Hadoop离线项目之数据清洗
文章目录
- 1.企业级大数据项目开发流程
- 2.企业级大数据应用分类(方向)
- 3基于Maven构建大数据开发项目
- 3.1创建基于Maven的hadoop项目
- 3.2日志解析功能开发
- 3.3数据清洗ETL功能本地测试
- 3.4数据清洗功能服务器测试
- 3.5使用Hive完成最基本的统计分析功能
1.企业级大数据项目开发流程
①项目调研:以业务为导向而不是技术。这个一般是非常熟悉业务的产品经理、项目经理去做。
②需求分析:明确要做什么 ,最后做成什么样子,不关心怎么做、不关心用什么技术
③方案设计
概要设计
详细设计
系统设计
④功能开发
开发
测试:单元测试 CICD
⑤测试
功能
联调
性能
用户 试用
⑥部署上线
试运行 DIFF 稳定性
正式上线 灰度
⑦后期
2期、3期、4期等 运维保障 功能开发 bug修复
有新功能,上面流程也要来一遍
2.企业级大数据应用分类(方向)
有哪些场景能用到大数据:
企业级大数据应用平台:
①数据分析:比如BI等。数据分析可以分为两大类:自研和商业。自研是自己公司开发的,基于开源的框架进行二次开发,自研的好处是数据都在自己公司,后面可以很方便构建自己的用户画像、用户推荐、精准营销等。商业是公司用阿里、腾讯等其他企业的产品,这些对于小公司来说方便些,出故障不需要自己去维护,它有后勤保障。中大型公司一般都是自研。重要的是数据都在自己这边。
②搜索/爬虫 :elk、solr、lucence、es、爬虫
③机器学习/深度学习 :对个人的学历要求门槛很高,重点学校研究生毕业才可以
④人工智能 :对个人的学历要求门槛很高,重点学校研究生毕业才可以
数据分析具体分为离线和实时两条线。根据已有的数据数据发现更多的价值。
⑤离线处理
⑥实时处理
3基于Maven构建大数据开发项目
3.1创建基于Maven的hadoop项目
现在你去访问某个产品或者某个web页面或者某个直播视频会产生某个日志信息。比如:
baidu CN A E [17/Jul/2018:17:07:50 +0800] 2 223.104.18.110 - 112.29.213.35:80 0 v2.go2yd.com GET http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 HTTP/1.1 - bytes 13869056-13885439/25136186 TCP_HIT/206 112.29.213.35 video/mp4 17168 16384 -:0 0 0 - - - 11451601 - "JSP3/2.0.14" "-" "-" "-" http - 2 v1.go2yd.com 0.002 25136186 16384 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1531818470104-11451601-112.29.213.66#2705261172 644514568
这是一条日志记录,里面有很多字段,第一个字段是:baidu是cdn的厂商;CN是中国;E是级别;后面是访问的时候所产生的时间;223.104.18.110是访问的ip;112.29.213.35:80是服务端的ip;v2.go2yd.com是域名;后面http…是url;TCP_HIT/206命中缓存(看一个视频的时候,先去缓存里你看一下有没有,如果没有再去服务器上拿);17168是所需要的流量。
上面这条日志就是所要处理的日志。
先用IDEA创建一个maven项目:(maven是需要联网的)

下一步:
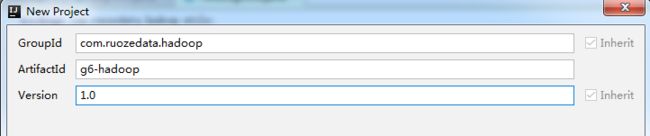
下一步:

下一步:

