Mycat个人心得笔记(五)
Mycat个人心得笔记(五)
目录
Mycat个人心得笔记(五)
一.mycat的配置文件
1.配置文件
2.备份文件
1.server.xml
2schema.xml
3.rule.xml
4.mycat测试案例
一.mycat的配置文件
- 根目录在conf中有两个核心的配置文件,配置内容实现:
- 读写分离,高可用替换,分布式存储,ER分片表的逻辑。
1.配置文件
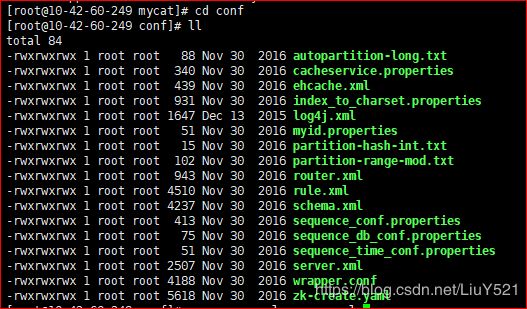
2.备份文件

备份:后缀.back为备份文件
- server.xml:配置当前mcyat启动的资源设定(例如端口占用,线程登录名,密码等)
- schema.xml:逻辑库,逻辑表,分片表,ER表的配置,底层链接的实际数据库信息。
1.server.xml
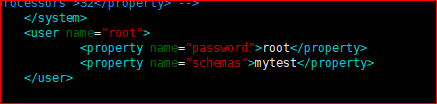
druidparser
root
mytest

1.system标签:定义了一大批的property属性内容,mycat软件,进程启动运行时加载的各种属性,使用的各种配置内容,不开启默认有值.
druidparser 拦截- 用户sql被拦截处理的实际执行者,根据定义的值(druidparser)去jar包中寻找配置的别名类
- 剩下的property都是端口,线程资源数量,启动配置
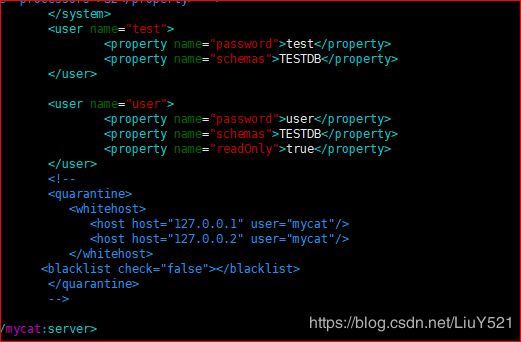
2.user标签:定义连接mycat的用户信息(名,密码,能干什么)
name属性定义就是用户名,
user
password的property标签登录密码,
TESTDB
schemas的property标签给TSETDB当前用户名可以访问的逻辑库schema.xml中配置的名称,
如果想要访问多个,需要用,隔开
TESTDB,MYCATDB,HAHADB
true
是否用户只读
- 修改或添加成如下内容
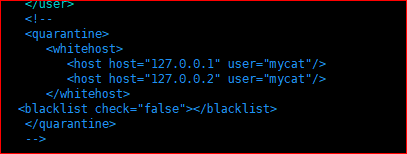
- quarantine标签:与mycat定义的安全信息有关
- whiteHost标签:白名单ip一旦配置,进入的ip地址就会根据白名单筛选
- blackList标签:黑名单sql,满足黑名单配置的sql语句不予执行
- 不会允许任何人在mycat执行select操作;
- 不允许使用select * from table来执行sql语句
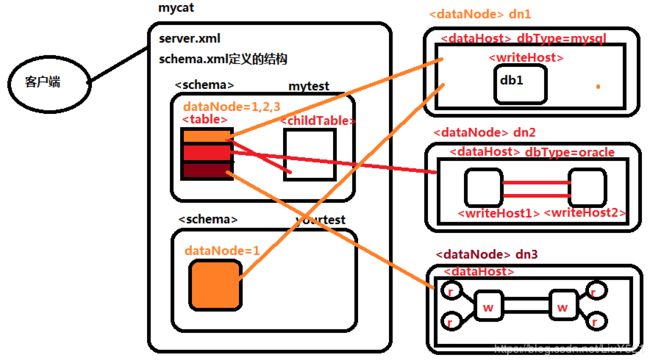
2schema.xml
1.mycat数据库内部结构的概念
- 逻辑库:mycat维护的内存中的对象,对外使用的客户端看到的库名称,实际数据库可能存在可能不存在(名称),数据来源可以被整合;
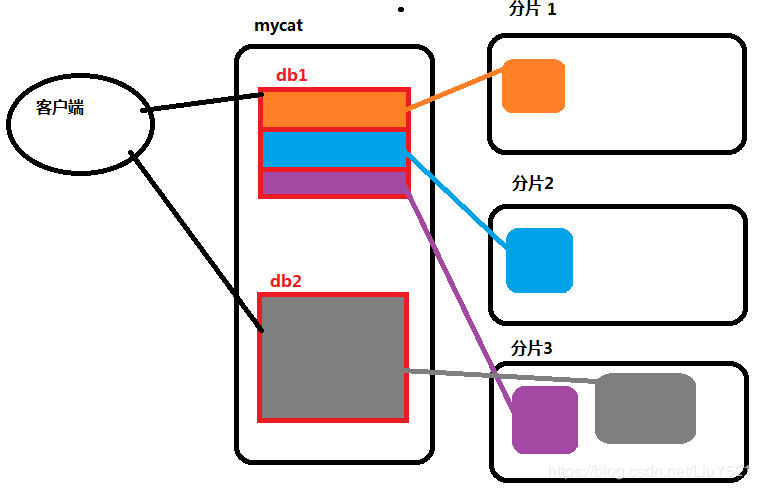
- 逻辑表:逻辑库数据结构的具体体现
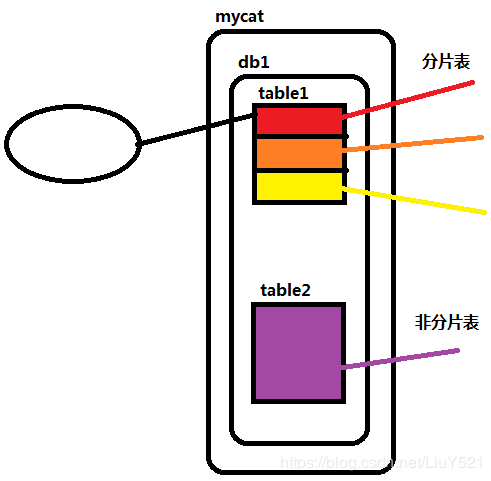
