU就会触发缺页异常,操作系统到这个时候才根据映射把相应的指令或数据读到某页内存中并修改原来不可用的页表项指向它,然后重新执行导致异常的那条指令。所以即使是上G的程序也是瞬间装载的。
- 共享内存,我们可以复制页表来实现进程间内存的共享。比如fork子进程就很快,因为只是复制了页表,所以子进程一开始是直接使用父进程内存的。再比如动态链接库,它们的指令所占内存页是在各个进程中共享的,所以公共动态链接库的繁荣可以减少内存占用。
- copy on write,除了上面提到的缺页异常可实现延迟装载,还有个页保护异常可实现 copy on write,每个页表项有记录该页是否可写的标志位,当某进程fork一个子进程的时候会将所有可写的内存页设置为不可写,当子进程修改数据时会触发页保护异常,操作系统会将该页复制一份让子进程修改,父进程的数据完全不受影响。
32位分页模式
32位分页模式相较于不分页的情况,多了个线性地址->物理地址的转换,一般情况下这个转换分两级:
- CR3 寄存器高20位(31:12 bit)存着第一级页目录表(4KB大小)的物理地址的高20位(低12位全部为0,这样的物理地址是4KB对齐的),页目录表可看成是个长度为1024的数组,每个元素的大小是4字节,它的低12位(11:0 bit)是一些标志位,比如第0位标志着这个页目录项是否可用,如果可用则高20位记录着下一级页表的物理地址,如果不可用那么线性地址如果走这个页目录项转换就会发生缺页异常。
第一级转换取线性地址的高10位(31:22 bit)作为数组下标定位页目录表中的项。 - 第二级页表也是4KB大小,也分为1024项,第0位也是可用与否的标志位,如果可用则高20位记录着一个内存页的物理地址,这里用线性地址的21:12 bit 来定位页表项,经过这两级映射最终得出了一个4KB内存页的起始地址,再加上线性地址的低12位页内偏移就得出了最终的物理地址。
文档(v3:4.3 32-Bit Paging)还给了一张非常形象的图来演示这个映射过程:
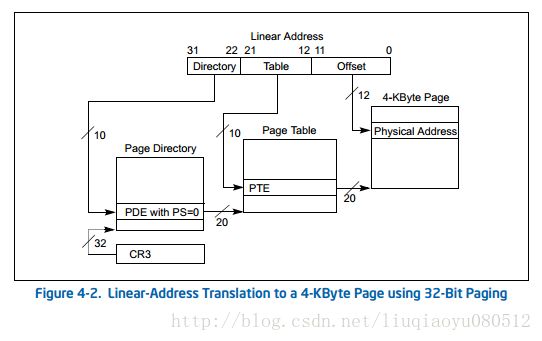
如果完全按上面这种方式映射的话,那么转换后还是32位的地址,那么最多也只能用4GB内存了。但是第一级页目录项还可以直接映射一个4MB的内存页——当页目录项中第7位为1的时候(为0就还有一级页表要转换,也就是上面的情况)。
这时页目录项的高10位(31:22 bit)作为物理地址的31:22 bit,低22位取线性地址的低22位作为页内偏移,然后相比于上面的映射,21:12 bit这里还有10个位空出来了,然后CPU就发扬了不用白不用的抠门精神,在其中8位(20:13 bit)多存储了物理地址的高8位(39:32 bit,实际上不同型号的CPU支持的位数可能不一样),这样利用映射4MB页的机制我们能使用最大达到40bit的物理地址,也就是高达1TB的内存。下图演示了这种映射:
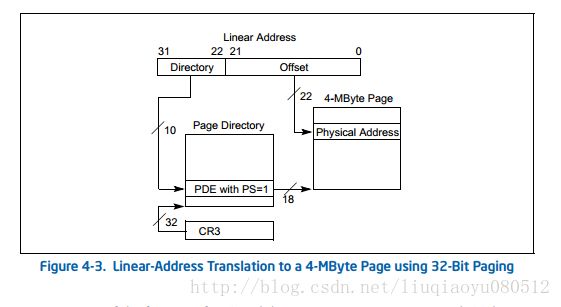
但是这种映射存在一些缺点:
- 线性地址还是32位的,也就是一个进程最多使用4GB内存(32位系统一般设计为一个进程一个页目录表,进程切换时自动修改CR3寄存器)
- 只有4MB的内存页能使用超过4GB的内存,而4MB对于磁盘交换来说未免太大了点,所以一般只能把那种不需要做磁盘交换的内存做4MB映射,比如操作系统内核;当然也可以把这样的内存页分配给需要大块内存的程序。
而PAE分页模式解决了第2个缺点(因为页表项变成了8字节,最后一级页表项也能表示一个宽地址,最高可达52位,跟IA-32e一样),但线性地址还是32位的,也就是单个进程还是最多使用4GB内存,但所有进程加起来理论上可以使用4PB内存(不过要1M个进程,太不现实)。
由此可见32位系统用超过4GB内存也是完全可能的,ReadyFor4GB有可能是通过4MB内存页映射实现的(如果系统原来是32位分页模式的话),也可能是原来就是PAE分页模式只是系统限制了只使用4GB以下内存,也可能是从32位分页模式大改造成PAE分页模式(但这个的难度要高很多,4字节页表项改成8字节页表项,能兼容原来的内核代码?)。
IA-32e(64位模式)
32位线性地址限制了进程的地址空间,即使有超过4GB的内存,在一个进程中也用不了。那么就扩大地址宽度吧,之前我们从16位扩到20位(8088到8086),然后从20位扩到32位(80386),那就扩到48位吧(想想当年把1MB内存当成宝贝,现在一个内碎片都可能超过1MB了)。现在可以放这张全家福了:
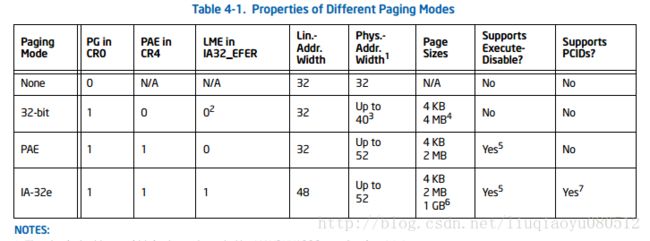