然后确定完成,第一次建立这个项目的时候会比较慢,因为要下载很多包什么的。
下一步:

pom.xml是maven的一个配置文件
main下面是开发代码的;test下面是测试代码的。两个下面的java颜色是不一样的。
在$MAVEN_HOME/conf/setting.xml中添加这个,让maven的仓库放在C盘以外,不然时间长了,存储越来越多。
D:\\software\\maven_repository
然后需要添加hadoop的依赖:
在pom.xml的properties里添加:
2.6.0-cdh5.7.0
这里面添加的版本一定需要和你的这个hadoop版本一致吗? 不需要。近似的版本即可。
比如生产上用cdh的,整日里你可以用apache的。因为到时候打包,Hadoop的包是不会打到里面去的,只是开发的时候用到的一个说明而已。
maven工程打包:胖包、瘦包 两种。胖包是把所有东西全打到一个jar包里面去,这里没有必要。瘦包是仅仅打包你开发的代码,一般是后面这个。
还要添加一个仓库:
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos
在pom.xml中添加
org.apache.hadoop
hadoop-client
${hadoop.version}
为什么要添加hadoop.version这个变量呢? 为了以后重构的需要,以后可能还要添加其他版本的Hadoop,如果每次修改就可以直接用这个变量${hadoop.version}就行了。
到此已经把工程建好了。
3.2日志解析功能开发
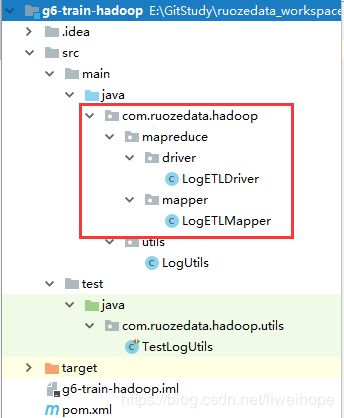
main下面建立两个包,utils下面再建立一个java类:LogUtils
test测试代码中建立一个utils包,包下面建立一个java类:TestLogUtils 单元测试

在LogUtils类中添加如下代码:用于解析日志,清洗数据
package com.ruozedata.hadoop.utils;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
public class LogUtils {
DateFormat sourceFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
DateFormat targetFormat = new SimpleDateFormat("yyyyMMddHHmmss");
/**
* 日志文件解析,对内容字段的处理
* 按\t分割
*/
public String parse(String log){
String result="";
try {
String[] splits = log.split("\t");
String cdn = splits[0];
String region = splits[1];
String level = splits[3];
String timeStr = splits[4];
String time = timeStr.substring(1,timeStr.length()-7);
time = targetFormat.format(sourceFormat.parse(time));
String ip = splits[6];
String domain = splits[10];
String url = splits[12];
String traffic = splits[20];
// System.out.println(cdn);
// System.out.println(region);
// System.out.println(level);
// System.out.println(time);
// System.out.println(ip);
// System.out.println(domain);
// System.out.println(url);
// System.out.println(traffic);
//面试题:StringBuilder和StringBuffer的区别:线程安全不安全
//解析出来的日志 → external table location是给外部表用的,所以用\t键隔开,用append拼接
StringBuilder builder = new StringBuilder("");
builder.append(cdn).append("\t")
.append(region).append("\t")
.append(level).append("\t")
.append(time).append("\t")
.append(ip).append("\t")
.append(domain).append("\t")
.append(url).append("\t")
.append(traffic);
result = builder.toString();
} catch (ParseException e) {
e.printStackTrace();
}
return result;
}
}
在单元测试TestLogUtils 里添加如下代码:进行测试
package com.ruozedata.hadoop.utils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class TestLogUtils {
private LogUtils utils;
@Before
public void setUp(){
utils=new LogUtils();
}
@After
public void tearDown(){
utils=null;
}
@Test
public void testLogParse(){
String log="baidu\tCN\tA\tE\t[17/Jul/2018:17:07:50 +0800]\t2\t223.104.18.110\t-\t112.29.213.35:80\t0\tv2.go2yd.com\tGET\thttp://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4\tHTTP/1.1\t-\tbytes 13869056-13885439/25136186\tTCP_HIT/206\t112.29.213.35\tvideo/mp4\t17168\t16384\t-:0\t0\t0\t-\t-\t-\t11451601\t-\t\"JSP3/2.0.14\"\t\"-\"\t\"-\"\t\"-\"\thttp\t-\t2\tv1.go2yd.com\t0.002\t25136186\t16384\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t-\t1531818470104-11451601-112.29.213.66#2705261172\t644514568";
String result = utils.parse(log);
System.out.println(result);
}
}
单元测试的结果:(仅仅测试了一条记录)
baidu CN E 20180717170750 223.104.18.110 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 16384
Process finished with exit code 0
现在还需要开发一个mapreduce。
3.3数据清洗ETL功能本地测试
建个mapper包,包下面建个LogETLMapper类;建个driver包,包下面建个LogETLDriver类。这些代码从driver作为入口。里面有mian方法,里面配置MapReduce的输入输出。
(只有map,没有reduce)
代码如下:
package com.ruozedata.hadoop.mapreduce.driver;
import com.ruozedata.hadoop.mapreduce.mapper.LogETLMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileInputStream;
public class LogETLDriver {
public static void main(String[] args) throws Exception {
if(args.length != 2){
System.err.println("please input 2 params: input output");
System.exit(0);
}
String input = args[0];
String output = args[1]; //"output/d=20180717"
//在本地运行的window环境需要加上 而打包到服务器注释掉本行
System.setProperty("hadoop.home.dir","D:/IDEAMaven/hadoop-2.6.0-cdh5.7.0");
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path(output);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(LogETLDriver.class);
job.setMapperClass(LogETLMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path(input));
FileOutputFormat.setOutputPath(job,new Path(output));
job.waitForCompletion(true);
}
}
然后加上参数:


然后直接运行main方法,看一下output里面的结果。
若出现异常:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:505)
at org.apache.hadoop.util.Shell.run(Shell.java:478)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:738)
解决方案:
(前提是在Windows本地先下载hadoop-2.6.0-cdh5.7.0包,然后解压)
1)、在https://github.com/4ttty/winutils 下载hadoop.dll和winutils.exe 文件。
2)、配置hadoop家目录:System.setProperty("hadoop.home.dir","D:/IDEAMaven/hadoop-2.6.0-cdh5.7.0");
3)、把hadoop.dll拷贝到C:\Windows\System32下面
4)、把winutils.exe文件拷贝到${HADOOP_HOME}/bin目录下
上面配置完之后然后再运行就可以了:

3.4数据清洗功能服务器测试
将代码打包过程:
打包之前先把这句代码注释掉:
//在本地运行的window环境需要加上 而打包到服务器注释掉本行
//System.setProperty("hadoop.home.dir","D:/IDEAMaven/hadoop-2.6.0-cdh5.7.0")


点击运行

把本地jar包上传到服务器上

把日志文件传到服务器上
[hadoop@10-9-140-90 data]$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring 20180717.log...
100% 9573 KB 4786 KB/sec 00:00:02 0 Errors
[hadoop@10-9-140-90 data]$ hdfs dfs -put /home/hadoop/data/20180717.log /data/
19/04/14 10:35:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@10-9-140-90 data]$ hdfs dfs -ls /data
19/04/14 10:35:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 9803062 2019-04-14 10:35 /data/20180717.log
[hadoop@10-9-140-90 data]$
然后运行
hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/lib/g6-hadoop-1.0.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /data/20180717.log /output
运行完之后可以查看一下output目录
[hadoop@10-9-140-90 data]$ hdfs dfs -ls /output
19/04/14 10:41:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2019-04-14 10:40 /output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 2963062 2019-04-14 10:40 /output/part-r-00000
[hadoop@10-9-140-90 data]$ hadoop fs -du -s -h /output
19/04/14 10:43:00 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2.8 M 2.8 M /output
[hadoop@10-9-140-90 data]$
上面这个运行语句不会每次去手动输入,要放在shell脚本里,调度程序去调度这个shell脚本。
现在创建一个g6-train-hadoop.sh脚本。添加如下代码:
#!/bin/bash
process_date=20180717
echo "step1:mapreduce etl"
hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/lib/g6-hadoop-1.0.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /data/$process_date.log /output/day=$process_date
然后运行脚本:
[hadoop@10-9-140-90 shell]$ chmod u+x g6-train-hadoop.sh
[hadoop@10-9-140-90 shell]$ ./g6-train-hadoop.sh
完了之后看结果:
[hadoop@10-9-140-90 shell]$ hadoop fs -ls /output/day=20180717
19/04/14 11:29:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2019-04-14 11:28 /output/day=20180717/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 2963062 2019-04-14 11:28 /output/day=20180717/part-r-00000
[hadoop@10-9-140-90 shell]$
3.5使用Hive完成最基本的统计分析功能
进入hive
创建一张外部表
create external table g6_access (
cdn string,
region string,
level string,
time string,
ip string,
domain string,
url string,
traffic bigint
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/d6_hive/external/access/clear'
看一下
[hadoop@10-9-140-90 data]$ hdfs dfs -ls /d6_hive/external/access/clear
19/04/14 11:52:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@10-9-140-90 data]$
然后把上一节跑的结果 /output/day=20180717/part-r-00000 移动到hive的分区表里
/d6_hive/external/access/clear/day=20180717 :
[hadoop@10-9-140-90 data]$ hdfs dfs -mkdir -p /d6_hive/external/access/clear/day=20180717