- 非分片表:全部表格数据来自一张后端的真实数据库表格
- 分片表:总体数据量庞大(商品,订单,订单商品),需要切分计算到不同分片处理
- 全局表:多个分片复制同一张表格存储使用
- ER表:涉及到多个表格分片关联关系
2.schema标签
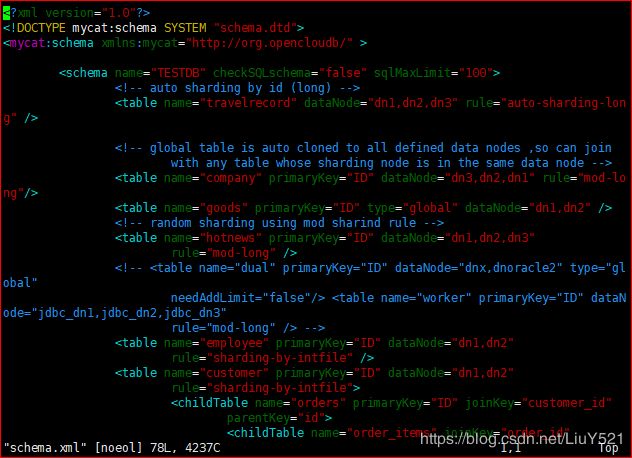
一个schema标签定义一个逻辑库
- name属性:逻辑库的名称,可以和后端数据库不一致
checkSQLschema:
- false 不自动添加连接访问的table的逻辑库名称,
select * from user where id=5;原封不动的发送给mycat处理 (容易出错)
- true 自动添加没有库名称sql语句的逻辑库名称
select * from user where id=5;到达mycat时会变成select * from mytest.user where id=5
sqlMaxLimit:
- 最大查询条数,保护措施,当用户没有天界limit关键字,mycat自动拼接limit 0,100的语句,保护查询中不会宕机;
3.tabal标签:定义逻辑表的标签内容
- name:table逻辑表的名字;一般需要对应真实表格
- dataNode:所有与分片计算有关的内容,都利用dataNode标签内容完成的,table中对应多个dataNode标签名称表示当前逻辑表示分片表
- rule:只要是分片表格定义了rule,就会根据rule的值定义分片计算时的逻辑 auto-sharding-long 根据id切分,0-500w在第一个分片,500w-1000w在第二个分片,1000w-1500w在第三个分片(默认值)
4.childtable标签:表示一个table标签的子标签,定义的是一个逻辑库的子库,实现的内容是ER分片表;
- name:表格的名称,
- primaryKey:主键
- joinKey:外键字段名称
- parentKey:外键字段在主表中的字段名称
5.dataNode标签:定义当前mycat中的分片单位
- name:所有的分片计算都会根据name来完成,
- dataHost:指定一个当前分片管理的数据库结构的标签dataHost
- database:当前分片下所有库的真实数据库名称
6.dataHost标签:管理一个数据库的集群,数据库连接,超时,空闲,读写分离的所有逻辑都是dataHost完成的
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
- name:名称,对应dataNode里绑定的值
- maxCon:连接数据库节点的最大谅解书
- minCon:最小连接数
- balance:读权限的定义
- 0:不开启读的分离,所有的读操作都在第一个writeHost
- 1:全部的readHost和备用writeHost都参与读数据的平衡,如果读的请求过多,负责写的第一个writeHost也分担一部分