IA-32e模式中线性地址是48位(256TB),物理地址是52位(4PB,最高值,各CPU实际支持的最大宽度普遍低于这个值,后面部分有检测方法)。
48位是6字节,但实际上64位程序中的地址(指针)的大小是8字节,文档(v1:3.3.7.1 Canonical Addressing)规定64位线性地址必须遵循一个规则:如果第47位是0,那么63:48bit全部是0;否则全部是1。其实就是扩展了符号位的意思,如果分页转换前的线性地址不符合这个规则就会触发CPU异常,这个应该是督促系统程序员兼容以后的真64位CPU。于是只有以下地址才是合法的地址:
0x00000000 00000000 ~ 0x00007FFF FFFFFFFF
0xFFFF8000 00000000 ~ 0xFFFFFFFF FFFFFFFF而CPU做线性地址到物理地址转换的时候只取其低48位。这个地址转换有4级,每级还是一个4KB的页表,其中每项8字节,那么就只有512个项,每级用线性地址中的9位做下标索引,4*9=36,刚好剩下12位填充4KB内存页的页内偏移:

让我们来算算各级页表项管理的地址空间的大小:
- PTE 4KB
- PDE 4KB * 512 = 2MB
- PDPTE 2MB * 512 = 1GB
- PML4E 1GB * 512 = 512GB
所以我们看出来了,不直接上64位貌似还挺有道理的,48位就已经很浪费了!第一级页表中一项竟然就映射了512GB的地址空间,我看了下Alienware Area-51才32GB的内存,所以以目前的内存大小来看,砍掉一级变成3级映射也是完全够用的。
在 IA-32e 模式中为了提高地址转换速度,同时为了减少页表数量(确实很有必要,内存越大,页表越多),我们可以在 PDE 中直接映射2MB的内存页(普遍支持),甚至可以在 PDPTE 中直接映射 1GB 的内存页(部分CPU支持,我的E3-1231 v3 刚好支持)。
最大物理地址宽度
某款CPU支持的最大物理地址宽度(maximum physical address bits)可以执行cpuid指令查询(v3:4.1.4 Enumeration of Paging Features by CPUID),如果自己实现的话要自己写个内联汇编程序,但是ubuntu 上有个同名命令行程序可以直接帮我们查出来,如下:
lqy@lqy-All-Series:~/temp$ cpuid | grep 'maximum physical address bits'
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
maximum physical address bits = 0x27 (39)
lqy@lqy-All-Series:~/temp$ 这是我的组装机,CPU是 Intel Xeon E3-1231 v3,四核八线程,可以看出每个处理器支持的最大物理地址宽度是39,也就是512GB。而我2010年买的联想 G450,奔腾双核 T4400,经检查是36位,也就是64GB。
Linux 内核限制
CPU在线性地址宽度上倒是没有打折扣,支持IA-32e的都有48位。但是操作系统的内存管理模型会对这个做进一步的限制,内核源码中有个txt介绍了Linux对x86_64的线性地址布局(Documentation/x86/x86_64/mm.txt):
0000000000000000 - 00007fffffffffff (=47 bits) user space, different per mm
hole caused by [48:63] sign extension
ffff800000000000 - ffff87ffffffffff (=43 bits) guard hole, reserved for hypervisor
ffff880000000000 - ffffc7ffffffffff (=64 TB) direct mapping of all phys. memory
ffffc80000000000 - ffffc8ffffffffff (=40 bits) hole
ffffc90000000000 - ffffe8ffffffffff (=45 bits) vmalloc/ioremap space
ffffe90000000000 - ffffe9ffffffffff (=40 bits) hole
ffffea0000000000 - ffffeaffffffffff (=40 bits) virtual memory map (1TB)
... unused hole ...
