Python 并行分布式框架:Celery 超详细介绍
先来一张图,这是在网上最多的一张Celery的图了,确实描述的非常好
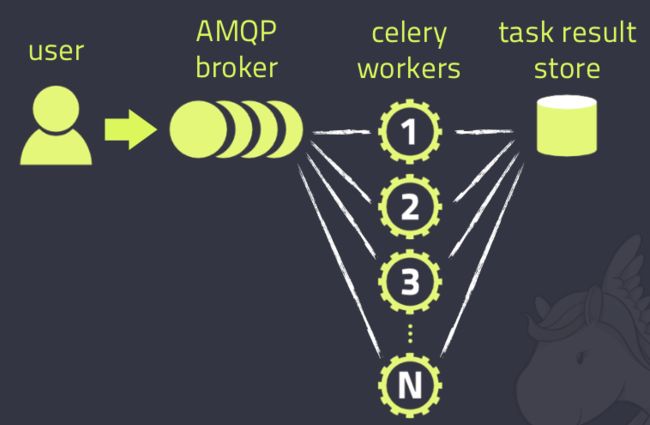
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis, MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy (experimental),Django ORM (experimental), IronMQ
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, Redis,memcached, MongoDB,SQLAlchemy, Django ORM,Apache Cassandra, IronCache
OK 废话就说到这, 来点使用的。
首先你也看到了, 你要有一个消息中间件,此处我们选择rabbitmq,为什么不用redis或者sqs呢,首先这两个我都用过了,想接触以下rabbitmq,所以果断选择这个。
Now 安装rabbitmq!
官网介绍有安装方法, 我贴以下网址吧,自己看看,很简单很简单。 我是Mac系统 http://www.rabbitmq.com/install-standalone-mac.html 如果是其他系统自己对应下。 可以把sbin的路径配置到path里面(我比较懒 没加,所以去到解压目录,囧)
启动管理插件:sbin/rabbitmq-plugins enable rabbitmq_management
启动rabbitmq:sbin/rabbitmq-server -detached
ok, now,rabbitmq已经启动,可以打开页面来看看
地址:http://localhost:15672/#/
用户名密码都是guest
现在可以进来了把,可以看到具体页面。
关于rabbitmq的配置,网上很多 自己去搜以下就ok了。
好了 消息中间件有了,现在该来代码了,我是在celeby官网看的,如果觉得我代码有问题,可以自己去官网看,嘿嘿。
安装celeby。
建议使用 virtualenv,具体怎么用 参考
http://www.nowamagic.net/academy/detail/1330228
http://liuzhijun.iteye.com/blog/1872241
首先,定义一个task。
from celery import Celery
app = Celery('tasks', backend='amqp://guest@localhost//', broker='amqp://guest@localhost//')
@app.task
def add(x, y):
return x + y保存为tasks.py
—>broker 就是中间件了,自己看着改吧, backend就是 后端来发送状态消息,保持追踪任务的状态,存储或发送这些状态
Now 可以启动了
命令: celery -A tasks worker –loglevel=info
想要查看完整的命令行参数列表
命令:celery worker –help 或者
celery help
现在 另开一个terminal,启用虚拟环境, ipython 启动python console
In [9]: from tasks import add
In [10]: result = add.delay(6, 7)现在你可以在用之前命令启动的终端中看到输出,而且可以验证结果。
调用任务会返回一个 AsyncResult 实例,可用于检查任务的状态,等待任务完成或获取返回值, 而且现在我们也设置了一个用于保存结果和状态等信息的backend, 现在你可以成功的拿到结果, 如果你print result, 你会看到一串字符串, 类似与uuid。
如下方式:
In [11]: result.ready()
Out[11]: True
In [12]: result.get(timeout=1)
Out[12]: 13
In [13]: result.get(propagate=False)
Out[13]: 13ok 现在看到结果了吧。
注: propagate的作用 倘若任务抛出了一个异常, get() 会重新抛出异常, 但你可以指定 propagate 参数来覆盖这一行为。
以上就是一些代码了。
下面是 celery的配置,配置的话 你不想看这个 可以去官网看,比我的详细的多。
app.conf.update(
CELERY_TASK_SERIALIZER='json',
CELERY_ACCEPT_CONTENT=['json'], # Ignore other content
CELERY_RESULT_SERIALIZER='json',
CELERY_TIMEZONE='Europe/Oslo',
CELERY_ENABLE_UTC=True,
)但是对于大型项目来说 这样配置就显得很low,这个时候可以用模块。你可以调用 config_from_object() 来让 Celery 实例加载配置模块。
app.config_from_object(‘celeryconfig’)
celeryconfig.py
BROKER_URL = 'amqp://'
CELERY_RESULT_BACKEND = 'amqp://'
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_ACCEPT_CONTENT=['json']
CELERY_TIMEZONE = 'Europe/Oslo'
CELERY_ENABLE_UTC = True可以使用 python -m celeryconfig 来验证配置是否正确。
好了 这是这篇博客的全部,稍后还有有的,谢谢。