19/04/14 11:58:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@10-9-140-90 data]$ hdfs dfs -mv /output/day=20180717/part-r-00000 /d6_hive/external/access/clear/day=20180717
19/04/14 11:59:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@10-9-140-90 data]$ hdfs dfs -ls /d6_hive/external/access/clear/day=20180717
19/04/14 11:59:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 hadoop supergroup 2963062 2019-04-14 11:28 /d6_hive/external/access/clear/day=20180717/part-r-00000
[hadoop@10-9-140-90 data]$
现在在hive的g6_access表里还查不到,还需要刷一下元数据信息。
hive (d6_test)> alter table g6_access add if not exists partition(day='20180717');
OK
Time taken: 0.2 seconds
然后再查一下这张表,就可以查到数据了:
hive (d6_test)> select * from g6_access limit 10;
OK
cdn region level time ip domain url traffic day
baidu CN E 20180717042142 156.89.48.178 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 62109 20180717
baidu CN E 20180717042548 220.33.176.204 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 15855 20180717
baidu CN E 20180717035042 106.57.68.100 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 93710 20180717
baidu CN E 20180717032512 20.193.134.67 v1.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 65513 20180717
baidu CN E 20180717022018 5.23.216.117 v1.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 643 20180717
baidu CN E 20180717043206 217.63.184.100 v2.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 99433 20180717
baidu CN E 20180717001518 245.160.115.101 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 46296 20180717
baidu CN E 20180717040324 238.38.219.35 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 49385 20180717
baidu CN E 20180717011300 230.141.140.80 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 13311 20180717
baidu CN E 20180717054030 223.3.4.174 v4.go2yd.com http://v1.go2yd.com/user_upload/1531633977627104fdecdc68fe7a2c4b96b2226fd3f4c.mp4_bd.mp4 4959 20180717
Time taken: 0.132 seconds, Fetched: 10 row(s)
hive (d6_test)>
然后就可以进行统计分析,写sql了。
例如,现在要求:统计每个domain的traffic之和:
hive (d6_test)> select domain,sum(traffic) from g6_access group by domain;
Query ID = hadoop_20190414115050_17d05247-7e1f-455c-a018-ffb626e1d555
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1551521482026_0058, Tracking URL = http://10-9-140-90:18088/proxy/application_1551521482026_0058/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1551521482026_0058
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-04-14 12:08:25,157 Stage-1 map = 0%, reduce = 0%
2019-04-14 12:08:35,115 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.77 sec
2019-04-14 12:08:46,160 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.49 sec
MapReduce Total cumulative CPU time: 3 seconds 490 msec
Ended Job = job_1551521482026_0058
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.49 sec HDFS Read: 2970723 HDFS Write: 92 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 490 msec
OK
domain _c1
v1.go2yd.com 252434700
v2.go2yd.com 252076506
v3.go2yd.com 250212070
v4.go2yd.com 248064592
Time taken: 37.966 seconds, Fetched: 4 row(s)
hive (d6_test)>