ffffec0000000000 - fffffc0000000000 (=44 bits) kasan shadow memory (16TB)
... unused hole ...
ffffff0000000000 - ffffff7fffffffff (=39 bits) %esp fixup stacks
... unused hole ...
ffffffff80000000 - ffffffffa0000000 (=512 MB) kernel text mapping, from phys 0
ffffffffa0000000 - ffffffffff5fffff (=1525 MB) module mapping space
ffffffffff600000 - ffffffffffdfffff (=8 MB) vsyscalls
ffffffffffe00000 - ffffffffffffffff (=2 MB) unused hole其中有3个区域我可以解释一下(其他的不是很了解):
0000000000000000 - 00007fffffffffff (=47 bits) user space, different per mm
这是进程的用户空间,而剩下的ffff80000000以上的空间是系统空间,所以线性地址空间是对半分的,应用程序可使用最大达128TB的地址空间。
ffff880000000000 - ffffc7ffffffffff (=64 TB) direct mapping of all phys. memory
这里占用了系统空间的一半,是对所有物理内存的线性映射,这个映射可以用个函数来表示:
假设线性地址X在这个地址空间中,那么 X的物理地址 = X - 0xffff8800 00000000
因为CPU开启分页后,所有指令中的内存地址都会自动经过分页地址映射转换成物理地址使用,即使是内核也不能直接使用物理地址,内核初始化阶段中会在这片空间中建立起对所有物理内存(<=64TB)的永久映射,这个映射建立好之后,内核就可以用物理地址+0xffff8800 00000000来访问0~64TB之间的任意内存了。
ffffffff80000000 - ffffffffa0000000 (=512 MB) kernel text mapping, from phys 0
这片空间存放着内核指令、数据。所以内核要小于512MB,目前我编译的内核压缩后是7MB,解压后是23MB,这个的512MB是对解压后的内核大小的限制,现在还非常够用。
总结
那么现在总结下 IA-32e 模式下,Ubuntu 64 位系统,从小到大的各种内存限制:
- 应该是主板/内存的限制,我的主板是华硕B85M-V5 PLUS,只有两个DDR3的插槽,目前插了一个8GB,好像16GB的 DDR3 很稀有,16GB 的 DDR4 倒是进入了可接受的价位,但主板不支持,所以最多再加一条 8GB,组成16GB内存。
- 假设主板/内存限制突破了,下一个坎是 CPU的物理地址宽度限制,512GB,如果到时候这个 CPU 还能在当时的硬件上用的话(估计是不可能的)。
- 按照文档的描述,现在难道存在物理地址是52位的 CPU?如果有这样的 CPU,而且以上的限制都不需要考虑的话,下一个坎就到了 Linux 内核这里了,最大可操作64TB的物理内存(可以想象一下:一个特制的主板上插着8192条8GB内存是一幅多么震撼的画面)。
- 再往上就得改内核了,而实际上64TB内存都有了的时候,CPU应该也支持真64位了,而且真的需要这么大的内存么,说不定到时候计算机的结构都不一样了。
因此 x86_64 平台上的 Linux 理论上最多支持64TB的物理内存,单个进程理论上可用128TB的地址空间(高128TB被操作系统占用了),但受限于物理内存的限制,其中最多有64TB是物理内存,其余的理论上还可以用虚拟内存(swap分区)顶包。
最后,我们看一下 Win10 的内存限制,取自微软官网:
| Version | Limit on X86 | Limit on X64 |
|---|---|---|
| Windows 10 Enterprise | 4 GB | 2TB |
| Windows 10 Education | 4 GB | 2TB |
| Windows 10 Pro | 4 GB | 2TB |
| Windows 10 Home | 4 GB | 128GB |
微软果然抠门啊,这种情况必须来一个加钱的理由,不过128GB也应该在相当长的时间里够用了。