- 2:所有的读操作,都随机的在所有的writeHost和readHost中进行
- 3:所有的读操作,都到writeHost对应的readHost上进行(备用writeHost不参加了),在集群中没有配置ReadHost的情况下,读都到第一个writeHost完成
- writeType:写权限设定1值已经在1.5之后的mycat不建议了
- 0:默认从第一个writeHost写数据
- 1:老版本的继承,在多个writeHost时,作用是读写的随机进行;writeType=1屏蔽balcance
- dbType:数据库的类型
- dbDriver:mysql=native,oracle,sqlServer还得指定driver全路径名称,并且再lib中提供jar包.
- switchType:故障转移的逻辑
- 1 表示在多个writeHost直接故障切换
- -1 不切换,只连接第一个writeHost
- slaveThreshHold:定义的从节点读取数据的最大延迟;对应show slave status语句返回结果中一个字段,超过数值就不会再从从节点读取数据
7.heatbeat标签:mycat心跳检测每个数据库节点使用的sql语句,如果想让slaveThreshHold生效.必须使用 show slave status
8.writeHost标签:一个dataHost中维护的数据库主从高可用集群,writeHost作为写的主机,只能配置主节点
password="sf123456">
- host:定义一个当前节点的代号,hostM1,hostM2,hostM3
9.readHost标签:一个dataHost中中维护的数据库主从高可用集群,readHost作为读的注解,主从节点都可以配置;
- host:定义的代号,hostM1S1,hostM2S1
3.rule.xml
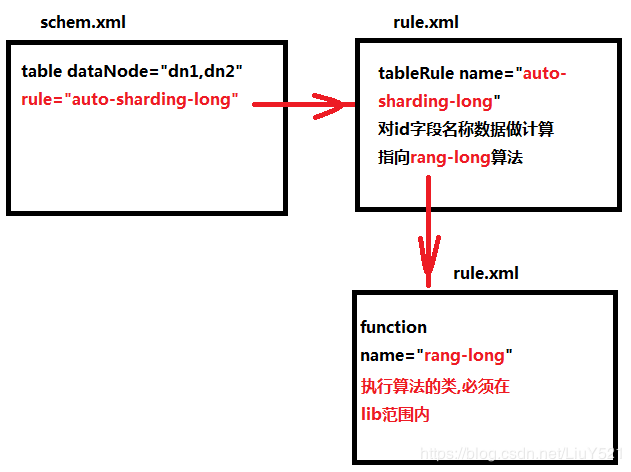
1.tableRule标签
- name:属性就是定义的一个计算规则名称,必须对应schema.xml中table指定的rule属性
- rule标签:定义计算规则
- columns:可以用来计算分片的字段名称;逗号可以隔开多个分片计算字段
- algorithm:算法的名称,对应rule.xml中一个function标签名称,指定使用的java代码
2.function标签
class="org.opencloudb.route.function.AutoPartitionByLong">
function中定义执行算法的class和mapFile(辅助文件)
3.观察autopartition-long.txt在mycat的conf文件夹中
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
在计算auto-sharding-long时,加载这个辅助的mapFile文件,可以根据配置内容定义分片计算整数值的范围;
# K=1000,M=10000.
0-30M=0
30M-60M=1
4.mycat测试案例
1.一个mycat中维护的各种不同结构的主从,分布式对应的所有标签含义
2.非分片表配置
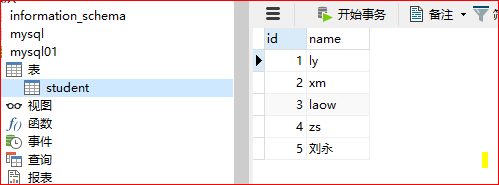
- 在数据库中(2个节点挑一个做,只使用其中一个),数据库mysql01,表格student();
- server.xml在之前时就配置完毕了
- schema.xml配置
select user()
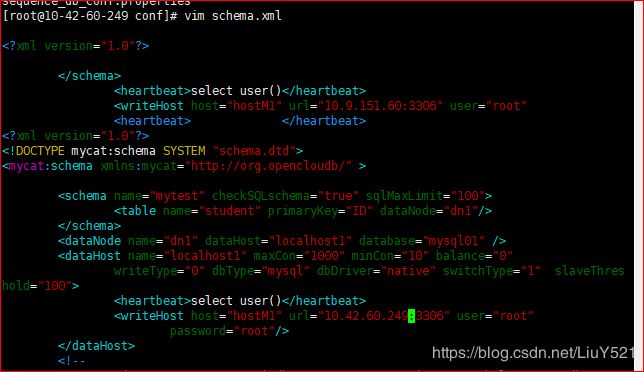
IP需要换一下
修改xml
历经九九八十一难,终于超过了,浪费我一个小时。
老是卡在一个警告上面,又浪费我半个小时
Warning: Using a password on the command line interface can be insecure.
ERROR 1045 (HY000): Access denied for user 'root' with host '10.42.60.249'
十万个曹尼玛在崩腾
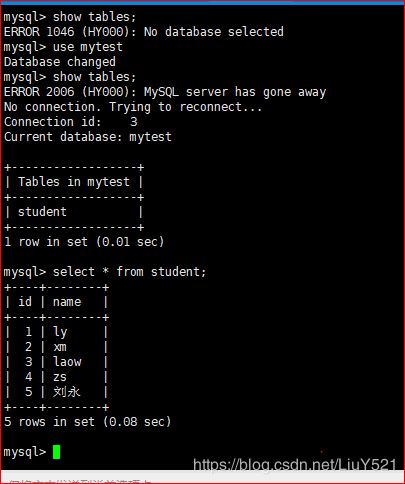
- show databases;
- use mytest;
- show tables;
- select * from student;
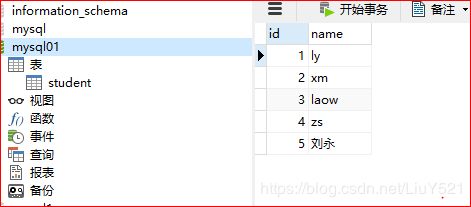
查看数据库内容

添加语句
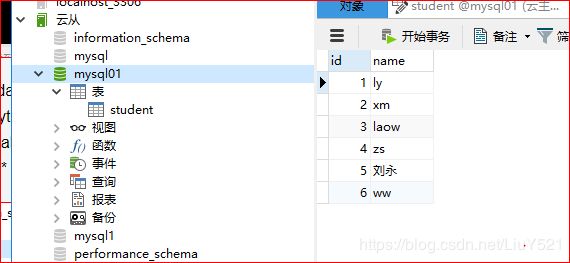
后面测试我单独写了篇博客去实现
https://mp.csdn.net/postedit/90759658